SettingWithCopyWarning:ってのをよく見かけるので調べました。
こちらの記事をご覧いただきありがとうございます。
機械学習を始めておよそ3カ月の私が、データをこねくり回すときにやたら出てくる「SettingWithCopyWarning:」ってやつが気になったので調べました。
自分が調べたことを後で確認するために記事を書きますが、ご覧いただいた皆様にも学びがあれば幸いです。もしくは内容に間違いなどあればぜひご指摘ください。私の勉強になります。
どんな警告?
警告を再現します。検証用の適当なデータを用意します。
a = np.arange(100).reshape(10,10)
df = pd.DataFrame(a)
df.columns = ['a','b','c','d','e','f','g','h','i','j']
生成されるデータ
このデータの、「e列が50以下」の「f列」のデータを「2倍」にしたいとします。こういった特定の条件を満たすデータを書き換える作業はそれなりにあると思います。
まずは「e列が50以下」を表示します。
df.query('e <= 50')
e <= 50 の条件を満たすデータ
これをf列だけ取り出します。
df.query('e <= 50')['f']
eが50以下のf列

これの値を2倍にします。
※後で気が付きましたが、mapじゃなくて*2でもOKです。わざわざ面倒なことしなくて大丈夫です。
df.query('e <= 50')['f'].map(lambda x: x*2)
eが50以下のf列を2倍

この値を使って、「e列が50以下」の「f列」のデータを「2倍」に書き換えます。
df.query('e <= 50')['f']=df.query('e <= 50')['f'].map(lambda x: x*2)
「e列が50以下」の「f列」のデータを「2倍」に書き換えると…

