requestsとBeautifulSoupでページ遷移をしながらPythonでスクレイピング
日本では機械学習などの統計分析のために、クローリング・スクレイピングでデータ収集することが許可されています。
ここではページ遷移をしながらのスクレイピングについて解説します。
スクレイピングのルールや注意点に関しては以下の記事が詳しいのでこちらを参照してください。
プログラムの構成
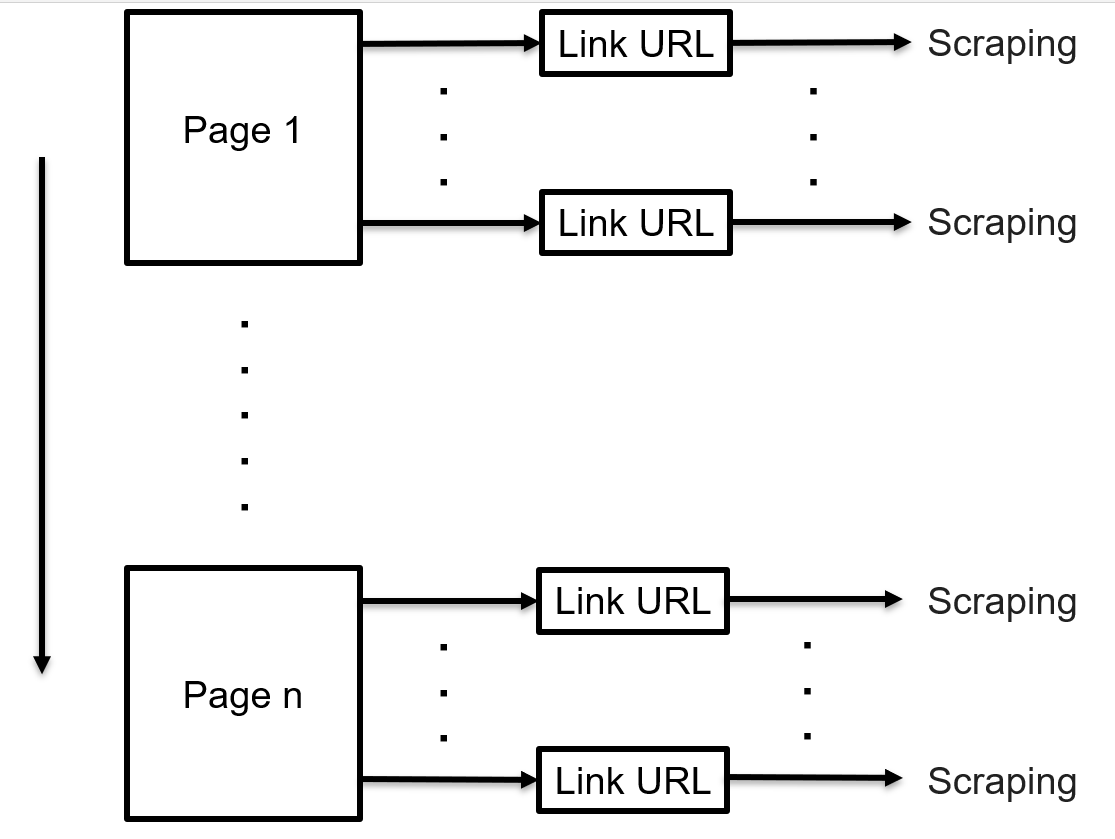
構成としては初めに基準となるURLから詳細情報のリンク先のURLを列挙し、そのURLに順にアクセスしてスクレイピング。
そしてURLを一通り巡回したらページ遷移のボタンがあるので、次のページがあればページ遷移。なければプログラム終了という流れです。
概要を図にも示しておきます
実装
使うモジュール
import requests
from bs4 import BeautifulSoup
import time
import os
import pandas as pd
import codecs
from urllib.parse import urljoin
html取得、解析
res = requests.get(url)
res.raise_for_status()
html = BeautifulSoup(res.text, 'lxml')
htmlから情報抽出
detail_url_list = html.find_all("取得したいURLのhtmlタグ")
next_page = html.find("次のページのURLのhtmlタグ")
ページ遷移
if bool(next_page) == False:
break
dynamic_url = urljoin(base_url, next_page.a.get("href"))
全体的な流れ
data_col = ["information1", "information2"]
while True:
res = requests.get(dynamic_url)
res.raise_for_status()
html = BeautifulSoup(res.text, 'lxml')
detail_url_list = html.find_all("取得したいURLのhtmlタグ")
next_page = html.find("次のページのURLのhtmlタグ")
for i in range(len(detail_url_list)):
res2 = requests.get(urljoin(base_url, detail_url_list[i].a.get("href")))
res2.raise_for_status()
html2 = BeautifulSoup(res2.text, 'lxml')
# 抜き出す情報に合わせて抽出するタグの変更
information1 = html2.img.get("alt")
information2 = html2.a.get("href")
s = pd.Series([information1, information2],
index=data_col)
df = df.append(s, ignore_index=True)
df.to_csv(save_csv)
time.sleep(5)
if bool(next_page) == False:
break
dynamic_url = urljoin(base_url, next_page.a.get("href"))
time.sleep(5)
WEBサイトのHTMLはそれぞれ異なる構造をしていますが、ページ遷移をしながらのスクレイピングはこれらの方法がおおよそ適用できると思います。スクレイピングのインターバルは1秒あれば良心的だそうですが、日本では1秒のインターバルでも攻撃とみなされて捕まった例もあるので長めにしておいた方がいいと思います。