はじめに
この記事は、
Hosting a REST API with a Cloud Firestore backend
という動画を参考に、『実際にやってみた』という記事になります。
この記事で実施する事。
-
sample codeをgit cloneする。 -
Artifact Registoryでリポジトリを作成。 -
Cloud Firestoreデータベースを作成する。 -
deploy.shを編集して、イメージのビルドとプッシュ、
Cloud Runのデプロイまで行う。 -
コレクションとドキュメントを手動で登録する。 -
Postmanを使って、コレクションとドキュメントを登録する。 -
特定のURLのパスを実行して、Firestoreからドキュメントを取得する。
以下はその必要となる大まかな構成になります。
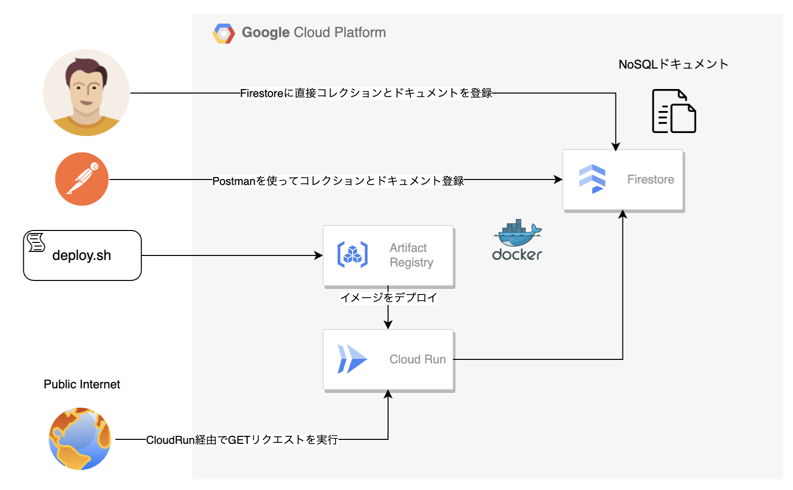
Google Cloud Firestoreについて噛み砕いて理解しておく。
Google Cloud Firestore について噛み砕いた説明を以下にまとめます。
フルマネージドのNoSQLドキュメントデータベースである。
Googleが全ての技術的な面倒を見てくれるデータベースであり、
ユーザーはサーバーの設定や日々の運用に頭を悩ませることなく、
自分のアプリケーション作りに集中できる。
また、データを保存する形式も柔軟で、様々な形の情報を扱うことが可能である。
スケーラブルで安全なグローバルインフラを背景に高い可用性を実現している。
多くの人が使うようになり、システムにかかる負荷が増えても、
必要に応じて処理能力や記憶容量を自動で増やせるので、
サービスが止まる心配をする必要がない。
さらには、世界中に分散したデータセンターでデータを
複数コピーしておくことで、たとえどこか一つに問題があっても、
他の場所が代わりに動くため、アプリケーションはいつも通り使える。
そして、これら全てはGoogleの厳重なセキュリティ対策によって保護されている。
リアルタイムでのデータ同期や組み込みのオフラインサポートを実現している。
このデータベースサービスを使えば、データはいつも最新の状態を保っており、
インターネットが使えない時でもアプリを動かし続けることが可能である。
自動シャーディングとロードバランシング機能を通じて、
アプリケーションの拡大に合わせて自動的にスケールアウトする。
データを適切に分けて、異なるサーバーへ均等に負荷を
分散させる事が可能で、ユーザーの増加やデータの増大に応じて、
サーバーやサービスの処理能力の増強を自動的に行ってくれる。
ACIDトランザクションのサポートや強力なクエリ実行能力を有しており、
アプリケーションの可用性を損なうことなく、データストアを柔軟に拡張することができる。
