背景
ライブイベントの楽しみのひとつに、ファンが贈るフラワースタンドがあります。簡素なものから豪華なものまで様々な趣向の凝らされた花が会場のロビーや特設フラスタ置き場に並ぶ様は壮観です。僕自身もフラスタを贈ったことがあります。
まずはじめに、フラスタと言われてよく新規オープンした飲食店の前に置いてあるような形式的な花を想像している方向けに、我々オタクがイベントに出す花というのがどういうものか、ちょっと例示して認識を合わせておきます。

さて、2020年末の世の中はCOVID-19全盛です。様々なイベントが中止やオンライン開催を余儀なくされたり、集客開催できるイベントでも人の密集を避けるべく祝花の受付・掲出を行っていないケースが多いようです。確かにフラスタコーナー、みんな写真撮りに来るので密もいいところですからね。
悲しい話ではありますが、ただ悲しんでいるだけでなく何かできることはないだろうか、と考えた結果、オンラインでフラスタを掲出できるサービスがあれば、もちろん非公式なものですがファンが推しへの想いを表現できたり交流のきっかけになるかもしれない、というアイデアに思い至りました。
作ったもの
GitHub : https://github.com/yazin/flowerstand
この記事が公開される前日、2020/12/19に本番公開しましたが、公開しただけでは当然人は来ないので、この記事が実質プレスリリースみたいな位置付けになります。
このサイトはラブライブ!に絞ったものですが、設計自体はサーバーサイドは完全にコンテンツ非依存、フロントエンドも一部配色など程度でできるだけ汎用性の高い作りにしていて、DBとS3にあるデータでそれっぽさを出しています。Forkして適当に調整してもらえれば他のコンテンツにも使えるかと。
コンテンツを絞っているのは、いきなり無闇にユーザーの裾野を広げたくないのと、自分の知らないコンテンツについては適切なモデレーションができないためです。
このサービスでできること
宛名や贈り主の情報を入力するだけで簡単にフラワースタンド画像を作成してサイト上に表示することができます。自分で描いたイラストパネルを添付して豪華にすることもできますし、イラストが描けなくても花の色を選んだりして簡単なパターンオーダーで出すこともできます。
こんな感じのものがさくっとできます。画像はイメージです。
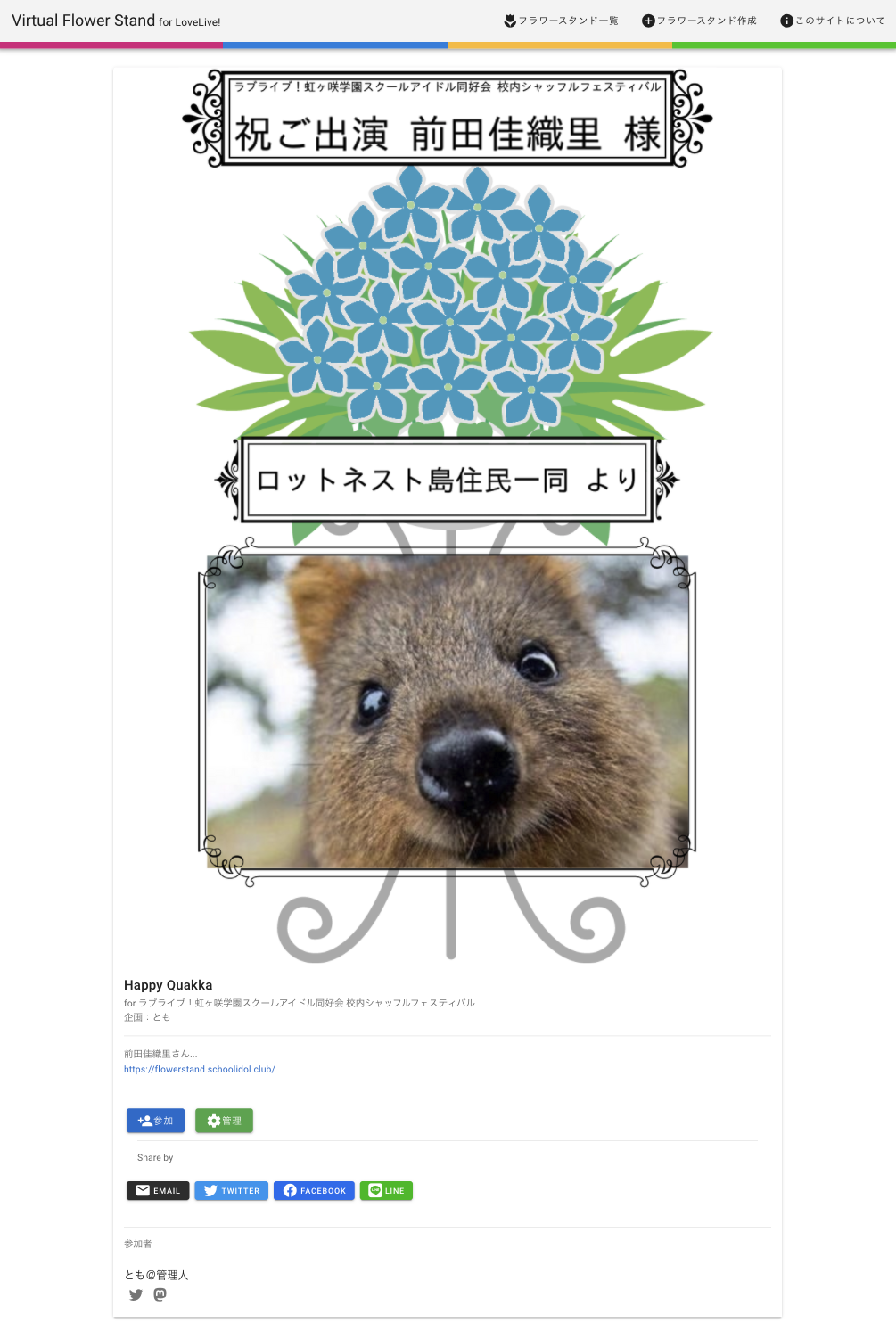
通常、フラスタを出す際はそれなりのお金がかかりますが、本サービスではなんと無料です。以前Aqoursの5thライブにフラスタ出したときは8万円くらいだったかな、天候不順と混雑のせいで自分で企画したフラスタの現物を自分で見られなかったという悲しい出来事がありました。
他の人の掲出したフラスタに賛同者として参加することもできます。複数人で合同でフラスタ出すときに、パネルに参加者の名前が並んでたりしますね。アレです。企画者が認めた人だけが参加できるように、参加には企画者に発行した参加コードが必要です。
サイトのトップページにはフラスタが並んでいます。簡単な絞り込み機能はありますが、リアルな会場の雰囲気を多少なりとも再現すべく、詳細な検索や並び替え、ランク付けなどはあえて実装していません。どんなフラスタでも平等にみんなの目に触れる、というのがこだわりのひとつです。
