はじめに
Qiita初投稿!!
今回、プログラミング初心者である私はSIGNATEで行われているコンペに初挑戦することにしました。
挑戦したコンペは、【練習問題】都市サイクルの燃料消費量予測です。
コンペの概要
車の情報を元に、燃料消費量を予測します。
課題種別:回帰
データ種別:多変量
学習データサンプル数:199
説明変数の数:9
欠損値:あり
与えられたデータ
- 学習用データ(train.tsv)
- 評価用データ(test.tsv)
- 応募用サンプルファイル(sample_submit.csv)
| カラム名 | 説明 | データ型 |
|---|---|---|
| id | インデックス | int |
| mpg | 燃料消費量 | int |
| cylinders | シリンダー | int |
| displacement | 変位 | int |
| horsepower | 馬力(一部欠損) | int |
| weight | 重量 | int |
| acceleration | 加速 | float |
| model year | モデル年 | int |
| origin | 起源 | int |
| car name | 車名 | varchar |
実践
早速実践です!
- 環境:google colab
データの読み込み
SIGNATEにはデータを直接ダウンロードすることなくできる便利な機能「SIGNATE CLI」というものがあったため、こちらを使いました。
参照
- https://pypi.org/project/signate/
- https://qiita.com/john-rocky/items/dd2b7f4cd8e655a5376b#5signate%E3%81%A7%E3%82%84%E3%81%A3%E3%81%A6%E3%81%84%E3%82%8B%E3%82%B3%E3%83%B3%E3%83%9A%E3%81%AE%E4%B8%80%E8%A6%A7%E3%82%92%E5%8F%96%E5%BE%97
- https://qiita.com/insilicomab/items/d757339d97b44feaff01
上記を参照したため、この章は省略します。
また、各種ライブラリの読み込みはここでは省略することにします。
欠損値の処理
データの説明にもある通り、horsepowerに欠損値があることを確認します。
trainデータ
train.info()
と実行すると
RangeIndex: 199 entries, 0 to 198
Data columns (total 10 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Unnamed: 0 199 non-null int64
1 mpg 199 non-null float64
2 cylinders 199 non-null int64
3 displacement 199 non-null float64
4 horsepower 199 non-null object
5 weight 199 non-null int64
6 acceleration 199 non-null float64
7 model year 199 non-null int64
8 origin 199 non-null int64
9 car name 199 non-null object
と表示されます。
一見、欠損値がないようにも見えますが、コンペテーブルには
欠損箇所は文字列"?"で表記されています
と書かれていました!
では?はあるのか確認してみましょう。
train.isin(['?']).sum()
を実行してみると、
Unnamed: 0 0
mpg 0
cylinders 0
displacement 0
horsepower 3
weight 0
acceleration 0
model year 0
origin 0
car name 0
dtype: int64
たしかにありました!
では、この欠損値をどの値で埋めるか考えるべく、horsepowerの分布を見てみることにします。
horsepowerはobject型のようなので、どの文字列が頻出しているのかSeries型でみてみましょう。
train['horsepower'].value_counts(ascending = False)
88 11
110 11
100 10
90 9
97 8
..
