はじめに
この記事では、BigQuery 上での分析を定期実行するワークフローを Apache Airflow を用いて作成します。

<モチベーション>
業務を開始する頃には既に分析を完了しているシステムがあれば時間的コストを削減できそうです。
マネージドサービスを用いれば互換性のないアップデートに対応するコストを削減することもできます。
メリットはありますが BigQuery のワークフローのために GKE 上で Cloud Composer を動かすことは避けたい思いもあります。
(Cloud Composer の料金の詳細)
Terraform
 Terraform は HashiCorp により提供されているインフラストラクチャの構築管理を行うツールです。
インフラストラクチャ の設定を HCL(HashiCorp Configuration Language : DSL)を使用してコード化することによりマルチクラウド環境で同じコードを利用することができます。
このセクションでは、 Terraform を用いて Cloud Composer 環境を立ち上げる方法を示します。
Terraform は HashiCorp により提供されているインフラストラクチャの構築管理を行うツールです。
インフラストラクチャ の設定を HCL(HashiCorp Configuration Language : DSL)を使用してコード化することによりマルチクラウド環境で同じコードを利用することができます。
このセクションでは、 Terraform を用いて Cloud Composer 環境を立ち上げる方法を示します。
<サービスアカウントの作成>
GCP のコンソールから Cloud Shell を開きサービスアカウントを作成します。
Terrafrom から Cloud Composer を立ち上げるために 「編集」と「Composer ワーカー」のロールをサービスアカウントに追加します。
$ gcloud version
$ export GCP_PROJECT_ID=${<project id>}
$ gcloud iam service-accounts create terraform
$ gcloud projects add-iam-policy-binding ${GCP_PROJECT_ID} --member serviceAccount:terraform@${GCP_PROJECT_ID}.iam.gserviceaccount.com --role roles/editor
$ gcloud projects add-iam-policy-binding ${GCP_PROJECT_ID} --member serviceAccount:terraform@${GCP_PROJECT_ID}.iam.gserviceaccount.com --role roles/composer.worker
<インスタンスの立ち上げ>
Compute Engine 上で VM インスタンス を立ち上げます。
その際に先ほど作成したサービスアカウントを選択します。
作成したインスタンスに SSH 接続しそのコマンドライン上で Terraform を用いた Cloud Composer の立ち上げを行います。
<Python 3 環境の構築>
(Python 3 環境で作業する習慣があるため Pythron 3 の環境を構築します。)
デフォルトでは Python 2 系 なので Python 3 系 の環境を構築します。
具体的には airflow というディレクトリを作りそのディレクトリに Python 3 環境を構築します。
$ sudo apt-get update
$ sudo apt-get install -y make build-essential libssl-dev zlib1g-dev \
libbz2-dev libreadline-dev libsqlite3-dev wget curl llvm libncurses5-dev \
libncursesw5-dev xz-utils tk-dev libffi-dev liblzma-dev python-openssl git
$ git clone https://github.com/yyuu/pyenv.git ~/.pyenv
$ echo 'export PYENV_ROOT="$HOME/.pyenv"' >> ~/.bashrc
$ echo 'export PATH="$PYENV_ROOT/bin:$PATH"' >> ~/.bashrc
$ echo -e 'if command -v pyenv 1>/dev/null 2>&1; then\n eval "$(pyenv init -)"\nfi' >> ~/bashrc
$ source ~/.bashrc
$ pyenv install 3.7.4
$ mkdir airflow
$ cd airflow
$ echo 'export PATH="$HOME/.pyenv/bin:$PATH"' >> ~/.bashrc
$ echo 'eval "$(pyenv init -)"' >> ~/.bashrc
$ source ~/.bashrc
$ pyenv local 3.7.4
$ python -V
<サービスアカウントの鍵の作成>
後の過程で使用するため ~/.config/gcloud の直下に airflow-te-terraform-credential.json を作成します。
$ gcloud iam service-accounts keys create ~/.config/gcloud/airflow-te-terraform-credential.json --iam-account terraform@${GCP_PROJECT_ID}.iam.gserviceaccount.com
<Terraform の導入>
wget を用いてダウンロードした Terraform のファイル(Linux-64bit)を解凍し /usr/local/bin の直下に配置します。
ダウンロードを行う最新のバージョンは公式のダウンロードページをご参照ください。
$ sudo apt-get update
$ sudo apt install unzip
