今すぐ「レイヤードアーキテクチャ+DDD」を理解しよう。(golang)
とはいっても記事を読み終わるのに三時間くらいかかる気がします。
対象読者
- レイヤードアーキテクチャ+DDDの実装に困っている方
- バックエンドエンジニアを目指す学生
- APIサーバを開発したことがある方
はじめに
アーキテクチャは学習コストが高いと言われています。その要因の一つとして考えられるのはアーキテクチャの概念を学んだとしても、アーキテクチャの細かい部分は実装者に左右されるので、ネット上にあるプログラムは概念とはズレがあるので混乱しやすいことだと思います。それに加えて他のサイトを参考にした時もやはり実装者による違いで混乱してしまうからです。
したがって、概念とズレがある部分はしっかり言及したうえで解説することが良いと思います。
アーキテクチャを採用する意味
- レイヤ間が疎結合になるため、ユニットテストが行いやすいこと。
- 責務がはっきりしているので、保守性が高いこと。
- 途中からフレームワーク等を入れたとしても影響範囲が限定されるので外部の技術の変更が容易なこと。
レイヤードアーキテクチャとは
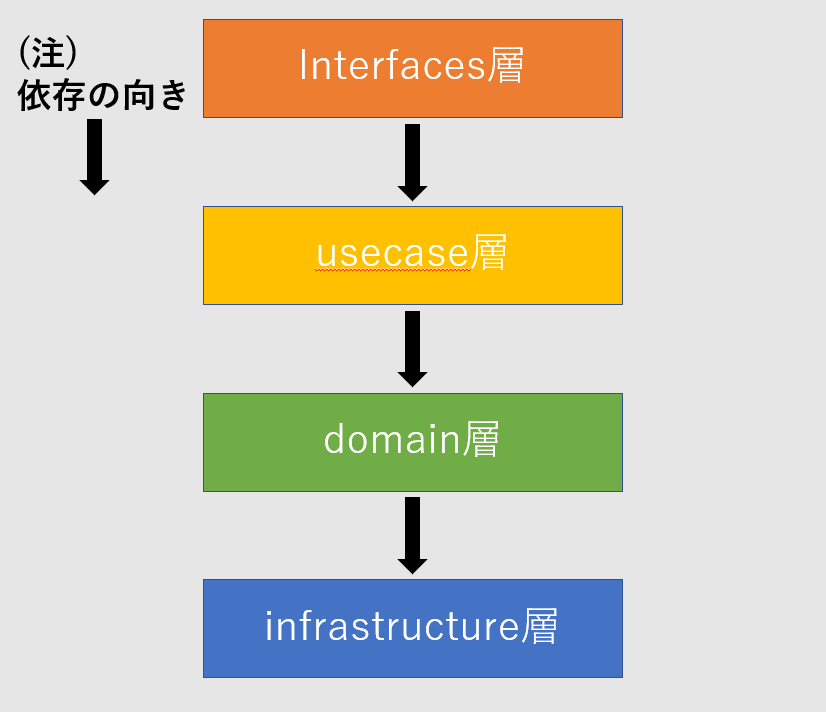 レイヤードアーキテクチャは図のようにレイヤを上下で表現します。上位のレイヤは下位のレイヤに依存するのが特徴です。図では直下のレイヤにのみ依存していますが、上位のレイヤが下位のレイヤに依存していれば、直下でなくてもOKです。例えば、usecase層がinfrastructure層に依存するケースやinterfaces層がdomain層に依存している場合があります。基本的にアーキテクチャを導入すると依存関係を守るために冗長化をする必要がありますが、小規模でそれほど複雑でない時や、チームで話し合って、冗長化することによるメリットよりもコードをシンプルにした方がいいという結論に至れば一つ飛ばしの層に依存しても問題はありません。
レイヤードアーキテクチャは図のようにレイヤを上下で表現します。上位のレイヤは下位のレイヤに依存するのが特徴です。図では直下のレイヤにのみ依存していますが、上位のレイヤが下位のレイヤに依存していれば、直下でなくてもOKです。例えば、usecase層がinfrastructure層に依存するケースやinterfaces層がdomain層に依存している場合があります。基本的にアーキテクチャを導入すると依存関係を守るために冗長化をする必要がありますが、小規模でそれほど複雑でない時や、チームで話し合って、冗長化することによるメリットよりもコードをシンプルにした方がいいという結論に至れば一つ飛ばしの層に依存しても問題はありません。
DDD(domain driven design)とは
こちらの記事を参考に理解を深めてください。
レイヤードアーキテクチャにドメイン駆動設計の考えを取り込むと次の図のような依存関係になります。
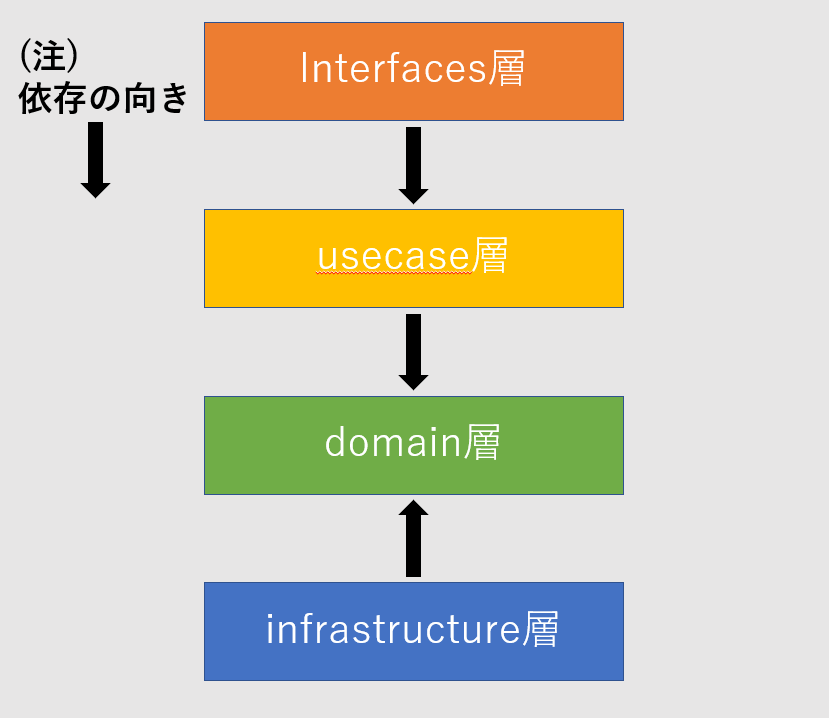
純粋なレイヤードアーキテクチャと違う点はdomainとinfrastructureの依存関係が逆になっていることです。
ここでは説明を省きますが、もっと知りたければエリック・エヴァンス氏の書籍ドメイン駆動設計を読むことをおすすめします。
前置きはこのくらいにして、以降はコードベースで解説していきます。
ディレクトリ構成
レイヤードアーキテクチャの層は本来は一番上から、
Presentation → Application → Domain → Infrastructure
という名前が付いていますが責務のイメージが浮かびずらいと思うので今回は
Interfaces → Usecase → Domain → Infrastructure