作業量
あまりよく覚えていないんですが最初に手を動かし始めたのは9月頃だったと思います。本気出し始めてGitHubにリポジトリ作ったのが11月。リリースが12月なので期間的には3ヶ月ちょっとくらいです。アイデア自体はもう少し前からありました。
夏頃から体調を崩してしばらく仕事を休んでいて今も半ばリハビリみたいな状態で、作業療法のノリでのんびり作っていた面もあるので工数云々の参考値としては極めて弱いですが、作業時間は平均すると平日休日問わず1日あたり1〜2時間程度でしょうか。調子の悪い日は何もしなかったし調子のいい日は半日くらいやってたかもしれない。2時間3ヶ月休日なしで雑に計算すると1.5人月という数字が出てきました。
技術の話
まず自分のバックグラウンドについて。僕の現在の本業は旅行会社のサーバーサイドエンジニアで主にPHP書いてるのですが、転職回数が多かったり受託開発で小さい案件を数捌くような仕事をしていたこともあり、過去には様々な技術を扱ってきた経験があります。いろいろできるけど得意な技術は特にない、という悲しいフルスタックエンジニアの典型例です。プロジェクトマネージャーや品質管理やプリセールスやってた期間がキャリアの半分くらいを占めるので最早エンジニアという表現すら違うのかもしれない。
テクニカルな仕事ではC++やC#やJavaなど静的型付けの言語の経験が比較的長い一方、個人で軽く何かコード書く時はJavaScript(Node)やPythonがメイン、フロントエンドはここ数年ではAngular/React/Vueを一通り触ったけどFluxに深刻なトラウマがある、デザインはWCAGだのJIS X 8341だのという仕事もしていたものの、自分で本格的なWebデザインができるかというと致命的なセンスの欠如によりNo、インフラはメインはAWSですが場合によりGCPとAzureも使っていて自宅サーバーは2年ほど前に全廃、といったところです。管理しているサーバーの.bashrcや.zshrcにはだいたいalias vi=emacsと書いてあります。
本記事には個別の技術についての踏み込んだ話は書きません。コードはGitHubを見ていただければと思います。また、本サービスの開発にあたって苦戦したことや学んだことをいくつかQiitaに記事として投稿しているので、興味があればそちらもご覧ください。
全体構成
VueのSPAとExpressのAPIサーバー、というわりとよくある構成です。言語はどちらもTypeScriptを採用しています。インフラやツール系はGitHubとSwaggerHub以外は全てAWSで完結しています。
ある程度の規模のもの作るなら型がないと後で苦しむよね、というのは、20世紀末にPerlで開発されドキュメントもまともに残っていない200画面超のWebシステムのマイグレーション案件を仕事でやったときにつくづく思い知りました。この$_や@_にはどんな内容が入ってる可能性があるのか、この関数は何を返すことを期待されているのか、実装と乖離したコメントや最悪ベトナム語で書かれてるコメントに惑わされず逐一遡って調べるのとか本当に拷問なので、PerlやRubyや生JavaScriptで大規模システムの構築・保守ができる人たちすごいなー、と思いつつ、自分ではやりたくないのでフロントもサーバーも可能な限り静的型付けの言語を使っていきます。
