こちらの記事をご覧いただきありがとうございます。
以前SUUMOの物件データをスクレイピングした記事を投稿しました。今回はスクレイピングしたデータから見つかった、入力ミスと思われる変なデータをご紹介します。
スクレイピングした記事
↓でスクレイピングしたデータから見つかった変なデータを紹介します。
前置き:SUUMOに批判的な意見を主張したいわけではありません。
やっていること自体は人の揚げ足取りと思われて致し方ないことですが、決して批判的な意見を言いたいわけではありません。
機械学習をするうえで、イレギュラーなデータを見つけることは分析精度を上げることにつながります。
てかむしろSUUMO凄くない?
と思います。どう見ても入力ミスだよな…?と思う場面はそんなにありませんでした。
人は誰しも細かいミスをしてしまうものだと思いますし、自分も毎日ミスだらけです。スペルミスのエラーとか1分に1回しています。
22万件データがあって入力ミスらしいものが数えるくらいしかないってすごくないですか?SUUMOの内部システムつよつよなんやろなぁ。
変なデータを探し出せるのも大事なことだとご理解いただけると幸いです。
入力ミスみたいな変なデータをそのまま機械学習モデルにぶち込むと怪しい挙動をし始めます。
モデルにぶち込んで怪しい挙動をして、原因を調査してイレギュラーを取り除く、そんなことを繰り返します。
ここで紹介するのは、私がその試行錯誤をしている中で見つかってしまった変なデータの皆さんです。
ここからミスっぽいデータの紹介
では入力ミスっぽいデータの紹介に移ります。
間取り:42DK
こちらの物件です。
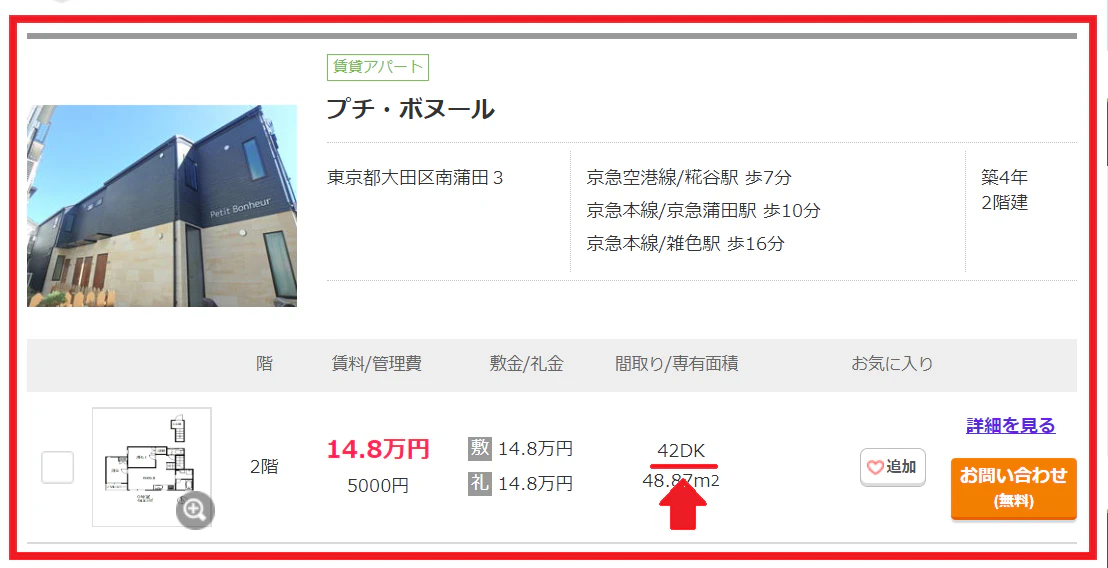