$ wget https://releases.hashicorp.com/terraform/0.13.1/terraform_0.13.1_linux_amd64.zip
$ sudo unzip terraform_0.13.1_linux_amd64.zip -d /usr/local/bin/
$ terrraform version
<Cloud Composer 環境の立ち上げ>
立ち上げる Cloud Composer の環境は GKE により管理されますが Cloud Composer 以外のリソースは GKE により管理されないことに注意が必要です。
Cloud Composer 環境の設定は HCL(HashiCorp Configuration Language : DSL)を用いて tf ファイルに記述します。
$ vi composer-te.tf
tf ファイルの書き方については公式ドキュメントをご参照ください。
今回はコードをまとめるためにサービスアカウントの鍵のパスを credentials に指定していますがこの方法は推奨されていません。
export により鍵のパスの変数を作りその変数を credentials に指定する方法を公式も推奨しています。
provider "google" {
credentials = "${file("~/.config/gcloud/airflow-te-terraform-credential.json")}"
project = "<project id>"
region = "<region>"
}
resource "google_composer_environment" "test-environment" {
name = "<arbitary composer name>"
project = "<project id>"
region = "<arbitary region>"
config {
node_count = 4
node_config {
zone = "<arbitary zone>"
machine_type = "<arbitary machine_type>"
disk_size_gb = 30 # default: 100 GB
service_account = "terraform@${GCP_PROJECT_ID}.iam.gserviceaccount.com"
}
software_config {
pypi_packages = {
pandas = ""
numpy = ""
}
env_variables = {
FOO = "bar"
}
image_version = "composer-1.11.3-airflow-1.10.6"
python_version = 3
}
}
}
| command: | |
|---|---|
| terraform fmt | 作成した tf ファイル のインデントを調整 |
| terraform validate | HCL の構文をチェック |
| terraform plan | クラウドの API にアクセスし tf ファイルをシステムに影響を与えることなく実行。表示されるクラウド上のリソース情報を元に tf ファイルを apply により実行するかを判断します。 |
| terraform init | Terrafrom の設定ファイル (tf ファイル)を含むワークディレクトリを初期化 |
| terraform apply | Cloud Composer 環境の立ち上げ |
$ terraform
$ terraform validate
$ terraform plan
$ terraform init
$ terraform apply
GCP の Composer を確認すると環境ができているはずです。
これで Airflow を実行する環境が整いました。
Apache Airflow
 Apache Airflow は複数のタスクの実行順序や実行のスケジューリングを管理することができるツールです。
各タスクの依存関係は Python により記述され、ワークフローでの各タスクの依存関係と実行状況を有向非巡回グラフとして Web UI からモニタリングすることができます。
Cloud Composer 環境が立ち上がるのと同時に Cloud Storage にバケットが作成されます。
そのバケットの dags フォルダに ワークフロー(DAG)の設定を記述した Python ファイルをアップデートすることでワークフローを実行します。
Apache Airflow は複数のタスクの実行順序や実行のスケジューリングを管理することができるツールです。
各タスクの依存関係は Python により記述され、ワークフローでの各タスクの依存関係と実行状況を有向非巡回グラフとして Web UI からモニタリングすることができます。
Cloud Composer 環境が立ち上がるのと同時に Cloud Storage にバケットが作成されます。
そのバケットの dags フォルダに ワークフロー(DAG)の設定を記述した Python ファイルをアップデートすることでワークフローを実行します。
<必要なライブラリの読み込み>
import re
import json
import requests
from datetime import datetime, timedelta
import pendulum
import codecs
import pandas_gbq
from airflow.models import Variable
from airflow import DAG
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
from airflow.contrib.operators.bigquery_operator import BigQueryCreateEmptyTableOperator
from airflow.contrib.operators.bigquery_table_delete_operator import BigQueryTableDeleteOperator
<Slack への通知>
タスクの 成功/失敗 を Slack に通知する関数を作ります。
Slack に通知する方法はいくつかありますが以下では Incoming Webhook を用いた方法を採用しています。
