こちらの記事をご覧いただきありがとうございます。
ネットに転がっている情報を使ってなんやかんやしたいな~と思うことはだれしもあると思います。ネットの情報を手作業で書き写すことはできますがすごーく面倒ですね。そんな時に、パソコンにデータ収集を手伝ってもらう手法 がスクレイピングです。pythonを使ったスクレイピングの手法を書きます。
自分で後で見返すために作成しますが、ご覧いただいた皆様にも学びがあれば幸いです。また、まだ勉強して間もないので間違っていることを書いている可能性があります。ご指摘やご意見を頂けますと幸いです。
※htmlについての解説は基本していませんので、htmlのタグなど調べながら見ていただくと内容がよくわかると思います。
参考
私はこちらの本でスクレイピングの勉強を行いました。この本の中でも基本的なところだけでもスクレイピングできます。
スクレイピングとは?
前置きにも書きましたが、パソコンにデータ収集を手伝ってもらう手法 の一つにスクレイピングがあります。イメージしやすいように具体例を用意します。
私が練習でyahooを使ったので、具体例もyahooにします。↓のurlを使います。
yahooトップページの、ニュース記事一覧を取り出すことができます。
赤枠のニュースの一覧を取り出したい

取り出した

私は基本操作に慣れたので、これだけなら数分で出来ました。もっとたくさん情報を集めるならこれより長いコードを書く必要がありますが、それもこの後書く基本をうまく活用すれば実現できると思います。
スクレイピングの注意
スクレイピングの方法を書く前に、スクレイピングを実施するうえでの注意を紹介しておきます。
- スクレイピングしたデータは著作物です
著作権の範囲内で利用しましょう。個人の範囲での利用ならおおよそ問題ないように思いますが、収集したデータを公開するなどは問題になります。 - サーバーに負荷がかからない配慮をしましょう
アクセスが集中してサーバーがダウンした、なんてニュースはいくらかあると思いますが、スクレイピングのやり方によっては同じようにサーバーに大きな負荷がかかります。特に繰り返しスクレイピングする場合は気をつけましょう。今回記事に書く内容だけならあまり気にしなくてもよいのでこの記事に詳しく書きませんが、より発展的なスクレイピングをするなら対策が必要です。 - スクレイピングを禁止しているサイトがあります
Amazonなど、スクレイピングを禁止しているサイトがあります。事前によく確認してからスクレイピングしましょう。
詳しく書かれた記事を見つけましたので、載せておきます。ぜひご一読ください。
スクレイピングの手法
ここからスクレイピングの手法を書きます。
requests で html の情報をもらってくる
requestsという、スクレイピングしやすいモジュールがあります。pipしましょう。
pip install requests
スクレイピングしたいサイトのurlを用意します。requestsを使って、そのurlのサイトを構成するhtmlの情報をもらってきます。もらってきた情報はそのままでは読めないので、エンコードします。
↓でそれを実行できます。
※記事作成時点でのurlから変更された場合に実行できなくなります。その場合はurlの部分を取り換えれば動くはずです。
import requests
# urlのサイトの情報をもらってくる
url = 'https://www.yahoo.co.jp/'
html = requests.get(url)
# エンコードする
html.encoding = html.apparent_encoding
print(response.text)
出力