このデータベースには以下の特徴があります。
原子性(Atomicity)
処理が途中で止まってしまうことで、一部だけが実行された状態に
なることはなく、すべての処理が完全に終わるようになっている為、
データの不整合やデータ損失のリスクが高まる事を抑える。
--
一貫性(Consistency)
データの整合性を保つために、変更があった際には、
データベース全体へと、最新の状態が反映される。
--
独立性(Isolation)
複数のユーザーが同時にデータの変更を加えても、
互いの操作は独立している事から、干渉し合う事はない。
--
耐久性(Durability)
一度保存されたデータは永続的に保持されるので、
システムに何かあってもデータが消えるといった心配事もない。
--
これらの特徴に加えて、複雑な検索やデータの取り出しも、
簡単かつ迅速に実行できるため、データベースのサイズを
大きくする時も、アプリの動作を妨げる事なく対応が可能である。
強固なデータ整合性と耐障害性を特徴とし、
マルチリージョンレプリケーションによって高い耐久性を提供している。
しかし、自動的なデータバックアップと時点復旧は
直接的な機能としては提供されておらず、
これはサードパーティのソリューションまたは
手動のスナップショットによって実現する必要がある。
データを守る為、複数の場所に保存することで、データが失われにくいという特徴が
ある一方で、データのスナップショットを自動で定期的に行う仕組みがないことから、
特定の時点まで戻すためには、手動でスナップショットをとらなければならず、
自動化するには、SchedulerやCloud Functions等と組み合わせる必要がある。
セキュリティに関して、FirestoreはFirebase SDKや
Google Cloud APIを通じてアクセス可能で、
細かい粒度でのセキュリティルールを設定することで、
読み書きアクセスを適切に管理することができる。
このルールに基づいて、ドキュメントレベルで
アクセスを制御し、データのセキュリティを保証している。
Google Cloud Firestoreでは、FirebaseやGoogle Cloudの
専用ツール(SDKやAPI)を使ってデータにアクセスすることができる。
そして、データを安全に守るために、セキュリティルールを使って
細かくアクセスを管理する事が可能である。
これにより、一つ一つのデータ毎に、誰が閲覧や編集を行えるかを詳細に設定できるため、
不正アクセスを防ぎつつ、必要なユーザーのみがデータを扱えるようになる
データモデリングの柔軟性を提供し、コレクションとドキュメントを
通じてデータを効果的に管理することが可能である。
リレーショナルデータベースとは異なるアプローチが必要だが、
