当初の状況
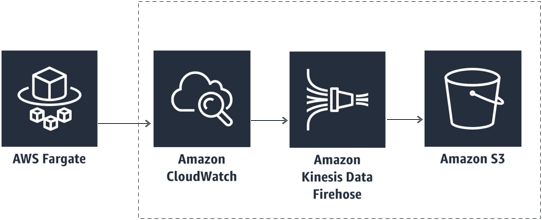
あるサービスで Fargate + Goの運用が始まり、取り急ぎGoが出力したログの運用を以下のようにしていました。
- Goが出力したログの流れ
- awslogsドライバ経由でCloudWatch Logsに保存。
- CloudWatch Logsのサブスクリプションを使ってKinesis Data Firehose経由でS3に保存 (ログの永続保存/コスト考慮的な)
運用を始めて出てきた要望
運用を始めると開発時とは違った形でログを調査することが増えてきて、ログ調査に対する要望が出てきました。
- 主な要望
- CloudWatch LogsやS3上のログを見るのにAWS Console使うのは頻度的に手間/ストレス
- CloudWatch LogsやS3上のログにgrep的なことをするのにAWS ConsoleやAWS CLIだと調べにくい
- S3 Selectしてみると1レコードに複数ログ(logEvents部分)が入っているケースがあるので、1レコード1ログで見られるといい
[
{
"messageType": "DATA_MESSAGE",
"owner": "xxx",
"logGroup": "/ecs-task",
"logStream": "/ecs-task/xxxxxxx-4c18-4ab5-b1d6-7f8bff82a23d",
"subscriptionFilters": [
"/ecs-task"
],
"logEvents": [
{
"id": "xxxxxxxx",
"timestamp": 1544414264183,
"message": "{\"level\":\"info\",\"ts\":\"2018-12-10T12:57:44.183+0900\",\"msg\":\"request and response log\",\"out\":\"stdout\",\"log\":{\"start_time\":\"2018-12-10T12:57:44+09:00\",\"duration\":10267638,\"request\":{\"hostname\":\"api.tomy103rider.xxx\",\"method\":\"GET\",\"path\":\"/v1/xxx/xxx-xxx\"},\"response\":{\"status\":200}}}"
},
{
"id": "xxxxxxxx",
"timestamp": 1544414336184,
"message": "{\"level\":\"info\",\"ts\":\"2018-12-10T12:58:56.184+0900\",\"msg\":\"request and response log\",\"out\":\"stdout\",\"log\":{\"start_time\":\"2018-12-10T12:58:56+09:00\",\"duration\":11138161,\"request\":{\"hostname\":\"api.tomy103rider.xxx\",\"method\":\"GET\",\"path\":\"/v1/xxx/yyy-yyy\"},\"response\":{\"status\":400}}}"
}
]
}
]
方針
元々Kibanaを使っているメンバーが多かったり、慣れというのもあり以下のような方針にしてみました。
- ログをAmazon Elasticsearch Service (以下ES)に流す
- 雑に検索できるようになる
- Kibanaで見やすくなる
- ESには最低限必要なログ要素だけを流す
- Lambda(Python)でlogEvents部分のログを1つ1つバラしながらESに流す
- Lambdaは S3 PUT をトリガーにして実行してみる
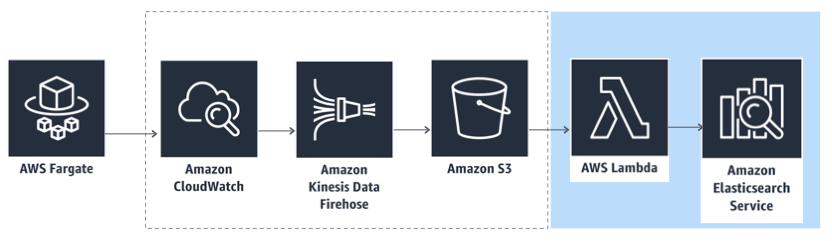
※FirehoseでLambda/ES + S3 に流すこともできるがFirehoseにやってもらうことはS3に流すだけにしたかったのでこの構成にしてみました。
環境構築
実際の構築はざっくり以下のような感じです。
- Elasticsearch ドメイン
ESの細かい構築方法は割愛。
参考までにこの環境では
VPCアクセス(推奨)、かつPrivate SubnetにElasticsearch ドメインを作成しました。
| 設定 | 値 | 備考 |
|---|---|---|
| VPCエンドポイント | https://vpc-tomy103rider-es-x.ap-northeast-1.es.amazonaws.com |
- Lambda関数
- Lambda関数の実行ロールを作成しておく
| 設定 | 値 | 備考 |
|---|---|---|
| ロール名 | S3LambdaES-role | |
| アタッチするポリシー | AmazonS3ReadOnlyAccess AmazonESFullAccess AWSLambdaVPCAccessExecutionRole |
さらに以下のインラインポリシーを割り当てる。(Lambda自身のログ出力用)
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "VisualEditor0",
"Effect": "Allow",
"Action": [
"logs:CreateLogStream",
"logs:PutLogEvents"
],
"Resource": "arn:aws:logs:*:*:*"
},
{
"Sid": "VisualEditor1",
"Effect": "Allow",
"Action": "logs:CreateLogGroup",
"Resource": "arn:aws:logs:*:*:*"