何やら文字がたくさん出てきましたね。これがyahooのサイトを構成する情報の全てです。ここから必要な情報だけを取り出します。
BeautifulSoup で必要な情報を取り出す
BeautifulSoup で情報を取り出せるように変換する
requests でサイトの情報をもらってきたら、BeautifulSoup で必要な情報を取り出します。BeautifulSoup はこれまたスクレイピングに便利なモジュールです。これもpipしましょう。
pip install beautifulsoup4
まずはBeautifulSoupで情報が取り出せる状態に変換します。
import requests
from bs4 import BeautifulSoup
# urlのサイトの情報をもらってくる
url = 'https://www.yahoo.co.jp/'
html = requests.get(url)
# BeautifulSoupで使えるように変換
soup = BeautifulSoup(html.content, 'html.parser')
print(soup)
出力
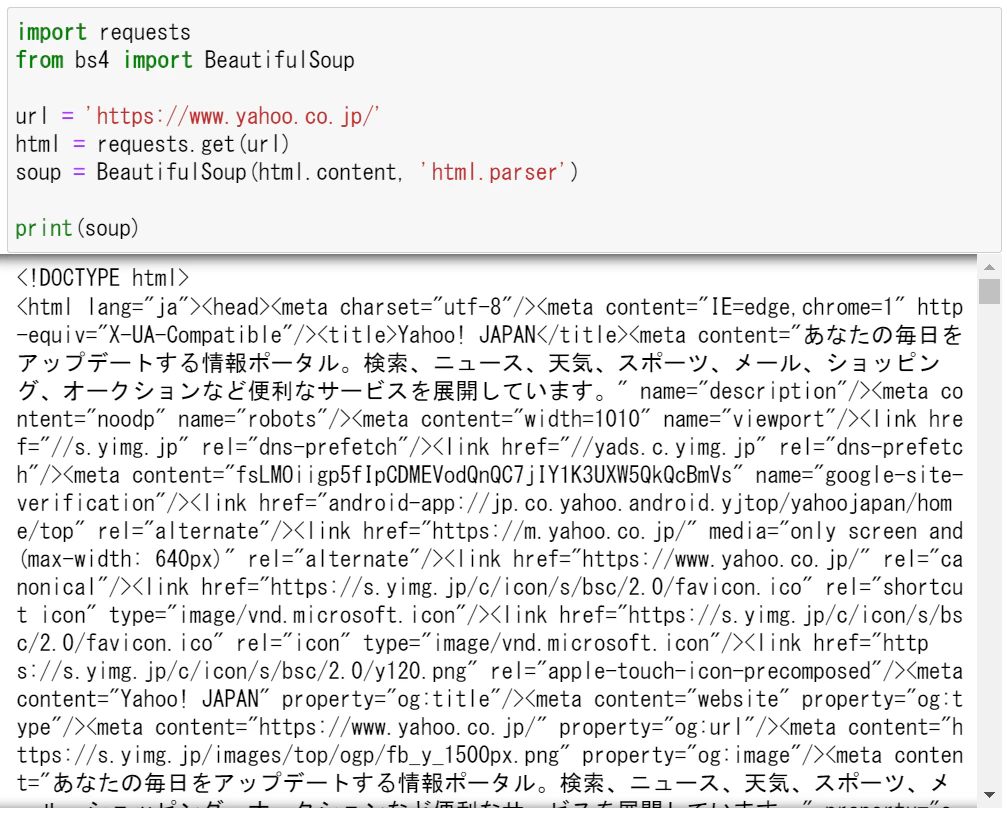
さっきとだいたい同じ出力になりますが、これでOKです。
findとfind_allで情報を取り出す
先ほどの出力にはサイトの情報全部が入っているので、ここから必要な情報だけ取り出します。そのためにfindやfind_allを使います。
findやfind_allは、htmlのタグを指定して、そのタグで囲まれた情報を取り出すことができます。とりあえずで、よく見出しに使う<h1>タグを取り出してみます。
# urlのサイトの情報をもらってくる
url = 'https://www.yahoo.co.jp/'
html = requests.get(url)
# BeautifulSoupで使えるように変換
soup = BeautifulSoup(html.content, 'html.parser')
# h1タグを取り出す
h1 = soup.find('h1')
print(h1)
出力