最初にざっくりした画面遷移や構成を考えて頭に置いた上で、まずサーバーサイドのAPIから作り始め、Swaggerから叩いて一通り動くようになってからフロントエンドを作り始める、という流れで進めました。
主要技術スタック
- Server
- Node
- Express
- OvernightJS
- InversifyJS
- TypeScript
- sharp
- Amazon Rekognition
- Frontend
- Vue
- Vuetify
- TypeScript
- Database
- MySQL
- TypeORM
- Web
- Nginx
- Infrastructure
- AWS
- EC2
- Application Load Balancer
- Auto Scaling Group
- Amazon S3
- AWS Lambda
- AWS
- CI
- GitHub
- AWS CodeBuild
- AWS CodeDeploy
- AWS CodePipeline
- Document
- SwaggerHub
サーバーサイド
大雑把にまとめるとサーバーサイドでやることはフラスタの情報のDBへのCRUDと画像の生成処理の2つと、それに付随する考慮事項がいくつかです。
フレームワーク
TypeScriptを使ってExpressのサーバーアプリケーションを開発する場合、方法として比較的よく見かけるのが、express-generatorで生成したJavaScriptのコード一式をTypeScriptに対応させるように書き換える、というもの。ピュアTypeScriptで開発したいのでそれは絶対に嫌でした。
かといってExpressのアプリケーションをフルスクラッチで書くのもつらいので、いろいろな方法を模索していた結果辿り着いたのがOvernightJSでした。日本語の情報が全く見当たらないので日本で僕以外に使ってる人いるんだろうか、と思う程度にはマイナーな代物ですが、開発が止まっているわけでもなく、TypeScriptに対応したボイラープレートやライブラリやフレームワークの中でもTypeScriptネイティブで最もシンプルに実装できそうだったので採用しました。
OvernightJSによるAPIサーバー実装については以下の記事で紹介しています。
OvernightJSでNode+Express+TypeScriptなAPIサーバーを構築する
DB周り
データモデルは至ってシンプルです。フラワースタンドの情報が中心にあり、その属性として使われるマスタ(宛先のメンバーや掲出するイベントなど)が何種類かある、というだけ。環境がNodeなので何も考えずにMongoDBを選びがちですが、直接DBを触らずきちんとORマッパーを噛ませて作りたいな、と考えたので、先にNode/TypeScriptの環境に適したORマッパーを探しました。
結果TypeORMが最有力っぽい、ということでこれを採用。バックエンドとして使えるDBMSは種類豊富で選び放題ですが、プログラムから見て同じように扱えるのであればNoSQLにこだわる必要もないので、使い慣れていてRDSでマネージドサービスの恩恵も受けやすいMySQLにしました。