という名前で進めさせていただきます。
LayeredArchitecture
├── cmd
│ └── api
│ └── main.go
├── domain
│ └── repository
| | └── user_repository.go
| └── user.go
├── config //DBの起動など
│ └── database.go
├── interfaces
│ └── handler
│ | └── user.go
| └── response
│ └── response.go
├── infrastructure
│ └── persistence
│ └── user.go
└── usecase
└── user.go
domain層

domain層はドメインロジックを実装する責務を持ちます。ドメインロジックに関してはこちらの資料を参考にしてください。domain層はDBアクセスなどの技術的な実装は持たず、それらはinfrastructure層が担当します。
package domain
type User struct {
UserID string
Name string
Email string
}
続いてリポジトリの実装です。
package repository
import (
"database/sql"
"LayeredArchitecture/domain"
)
type UserRepository interface {
Insert(DB *sql.DB, userID, name, email string) error
GetByUserID(DB *sql.DB, userID string) (*domain.User, error)
}
domain層はどの層にも依存しないのでこの層だけで完結します。
infrastructure層
 infrastructure層は、DBアクセスなどの技術的関心を記述します。この層はdomain層に依存しています。純粋なレイヤードアーキテクチャの場合、依存の向きがdomain → infrastructureですが、今回はDDDを取り込んだ設計になるので、依存の向きが逆転します。そのためinfrastructure層はdomain層のrepositoryで定義したインタフェースを実装します。
infrastructure層は、DBアクセスなどの技術的関心を記述します。この層はdomain層に依存しています。純粋なレイヤードアーキテクチャの場合、依存の向きがdomain → infrastructureですが、今回はDDDを取り込んだ設計になるので、依存の向きが逆転します。そのためinfrastructure層はdomain層のrepositoryで定義したインタフェースを実装します。
package persistence
import (
"LayeredArchitecture/domain"
"LayeredArchitecture/domain/repository"
"database/sql"
)
type userPersistence struct{}
func NewUserPersistence() repository.UserRepository {
return &userPersistence{}
}
//ユーザ登録
func (up userPersistence) Insert(DB *sql.DB, userID, name, email string) error {
stmt, err := DB.Prepare("INSERT INTO user(user_id, name, email) VALUES(?, ?, ?)")