これによってよりスケーラブルなデータ構造を実現している。
データを自由に組み合わせて保存することが可能で、
従来の表形式のデータベース(RDB)とは
異なる方法でデータを管理し、「コレクション」と
呼ばれる箱に「ドキュメント」という個々の情報の
ページを入れるようなイメージで保存できるため、
たくさんの情報を効率的に扱えるようになっている。
料金体系に関しては、利用した読み書きの操作数や保存されるデータ量、
ネットワークの使用量に基づいて課金されますので、
コストを抑えるためのデータ構造とクエリの最適化が重要となる。
Google Cloud Firestoreでの料金は、使った分だけ払う仕組みである。
データを読み込んだり、書き込んだりする回数、データをどれだけ保存しているか、
そしてインターネットをどれくらい使ったかによって、料金が変わる。
だから、お金を節約するためには、データの保存の仕方や
検索の方法を考えて、無駄な操作を減らすことが大切である。
Google Cloud Firestore は、これらの特性により、モバイル、ウェブ、
サーバーレス、IoTといった幅広い用途でのデータ管理に適しており、
FirebaseやGoogle Cloud Platformの他のサービスとの統合により、
アプリケーションの開発とスケーリングを容易にします。
Google Cloud Firestore は、さまざまな種類のアプリケーションに
適している便利なデータベースであり、スマートフォンのアプリやウェブサイト、
インターネットに繋がる機器(IoT)に加えて、
サーバーを必要としないプロジェクトの開発でも使える。
FirebaseやGoogle Cloud Platformと組み合わせることで、
アプリの開発がしやすくなるだけでなく、システムの
成長に柔軟に対応できるように設計されている為、
開発者は利用者の増減に合わせて、手間をかけずに
アプリケーションをスケーリングすることが可能である。
sample code を git clone する。
hosting-a-rest-api-with-a-cloud-firestore-backend を、git clone してください。
git clone https://github.com/GoogleCloudPlatform/serverless-expeditions.git
git cloneの実行が完了したら、cdコマンドを使って、対象のディレクトリ階層へ移動。
cd serverless-expeditions/hosting-a-rest-api-with-a-cloud-firestore-backend
サンプルコードは、Dockerイメージを、
Container Registry へデプロイします。
Container Registry は非推奨となっているため、