ちなみにマスタ管理画面的なものは全く作っていません。イベントとかのデータはスクリプト書いて投入してます(ORM使ってるので直接SQLというわけにはいきません)。今の時点で必要のないものは必要になってから作ります。
画像生成
現実のフラスタは豪華なものは際限なく豪華なので画像生成は凝り始めるときりがないのですが、最初は基本的なところから、ということで、リアルにフラワースタンドを出す際に花屋さんから必ず聞かれる情報、すなわち宛名・贈り主・花の色の3つと、それだけだと素っ気ないのでオプションでイラストパネルを1枚、の4要素の合成でまずは割り切っています。
花の色の指定の仕方も無限にありますが、今回紹介するサービスで扱うラブライブ!では好都合なことにメンバー全員にイメージカラーが割り当てられています。これを利用して、誰宛の花かを選ぶとそれに応じて花の色が決まるようにしました。この「誰宛」の選択とは別に宛名をテキスト入力できるようになっています。同じ色でもキャストさん宛だったりキャラクター宛だったり愛称だったり、我々オタクはいろいろとめんどくさいので。
フラワースタンドの画像の下地はフリー素材で、花に動的に色を付けるのは難しいので手作業で着色した画像をパターン数分作ってS3に置いておき、合成時にはそこから取ってきて使う形にしています。
画像処理にはsharpを採用しています。Nodeで画像処理をやるには他にもJimpや、ImageMagickを直接使うなどいくつか方法はありますが、画像の合成という観点で見るとsharpが扱いやすそうでした。Jimpはどちらかというと加工に強いようです。
ユーザーが入力した宛名や名義、イベント名などは文字列を画像に変換する必要があるので、その処理はtext-to-svgを使っています。その名の通り文字列をSVGに変換してくれるので、その変換結果をsharpに渡して合成すれば完成です。できた画像はS3の公開バケットにアップロードしてURLをDBに保存します。
コンテンツモデレーション
完成した画像、そのまま公開しても大丈夫でしょうか。危ないですよね。特にアップロードされたイラストの内容の健全性チェックはプログラムでは難しいですし、かといって都度人間がチェックするのはとてもやってられません。とはいえ、昨今はいろいろとよろしくない画像を放置しておくとサイトの運営者が責任を問われたりする場合がありそうです。
ここはAIに頼ります。AWSにはAmazon Rekognitionという画像認識AIがあります。最低限の露払いはこいつにお願いしています。
Rekognitionによるモデレーションについては以下の記事にまとめています。
Amazon Rekognitionでユーザーがアップロードしたアレな画像を収集ブロックする
DI
ここまで、画像はS3にアップロード、モデレーションはRekognition、という説明をしてきましたが、実際に使うサービスを後から切り替えができるようにこの2つにアクセスするクラスはInversifyJSでDIしています。S3が高コストなので他のストレージサービスに切り換えるとかローカルストレージ保存に切り換えるとか、画像認識をRekognition以外のAIサービスなどに切り換えるとか自前で機械学習で頑張るとか、そういうことが既存コードにほぼ手を加えずにできるようになっています。