<h1>で囲まれている情報を取り出すことができました。先ほどのコードの、find('h1')の部分で別のタグを指定することで、別の情報を取り出すことができます。
このままだとタグがうるさいので、タグを消します。.testを付けるだけでタグを消すことができます。
import requests
from bs4 import BeautifulSoup
# urlのサイトの情報をもらってくる
url = 'https://www.yahoo.co.jp/'
html = requests.get(url)
# BeautifulSoupで使えるように変換
soup = BeautifulSoup(html.content, 'html.parser')
# h1タグを取り出す
h1 = soup.find('h1')
# タグを消去して表示
print(h1.text)
出力
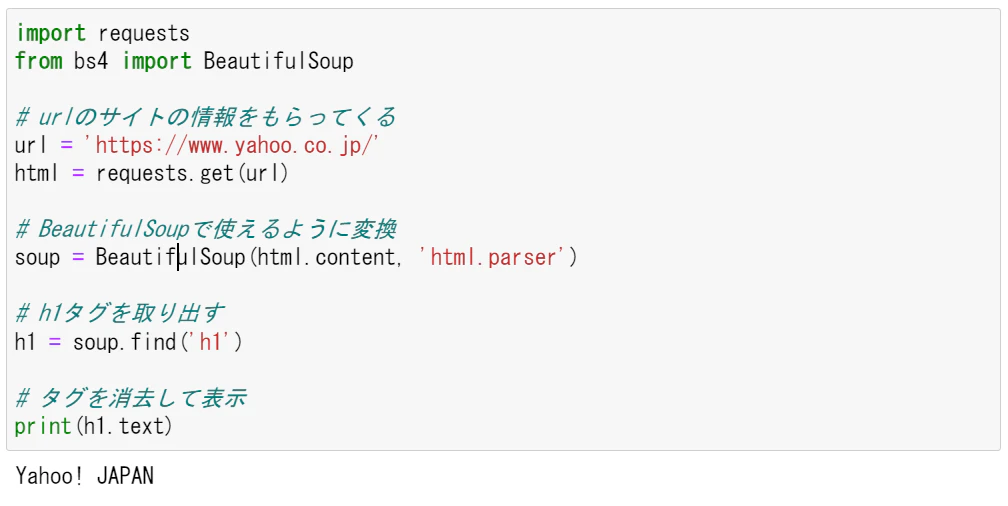
Yahoo!JAPANの文字列だけを取り出すことができました。
find_allだと指定したタグを全て取り出すことができます。リストの状態で出力されます。
# urlのサイトの情報をもらってくる
url = 'https://www.yahoo.co.jp/'
html = requests.get(url)
# BeautifulSoupで使えるように変換
soup = BeautifulSoup(html.content, 'html.parser')
# h1タグを全て取り出す
h1 = soup.find_all('h1')
# タグを消去して表示
print(h1)
出力
※長くなるのでコードの部分は切り落としました。

あとはリストの使い方で1個だけ表示したり全部表示させたりできます。
# urlのサイトの情報をもらってくる
url = 'https://www.yahoo.co.jp/'
html = requests.get(url)
# BeautifulSoupで使えるように変換
soup = BeautifulSoup(html.content, 'html.parser')
# h1タグを全て取り出す
h1 = soup.find_all('h1')
# 最初の1つを表示
print(h1[0].text)
print('\n')
# 全部表示
for element in h1:
print(element.text)
出力

<h1>に囲まれた文字列を全て取り出せました。
idやclassを指定して欲しい情報を取り出す
先ほどの取り出し方でもニュースの見出しっぽいものは取り出せているように見えますが、余計なものが入っていたり、そもそもタグを当て勘で指定して拾いに行くのも面倒ですね。必要な情報を確実に取り出すときに、idやclassの指定が役に立ちます。
欲しい情報がどこにあるのか確認する
欲しい情報に絞って取り出すときに、まずhtmlのどこに欲しい情報があるのかを確認しましょう。
情報を取り出すサイトを開いて、デベロッパーツールを開きます。↓はchromeの例です。他のブラウザでも同じような操作になると思います(Edgeはだいたい同じでした)。
※ショートカットキーでctrl+shift+iでも開けます)
右上点3つのボタン→その他のツール→デベロッパーツール

デベロッパーツールを地道にみてもいいですが時間がかかるので、欲しい情報がどこにあるのか教えてくれる機能を使います。
デベロッパーツールの左上にある矢印のボタンを押します。その後、欲しい情報にカーソルを合わせてクリックします。すると、デベロッパーツールが欲しい情報のある場所を表示してくれます。
左上の矢印ボタンをクリック