125 1
138 1
153 1
82 1
137 1
Name: horsepower, Length: 72, dtype: int64
頻出度を降順(大きい順)にし、上からみてみると88と110が11回、100が10回登場していることがわかります。
今回は88で欠損値を埋めることにします。
# まず?をNaNに変換
train.replace('?', np.nan, inplace = True)
# 88で欠損値を埋める
train['horsepower'].fillna('88', inplace = True)
最後に欠損値がなくなったか確認します。
train.isnull().sum()
Unnamed: 0 0
mpg 0
cylinders 0
displacement 0
horsepower 0
weight 0
acceleration 0
model year 0
origin 0
car name 0
dtype: int64
無事欠損値の処理が終わりました。
testデータ
trainデータと同様の作業を行なうため、省略します。
データの可視化
今回のコンペでは、
- 説明変数:mpg
- 目的変数:その他
となります。
従って、mpgと相関関係が強い変数を探すため、ヒートマップを作成することにします。
sns.heatmap(train.corr(), annot = True, cmap = 'bwr', linewidths = 0.2);
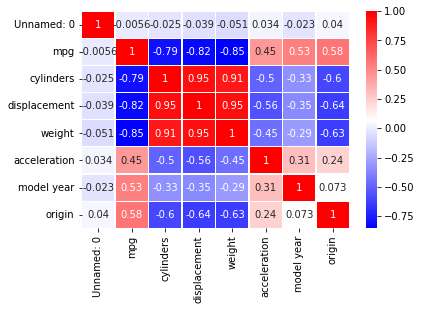
このような結果となりました。
mpgと高い相関がある変数は
- cylinders
- displacement
- weight
であることがわかります。
この変数を使って学習をするとよいのでしょうか。
しかしよくみると、
これらの変数は相互に高い相関関係にあります。
つまり、このまま使うと多重共線性が発生する可能性があります。
※多重共線性については、以下を参照いただきたい
https://www.ydc.co.jp/column/mi/mieruka04.html
従って、ここではmpgと最も相関が大きいweightのみに変数を絞ることにします。
機械学習
いよいよ機械学習の実装です。
今回は回帰問題であるため、LinearRegressionを用いることにします。
# trainデータをmpgとweightのみにする
train1 = train[['mpg', 'weight']]
X = train1.drop('mpg', axis = 1)
y = train1['mpg']
# 学習データとテストデータに分割
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5, random_state=0)
# モデルの作成
model = LinearRegression()
# 学習
model.fit(X_train, y_train)
# 評価
print('決定係数(train):{:.3f}'.format(model.score(X_train, y_train)))
print('決定係数(test):{:.3f}'.format(model.score(X_test, y_test)))
決定係数(train):0.671
決定係数(test):0.767
テストデータのほうがスコアが高いため、過学習は起きていないと思われます。
最後に回帰曲線がどのようになったか示してみます。
print('\n回帰係数\n{}'.format(pd.Series(model.coef_, index=X.columns)))
print('切片: {:.3f}'.format(model.intercept_))
回帰係数
weight -0.007107
dtype: float64
切片: 44.725
mgh = 44.725 - 0.007107 * weight
のような式になったことがわかりました。
提出
最後にサンプルファイルを参考に、提出用にデータを加工していきます。
実は、私自身ここでかなり手こずりました(°ー°〃)
まずテストデータのweightを用いて、mgtを予測します。
# テストデータからweightを取り出す
X_test = test[['weight']].values
# 予測データをpredictに格納
predict = model.predict(X_test)
# テストデータにpredictを追加
test['mpg'] = predict
# 提出するファイル用に、Unnamed: 0(id)とmpg(予測)のみを取り出す
sub = test[['Unnamed: 0', 'mpg']]
ここでサンプルファイルを見てみます。
1 40.9
0 2 28.8
1 4 11.0
2 5 19.4
3 6 14.0
4 7 32.9
... ... ...
193 391 20.5
194 392 16.0
195 393 18.2
196 394 37.2
197 397 38.0
198 rows × 2 columns
- ヘッダーなし
- mpgは小数第一位まで(コンペの説明文にはmpgはint型と書いてありましたが、intにするとなぜかエラーになったため)
- インデックスなし(Unnamed: 0をidとして用いるため)
以上の点に気を付けて加工を行います。
# 小数第一位までに丸める
sub = sub.round(1)
# csvに変換(インデックスなし、ヘッダーなし)
sub.to_csv('mpg.csv', index = False, header = None)
これで提出用のファイルが完成しました。
ちなみに、提出した結果はかなり悪かったです。
下から数えたほうが早い順位でした≡(▔﹏▔)≡
参照
https://www.kaggle.com/katotaka/kaggle-prediction-house-prices
37行目あたりからかなり参照させていただきました。
反省(備忘録)
- 特徴量の意味をしっかり捉える必要がある
- ドメイン知識がかなり重要
- 新たな変数を作ってもよかった
SIGNATEは日本の分析コンペプラットフォームであるため、kaggleよりは初心者の私でも気軽に取り組むことができました。
これからも勉強しつつ、コンペに参加し、そのアウトプットとしてこのqiitaに記録していこうと思います。
最後までお読みいただきありがとうございました。