部屋多すぎだろ…。
間取り図を見る限り「2DK」が正しい気がします。
このミスはかなり早い段階で見つかりました。なぜなら、検索して最初に表示された物件だからです。
最寄り駅:西部バス/大泉風致地区
こちらの物件です。
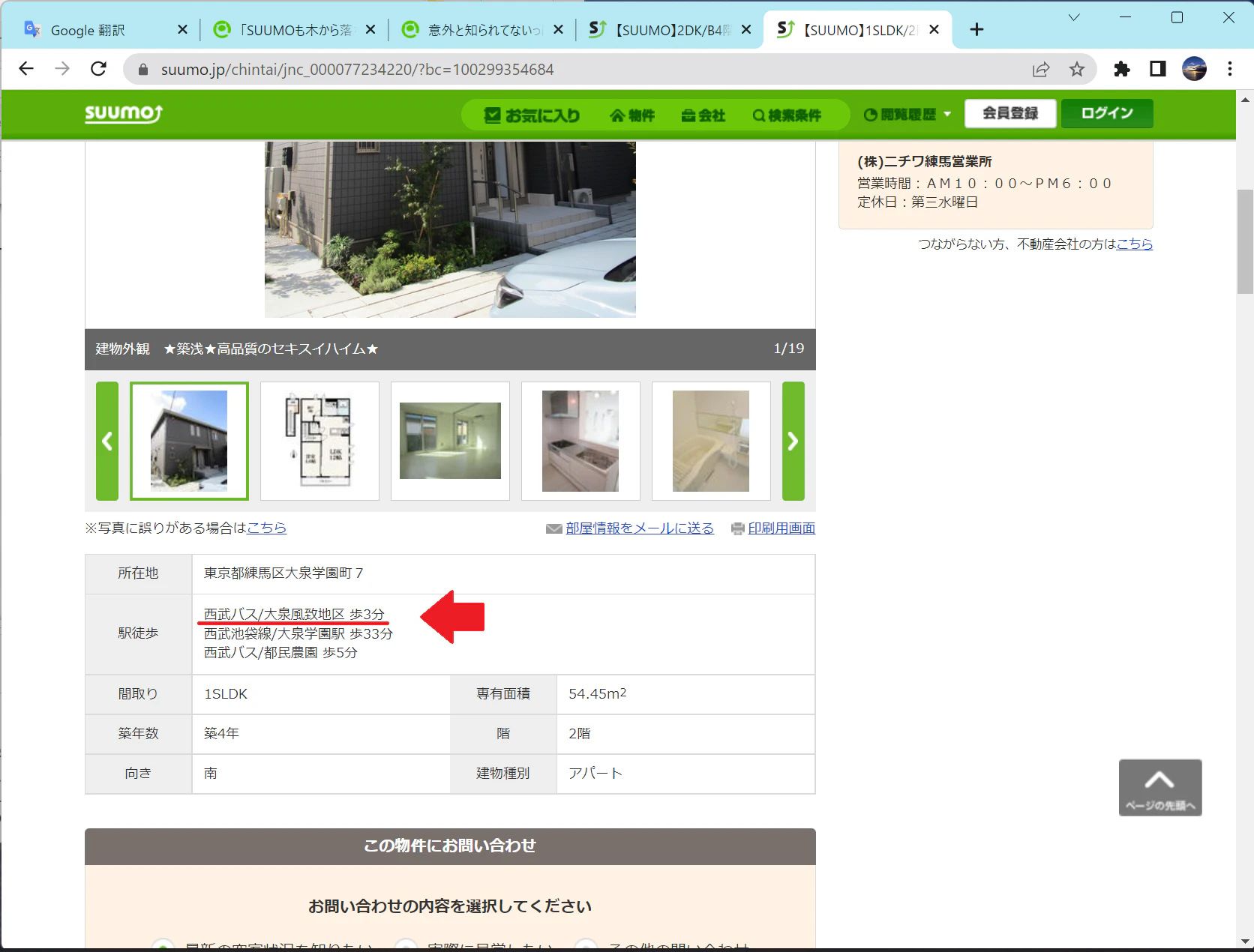
駅徒歩って聞いたら電車の最寄り駅のことだと思うじゃないですか。私はそう思っていました。
ので、「大泉風致地区」っていう駅があるもんだと思って検索してしまいました。(もちろん駅は出てこない)
ちなみに駅徒歩にバス停情報が入っていたのは、(私が見つけたもので)この物件だけでした。
入力ミスというよりは、最寄り駅が最寄って程じゃないからバス停情報を載せたんだと思います。