欲しい情報がある場所をクリック

デベロッパーツールに欲しい情報がある場所が表示される

デベロッパーツールを見ると、<div class=~ ></div>の中に欲しい情報があるみたいですね。これを取り出します。find(class_='~~')と書くとclassを指定して取り出せます。
# urlのサイトの情報をもらってくる
url = 'https://www.yahoo.co.jp/'
html = requests.get(url)
# BeautifulSoupで使えるように変換
soup = BeautifulSoup(html.content, 'html.parser')
# classを指定して取り出す
class_ = soup.find(class_='_1XAfHUWtx6tfYZuWDVjNxZ')
# 表示
print(class_.text)
出力

ニュースの見出しっぽい文字列が取り出せました。しかしこの状態だと文字列が繋がっていてるのと、余計な情報も入っているので、データとして扱いづらいです。見出しを1個づつ取り出します。
ニュースの見出しのような、同じようなものが並んで表示されている場合にはだいたいそれぞれに同じclassが割り当てられているはずなので、そのclassを指定してfind_allでまとめて取り出します。
デベロッパーツールで先ほどのニュース見出しが全て入っているところから、黒い三角のところをクリックすると中身を細かく表示することができます。これを繰り返すと、いかにも見出しが1個ずつ入っている場所があります。
▶をクリックしてより細かく表示
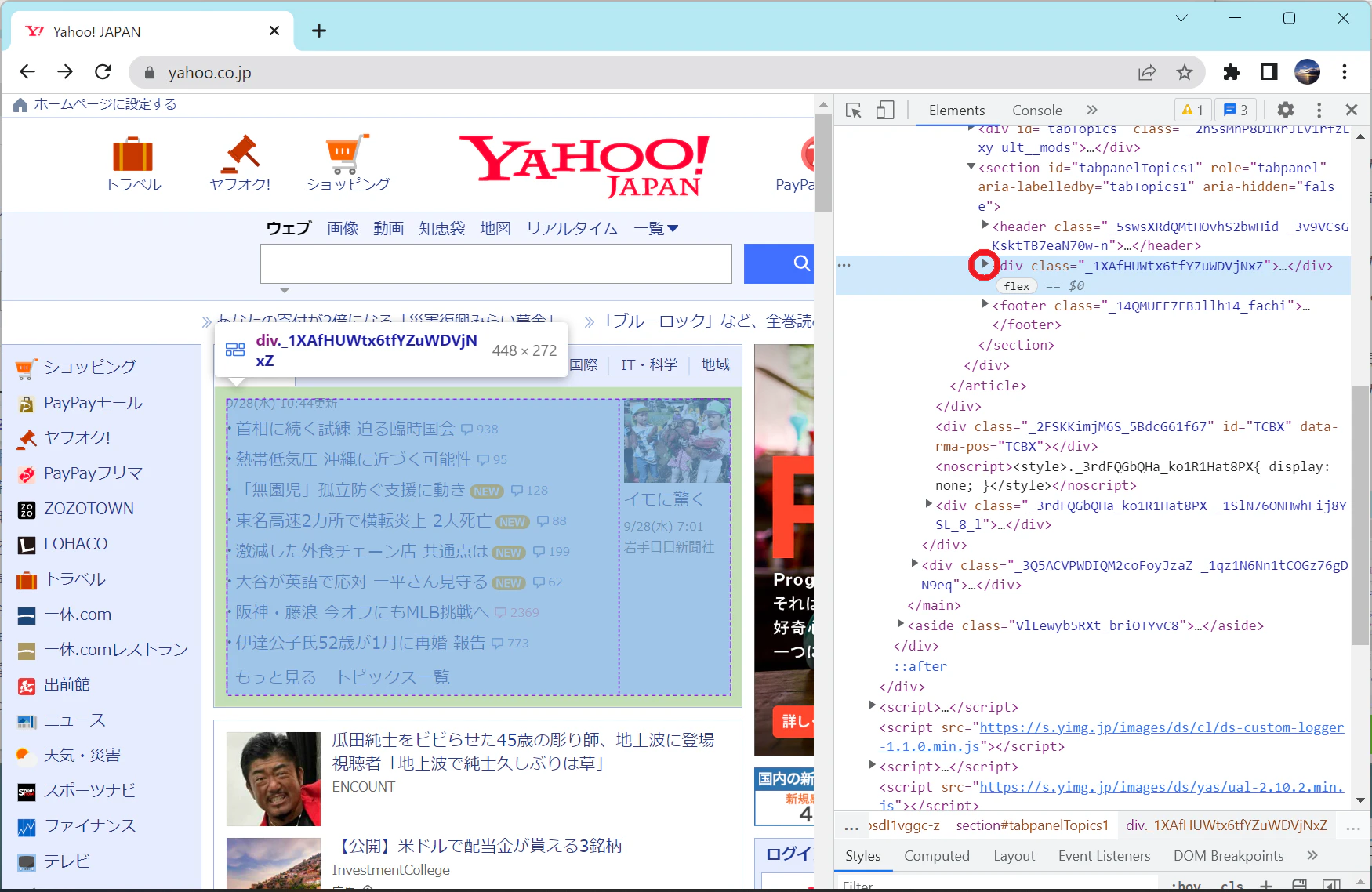
見出しが1個づつ入ってそうなところを表示