でました。SettingWithCopyWarningです。
警告だけなら良いのですが、中身が書き換わっていません。何の意味もないですね。これに気が付かずに作業を進めると数時間がパアになるなんてこともありそう…?
どういう時に起こるの?対策は?
私自身が経験則的に、データの情報を参照してデータの書き換え(上書き?)をしようとしたときに良く起こる印象でした。例えば、欠損値を他のデータでとった平均値で埋めようと思った時とか、一度欠損値のあるデータを無視して他のデータだけ操作しようと思ったときとか…。
SettingWithCopyWarningの発生する条件を調べていたら、やはり上書きをするときに良くないやり方をしていると起こるようです。
その良くない書き方と解決手段を一緒に紹介します。
上が警告のでる書き方、下が警告の出ない書き方です。比較のため並べて書きます。
df.query('e <= 50')['f']=df.query('e <= 50')['f'].map(lambda x: x*2)
df.loc[df['e']<=50,'f'] = df.loc[df['e']<=50,'f'].map(lambda x: x*2)
警告が出るパターン
警告が出ないパターン
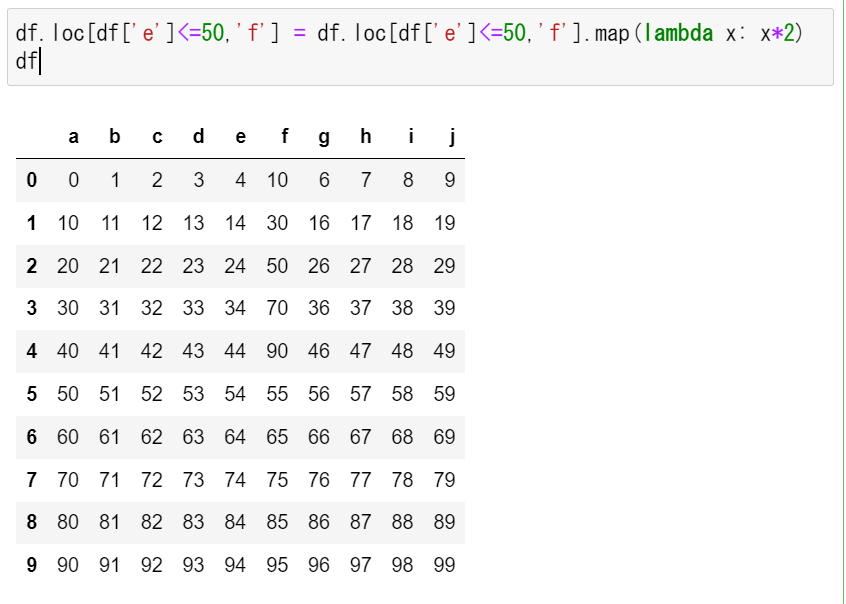
警告が出ないパターンでは、ちゃんとデータも書き換わっています。
警告が出るパターンと出ないパターンでは、条件を満たすセルの参照の仕方に違いがあります。
- 警告が出る :
.query('e <= 50')['f'] - 警告が出ない:
.loc[df['e']<=50,'f']
警告が出ると出ないの違いは参照の連鎖がある(Chained Indexing って言うらしいです)かどうかのようです。参照を複数回繰り返すと警告が出て、参照を1回で済ませると警告が出ないようです。
警告が出る書き方は、.query('e <= 50')で「e列が50以下」を、['f']で「f列」を参照しています。参照を2回に分けて行う 点が良くないようです。
警告が出ない書き方では、.loc[df['e']<=50,'f']によって「e列が50以下のf列」を参照、つまり 複数の条件を1回で同時に 参照しています。
警告の内容にも書いてあったように、.locによって書き換えたいセルを直接参照すれば、警告が出ずにうまく書き換えられるようですね。
ちなみに、書き換えたいセルを複数の参照で呼び出すのが良くないのですが、書き換える値に複数の参照を使うのは問題ありませんでした。
どういうことか、下をご覧ください。
# 警告が出る(書き換えられない)
df.query('e <= 50')['f']=df.query('e <= 50')['f'].map(lambda x: x*2)
# 警告が出ない(書き換えられる)
df.loc[df['e']<=50,'f'] = df.loc[df['e']<=50,'f'].map(lambda x: x*2)
df.loc[df['e']<=50,'f'] =df.query('e <= 50')['f'].map(lambda x: x*2)
このコードのうち、一番下の=より右、つまり書き換える値を作っている部分
df.query('e <= 50')['f'].map(lambda x: x*2)
は、複数の参照をする形ですが問題ありませんでした。
対策をもう一つ
先ほどは複数の条件をまとめて1回で参照することで警告を回避する方法を取りました。これと別にもう一つ対策があります。それがcopyを使うことです。
まずは以下をご覧ください。
df_1 = df.query('e <= 50')
df_1['f'] = df_1['f'].map(lambda x: x*2)
警告が出ます
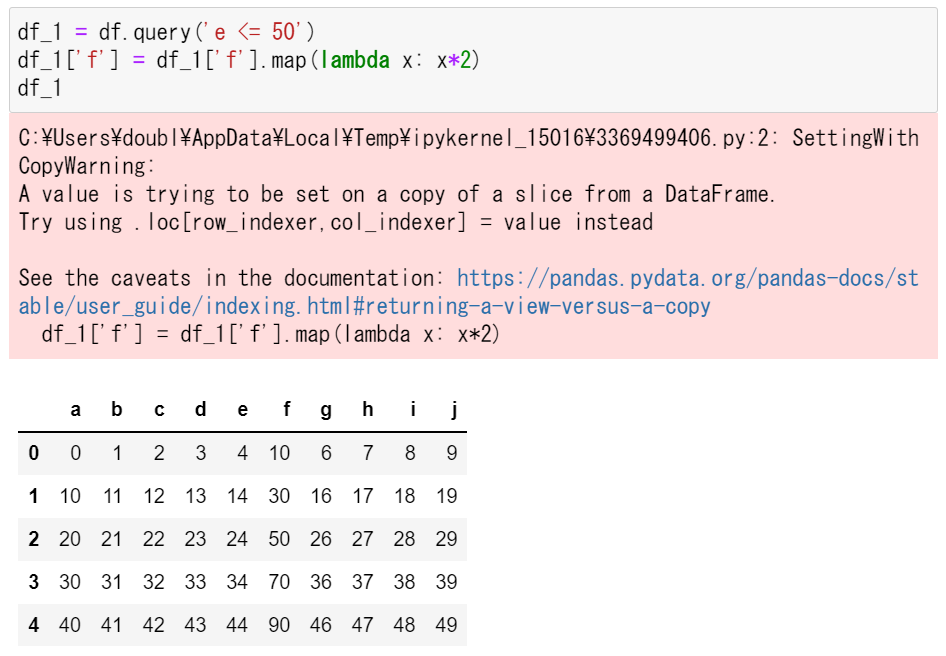
条件で絞り込んだデータを変数に保存して、それをさらに条件付きで書き換えようとすると警告が出ます。ただ、書き換えには成功します。
※参照元(このコードだとdf)の値は書き換わりません。
これは、変数に入っているものがデータの参照だからと考えられます。変数には「dfを'e <= 50'の条件で絞り込んだもの」という情報が入っていて、df_1を呼び出すたびに参照が行われているようです。そこに別の参照を付け加えるとChained Indexingになってしまうっぽいですね。
このパターンは個人的にそれなりにありました。欠損値があるデータを欠損値がない状態にしてからいろいろ加工をしようとすると、警告が出ていたように思います。
条件で絞り込んだデータに対して書き換えを行いたい場合に、copyが役に立ちます。
df_1 = df.query('e <= 50')
df_1['f'] = df_1['f'].map(lambda x: x*2)
import copy
df_1 = copy.copy(df.query('e <= 50'))
df_1['f'] = df_1['f'].map(lambda x: x*2)
copyで警告を回避する

copyはデータを複製することができます。条件で絞り込んだデータと同じものを新しく作ってくれます。これを変数に保存すると、変数を呼び出してもdfは呼び出されず、参照が発生しないのでChained Indexingを回避できます。
終わり。
個人的によく見る警告だったので、原因と対策がわかってすっきりしました。
n番煎じの話題だと思いますが、ご覧いただいた皆様がSettingWithCopyWarningを回避できるようになりましたら幸いです。
参考
こちらを拝見させていただきました。私の記事がこちらとほとんど同じことを繰り返しているような気がします。