とはいえ、機械学習で基本電車の最寄り駅情報が載っているところにバス停情報を混ぜるのは良くないと思います。
のでSUUMOに乗っている分にはOKですが私のデータ分析的にはNOです。
駅徒歩:西武池袋線 大泉学園駅/大泉学園町4丁目 徒歩4分 歩14分
こちらの物件です
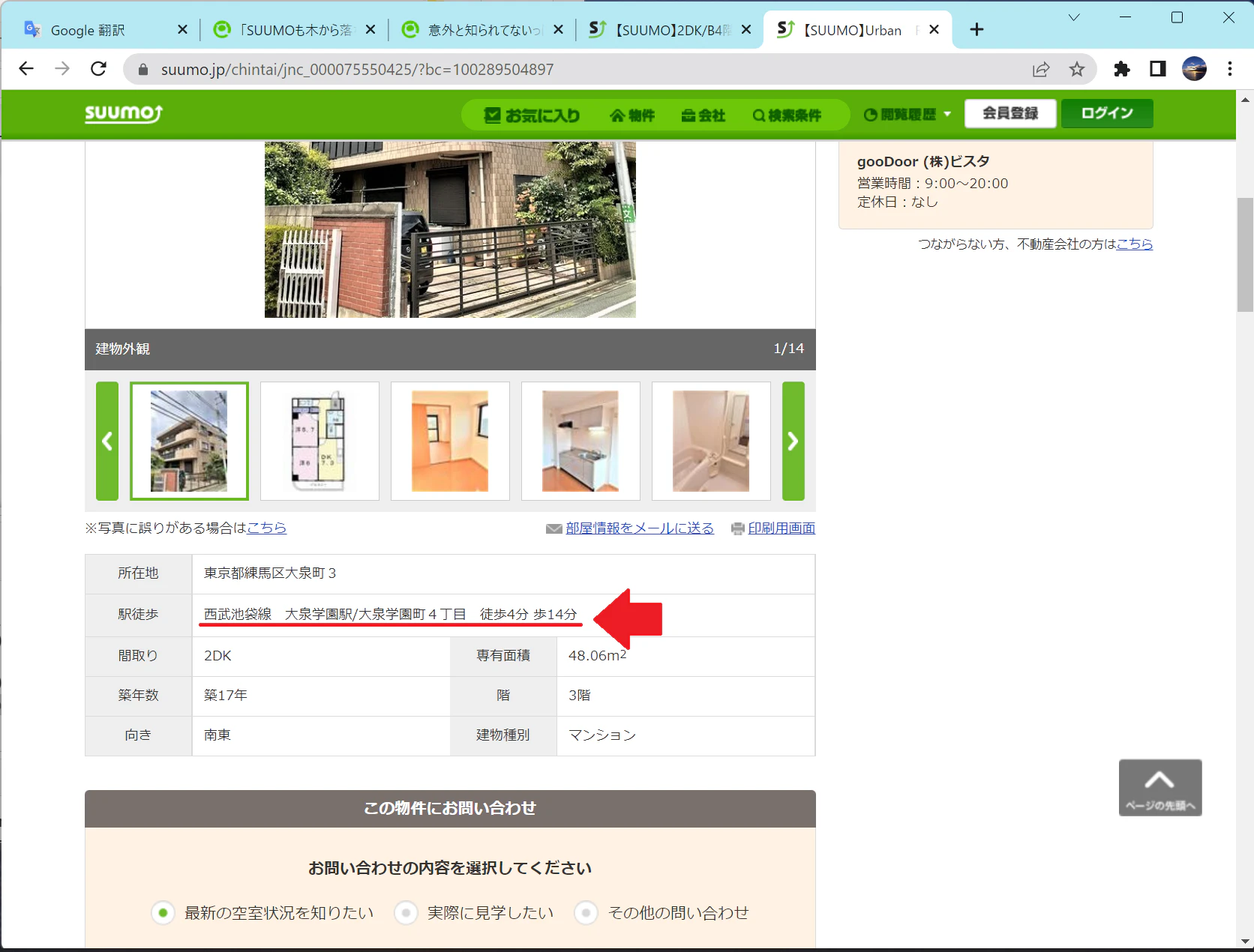
駅の情報なのか住所の情報なのか、歩いて4分なのか14分なのか…。
地図を確認する限りは、徒歩14分っぽいです。
データを1個ずつ確認する分には地図を見てどっちが正しいとかできますが、物件22万件を相手にそんなことやってられません。
正規表現を使って「歩??分」のところを取り出していますが、その場合「徒 歩4分 」も引っかかることになります。
このイレギュラーを考慮した正規表現を書くのは結構面倒ですね。
駅徒歩:見沼代親水公園駅/伊興赤山 歩1分
