はじめに
画像生成 Stable Diffusion を Web 上で簡単に使うことができる Stable Diffusion WebUI を Ubuntu のサーバーにインストールする方法を細かく解説します!また、日本語化の方法や、SDXLに対応したモデルのインストール方法、基本的な利用方法などをまとめましたー。わーわー。
Stable Diffusion WebUIとは?
画像生成AIである、Stable Diffusion WebUI を文字通り Web の UI で使うことができるやつ。 AUTOMATIC1111 版を使います!
MacBook Pro (m2搭載)でも動く!けど!
なにげに、MacBook Proでも動くので、ちょいちょい遊んで見たりはしてたんだけど・・・。画像生成に、結構時間がかかります。512x512 の画像で、最低限の設定とかでも 30秒 近く・・・。なんかいろいろ凝ろうとするともっとかかる。うーん。
サーバーで動かしたら早いのでは!?
と、いうわけで、サーバーで動かすことにしました!普通のサーバーじゃなくって、仮想通貨のマイニングとかにも使えるようなやつなら、画像もサクサク生成できるはず!
実際のサーバーがこれ!
なんか、めっちゃ縦に大きい気がする。よくわかんないけど。

上の分厚いのが、今回使ってるやつ・・・だと思う。
CPU: AMD Epyc 7443 (24Core/48Thread, 2.85GHz-4.0GHz)
GPU: 1 x NVIDIA RTX A6000 (48GB GDDR6)
RAM: 256GB DDR4-3200 ECC (32GBx8)
SSD: 6TB NVMe PCIe4x4 (2TB+4TB)
HDD: 384TB (16TBx24) DAS接続
LAN: 10GBASE-T
これがスペック。誰かの参考になれば幸い。
【PR】
ちなみに、このサーバーは、Innovation Farm 株式会社 さまのサーバーを使わせてもらっています!本来は企業向けにクラウドを提供したり、IoT機器の製造から量産までを一気通貫に行うサービスを提供している会社です!最近では、AIを活用した新規プロダクトの研究開発なども行っているとのこと!今回は特別に、個人でも使用させていただいています!わーわー。
インストールしてみよう!
とりあえず、 NVIDIA のドライバーと CUDA は、別アカウントで入れてあるとのことなので、まずは Anaconda からいれてみます!
Anaconda
まずは、公式サイトにアクセス
右上の Free Download を押して、

