はじめに
Twitterで技術アカウントをフォローしているならよく見かけるハッシュタグ 『#今日の積み上げ 』。
その日に成し遂げたことを箇条書きで書かれていることが多いですが、実際には何が積み上がっているのか?
気になったので可視化してみました。
実装方針
実際に何を積み上げたのかをカウントして集計するのは難しそうなので、
当該ハッシュタグを含むツイートの頻出単語を集計する方針とします。
以下の流れで実装を進めていきます。
1. tweepyで「#今日の積み上げ」のツイートを取得
2. 取得したツイートをMeCabで形態素解析し、単語ごとにカウント
3. カウントした結果をMatplotlibで可視化
前準備
使用するライブラリ等をダウンロード、インストールします。
# MeCab(形態素分析ライブラリ)
!apt-get -q -y install sudo file mecab libmecab-dev mecab-ipadic-utf8 git curl python-mecab > /dev/null
# MeCabで使用する辞書(mecab-ipadic-NEologd)
!git clone --depth 1 https://github.com/neologd/mecab-ipadic-neologd.git > /dev/null
!echo yes | mecab-ipadic-neologd/bin/install-mecab-ipadic-neologd -n > /dev/null 2>&1
# シンボリックリンクによるエラー回避
!ln -s /etc/mecabrc /usr/local/etc/mecabrc
# 日本語フォント(Google Colaboratoryでフォントを指定せずにmatplotlibを使うと日本語が文字化けしてしまうため)
!apt-get -y install fonts-ipafont-gothic
必要なライブラリもインストールします。
!pip install mecab-python3 > /dev/null
!pip install tweepy==3.10.0
また、以降はTwitterAPIを申請・各種キーを取得している前提で進めていきます。
申請方法については本記事では記載しませんが、私はこちらの記事を参考にさせていただきました。
1. tweepy で「#今日の積み上げ」のツイートを取得
SEARCH_WORDで検索したい語句を指定します。検索オプションも指定可能です。
今回指定した検索オプションの意味はそれぞれ以下のようになっています。
-
exclude:retweets非公式リツイートを除外(リツイートは元々検索結果に表示されない) -
OR @iユーザー名で引っかかるものを除外
import tweepy
# Twitter APIの情報
API_KEY = {{取得したAPI_KEY}}
API_SECRET = {{取得したAPI_SECRET }}
ACCESS_TOKEN = {{取得したACCESS_TOKEN }}
ACCESS_TOKEN_SECRET = {{取得したACCESS_TOKEN_SECRET }}
# tweepyの認証
auth = tweepy.OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)
# 検索語句
SEARCH_WORD = "#今日の積み上げ exclude:retweets OR @i"
# ツイート取得
tweets = api.search(q=SEARCH_WORD, count=100, tweet_mode='extended')
2. 取得したツイートを MeCab で形態素解析し、単語ごとにカウント