Slack への通知方法に関してはこちらの記事(AirflowのDAGの実行状況をSlackに通知して監視する)にシンプルかつ分かりやすいコードが記述されていたので拝借しました。
Incoming Webhook の機能についての記事(slackのIncoming webhookが新しくなっていたのでまとめてみた)も参考にしています。
# webhook URLやチャンネル名などを指定
webhook_url = '<webhook url>' # Variable.get('slack_webhook_url')
webhook_name = '<slack webhook name>' # webhook_name = Variable.get('slack_webhook_name')
channel_name = '<channel name>' # channel_name = Variable.get('slack_channel_name')
# タスク失敗を通知する関数
def failured(status):
dag_name = re.findall(r'.*\:\s(.*)\>', str(status['dag']))[0]
task_name = re.findall(r'.*\:\s(.*)\>', str(status['task']))[0]
data = {
'username': webhook_name,
'channel': channel_name,
'attachments': [{
'fallback': f'{dag_name}:{task_name}',
'color': '#e53935',
'title': f'{dag_name}:{task_name}',
'text': f'{task_name} was failed...'
}]
}
requests.post(webhook_url, json.dumps(data))
# タスク成功を通知する関数
def successed(status):
dag_name = re.findall(r'.*\:\s(.*)\>', str(status['dag']))[0]
data = {
'username': webhook_name,
'channel': channel_name,
'attachments': [{
'fallback': dag_name,
'color': '#1e88e5',
'title': dag_name,
'text': f'{dag_name} was successed!'
}]
}
requests.post(webhook_url, json.dumps(data))
webhook_url, webhook_name, channel_name それぞれの変数を作り Variable.get('') を用いて変数を読み込む方法もあります。
Terraform を用いて Cloud Composer 環境を立ち上げる際には以下のようにして Airflow に用いる変数を設定できます。
- Terraform 公式 (google_composer_environment)
- Airflow 公式 (Concepts) )
resource {
config {
software_config {
env_variables = {
SLACK_WEBHOOK_URL = "<webhook url>"
SLACK_WEBHOOK_NAME = "<slack webhook name>"
CHANNEL_NAME = "<channel name>"
}
}
}
}
<SQL ファイルのインポート>
SQL 構文を DAG の設定ファイルに記述するとクエリやワークフローが複雑になった場合に DAG の設定ファイルのコードが SQL 構文のために長くなります。
回避するために SQL 構文を別のファイルに記述し Cloud Composer 環境にインポートします。
Cloud Composer 環境にインポートした SQL ファイルを DAG の設定ファイルに読み込みます。
$ mkdir sql
$ cd sql
$ vi airflow-te.sql
with with_1 as (
select
count(distinct purchase_id) as Z_count
from `<project id>.<dataset>.<table>`
),
with_2 as (
select
a.purchase_id,
a.product_id,
count(*) over(partition by a.product_id) as product_count,
b.Z_count
from `<project id>.<dataset>.<table>` as a cross join (select Z_count from with_1) as b
),
with_3 as (
select
a.product_id as A,
b.product_id as B,
a.product_count as A_count,
b.product_count as B_count,
count(*) as A_B_count,
a.Z_count
from with_2 as a
inner join with_2 as b on a.purchase_id = b.purchase_id
where A <> B
group by A, B, A_count, B_count, Z_count
)
select
c.A,
c.B,
round(100.0 * (c.A_B_count / c.Z_count) , 2) as support,
round(100.0 * (c.A_B_count / c.A_count) , 2) as confidence,
round(100.0 * ((c.A_B_count / c.A_count) / (c.B_count / c.Z_count)) , 2) as lift
from with_3 as c
order by A, B
;
以下の gcloud コマンドで Cloud Composer にインポートされた フィルは /home/airflow/gcs/plugins に配置されます。
$ cd ..