一番下までスクロールして、右側の Linux のとこにある「64-Bit (x86) Installer (1010.4 MB)」をダウンロードします。

ちなみに、自分は Anaconda3-2023.07-1-Linux-x86_64.sh でした!
サーバに転送
サーバに入ってファイルを置きます。GUIが楽ちんなので、SFTPでログインしてファイルを置きました。workフォルダ作っておくと後で楽だと思う。
インストーラーを実行
cd work
bash Anaconda3-2023.07-1-Linux-x86_64.sh
なんか、ライセンスが表示されるので、下を押して最後まで読んだら、yesで先に進みます。
Please answer 'yes' or 'no':'
>>> yes
そうすると、フォルダを聞かれます。とりあえずそのままでいいので ENTER
Anaconda3 will now be installed into this location:
/home/tono/anaconda3
- Press ENTER to confirm the location
- Press CTRL-C to abort the installation
- Or specify a different location below
しばらくするとこんなメッセージが!
done
installation finished.
Do you wish the installer to initialize Anaconda3
by running conda init? [yes|no]
[no] >>> yes
yes でおしまいです!
ターミナルの再起動
ここで一旦ターミナルを閉じて、再度サーバに接続します!
(じゃないと、condaコマンドが使えない)
pythonの環境を作る
続いて、Stable Diffusion WebUIのための環境を作っていきます。
何か聞かれたら y でいけます。
conda upgrade --all
conda clean --packages
conda create -n webui python=3.9
ここまで終わると、
# To activate this environment, use
#
# $ conda activate webui
#
# To deactivate an active environment, use
#
# $ conda deactivate
という感じで「conda activate webui」「conda deactivate」で webui 環境の切り替えができるようになります!
pytorchのインストール
どんどんいきましょう!
conda activate webui
conda install pytorch torchvision torchaudio pytorch-cuda=11.7 -c pytorch -c nvidia
まあまあ時間かかるけど、そのうちおわります!
tensorflowのインストール
環境は webui のまま続けます。
pip install tensorflow==2.8
