Skip list in Rust
tl;dr
アドベントカレンダーに合わせて skip list を Rust で実装しようとして間に合わなかった話です。
進捗はこちら: https://github.com/topecongiro/skiplist-rs
はじめに
はじめまして。オープンプラットフォーム事業部の内田です。今年新卒として DeNA に入社しました。仕事では C++ で SDK や常駐プログラムを書いています。最近の悩みは週3で麻婆豆腐麺を食べていたら肥えてきたことです。
特に業務関連で記事のネタが無かったので、個人的に興味のある Rust を使ってデータ構造を書き、標準ライブラリのものと比較したベンチマークを取るぐらいまでやってみようかな〜と気軽な気持ちでネタを決めました。
結果的に、想定していた倍の時間を費やしても終わらず、Rust でデータ構造を多少真面目に書こうとすると、とても大変ということがわかりました ![]()
ベンチマークどころかデータ構造自体の実装すらもろくに終わっていない状態なため、本記事では
- 書いている skip list の工夫について
- 現時点での達成度
- 書いていく上で得た所感
について書いていこうかと思います。
とりとめのない話になりますが最後までお付き合いくだされば幸いです。
Skip list とは
Skip list は確率的なデータ構造です。名前に「list」とありますが、性質は探索木に近しいです。気持ちとしては、連結リストに「高さ」をランダムにつけて、探索を効率化したものです。詳しくは wikipedia を参照してください。

[William Pugh (1990), A Skip List Cookbook, Figure 1.]
探索木が挿入・削除の度にいろいろ頑張って構造全体のバランスを取り性能を担保しているのに対し、skip list はノードの高さをランダムに選択するだけで(大体)期待通りの性能になるという、少しインチキ臭い作りになっています。探索木と比べると、挿入・削除の度にポインタをぽちぽち張り替えるだけで済むので、相対的に実装が楽です。
木構造の辛み
Skip list に限らず、木構造のようなデータ構造は一般的に以下の辛みがあります:
- キャッシュミスの頻発
- メモリ非効率
一般的な木構造では1つのノードに1つの key-value pair を持たせる構造になっています。このような構造は、一般的にキャッシュとの親和性が低いです。なぜなら、探索時に、キーを比較するために毎回毎回別のノードにアクセスする必要があり、その度に高い確率でキャッシュミスが発生するためです。また、各ノードには構造用のポインタをもたせる必要があります。ナイーブな実装の場合、binary search tree であれば1ノード毎に2つ、skip list であれば skip list が取りうる高さの分だけのポインタが必要になります。64-bit 環境ではポインタは8バイトに相当するため、無視できないオーバーヘッドとなります。
// A node of binary search tree.
struct bst_node_t {
struct bst_node_t *left, *right;
uint64_t key;
void *val;
};
// A node of skip list.
struct skip_list_node_t {
struct skip_list_node_t *right_nodes[MAX_HEIGHT];
uint64_t height;
uint64_t key;
void *val;
};
この辺りを嫌ってか、Rust の標準ライブラリにはキャッシュとの親和性が高く、key-value pair 辺りのポインタ数が少なくて済む B-tree が採用されています 1 。
今回 skip list を実装するにあたって、この二点に気を配ってみました。
今回実装する skip list の工夫
ノードあたりに保存する key-value pair の数を増やす
B-tree のように、1ノードあたりに2個以上の key-value pair を持たせるようにします。
ノードに持たせるポインタのための領域を最低限にする
上の C で書かれた疑似コードでは、ポインタのための領域は配列として確保してありました。これだと使わない部分が無駄になります。 Vec を使えばメモリ領域の無駄は無くなりますが、その分余計に参照する必要があります。可変長の型があればよいのですが、Rust ではコンパイル時にオブジェクトの大きさが決まっている必要があるため、少し工夫が必要です。今回は、 malloc 相当の関数2を使い、ポインタのための領域の大きさを実行時に決められるようにします。
具体的には、以下のような構造を作ります:
struct Node<K, V> {
keys: [K; 16],
vals: [V; 16],
len: usize,