$ gcloud composer environments storage plugins import --project <project id> --environment <environment name> --location <region in which to create the environment> --source sql
Reference:
gcloud composer environments storage plugins import
Airflow コマンドライン インターフェース
Airflow 構成をオーバーライドする
<ワークフロー(DAG)の設定>
以下の 3 ステップを順に実行するワークフローを作成します。
- 前回の分析結果を持つテーブルを削除。
- 削除したテーブルと同じスキーマを持つ空のテーブルを作成。
- 作成した空のテーブルにクエリの結果を送る。
BigQuery を操作するためには Google BigQuery operators を使用します。
| Operator: | |
|---|---|
| BigQueryTableDeleteOperator | テーブルを削除 |
| BigQueryCreateEmptyTableOperator | 空のテーブルを作成 |
| BigQueryOperator | クエリの結果を INSERT |
default_args = {
'owner': 'airflow',
'depends_on_past': True,
'start_date': datetime(2020, 8, 31, tzinfo = pendulum.timezone('Asia/Tokyo')) - timedelta(days = 2), # 2 日前のワークフローから実行
'retries': 5,
'retry_delay': timedelta(minutes = 5),
'on_failure_callback': failured # 1 つでもタスクが失敗した場合に通知
GCP_PROJECT_ID = '<project id>'
DATASET_ID = '<arbitary dataset name>'
table_name = '<arbitary table name>'
schedule_interval = '0 9 * * *' # ワークフローを 9:00 に実行
with codecs.open('/home/airflow/gcs/plugins/sql/s-c-l.sql', 'r', 'utf-8') as q:
query = q.read()
with DAG(dag_id = 'airflow-te',
default_args = default_args,
schedule_interval = schedule_interval
) as dag:
delete_table = BigQueryTableDeleteOperator(
task_id = 'delete_existing_table',
deletion_dataset_table = '{}.{}.{}'.format(GCP_PROJECT_ID, DATASET_ID, table_name),
dag = dag
)
create_empty_table = BigQueryCreateEmptyTableOperator(
task_id = 'create_empty_table',
project_id = GCP_PROJECT_ID,
dataset_id = DATASET_ID,
table_id = table_name,
schema_fields = [{"name": "A", "type": "STRING", "mode": "NULLABLE"},
{"name": "B", "type": "STRING", "mode": "NULLABLE"},
{"name": "support", "type": "FLOAT", "mode": "NULLABLE"},
{"name": "confidence", "type": "FLOAT", "mode": "NULLABLE"},
{"name": "lift", "type": "FLOAT", "mode": "NULLABLE" }], # '/schema/{}-schema.json'.format(table_name),
dag = dag
)
write_to_bq = BigQueryOperator(
task_id = 'write_to_bq',
use_legacy_sql = False,
write_disposition = 'WRITE_TRUNCATE',
allow_large_results = True,
sql = query,
destination_dataset_table = '{}.{}.{}'.format(GCP_PROJECT_ID, DATASET_ID, table_name),
dag = dag,
on_success_callback = successed # すべてのタスクが成功した場合に通知
)
delete_table >> create_empty_table >> write_to_bq
# delete_table.set_upstream(create_empty_table)
# create_empty_table.set_upstream(write_to_bq)
| argument: | |