このブログでは、Artifact Registory に対して、
Dockerイメージがデプロイされるように修正します。
Artifact Registory でリポジトリを作成。
Dockerイメージをホストするためのリポジトリを作成。
GCPのプロジェクトIDのみ、自己の環境に書き換えてください。
リージョンは予め指定していますが、最寄りでない場合は書き換えてください。
gcloud artifacts repositories create dog-breed-api \
--repository-format=docker \
--location=asia-northeast1 \
--description="Docker repository" \
--project=# YOUR GCP PROJECT ID GOES HERE
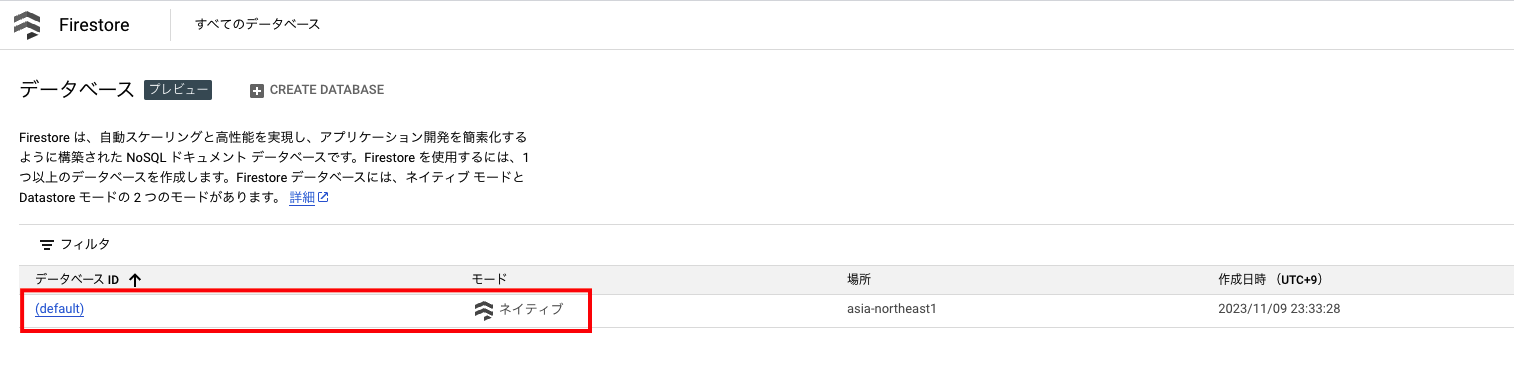
Cloud Firestore データベースを作成する。
CREATE DATABASE をクリック。
この時、 CREATE DATABASE をクリックできない場合、
既存で Firestore Database が作られている可能性があります。
その場合、Datastoreモード で作られていると、
サンプルコードは ネイティブモード の Firestore Database に
対してのみ、動作する為、ネイティブモード に変えなければなりません。
ただし、一度作成してしまうと、モードを切り替える事ができない為、
新規でプロジェクトを立ち上げ直し、一から作り直す必要があります。
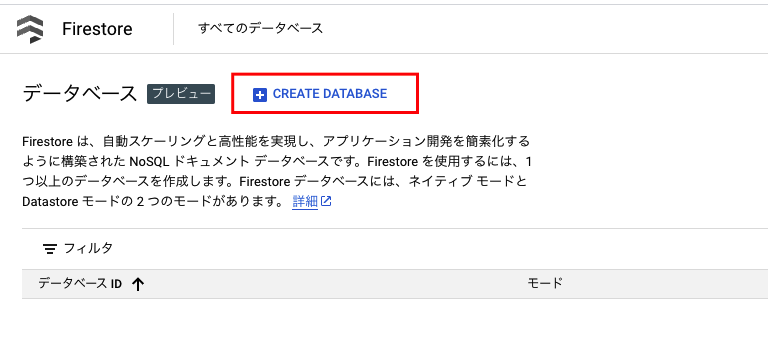
ネイティブモードを選択。
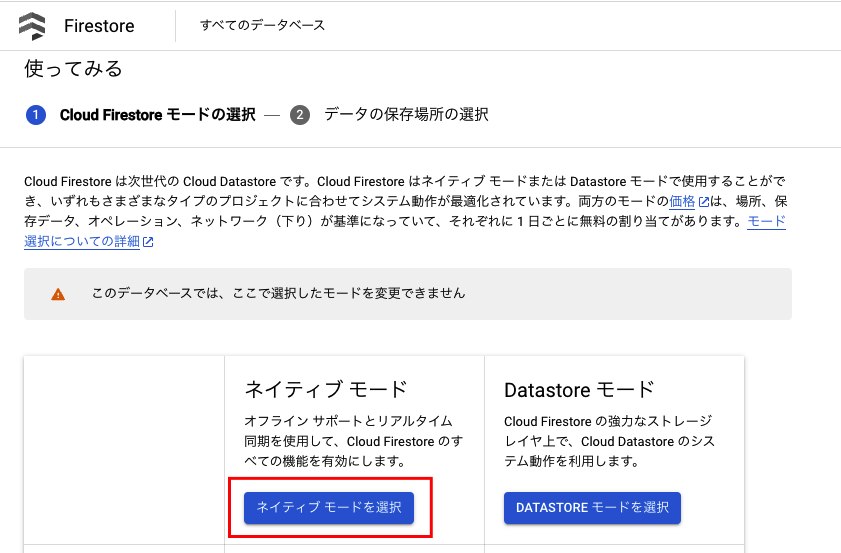
ロケーションを選択して、データベースを作成。
ロケーションは最寄りを選択。
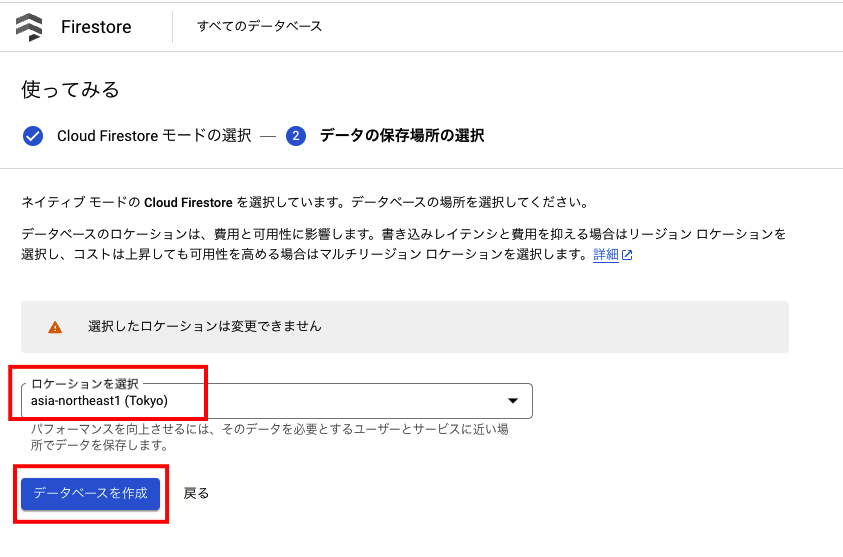
ネイティブモードでデータベースが作成されていればOK
deploy.sh を編集して、イメージのビルドとプッシュ、Cloud Runのデプロイまで行う。
deploy.sh スクリプトは、ソースコードをGoogle Cloud に
デプロイするための一連のコマンドが書かれていますが、
サンプルは Container Registry に対して、
イメージをビルド、プッシュするようになっている為、
これを Artifact Registory にデプロイされるように修正します。
vimコマンドを使って、テキストエディタを開く。
vim deploy.sh
キーボードの i を実行して、編集モードに切り替える。
Artifact Registory に対して、