if err != nil {
return err
}
_, err = stmt.Exec(userID, name, email)
return err
}
//userIDによってユーザ情報を取得する
func (up userPersistence) GetByUserID(DB *sql.DB, userID string) (*domain.User, error) {
row := DB.QueryRow("SELECT * FROM user WHERE user_id = ?", userID)
//row型をgolangで利用できる形にキャストする。
return convertToUser(row)
}
//row型をuser型に紐づける
func convertToUser(row *sql.Row) (*domain.User, error) {
user := domain.User{}
err := row.Scan(&user.UserID, &user.Name, &user.Email)
if err != nil {
if err == sql.ErrNoRows {
return nil, nil
}
return nil, err
}
return &user, nil
}
domain層で定義したGetByUserIDとInsert関数の引数や返り値を満たしながら中身を実装しているので確かにinfrastructure層がdomain層に依存しています。実はこの手法は**DIP(依存性逆転の原則)**といいます。golangでつまずく人が多いinterface(interfaces層とは全くの別物)というものを使って実体を抽象に依存させることで依存性を逆転しています。ここでいう抽象とは名前、引数、返り値だけ決まっている関数のことで、実体とは、その関数の具体的な処理内容のことです。
interfaceが全く分からないという方はこちらの記事を参考に、ある程度分かってきたらこちらの記事を参考にしてください。
interfaceに慣れる
interfaceになれている方は読み飛ばしていただいて結構です。
interfaceになれていない方はおそらく以下の部分で混乱してしまうと思うので補足説明しておきます。
type userPersistence struct{}
func NewUserPersistence() repository.UserRepository {
return &userPersistence{}
}
NewUserPersistence()の返り値がrepository.UserRepository型になっています。interfaceを理解していない方はここでつまずくのではないでしょうか。「返り値はUserRepositoryなのに、返却しているのがuserPersistence型?」と思ってしまいますよね。
これが許される理由は、interfaceであるUserRepositoryを満たすようにuserPersistenceを実装しているからです。どういうことかというと、
①UserRepositoryはGetByUserIDとInsert関数を持っている。(関数名、引数、返り値だけ決まっている)
②userPersistenceをレシーバに持つGetByUserIDとInsert関数(関数名、引数、返り値がUserRepositoryで指定されているものと同じ)を実装する。
③userPersistenceがinterfaceのUserRepositoryを満たしていることになる。
④interfaceの性質上、型(今回に関してはレシーバの型)は不問。
⑤返り値はUserRepositoryというinterfaceなのでそれを満たしているので返り値として満たされる。
という事になります。そのため、userPersistenceをレシーバに持つUserRepositoryで定義した関数を満たしている必要があります。その実装がこのコードより下の部分で行っています。
純粋なレイヤードアーキテクチャの場合
ここで、「じゃあ純粋なレイヤードアーキテクチャの場合はどのように依存関係をdomain層 → infrastructure層にしているの?」と疑問をもつ方のためにDDDの概念を持ち込まない純粋なレイヤードアーキテクチャの実装も載せておきます。
方針としては、infrastructure層にdomainのモデルと同じ構造体を用意することです。DDDを採用しようがしまいが各レイヤの責務は変わらないのでinfrastructureはDBアクセスの技術的な関心事を記述します。しかし、domainで定義されたモデルを扱うことができないのでDTOを利用します。DTOに関してはこちらの記事が分かりやすかったので参考にしてください。今回の場合は依存関係を保つためにDTOを利用するという形になっています。解説はGetByUserIDについてのみになります。
package infrastructure
import "database/sql"
type UserDTO struct {
UserID string
Name string
Email string
}
//ユーザ情報を取得