今回、1ツイートに同じ単語が2回以上出現した場合は1回目のみカウントします。
import MeCab
import collections
# 前準備でダウンロードしていた辞書を読み込む
path = "-d /usr/lib/x86_64-linux-gnu/mecab/dic/mecab-ipadic-neologd"
m = MeCab.Tagger(path)
# ツイートを形態素解析
words = []
for tweet in tweets:
text = tweet.full_text
node = m.parseToNode(text)
temp_words = []
while node:
word = node.surface
# 当該ツイート内で単語が初出の場合のみカウントする。
if word not in temp_words:
temp_words.append(word)
node = node.next
words += temp_words
# 単語の登場回数順に並び替え
c = collections.Counter(words)
3. カウントした結果を Matplotlib で可視化
import seaborn
import matplotlib.pyplot as plt
# グラフ描画
seaborn.set(font='IPAGothic') # フォントを指定
seaborn.set(context="poster") # フォントサイズを指定
fig = plt.subplots(figsize=(20, 20)) # グラフのスケールを指定
seaborn.countplot(y=words,order=[i[0] for i in c.most_common(30)]) # 上位30項目を表示する
出力結果がこちら。
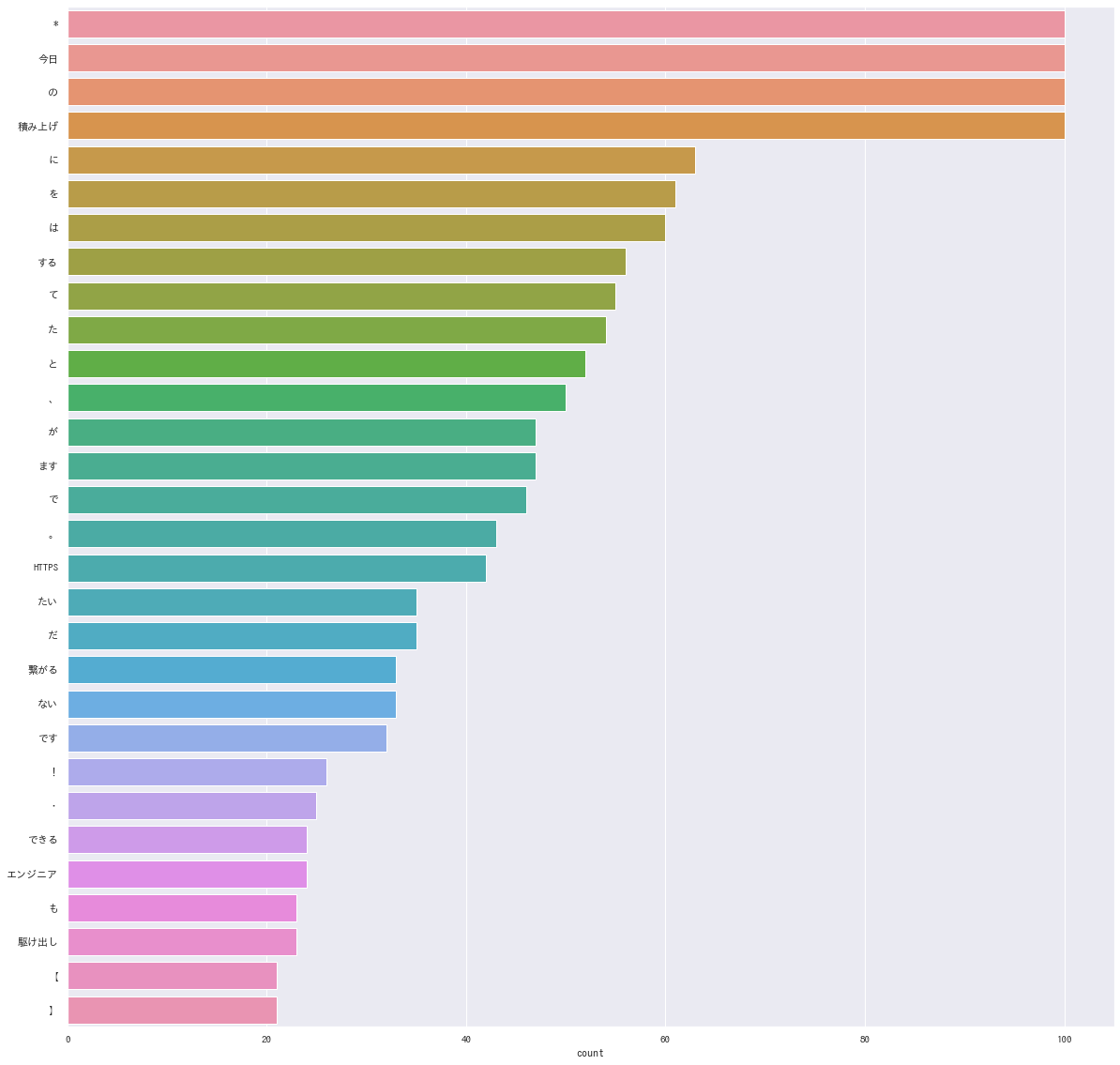
あれ、なんか思ってたのと違う…
何がダメだったか?
問題点を一つ一つ潰していきましょう。
①品詞を絞っていない
「*」「、」「。」などの記号や、「てにをは」などの副詞もカウントしてしまっています。
本記事の目標を達成するのであれば、品詞は名詞だけに絞ってよさそうです。
②除外キーワードを設定していない
「今日」「積み上げ」「こと」「よう」など、積み上げを可視化するにあたりノイズとなる語句が多く含まれています。
これらのノイズとなりうる語句を除外キーワードとしてリストアップしましょう。
③母数が少ない
上記の実装では現在時刻から直近100件のツイートのみ取得していました。
できるだけ多くのツイートを取得したいのですが、TwitterAPIでは検索時に以下の制限があります。
※Standardアカウントの場合
- 取得ツイートの数の上限:
100件/1リクエスト - リクエスト数の上限:
180リクエスト/15分 - ツイートを遡ることができる期間:
1週間
tweepy には以下の機能がありますので、そちらを組み込んでいきましょう。
- ツイートを制限の上限まで取得するメソッド
- 15分の制限に達した場合に自動で待機し、制限が明けると取得を再開するオプション
- ツイートの取得期間を設定するオプション
④取得したデータを再利用できるようにしたい
直接の問題点ではありませんが、③の実現により取得するツイート量が大幅に増加し、
取得にかかる時間も長くなることが予想されます。
取得したデータを扱いやすいように一度CSVとして出力しましょう。
Google Colaboratory から Google Drive にファイルを出力するにあたっては以下の記事を参考にさせていただきました。
改善後の実装