こっちは結構時間かかる・・・けど、気長に待ちます。画面に動きがないのが辛い・・・。
WebUI(AUTOMATIC1111版)のインストール
やっとここまできた!まずは、 git でリポジトリから Clone します。
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git
そうすると stable-diffusion-webui というフォルダができるので、
13行目の
#export COMMANDLINE_ARGS=""
を、
export COMMANDLINE_ARGS="--listen"
に、変更します。これで、サーバに入れても、外部からアクセスできます!
ターミナルの再起動
ここで、またもやターミナルを閉じて、再度サーバに接続します!
動かしてみよう!
それでは、動かしてみましょう。インストールしたフォルダに移動して、シェルから起動します。
cd stable-diffusion-webui/
conda activate webui
./webui.sh
途中色々なエラーを出しながら、いろんなファイルをダウンロードしながら起動します。
初回は、めちゃくちゃ時間がかかるので、ここで一旦放置・・・。
なんか出てた
いつの間にか起動してたけど、
[notice] A new release of pip is available: 23.1.2 -> 23.2.1
[notice] To update, run: pip install --upgrade pip
がでてたので、 CTRL+C でプログラムの実行を止めた後に、
指示に従って update しました。結構長かった・・・。
動いた!
再度実行したら、
Running on local URL: http://0.0.0.0:7860
To create a public link, set `share=True` in `launch()`.
Startup time: 2.7s (import torch: 0.9s, import gradio: 0.4s, import ldm: 0.3s, other imports: 0.4s, load scripts: 0.2s, create ui: 0.4s).
Creating model from config: /home/tono/stable-diffusion-webui/configs/v1-inference.yaml
LatentDiffusion: Running in eps-prediction mode
DiffusionWrapper has 859.52 M params.
Applying attention optimization: Doggettx... done.
Textual inversion embeddings loaded(0):
Model loaded in 1.3s (load weights from disk: 0.6s, create model: 0.3s, apply weights to model: 0.2s, move model to device: 0.1s).
こんな感じの表示になって、動きが止まります。