こちらの物件です
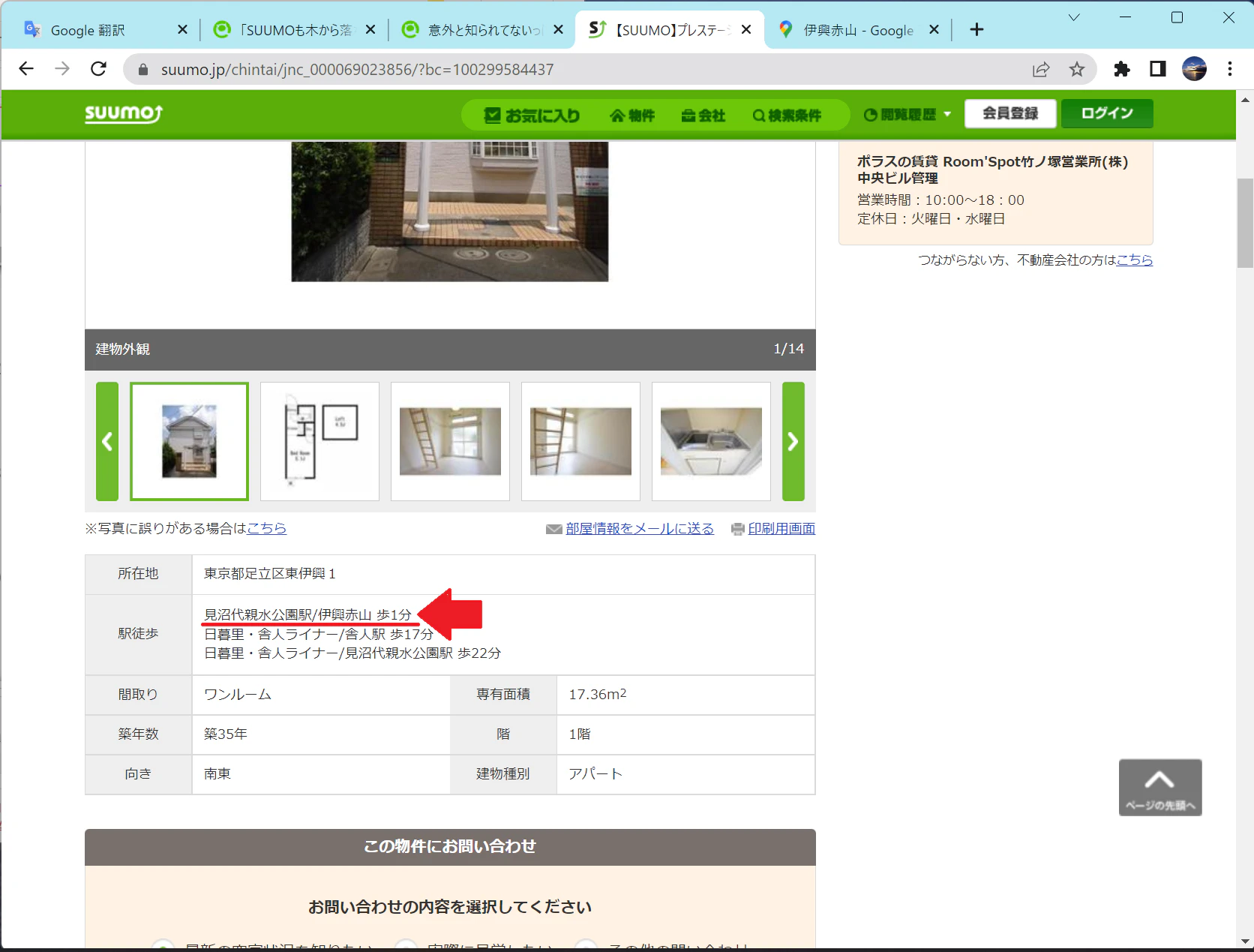
路線じゃなくて駅かいてもうてますやん。
SUUMOの最寄り駅情報は基本「路線/駅 歩?分」と書いてあります。
路線があるべきところに「見沼代親水公園駅」が、駅名があるべきところに「伊興赤山」が書いてあります。
前処理では「/」の前を路線、「/」から「 」(空白)までを駅名ということにして処理したので、「見沼代親水公園駅」という路線が生まれてしまいました。
ちなみに「伊興赤山」はバス停らしいです。
…ん?そうなると、歩1分って駅までなのかバス停までなのか…?。
管理費:700000円
こちらの物件です
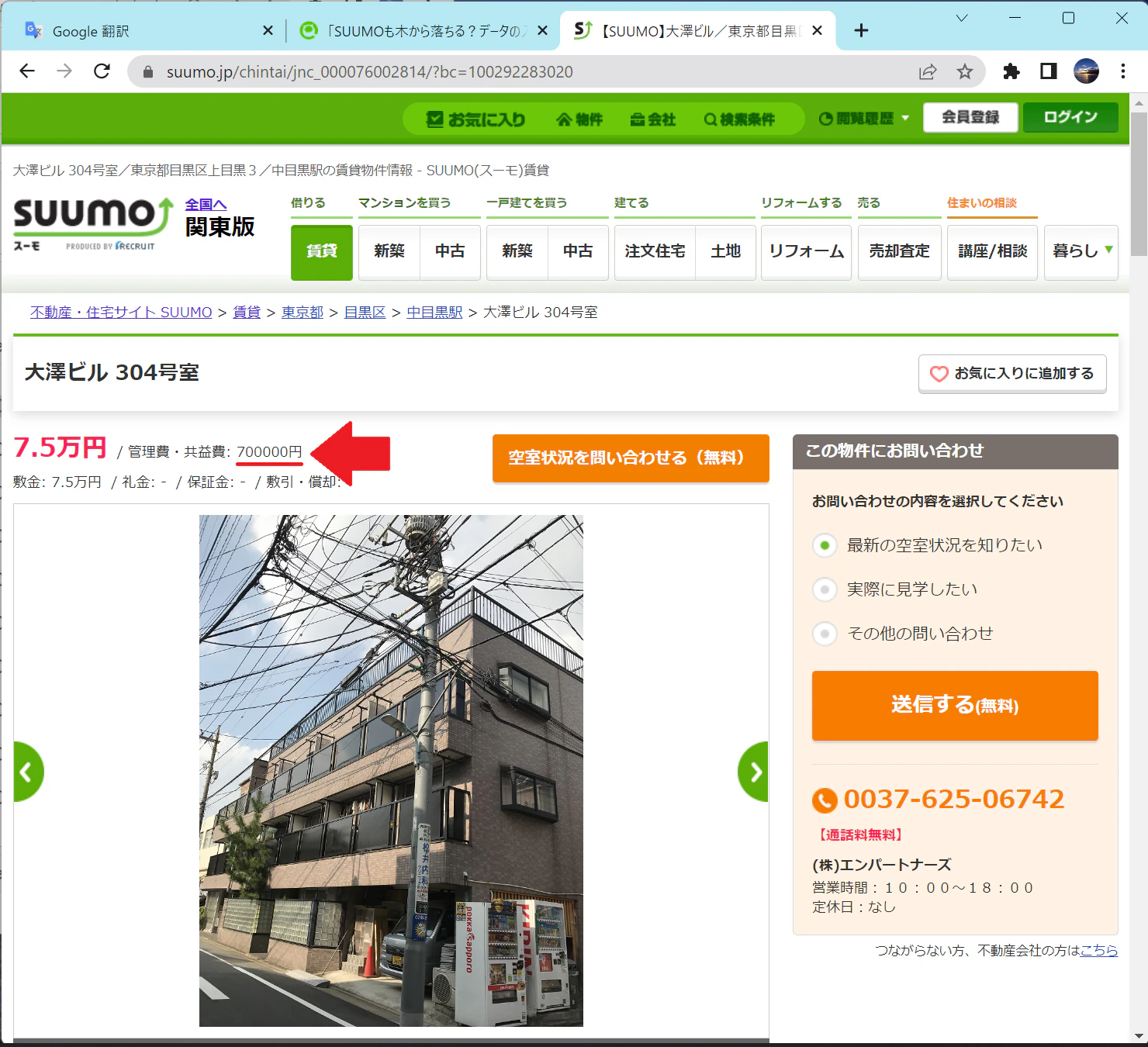
いったい何を管理するのか…?