|---|---|
| ower | ワークフロー(DAG) のタスクのオーナー |
| depends_on_past | それぞれのタスクは前回のワークフローの同じタスクの 成功/失敗 に依存する |
| wait_for_downstream | それぞれのタスクは前回のワークフローの同じタスクの下流にあるすべてのタスクの 成功/失敗 に依存する |
| start_date | ワークフローの開始日 |
| retries | タスクが失敗した場合のリトライ数 |
| retry_delay | タスクが失敗した場合にリトライを行う時間の間隔 |
| on_failure_callback | タスクが失敗した場合の Slack 通知 |
| on_success_callback | タスクが成功した場合の Slack 通知 |
| dag_id | ワークフロー(DAG) の一意の名前 |
| schedule_interval | ワークフローを実行する時間や曜日 |
| task_id | タスクの名前 |
| deletion_dataset_table | 削除テーブル |
| use_legacy_sql | 標準とレガシーどちらの SQL を使用するのか |
| write_disposition | 'WRITE_TRUNCATE' を設定した場合は書き込みの際のバッファを保持 |
| allow_large_results | SQL クエリで大きいサイズの宛先テーブルが有効 |
| destination_dataset_table | 宛先テーブル |
| A >> B | タスク A の後に タスク B を実行 |
| A.set_upstream(B) | タスク A の後に タスク B を実行 |
Reference: airflow.contrib.operators.bigquery_operator
<ワークフロー(DAG)の実行>
DAG の設定を記述した Python ファイルを dags フォルダにアップロードすることでワークフローを実行します。
ワークフロー(DAG)が最初に実行される時刻は start_date ではなく start_date + schedule_interval であることにも注意が必要です。 Reference: Airflow の流れを制す
以下のコードでは Timezone に明示的に JST を指定していますが Cloud Shell や Web UI から core に "default_timezone = Asia/Tokyo" を設定できます。
import re
import json
import requests
from datetime import datetime, timedelta
import pendulum
import codecs
import pandas_gbq
from airflow.models import Variable
from airflow import DAG
from airflow.contrib.operators.bigquery_operator import BigQueryOperator
from airflow.contrib.operators.bigquery_operator import BigQueryCreateEmptyTableOperator
from airflow.contrib.operators.bigquery_table_delete_operator import BigQueryTableDeleteOperator
webhook_url = '<webhook url>'
webhook_name = '<slack webhook name>'
channel_name = '<channel name>'
def failured(status):
dag_name = re.findall(r'.*\:\s(.*)\>', str(status['dag']))[0]
task_name = re.findall(r'.*\:\s(.*)\>', str(status['task']))[0]
data = {
'username': webhook_name,
'channel': channel_name,
'attachments': [{
'fallback': f'{dag_name}:{task_name}',
'color': '#e53935',
'title': f'{dag_name}:{task_name}',
'text': f'{task_name} was failed...'
}]
}
requests.post(webhook_url, json.dumps(data))
def successed(status):
dag_name = re.findall(r'.*\:\s(.*)\>', str(status['dag']))[0]
data = {
'username': webhook_name,
'channel': channel_name,
'attachments': [{
'fallback': dag_name,
'color': '#1e88e5',
'title': dag_name,
'text': f'{dag_name} was successed!'