IPアドレスが0.0.0.0になっていますが、これをサーバーのIPアドレスに変えてブラウザに打ち込むと・・・
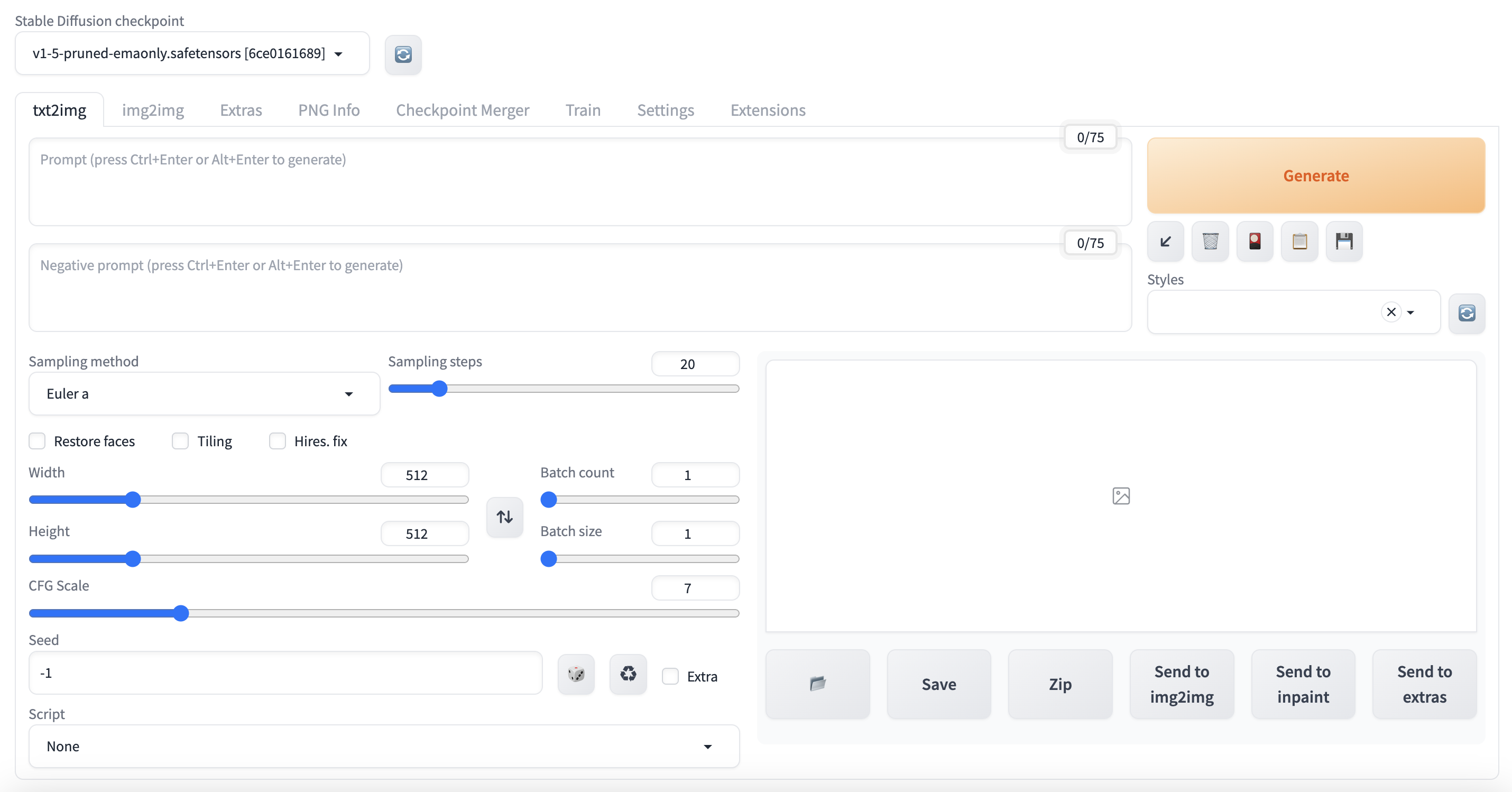
わーい。ブラウザで画像が生成できるようになりました!やった!
xformersを入れてみる
xformers いれてなかったので、
No module 'xformers'. Proceeding without it.
と表示されてました。なので、 xformers をいれてみます。
pip install -U xformers
次に、 webui-user.sh の COMMANDLINE_ARGS に追加します。
export COMMANDLINE_ARGS="--listen --xformers"
これで起動すると、初回にインストール処理が走って、xformers使うようになりました!やった!
Extensions を使ってみよう!
このままだと、Extensions が WebUI からインストールできないので、制限を解除します。
export COMMANDLINE_ARGS="--listen --xformers --enable-insecure-extension-access"
--listen オプションをつけると、外部から自由に使えちゃうので、 --enable-insecure-extension-access を付けないと、 Extensions が追加できなくなるみたいです。
日本語化する!
英語イマイチ苦手なので日本語化します。これのいいとこは、英語も併記してくれるとこ!
できた!
めっちゃわかりやすい!
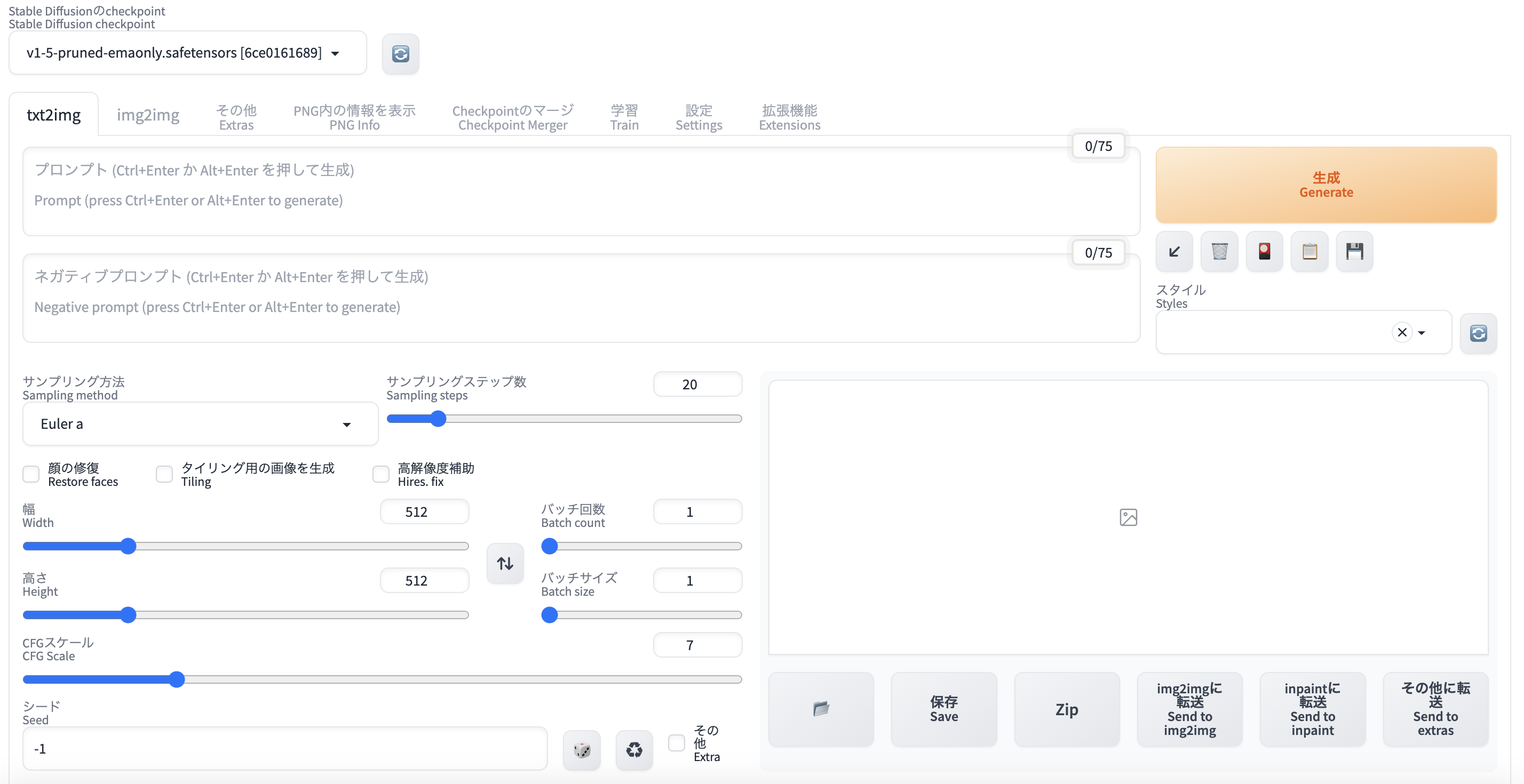
画像を生成してみる!
メモリがふんだんにあるので、サンプリングステップ数を 150 にしたりしても、画像サクサク画像が作れる!これはいいかんじ!
SDXL に対応してみる
ただ、このままだと従来のモデルしか使えないので、 SDXL に対応してみます。
SDXL ってなんだろう?
SDXL は、 Stable Diffusion XL の略で、従来( Stable Diffusion 1.5 )の Stable Diffusion の次世代モデルです。従来は 512x512 の画像で学習していたのですが、 SDXL 1.0 では 1024x1024 で学習しています。
大きな違いは、モデルが2個あることです。画像生成を base + refiner の 2 回に分けて処理することにより、従来より質感などが向上した画像が生成できるとのこと。
バージョン確認
Stable Diffusion WebUI のバージョン 1.5.0 から SDXL に対応しているとのことなので、バージョンを確認します。
# git log
commit f865d3e11647dfd6c7b2cdf90dde24680e58acd8 (HEAD -> master, tag: v1.4.1, origin/master, origin/HEAD)
なんか古いので、バージョンアップします。
# git pull
これで、最新になりました!