システム外部の特定のサービスに強く依存してしまうと、仕様面でも費用面でも状況の変化に追随できなくなることがあり得るので、この手の機能では現時点で特に予定がなくてもとりあえずDIでワンクッション挟んでおくとよいと思います。
フロントエンド
Vue CLIで作りました。最近のフロントエンドの技術にはあまり詳しくないのでプロジェクト作った当時は「Nuxt?聞いたことはあるけどまあ今回はいいか」という感覚でスルーしたんですが、その後Vue/TypeScript関係で調べ物をしていると掘っても掘ってもNuxtを使った情報しか出てこない。応用はできるのでそれほど困ってはいませんがトレンドに乗れず若干後悔しているところはあります。
教訓。技術選定にはちゃんと時間と労力をかけるべき。
サービス内容的にSEOを気にする類のものでもないのでSSRにこだわる必要もないか、と自分に言い聞かせながら粛々と開発しています。
UIフレームワークはVuetifyです。これは本業でVuetifyを触るようになったため、その勉強を兼ねて採用しました。本業ではすでに他の人が作ったものの保守なので、今回自分で0から作ってみた結果いろいろと理解が進み、本業にもプラスの影響が出ているように思えます。
最低限レスポンシブな作りにしてあるので、スマートフォンやタブレットでもそれっぽく見えると思います。PCでもSPでも古いブラウザだと動かないかもしれませんが、今更IE11とかサポートする気もないのでそのへんは割り切って切り捨てています。この手のサービス使うのに「IEしか使えない環境」とかまずあり得ないと思いますし、そんなセキュリティポリシーがっちがちな環境でこんなサイト見てちゃ駄目ですよ仕事してください。
Vuex?あーあー聞こえないー。
インフラ
この記事が公開される日はリリース翌日の予定で、このサービスがバズるか見向きもされないか全く読めないので、インフラについてはあくまで仮組みしたものです。
開発用にはDockerのコンテナ4つ、サーバーサイド・フロントエンド・Nginx・MySQLをdocker-composeで動かしています。スケーリングとSSLを考えないなら、セキュリティグループで80と3000を開けたEC2インスタンス上でリポジトリをcloneしてdocker-compose upで本番環境のできあがりです。簡単で安上がりですがユーザー数が増えてくると詰むやつです。なので、ひとまず以下のようにちゃんと作ります。人が集まらなければひっそりとDocker運用に縮退します。
全体像はこんな感じです。
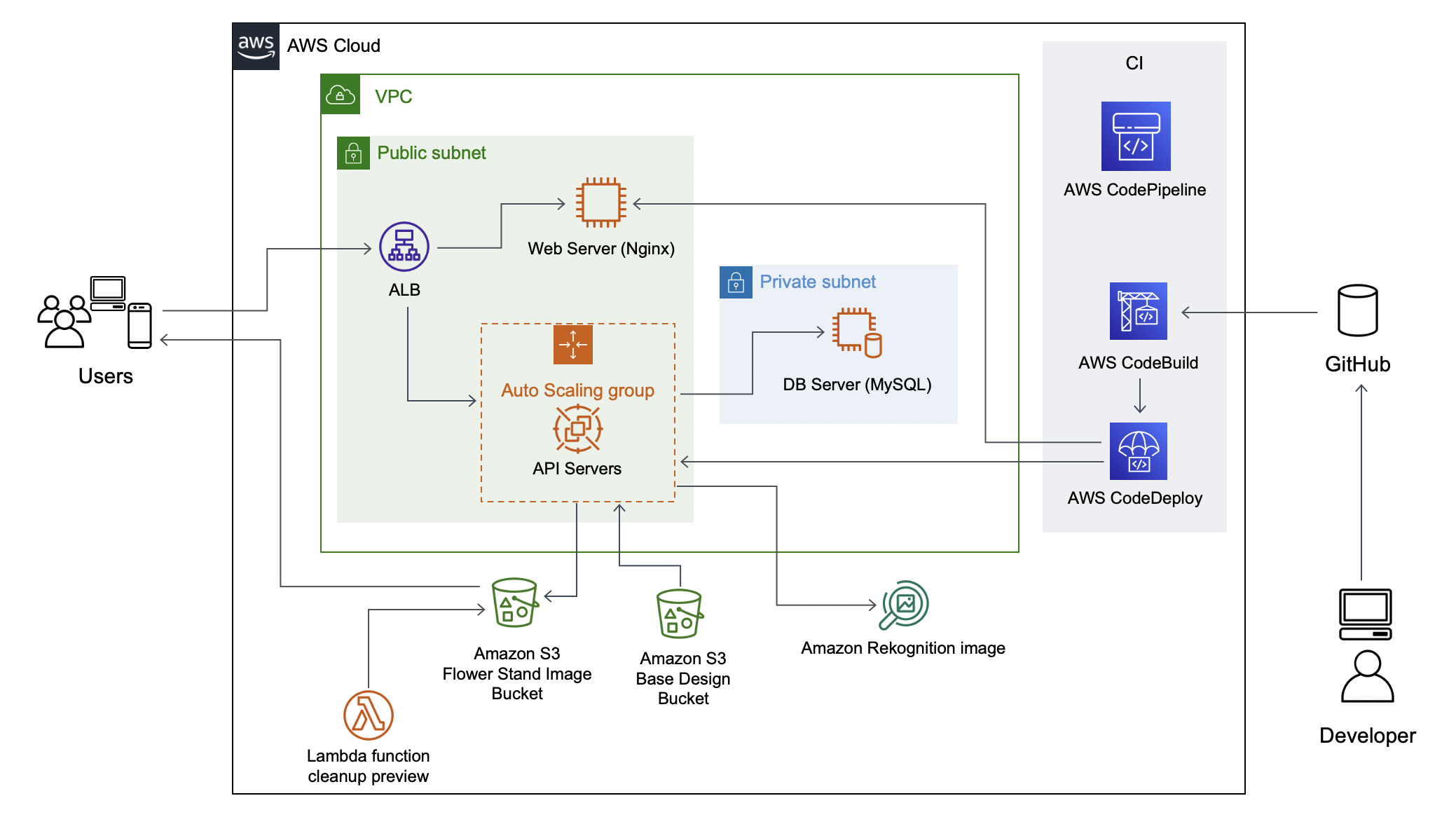
サーバー上にはログ以外のデータは置かない、画像生成も中間ファイルとか作らず全部オンメモリで結果は直接S3に投げ込む形で、全てのAPIが相互依存関係を持たず冪等になっているので、スケールしやすい作りだと思っています。
APIサーバーについてはAuto Scaling Groupで負荷に応じて必要なだけEC2インスタンスを起動するようにしてApplication Load Balancerに分散してもらえば、迂闊にバズってもある程度はどうにかなります。おそらくシステムへの負荷より先に僕のクレジットカードへの負荷が制約になるでしょう。サーバー上にデータを持たない=サーバーをカジュアルに立てたり潰したりできるので、APIサーバーたちはスポットインスタンスで比較的安く上げることができます。