func GetByUserID(DB *sql.DB, userID string) (*UserDTO, error) {
//DB にアクセスするロジック
row := DB.QueryRow("SELECT * FROM user WHERE user_id=?", userID)
return convertToUser(row)
}
//row型をuserDTO型に紐づける
func convertToUser(row *sql.Row) (*UserDTO, error) {
userDTO := UserDTO{}
err := row.Scan(&userDTO.UserID, &userDTO.Name, &userDTO.Email)
if err != nil {
if err == sql.ErrNoRows {
return nil, nil
}
return nil, err
}
return &userDTO, nil
}
infrastructure層でentityを扱うことになるので、User構造体を利用したいですが、それではdomainに依存してしまうので中身が全く同じのUserDTOという構造体を定義し、domain層にUser構造体に紐づける処理を加えます。そのため、domain層の実装は次のようになります。
package domain
import (
"LayeredArchitecture/infrastructure"
"database/sql"
)
type User struct {
UserID string
Name string
Email string
}
func GetUserByID(DB *sql.DB, userID string) (*User, error) {
//インフラストラクチャレイヤの実装を利⽤する。
userDTO, err := infrastructure.GetUserByID(DB, userID)
if err != nil {
return nil, err
}
user := &User{
UserID: userDTO.UserID,
Name : userDTO.Name,
Email : userDTO.Email
}
return user, nil
}
依存関係を実装に落とし込むことができていない人はこのあたりでつまずくと思ったので詳しく解説しました。以降は話をレイヤードアーキテクチャ+DDDに戻します。
usecase層
 usecase層の責務はinterfaces層から情報を受け取り、domain層で定義してある関数を用いて任意のビジネスロジックを実行することです。
usecase層の責務はinterfaces層から情報を受け取り、domain層で定義してある関数を用いて任意のビジネスロジックを実行することです。
package usecase
import (
"database/sql"
"errors"
"github.com/google/uuid"
"LayeredArchitecture/domain"
"LayeredArchitecture/domain/repository"
)
// User における UseCase のインターフェース
type UserUseCase interface {
GetByUesrID(DB *sql.DB, userID string) (domain.User, error)
Insert(DB *sql.DB, userID, name, email string) error
}
type userUseCase struct {
userRepository repository.UserRepository
}
// Userデータに対するusecaseを生成
func NewUserUseCase(ur repository.UserRepository) UserUseCase {
return &userUseCase{
userRepository: ur,
}
}
func (uu UserUsecase) GetByUserID(DB *sql.DB, userID string) (*domain.User, error) {
user, err := uu.userRepository.GetByUserID(DB, userID)
if err != nil {
return nil, err
}
return user, nil
}
func (uu UserUsecase) Insert(DB *sql.DB, name, email string) error {
//本来ならemailのバリデーションをする
//一意でランダムな文字列を生成する
userID, err := uuid.NewRandom()//返り値はuuid型
if err != nil {
return err
}
//domainを介してinfrastructureで実装した関数を呼び出す。
// Persistence(Repository)を呼出
err = uu.userRepository.Insert(DB, userID.String(), name, email)
if err != nil {