height: usize,
}
Node の定義には何も書いていませんが、実は Node の後ろにポインタ用の領域が確保してあるという状態です。気持ち的には下の図のような状態になっています:
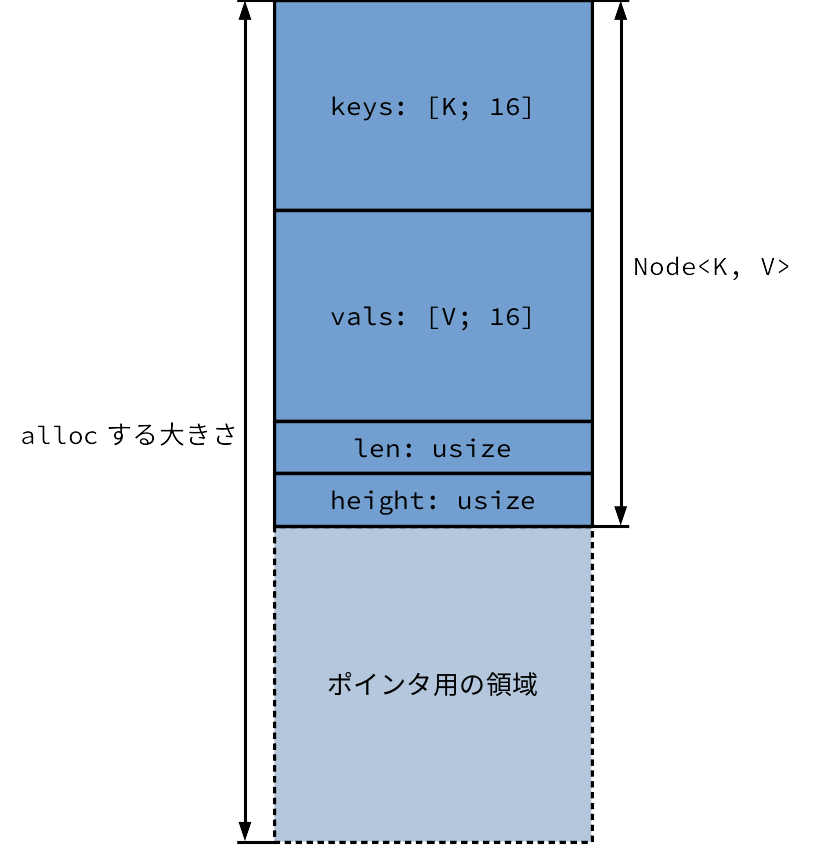
うっかりNode をクローンしたりしないよう、 Node を作るときは必ず alloc 経由で作り NonNull に包んで返します。その際、 Node 自体の大きさ + ポインタ分の領域を確保します:
fn new(height) -> NonNull<Node<K, V>> {
let size = size_of::<Node<K, V>>() + size_of::<*mut Node<K, V>>() * height;
let align = 32; // cache line size
let ptr = alloc(Layout::from_size_align(size, align).unwrap());
let mut node = NonNull::new_unchecked(ptr);
/*
* keys, vals, ポインタの初期化
*/
node
}
進捗
当初の目標では、 std::collections::BTreeMap と同じ API を提供する SkipListMap を実装し、両者のベンチマークを取って性能を比較するところまでやろうと思っていました。
翻って現在の進捗はというと、 insert と remove (の一部)の実装が完了したところです ![]()
その他の API や Iterator は手付かずとなっているので、今後の課題です。また現在の実装もわりとガバガバなので、引き続き改良していきたい所存です。
所感
ポインタをいじくり回す部分は Rust の恩恵が受けにくい
公式 HP によると Rust の売りはパフォーマンス、安全性、生産性だそうです。確かに、Rust でプログラミングをするとき、これらのメリットを強く感じます。
一方で、今回のようにポインタをいじくって遊ぶような場合、unsafe Rust を使わざるを得ません。unsafe なコードでは Rust コンパイラはこちらのことを助けてくれません。誤ったコードを書けば SIGABRT だの SIGSEGV だの double free or corruption だの多種多様なエラーメッセージを吐いてくれます。普段の Rust であればコンパイル時に防げていたかもしれないですが、unsafe Rust では地道にデバッグしていくしかありません。
とはいえ流石に平成の終わりも近い現代、Rust はポインタを扱いやすくしてくれる諸々を提供しています。今回使った中では、ptr::addなどのようにポインタをバイトではなく個数単位で扱える API 群やmemモジュール、NonNull, MaybeUninit などが便利だと感じました。
ランダム要素があるとテスト書きづらい
Skip list はランダムに構造が決まるため、同じ値を同じ順番で挿入したとしても違う構造になる可能性が高いです。そのため、再現性のある形でテストするためには気合で自前でデータを注入する必要があります。今回はそこまでやる余裕がなかったので、
手戻りを減らせるように事前に考えをまとめる
今回いくつか工夫を加えたことで、普通の skip list と比べると挿入や削除のときの処理が多少複雑になっています。当初はその複雑さを軽視したため、初期の実装は無駄に複雑になり、これはいかんと書き直す羽目になりました。また、データ構造を実装する上での指針、例えば「read と write のどちらを優先するか」「メモリ効率と速度のどちらを優先するか」「key-value pair を N 個含む skip list の最悪メモリ消費量は最大でもいくらになることを保証するのか」といったことをきっちり決めずに実装を始めてしまったので、途中で行ったりきたりしてしまい、無駄な作業や手戻りが生じました。
ある程度実装してみないと最適解が見えてこないしダラダラ実装するのは割と嫌いでは無いのですが、締切のある仕事だとそうも言ってはいられないので、事前になるべく広く洗い出しができるようになりたいと思いました(小並感)。
まとめ
アドベントカレンダー当日には間に合いませんでしたが、データ構造をちまちま考えて書いていくのはやはり楽しいので、今後も完成まで実装を続けてみようと思います。
自分にとっては初アドベントカレンダー参加となりました。Skip list についてはもちろん、記事の書き方などについてもコメントいただけると嬉しいです!
-
http://cglab.ca/~abeinges/blah/rust-btree-case/ に詳しい説明があります。 ↩
-
alloc::alloc::allocという名前の関数を使います。左から順にクレート名、モジュール名、関数名です。何がどうしてこうなった ↩
↩