・・・あれ?
この記事を書いていて気付いたこと。これだけ状態持たず冪等になっているのなら、APIはLambdaとAPI Gatewayでサーバーレスアプリケーションにすればよかったのでは?ユーザー全然来なくてもコストかからないし。ほら最近はLambdaからRDSつながるし。
というわけでここでも技術選定の甘さが露呈しました。個人開発は勢いも大事ですが、技術選定時に下した決断は後から変更するのが難しいことが多いので、考えるべきところは冷静になって考えた方が後々幸せです。
DBは一旦コスト節約モードでEC2インスタンス上でMySQLを動かして、様子見ながら必要であればRDSに移行、という感じです。このインフラ構成だと何かの弾みでアクセス殺到したときに最初に死ぬのは多分DBサーバーですが、RDSは最小限の構成でもぼちぼちお金かかるし、いきなりリザーブドインスタンス購入するのもギャンブルなので・・・。
受託で開発やってたときは、気前のいいお客さんの案件であれば「ユーザー数増えてきてサーバー負荷上がってきたのでインスタンスサイズをc4.8xlargeに上げますねー」とチャットで一言入れてコンソールでぽちっとやって請求書に書けば済んだりもしたのですが、個人でやっているとそんな富豪的アプローチも取れないので、インフラ考えるときは仕事の時以上にお金にシビアになる必要があります。
CI
CIといえばCruiseControlやContiniuumやJenkinsのサーバー立てる時代もありましたが、最近は各種クラウドプラットフォームが提供するサービスにGitHub Actionsとかもあり選択肢が増えてきました。何を使うか結構迷ったんですが、インフラが一通りAWSなこともあってAWSのCodeシリーズを使っています。
GitHubをソースリポジトリとして、CodeBuildでビルド、CodeDeployでデプロイ、という一連の流れをCodePipelineで管理しています。CodeDeployに関しては特に日本語の情報がまだまだ少なく、AWSの公式ドキュメントも機械翻訳の日本語がわりとひどく英語で読んだ方が楽、という状況なので、そのうち記事にまとめようと考えています。
ソースリポジトリとしてCodeCommitという考えもあったはあったのですが、結局はエコシステムの差と、CodePipelineがGitHubをわりと手厚くサポートしていることもあり、ここだけはAWSの外に出しました。GitHub使いたい要望さぞかし多かったんだろうなあ・・・。
CodeDeployの罠
個別の技術の詳細は書かないと言いつつ、突っ込みに備えて1つだけ補足しておきましょう。
先ほどのインフラ構成図を見て、あれ?と思った方もいるのではないでしょうか。Private subnet切ってDBサーバー置いて、やれてる系インフラっぽい感じなのに、なんでALB通してるWebサーバーとAPIサーバーがPublic subnetにあるの?と。
最初はPrivateに置くつもりでした。実際インスタンス立ち上げるところまでやりました。ところがCodeDeployが初手ApplicationStopでエラーコードも何もなしにこける。あれこれ調べてみると、どうやらCodeDeployの対象になるインスタンスはインターネットに出て行ける必要があるとのこと。つまり、Private subnetにあるインスタンスにデプロイするのであればNATゲートウェイかNATインスタンスを用意する必要がある、ということです。