ツイートを取得してCSVに出力する処理がこちら。
import tweepy
import pandas as pd
# Twitter APIの情報
API_KEY = {{取得したAPI_KEY}}
API_SECRET = {{取得したAPI_SECRET }}
ACCESS_TOKEN = {{取得したACCESS_TOKEN }}
ACCESS_TOKEN_SECRET = {{取得したACCESS_TOKEN_SECRET }}
# tweepyの認証
auth = tweepy.OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(
auth,
wait_on_rate_limit = True, # 15分の制限に達した場合は待機する
wait_on_rate_limit_notify=True,# 15分の制限に達したことを通知する
)
# 検索語句
SEARCH_WORD = "#今日の積み上げ exclude:retweets OR @i"
# 取得対象期間
SINCE_YMD = '2021-08-30'
UNTIL_YMD = '2021-09-03'
sinceParam = SINCE_YMD + '_00:00:00_JST'
untilParam = UNTIL_YMD + '_23:59:59_JST'
# ツイートを取得してCSV書き込み用配列に格納
# 2021-08-30~2021-09-03 のツイートをすべて取得する
tweets = tweepy.Cursor(api.search, q=SEARCH_WORD, since = sinceParam, until = untilParam).items()
toCsvData = []
for tweet in tweets:
row = {
"date": tweet.created_at, # ツイート日時
"tweet_text": tweet.text, # ツイート本文
"tweet_id": tweet.id_str, # ツイートのID
"hashtags": tweet.entities["hashtags"], # ツイートに含まれるハッシュタグ
"user_id": tweet.author.screen_name, # ツイートしたユーザーのユーザー名
}
toCsvData.append(row)
# Google DriveにCSV出力
BASE_DIR = "/content/drive/MyDrive/今日の積み上げ/"
csvFileName = SINCE_YMD + "_" + UNTIL_YMD + ".csv"
df = pd.DataFrame(toCsvData)
df.to_csv(BASE_DIR + csvFileName, encoding="utf-8")
CSVを読み込んでグラフに出力する処理がこちら。
import pandas as pd
import MeCab
import collections
import seaborn
import matplotlib.pyplot as plt
# CSV読み込み
csvFileName = SINCE_YMD + "_" + UNTIL_YMD + ".csv"
df = pd.read_csv(BASE_DIR + csvFileName, encoding="utf-8")
# ツイートから除外するキーワード
exclude_keyword = [
"*",
"今日",
"積み上げ",
"駆け出し",
"エンジニア",
"初心者",
"明日",
"復習",
"こと",
"の",
"本日",
"よう",