return err
}
return nil
}
このように、usecase層はバリデーション、ユーザIDの生成などのビジネスロジックを記述したり、infrastructure層で実装したDBアクセスに関する処理をdomain層を介して間接的に呼んだりします。ここに関してはイメージがしずらいと思います。「実際に利用するのはinfrastructure層の具体的な内容が実装されている関数だから結局usecase層はinfrastructure層に依存するんじゃないの?」と思う人が多いと思います。
そこで先ほどから出てきているNewXxxXxxやここでもUserUsecaseでinterfaceを定義していることによって間接的に呼びだしているように実装できるんです。アーキテクチャの話をするとよく聞くDI(依存性の注入)というものに利用します。それらについては後で説明します。
interfaces層
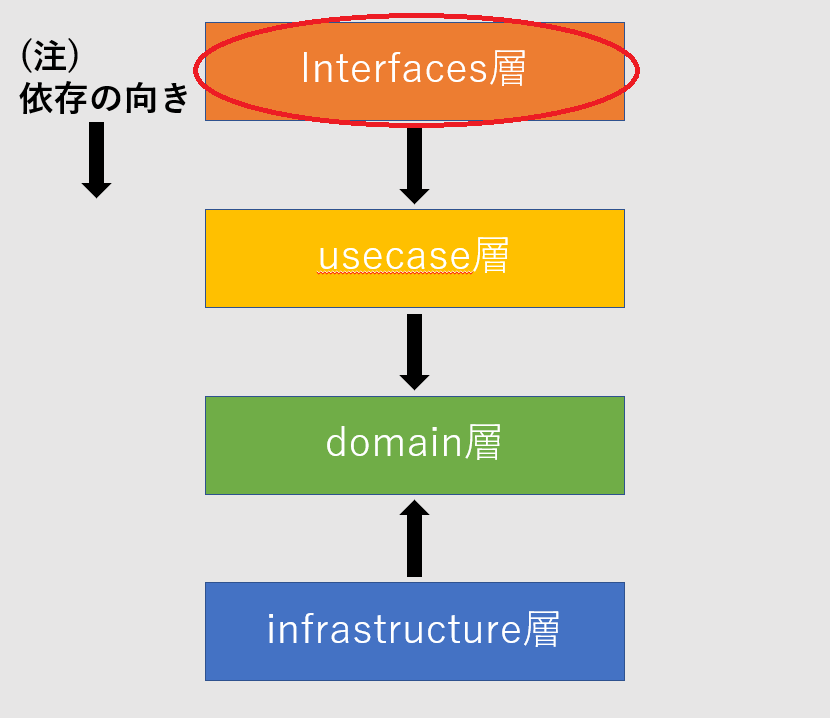 今回実装したinterfaces層の責務は、HTTPリクエストを受け取り、UseCaseを使って処理を行い、結果をクライアントに返したり、サーバのログに出力することです。今回はレイヤの責務がイメージしやすいようにHTTPリクエストに限定していますが、外部データとの差異を吸収してusecaseに渡し、結果を返却する役割を担うのがこの層の役割です。
今回実装したinterfaces層の責務は、HTTPリクエストを受け取り、UseCaseを使って処理を行い、結果をクライアントに返したり、サーバのログに出力することです。今回はレイヤの責務がイメージしやすいようにHTTPリクエストに限定していますが、外部データとの差異を吸収してusecaseに渡し、結果を返却する役割を担うのがこの層の役割です。
package interfaces
import (
"LayeredArchitecture/config"
"LayeredArchitecture/interfaces/response"
"LayeredArchitecture/usecase"
"encoding/json"
"io/ioutil"
"log"
"net/http"
"github.com/julienschmidt/httprouter"
)
// Userに対するHandlerのインターフェース
type UserHandler interface {
HandleUserGet(http.ResponseWriter, *http.Request, httprouter.Params)
HandleUserSignup(http.ResponseWriter, *http.Request, httprouter.Params)
}
type userHandler struct {
userUseCase usecase.UserUseCase
}
//Userデータに関するHandlerを生成
func NewUserHandler(uu usecase.UserUseCase) UserHandler {
return &userHandler{
userUseCase: uu,
}
}
//ユーザ情報取得
func (uh userHandler) HandleUserGet(writer http.ResponseWriter, request *http.Request, _ httprouter.Params) {
// Contextから認証済みのユーザIDを取得
ctx := request.Context()
userID := dddcontext.GetUserIDFromContext(ctx)
//usecaseレイヤを操作して、ユーザデータ取得
user, err := usecase.UserUsecase{}.SelectByPrimaryKey(config.DB, userID)
if err != nil {
response.Error(writer, http.StatusInternalServerError, err, "Internal Server Error")
return
}
//レスポンスに必要な情報を詰めて返却
response.JSON(writer, http.StatusOK, user)
}
// ユーザ新規登録
func (uh userHandler) HandleUserSignup(writer http.ResponseWriter, request *http.Request, _ httprouter.Params) {
//リクエストボディを取得
body, err := ioutil.ReadAll(request.Body)
if err != nil {
response.Error(writer, http.StatusBadRequest, err, "Invalid Request Body")
return
}
//リクエストボディのパース
var requestBody userSignupRequest
json.Unmarshal(body, &requestBody)
//usecaseの呼び出し