}
]
}
信頼関係はこんな感じに。
{
"Version": "2012-10-17",
"Statement": [
{
"Effect": "Allow",
"Principal": {
"Service": "lambda.amazonaws.com"
},
"Action": "sts:AssumeRole"
}
]
}
- lambda関数を作る
| 設定 | 値 | 備考 |
|---|---|---|
| 名前 | ecs-task-log-to-es | |
| ランタイム | Python 3.7 | |
| ロール | S3LambdaES-role | 上記で作成したロール |
| タイムアウト | 2分0秒 | デフォルトだと短すぎてタイムアウトしがちだった |
| ネットワーク | VPC/サブネット/セキュリティグループを適宜指定 |
- 環境変数を用意しておく
環境(production/stagingなど)で変わる部分をLambdaの環境変数に。
| 設定 | 値 | 備考 |
|---|---|---|
| ES_DOMAIN_URL | https://vpc-tomy103rider-es-x.ap-northeast-1.es.amazonaws.com | https://ESのドメイン名 |
| ES_INDEX_PREFIX | ecs-task | ESに作成するインデックスのプレフィックス |
- Lambda関数コード
予め作ってzipでまとめたものをアップロードしました。
(このあたりの公式ドキュメントを参考)
※注意(?)
普段コーディングをしていない人間が人生で初めて書いたpythonのコードです。
やりたいことの気持ちを表現して方針を実現はできた感がありますが、
書き方汚いとかお作法無視してるとかは絶対あると思いますので参考程度に...(いつか見直す...)
import os
import boto3
import json
import gzip
import requests
import urllib.parse
from datetime import datetime, timezone, timedelta
s3 = boto3.resource('s3')
# Lambda execution starts here
def lambda_handler(event, context):
# Count Check
count = 0
# Elasticsearch Parameters
es_host = os.environ.get('ES_DOMAIN_URL')
es_index_prefix = os.environ.get('ES_INDEX_PREFIX')
es_type = 'type-lambda'
es_headers = {"Content-Type": "application/json"}
try:
# Get bucket name for make ES Index
for record in event['Records']:
# s3 info
bucket_name = record['s3']['bucket']['name']
object_key = urllib.parse.unquote_plus(record['s3']['object']['key'], encoding='utf-8')
# Get S3 Object
s3.Bucket(bucket_name).download_file(object_key, '/tmp/dl_log')
file = gzip.open('/tmp/dl_log', 'rt')
lines = file.readline()
decorder = json.JSONDecoder()
while len(lines) > 0:
record, index = decorder.raw_decode(lines)
lines = lines[index:]
for lines_dict in record['logEvents']:
# Convert timestamp for ES data
JST = timezone(timedelta(hours=+9), 'JST')
log_timestamp_tmp = lines_dict['timestamp']
log_timestamp = datetime.fromtimestamp(int(str(log_timestamp_tmp)[:10]), JST)
es_timestamp = log_timestamp.strftime('%Y-%m-%dT%H:%M:%S%z')
es_timestamp_day = log_timestamp.strftime('%Y-%m-%d')
# Get log message
log_message = lines_dict['message']
# POST to ES
es_index = es_index_prefix + '-' + es_timestamp_day
es_url = es_host + '/' + es_index + '/' + es_type
es_document = {"@timestamp": es_timestamp, "message": log_message}
r = requests.post(es_url, json=es_document, headers=es_headers)
count += 1
except Exception as e:
print(e)
finally:
file.close()
print('Posted ' + str(count) + ' items from s3://' + bucket_name + '/' + object_key + ' to ' + es_host + ' .')