イメージのビルドとプッシュが行われるように、
下記のサンプルコード通りに書き換えてください。
GCPのプロジェクトIDのみ、自己の環境に書き換えてください。
リージョンは予め指定していますが、最寄りでない場合は書き換えてください。
GOOGLE_PROJECT_ID=# YOUR GCP PROJECT ID GOES HERE
REPOSITORY_NAME=dog-breed-api
LOCATION_NAME=asia-northeast1
gcloud builds submit --tag $LOCATION_NAME-docker.pkg.dev/$GOOGLE_PROJECT_ID/$REPOSITORY_NAME/barkbarkapi \
--project=$GOOGLE_PROJECT_ID
gcloud run deploy barkbark-api \
--image $LOCATION_NAME-docker.pkg.dev/$GOOGLE_PROJECT_ID/$REPOSITORY_NAME/barkbarkapi \
--platform managed \
--region=$LOCATION_NAME \
--project=$GOOGLE_PROJECT_ID
入力が終えたら、保存して編集モードを解除してください。
キーボードの : + w + q を実行で編集モードを解除できます。
deploy.sh スクリプトを実行して、Artifact Registory に
対して、イメージのビルドとプッシュを行ってください。
./deploy.sh
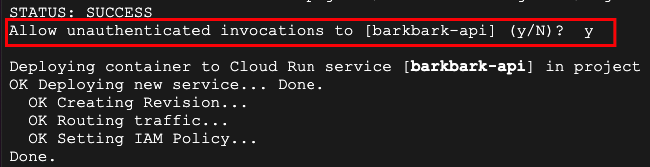
コマンド実行中に、Google Cloud Runサービスを
デプロイする際に、認証されていないユーザーからの
リクエストをサービスが、受け入れるかどうかを尋ねられます。
認証されていないユーザーからのリクエストを受け付けるなら、y
Google Cloud の IAMを通じて、特定のユーザー
もしくはサービスアカウントによるリクエストのみ
許可するなら、Nを入力してください。
Allow unauthenticated invocations to [barkbark-api] (y/N)?
デプロイされた Cloud Run の URL を実行して、
レスポンスが変えれば、Cloud Run のデプロイは完了です。


コレクションとドキュメントを手動で登録する。
Cloud Run の URL を使って、特定のパスに対して、
HTTPの GET リクエストが送れるように手動で、
コレクションとドキュメント作成します。
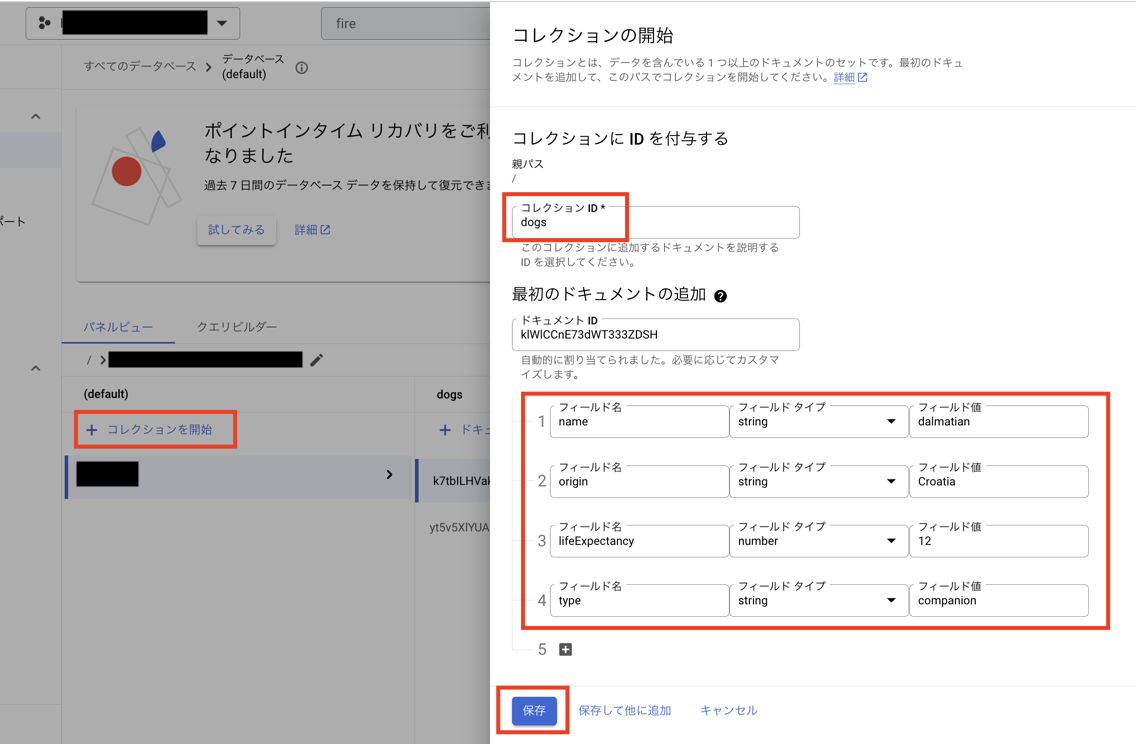