}]
}
requests.post(webhook_url, json.dumps(data))
default_args = {
'owner': 'airflow',
'depends_on_past': True,
'start_date': datetime(2020, 8, 31, tzinfo = pendulum.timezone('Asia/Tokyo')) - timedelta(days = 2),
'retries': 5,
'retry_delay': timedelta(minutes = 5),
'on_failure_callback': failured
GCP_PROJECT_ID = '<project id>'
DATASET_ID = '<arbitary dataset name>'
table_name = '<arbitary table name>'
schedule_interval = '0 9 * * *'
with codecs.open('/home/airflow/gcs/plugins/sql/s-c-l.sql', 'r', 'utf-8') as q:
query = q.read()
with DAG(dag_id = 'airflow-te',
default_args = default_args,
schedule_interval = schedule_interval
) as dag:
delete_table = BigQueryTableDeleteOperator(
task_id = 'delete_existing_table',
deletion_dataset_table = '{}.{}.{}'.format(GCP_PROJECT_ID, DATASET_ID, table_name),
dag = dag
)
create_empty_table = BigQueryCreateEmptyTableOperator(
task_id = 'create_empty_table',
project_id = GCP_PROJECT_ID,
dataset_id = DATASET_ID,
table_id = table_name,
schema_fields = [{"name": "A", "type": "STRING", "mode": "NULLABLE"},
{"name": "B", "type": "STRING", "mode": "NULLABLE"},
{"name": "support", "type": "FLOAT", "mode": "NULLABLE"},
{"name": "confidence", "type": "FLOAT", "mode": "NULLABLE"},
{"name": "lift", "type": "FLOAT", "mode": "NULLABLE" }], # '/schema/{}-schema.json'.format(table_name),
dag = dag
)
write_to_bq = BigQueryOperator(
task_id = 'write_to_bq',
use_legacy_sql = False,
write_disposition = 'WRITE_TRUNCATE',
allow_large_results = True,
sql = query,
destination_dataset_table = '{}.{}.{}'.format(GCP_PROJECT_ID, DATASET_ID, table_name),
dag = dag,
on_success_callback = successed
)
delete_table >> create_empty_table >> write_to_bq
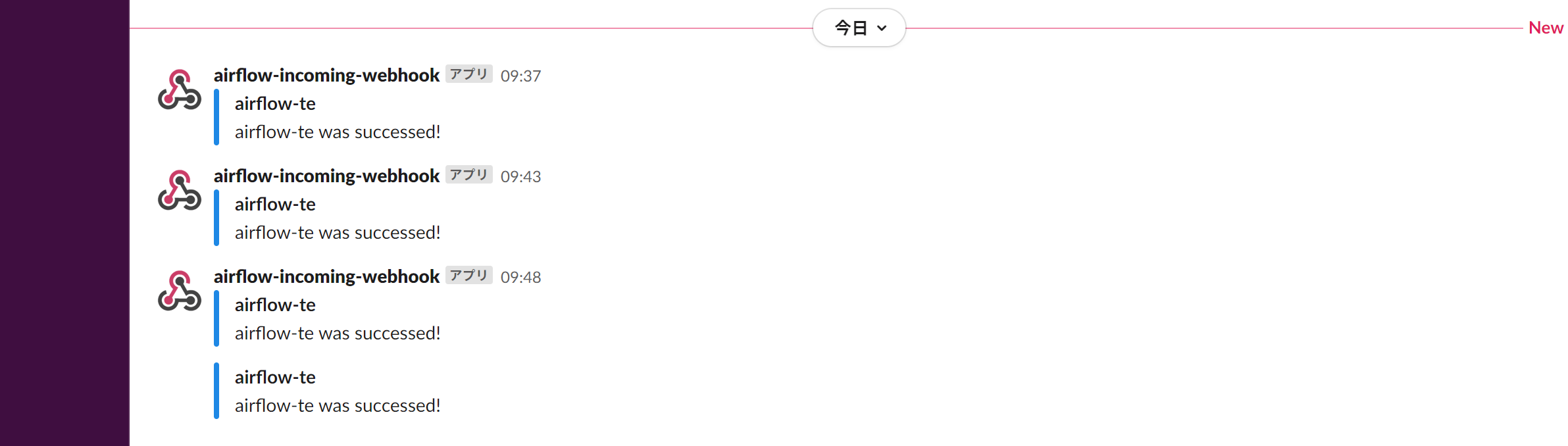
成功すれば Web UI の表示と Slack への通知は以下のようになります。


まとめ
Apache Airflow を用いて BigQuery 上での分析を効率化する簡単なワークフローを構築してみました。
より効率的な方法や理解不足なところなどありましたらご指摘のほどよろしくお願いいたします。