流れは以下。
- FirehoseからS3 PUTされたログファイルのS3バケット名とオブジェクトキー名取得
- ログファイルを一時ファイルとしてDL
- DLしたファイルを読んでく
- ログのtimestampからESで使う2パターンのフォーマットを生成
- ログのメッセージ(実体)を1つ1つESにPOST
- Lambda関数のトリガー作成
トリガーの追加で S3 選択
| 設定 | 値 | 備考 |
|---|---|---|
| バケット | application-logs-raw | Firehoseでの流し先がここ |
| イベントタイプ | PUT | |
| プレフィックス | _/cwl/ecs/ecs-task/ | Firehoseでの流し先がここ |
| サフィックス | なし | |
| トリガーの有効化 | チェックする |
Kibana
- index作成(作り方は色々あると思うのでイチ例)
http(s)://<kibana URL>/_plugin/kibana/app/kibana/
| 設定 | 値 | 備考 |
|---|---|---|
| Index pattern | index名-* |
※index名は上記Lambdaで指定しているS3 Bucket名 |
| Time Filter field name | @timestamp |
※ここでの例 |
- Kibanaの「Discover」画面を見てみる
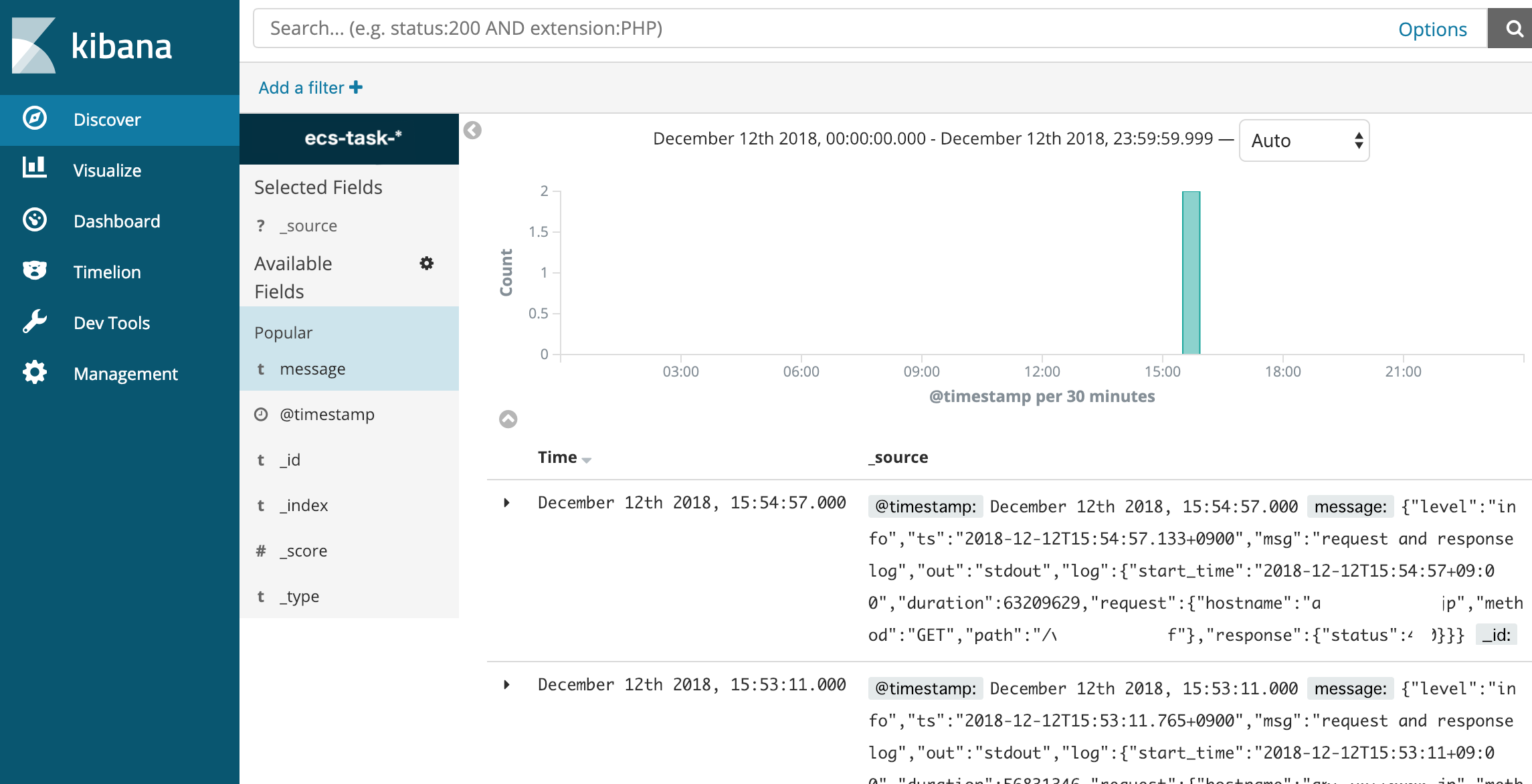
のように良い感じで可視化/ログ閲覧ができるようになりました。
上部の「Search」のところでログのgrep的なこともできるのでこれで要望を満たすことができそうです。
まとめ
今回は使い慣れていたElasticsearch/Kibanaで一旦なんとかしましたが、AWS Consoleでも良ければCloudWatch Logs Insightsを使う、もしくは他のツールを使うなど色々選択肢があると思います。
ちょうどPythonとLambdaに触れたいと思っていたところだったので、割と苦労しましたが作っていて楽しかったのでそういう面でも良かったです。