見出しが1個づつ入っていそうなところをよく見ると、classが同じ文字列だと気づくと思います。これを指定してfind_allすれば、見出しを1個づつ取り出せそうです。
# urlのサイトの情報をもらってくる
url = 'https://www.yahoo.co.jp/'
html = requests.get(url)
# BeautifulSoupで使えるように変換
soup = BeautifulSoup(html.content, 'html.parser')
# classを指定して取り出す
class_ = soup.find_all(class_='_2j0udhv5jERZtYzddeDwcv')
# 表示
for element in class_:
print(element.text)
1個づつ取り出せたが…?

見出しを1個づつ取り出せました。しかし、新着情報を表すnewが邪魔ですね…。str.replace()とかで取り除いてもいいのですが、newもない状態で取り出すことを考えます。
たぶんニュースの見出しとnewで別々にclassの指定があると思うので、デベロッパーツールでもう少し詳しく表示します。
細かいところまで表示

見出しの文字が入っているところまで細かく表示しました。最初から文字列が入っているclass指定すればよくね?と一瞬思いましたが、案外そうでもなかったりします。すぐにわかります。
classを指定して取り出してみましょう。
# urlのサイトの情報をもらってくる
url = 'https://www.yahoo.co.jp/'
html = requests.get(url)
# BeautifulSoupで使えるように変換
soup = BeautifulSoup(html.content, 'html.parser')
# classを指定して取り出す
class_ = soup.find_all(class_='fQMqQTGJTbIMxjQwZA2zk _1alzSpTqJzvSVUWqpx82d4')
# 表示
for element in class_:
print(element.text)
また余計なものが…?

newはなくなりましたが、「もっと見る」などの関係ない情報が出てきました。文字列を直接囲むタグのclassを指定すれば全部解決ってわけではなさそうです。
情報を使う上ではいらない情報を捨てればよいのですが、ちょうどよいclass指定がどこにあるのかいろいろ試して探します。1つ上の<h1>にあるclass指定ならどうでしょうか?
※ほぼ同じコードなので省略します。
きれいに取り出せました

余計なものがない状態で取り出せました。
※時間がたってyahooのニュースが入れ替わったようですね。やりたいことは出来ていますので、中身が違いますが気にしないでください。
デベロッパーツールを使わずに必要な情報を探す
デベロッパーツールがなくても指定するclassを探す手段があるので、それも書いておきます。
いったんhtmlの情報が全部入っているものを表示させます。そのあと、取り出したい文字列を検索します。検索の仕方はデベロッパーツールを開くときと同じで、右上の点3つのボタンから検索が使えます。
※ショートカットキーでctrl+fでも使えます。
取り出したい文字列を検索

検索した文字列はデベロッパーツールと同様にタグで囲まれているので、検索した文字列の少し前を見てclassの情報を探します。これで、デベロッパーツールでclassを探すときと同じような作業ができます。
終わり。
ここまでに書いた手法で、ネット上の文字列データはだいたい収集することができるような気がします。画像やurlなどの情報は+で専用のやり方が必要ですが簡単です。そこまで出来ればおおよそ欲しい情報は集められるのではないでしょうか。
私はこの後不動産情報とかを収集して機械学習してみようと思っています。ていうかデータのスクレイピングは完了しました。それについての記事もいずれ書くかもしれません。