err = usecase.UserUsecase{}.Insert(config.DB, requestBody.Name, requestBody.Email)
if err != nil {
response.Error(writer, http.StatusInternalServerError, err, "Internal Server Error")
return
}
// レスポンスに必要な情報を詰めて返却
response.JSON(writer, http.StatusOK, "")
}
HTTPリクエストのリクエストボディや、ヘッダーから情報を取得し、そのデータをusecaseで扱うデータ型にキャストして渡しています。そして、usecaseの処理結果をサーバ出力やクライアントへ返却しています。
ユーザ情報取得のAPIでアーキテクチャを説明すると、userIDを取得する部分など、余計な部分で実装が複雑になるので、よく紹介されているのはInsertやGetAllみたいな関数ですね。わかりずらい例を挙げてしまい申し訳ございません。
//Contextから認証済みのユーザIDを取得という部分について
今回はコンテキストにユーザIDをセットするまでの流れは省いていますが一応説明しておきます。この部分はアーキテクチャの部分とは関係ないので読みとばしていただいて結構です。
本来ならmiddlewareを実装しmiddleware(HandleUserGet())のようにミドルウェアを挟んでmiddleware内でクライアント側から送られてきた認証トークンからアクセスしたユーザIDを特定する操作をし、コンテキストに入れます。middlewareはinterfaces層で実装するのが良いと思います。
responseパッケージについて
内容は省略しますが、レスポンスなのでパッケージはinterfaces層にあり、サーバにログ出力する部分と、クライアントへステータスコードとレスポンスメッセージを返却する関数を定義しています。
configパッケージについて
DBの初期化などの部分を実装しています。今回扱っているDBという変数はこの中で初期化しています。
main.go
ここではサーバの起動やルーティング、usecaseの時に後ほど説明すると述べたDI(依存性の注入)を行います。
package main
import (
"fmt"
"log"
"net/http"
"github.com/julienschmidt/httprouter"
"LayeredArchitecture/interfaces/handler"
"LayeredArchitecture/infrastructure/persistence"
"LayeredArchitecture/usecase"
)
func main() {
// 依存関係を注入(DI まではいきませんが一応注入っぽいことをしてる)
userPersistence := persistence.NewUserPersistence()
userUseCase := usecase.NewUserUseCase(userPersistence)
userHandler := handler.NewUserHandler(userUseCase)
//ルーティングの設定
router := httprouter.New()
router.GET("/api/v2/get", userHandler.HandleUserGet)
router.POST("/api/v2/signup", userHandler.HandleUserSignup)
// サーバ起動
fmt.Println("Server Running at http://localhost:8080")
log.Fatal(http.ListenAndServe(":8080", router))
}
main関数の一番最初の三行で、依存関係を注入しています。
①DBアクセスの実体を持っていたuserPersistence(repository.UserRepositoryを満たす)を生成する。
②そのuserPersistenceをusecase層のuserUsecase(repository.UserRepositoryをフィールドに持つ)に注入する。
③生成したuserUsecaseをuserHandler(userUsecaseをフィールドに持つ)に注入する
こうすることで、各レイヤの依存関係を守ることができ、かつそれぞれの責務を果たすことができます。
規模が小さいと冗長化するメリットがあまりわからないと思いますが、アーキテクチャを意識することはとても大事だと思うのでぜひ取り組んでみてください。
最後に
今回はエラーハンドリングの部分は雑にやってしまったので参考にはしないほうがいいと思います。
この記事を作成するにあたって参考にしたサイトはこちらです。
①【Golang + レイヤードアーキテクチャ】DDD を意識して Web API を実装してみる
②githubのリポジトリ
個人的には①のサイトがめちゃくちゃわかりやすかったです。
まだまだ甘い部分があると思うので、アーキテクチャについてはもっと深堀りして、自分でケースに合ったアーキテクチャを採用できるくらいになりたいと思います。