家賃が7.5万なのに対して管理費70万なわけないですね。家賃ウン百万の高級マンションだったらまだわからなくもないのですが…。
この物件の最寄り駅、遠すぎ…?
こちらの物件です
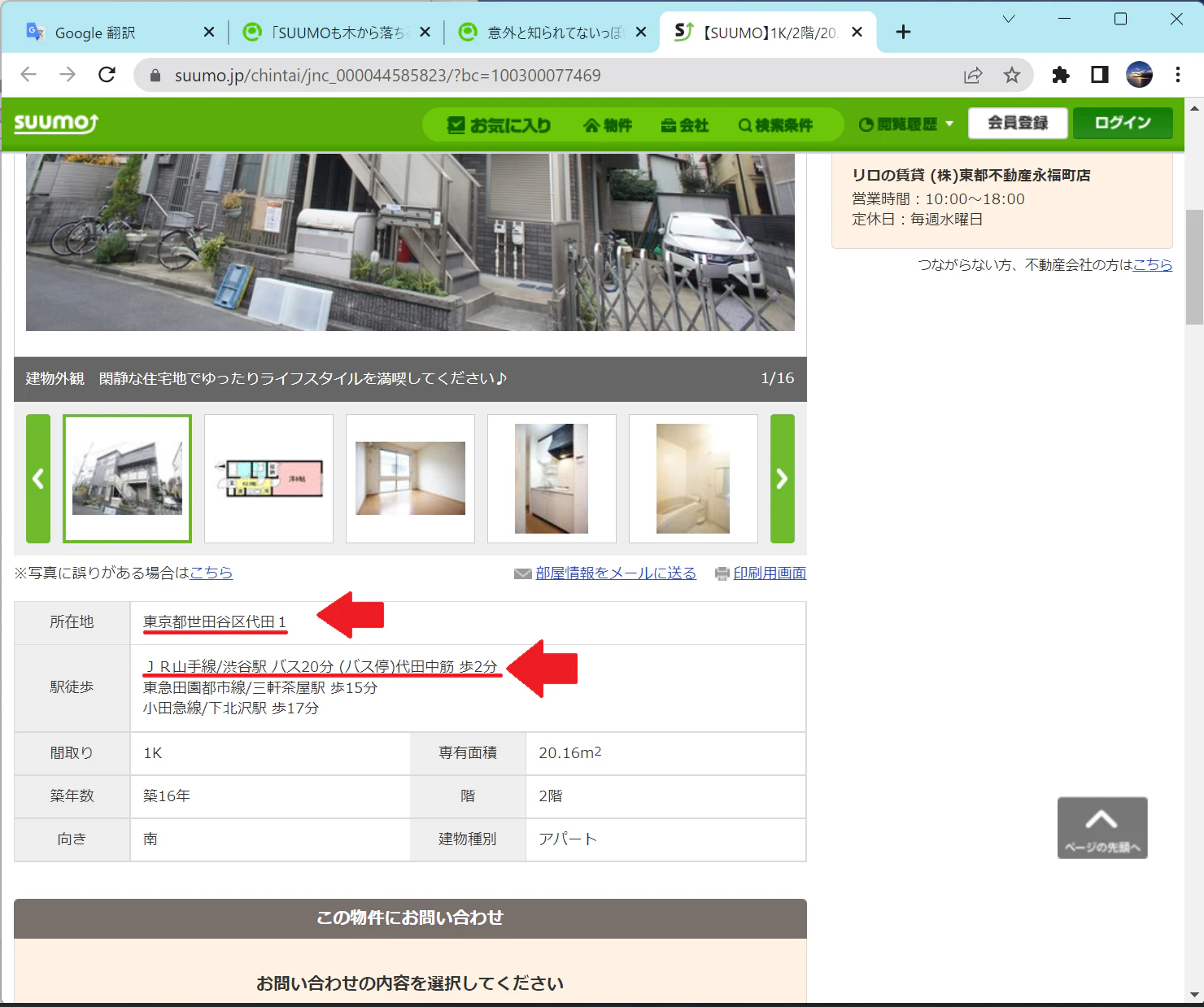
一見して普通なんですが、よくよく考えると、この物件の最寄り駅もっといいとこあるやろ?と思えてきます。
地図上に表してみました。
オレンジが物件の場所、赤が最寄り駅の場所、緑が他の駅の場所を示しています。
オレンジが物件、赤が最寄り駅、緑が他の駅
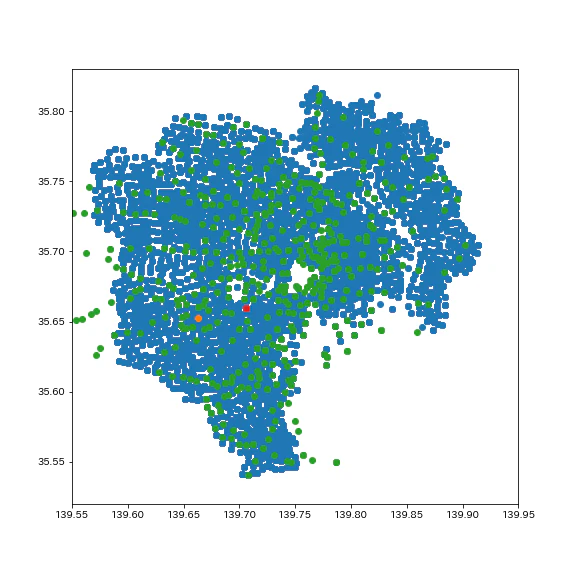
いや絶対もっと近い駅あるやん。なんで渋谷にしたんや。
これに気が付いたのは、「最寄り駅からの距離」を測って異常に数値がデカかったからです。
この物件の最寄り駅までの距離は「3.96km」だそうです。郊外ならまだわかるんですが都心でこれはないよな…?
他にもあった変なデータ
↑で紹介した以外にも変なデータはいくらか見つかったのですが、物件詳細のページがなくなっていたので紹介だけしておきます。
異常が見つかったから取り下げたんでしょうかね?私がスクレイピングしたのが10月上旬で、この記事を書いているのが10月末なので、その間に気が付いた可能性はおおいにあり得ると思います。
物件のある階:B26階
いやどんだけ下いくねん。
ちなみにこの物件は地下4階までしかないらしいです。えぇ…。
最寄り駅までの移動時間:車2分
いや歩きなよ。わざわざ車使わんでもええやん。
たぶん歩2分の間違いっぽいです。
終わり。
いかがでしたでしょうか。
改めて書いておきますが、前処理の重要性とか、変なデータを見つけることの重要性とか、そんな話をお伝えしたいのであって、SUUMOを批判する意味はありません。ご理解いただけますと幸いです。
機械学習をするうえでデータが汚いと得られる結果も汚くなってしまいます。可能な限りきれいにした方がいいと思います。というのを身に染みて感じています。回帰分析してゴミみたいな結果が出てくることが結構ありました。この試行錯誤の過程も余裕があれば記事にします。
ぜひご覧の皆さんも変なデータがないか確かめてみてください。
他のSUUMO記事
まとめ記事書いたのでぜひご覧ください。