こんな感じで、 WebUI を起動すると、フッタにバージョンが出るので確認しましょう。
オプションの追加
ドキュメントを見ると
needs --no-half-vae commandline argument
と書いてあるので、 webui-user.sh の COMMANDLINE_ARGS に追加します。
export COMMANDLINE_ARGS="--listen --xformers --enable-insecure-extension-access --no-half-vae"
これで、 WebUI の設定は OK !
モデルのダウンロード
Hugging Face にあるモデルをダウンロード! base と refiner に分かれてるので、2個ダウンロードします。あと、 base モデルに対応した VAE も一緒にゲットします!
base モデル
sd_xl_base_1.0.safetensors
refiner モデル
sd_xl_refiner_1.0.safetensors
Vae
sdxl_vae.safetensors
Vae 適用済みモデル?!
civitai みたら、 Vae があらかじめ合体してあるモデルもあったので、そっちもダウンロードしてみました。全く同じなのかな。こっちの方が楽そう。
ファイルの配置
モデルは、 stable-diffusion-webui の中にある、 models/Stable-diffusion にコピーします。 VAE は、models\VAE にコピーします。
画像を生成してみよう!
公式ページの説明を見ると 128x128 で画像を生成しないとダメなように取れるのですが、普通に 1024x1024 で生成すればいいみたい!早速ためしてみます。
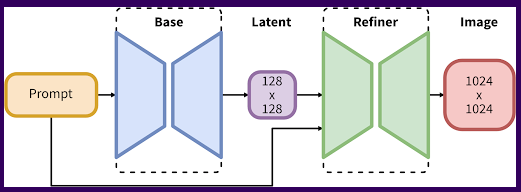
https://ja.stability.ai/blog/sdxl10 より引用
base モデルで画像を生成
まずは、 base モデルで画像を生成します。
設定はこんな感じ!
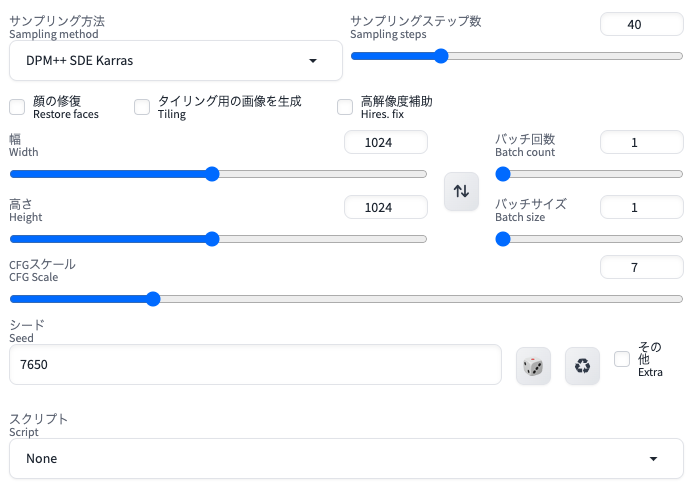
プロンプトは・・・
photo of robot playing a shooting game in game center
これで生成されたのが・・・