コレクションの登録画面が開いたら、
コレクションIDやドキュメント内の
フィールド情報を埋めて保存してください。
犬種 dalmatian の品種情報を登録します。
入力手順は、スクリーンショットを参考にしてください。
"name": "dalmatian",
"origin": "Croatia",
"lifeExpectancy": 12,
"type" : "companion"
Postmanを使って、コレクションとドキュメントを登録する。
コレクションとドキュメントを直接操作するのではなく、
Postmanを経由して、JSONデータを渡して、
登録する方法もありますので、ここではそれを実践します。
コードはすでにサンプルに書かれているので、
ここでは説明を省き、動作だけを確認します。
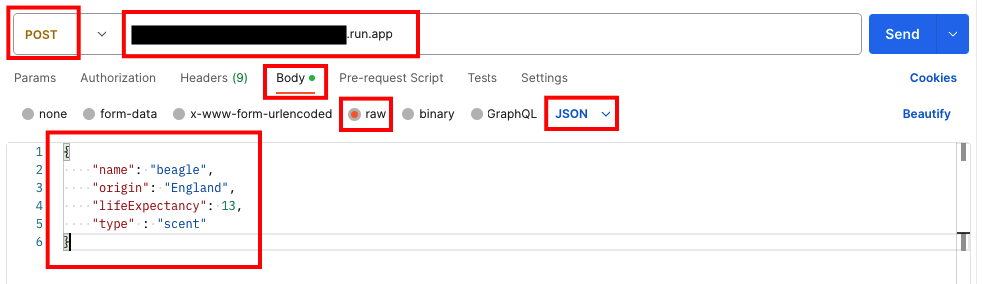
犬種 beagle の品種情報を登録します。
入力手順は、スクリーンショットを参考にしてください。
URL は、Cloud Run にデプロイされた対象のサービスを指定してください。
{
"name": "beagle",
"origin": "England",
"lifeExpectancy": 13,
"type" : "scent"
}
特定のURLのパスを実行して、Firestore からドキュメントを取得する。
Cloud Run の URL を使って、特定のパスに対して、
HTTPの GET リクエストを渡すことができれば成功です。
[デプロイしたCloudRunのURLのパス]/dalmatian
[デプロイしたCloudRunのURLのパス]/beagle

終わりに
今回の記事は、動画を視聴しまして、
実際に『手を動かしてみた』という内容でまとめました。
Cloud Firestore データベースは、これまで触れたことがなく、
特にネイティブモード と Datastoreモード に惑わされてしまいました。
知らぬ間に、 Datastoreモード で、
Cloud Firestore データベースが作られてしまっていた為、
初めからプロジェクトを作り直すことになってしまったり、
全く関係のない、Firebaseプロジェクトを立ち上げてしまう等、
てんてこ舞いとなって、実装までに、時間がかかってしまいました。
Cloud Firestore データベースを使って、
NoSQLのドキュメントを管理したいが、
その前に軽く学習してみたいと考えていましたら、
参考にしていただけると幸いです。
あとで『じっくり読みたい』、『繰り返し読みたい』と
思ってくれましたら、『ストック』へ登録、
この記事が読まれている方にとって、
参考になる記事となりましたら、『いいね』を
付けていただけますと、励みになりますので、
よろしくお願いします。