"https",
"t",
"co",
"そう",
"ん",
"何",
"人",
"戦",
"中",
"分",
"土曜日",
"昨日",
"さん",
"これ",
"ため",
"チェックボックス",
"0",
"1",
"2",
"3",
"4",
"5",
"6",
"7",
"8",
"9",
"日",
"時間",
"☀",
"おは",
"朝",
"9月",
"8月",
]
# 取得対象の品詞
include_hinshi = ["名詞"]
# ツイートを形態素解析
words = []
for text in df['tweet_text']:
node = m.parseToNode(text)
temp_words = []
while node:
hinshi = node.feature.split(",")[0]
word = node.surface
# 取得対象の品詞であり、除外対象のキーワードではなく、
# 当該ツイート内で単語が初出の場合のみカウントする。
if hinshi in include_hinshi and word not in exclude_keyword and word not in temp_words:
temp_words.append(word)
node = node.next
words += temp_words
# 単語の登場回数順に並び替え
c = collections.Counter(words)
# グラフ描画
seaborn.set(font='IPAGothic') # フォントを指定
seaborn.set(context="poster") # フォントサイズを指定
fig = plt.subplots(figsize=(30, 30)) # グラフのスケールを指定
seaborn.countplot(y=words,order=[i[0] for i in c.most_common(50)]) # 上位50項目を表示
出力結果がこちら。
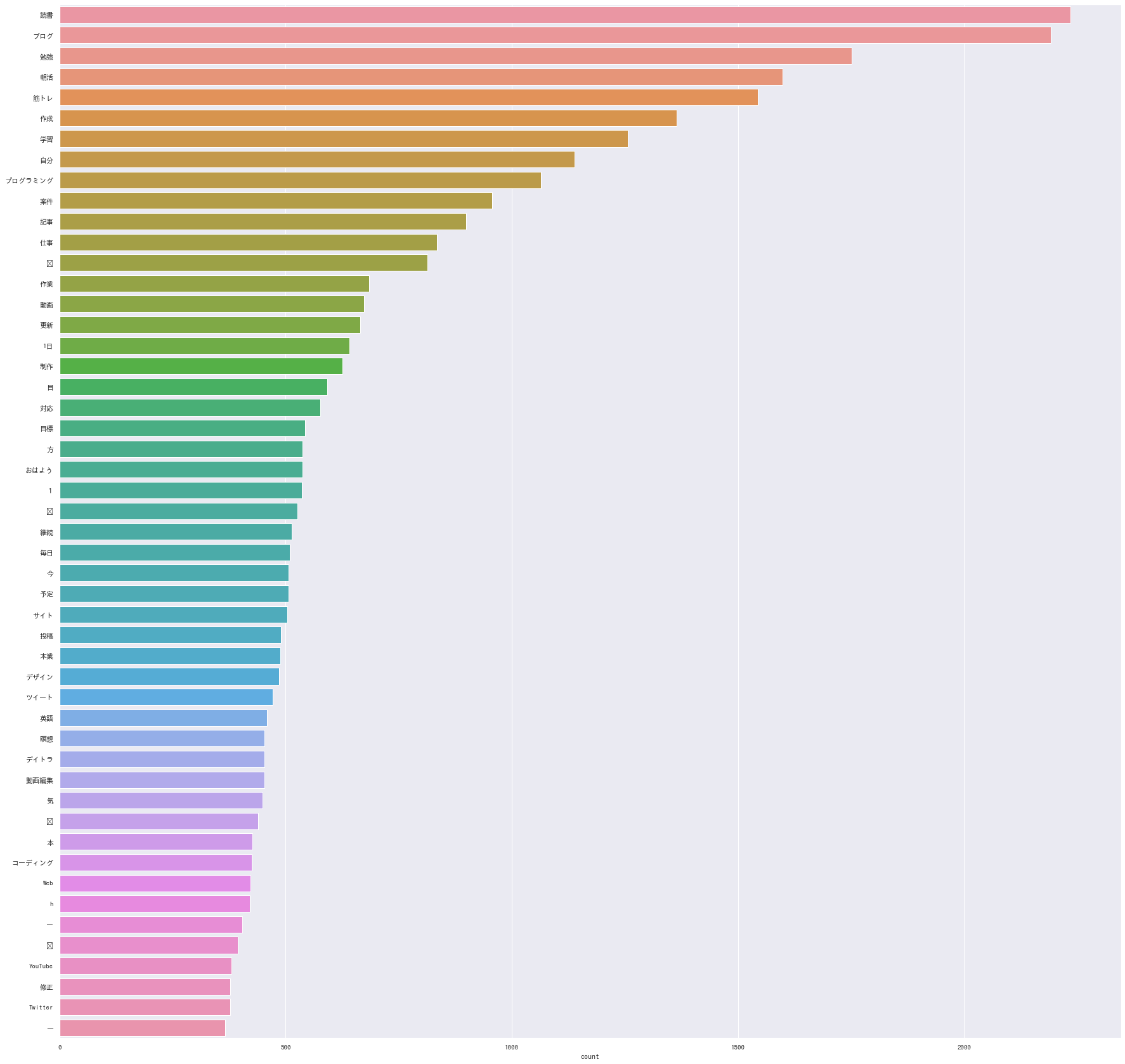
無事にそれっぽくなりました!
課題
表記ゆれを吸収できていない
もし「AWS」「Aws」「aws」「AWS」のように 表記が分かれていた場合、別々の単語としてカウントされてしまいます。
半角/全角、大文字/小文字の統一は簡単そうですが、「blog」「ブログ」等の場合はもう一捻り工夫が必要そうです。
除外キーワードのリストアップが力業
グラフをみて「この単語いらなくない?」と思ったものを除外キーワードにリストアップしていったのですが、
かなりの力業なのと、その人の感覚で判断してしまっています。
統一的なルールを制定し、そのルールに従って自動的にリストアップできるようになるのが理想的ですね。
実際に積み上げられたものではない
本記事で達成したのは**『#今日の積み上げ を含むツイートの傾向分析』であり、『実際に積み上げられたもの』**ではありません。
これが一番根深そうなのですが、残念ながら今の私にはその知見が無いので解決策が思い浮かびません。
もし知見がある方がいらっしゃいましたらご教授いただきたいです。
さいごに
今回のように簡単なものであれば Google Colaboratory でサクッと実現できて便利ですね。
また、今回はツイート本文しか使用しませんでしたが、取得したツイートのデータにはツイートの日時や
ツイートしたユーザーのプロフィールやフォロー/フォロワー数、(設定されている場合)位置情報なども含まれます。
これらをビッグデータとして活用すれば、もっと面白い事やビジネスにも転用できそうですね。
ふとした疑問から始まったのですが、いい感じに色々な技術の習作にすることができました。