おー。なんかそれっぽい!
Vae ちゃんと使われてる?
ねんのため Vae が適用されてるか実験。
設定を見ると Automatic だから大丈夫なはず!

でもまあ、いちおうファイル名指定

じゃーん。同じ気がする!

Civital の方もやってみよう
Vae の設定を Automatic に戻したあと、モデルを変更
結果は・・・

同じだ!
refiner モデルを適用してみよう!
2ステップ目は、自分でやらないとダメっぽい。ちょっとめんどいけど base モデルで作った画像を、 img2img の元イメージに設定すればいいみたい。
あとは、モデルを refiner に変更!

ノイズ除去強度を 低く設定しないとダメっぽい 0.3 が良いみたいなので設定。

これで生成ボタンを押すと・・・
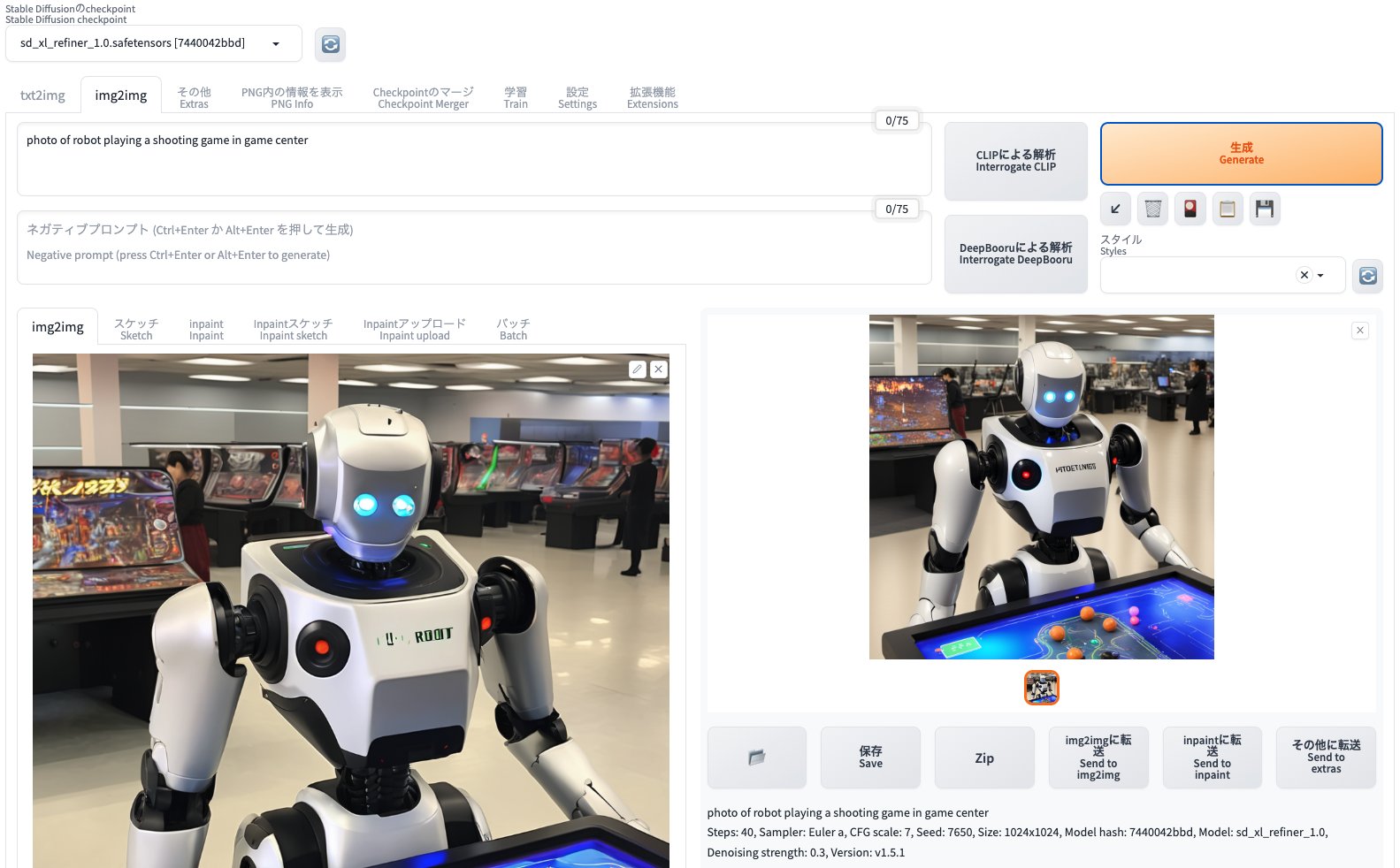
こんな感じで、元の画像を綺麗にしてくれた!

なんか、左上のゲームはよくなったけど、右の背景はゲーセン感が消えて工場みたいに・・・。ロボットも頭が違うし。胸の文字変わってるし。
でも、全体的に書き込みが上がってる気がする。ゲーム版の上のコマがミカンみたいになってるけど・・・。
シード固定をやめてみる
よく考えたら、ここでもシードが影響することに気がついたので、シード固定をやめて幾つか生成してみました。

できたのはこんな感じ!(元の解像度だとファイルサイズが大きすぎて Qiita にアップできなかったので、 Photoshop で解像度半分にしてます)
どれも綺麗に生成されてるけど、細部の書き込みが違うので、この辺はガチャなのかも!
おまけ
プロンプトに 「photo of」 って書いたから写真ぽくなったけど、他もいけるのかやってみた!
manga of robot playing a shooting game in game center
漫画風
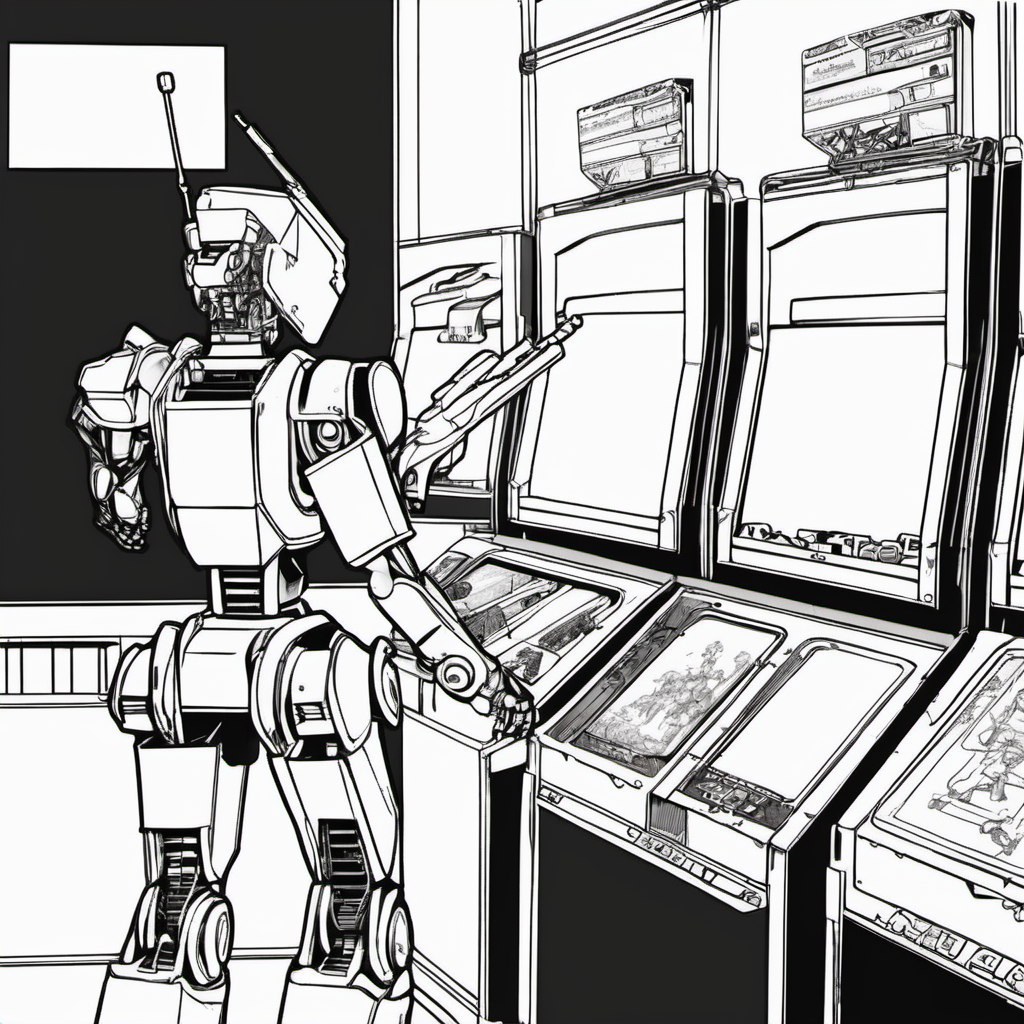
illust of robot playing a shooting game in game center
イラスト風

anime of robot playing a shooting game in game center
アニメ風

めんどいから refiner はしてないけどいい感じ!
おまけ2
まちがえて refiner で txt2img やったら、いい感じの画像出た!これはこれで使えるのかも!?
manga of robot playing a shooting game in game center
漫画風

まとめ
・Stable Diffusion WebUI を使うと、簡単に画像生成できる!
・プロンプト短くてもいい感じになる
・色んな絵柄にも対応してるっぽい
・SDXLすごい!
・わーわー