いやここまできてそんなお金は・・・。
ということでとりあえずPublicに移動して解決した次第です。あまり良い解決策ではないと思うので何とかしたいですが、Publicにあることでsshで直接接続できるというメンテナンスの楽さもあり、なんかもうこのままでいいかもしれない、と思っている節もあります。
得たものまとめ
エンジニアの技術力は書いたコードの量や立てたサーバーの数や潰したサーバーの数だけついていくと思っていて、どんなものでもとりあえず作ってみることには意味があり無駄になることはないと考えています。
今回はVue使うコードがだいぶすらすら書けるようになりました。インフラ面ではAuto Scaling Groupの利用やCIをフルオートにするあたりが初めて扱った部分で、個人でちょっと触ってみるというには敷居の高めな技術を学べたと思ってます。
また今回のサービスは、僕が個人で作ったもののなかではかなり大きな部類になります。これまで仕事では完全な新規開発はかなりレアで、大半はすでに誰かが作ったものの機能追加や改修だったのと、開発は複数人で分業でやることが多かったので、0から全部1人で作ってみて特に気付いた点は以下です。
- 雑に手を動かし始める前に、後から変更できるところとそうでないところを見極めて、変更できないところは最初に時間をかけて詰めて考える
- 収益や採算を考えないサービスであればこそ、長期継続のために現実的に支払える運用コストを意識するのが重要
- 自分が好きなもの、自分がユーザーとして使いたいものを作っていれば、手間や時間がかかっても一時的に行き詰まっても苦しくないので効率よく学べる
余談
困ったら猫
Webシステムの開発には付きもののエラー画面の実装。NginxやApacheのデフォルトのエラーページ出したりしてませんか?あるいは内部エラーの内容について事細かに説明しようとしていませんか?
そうではないのです。猫です。猫を出すのです。インターネットの最上位存在である猫を前にしてはいかなるクレーマーも黙るのです。
これは冗談ではなく、toCサービスにおけるエラー処理の在り方としてわりと本気で考えて書いています。作っているのが業務システムであれば、エラーの詳細な情報を表示することで情シスによるトラブルシューティングの助けになるでしょう。ですが、コンシューマー向けのサービスで同じことをやったらどうなるでしょうか。
一般的にユーザーは、サービスを利用して意図した結果が得られなければマイナスの感情を抱きます。仕事で使うシステムなら文句言いながら仕方なく使い続けるでしょうが、そうでない場合は機嫌を損ねたユーザーはすぐに離れていきます。場合によってはインターネット上に悪評が広がります。ユーザーを待たせず捌けるサポート窓口を開設しているなら問い合わせに必要な情報としてエラーの詳細を表示するのは妥当な範囲ですが、そうでない限りはシステム内部で起きたことを説明しようとしてもユーザーの感情を逆撫でするだけです。かといって、ただ平謝りするような内容だとモンスタークレーマーの発生源になります。toCサービスのエラー画面が果たすべき役割は、まず第1にユーザーの感情を受け止めてケアすることだと考えています。
エラー処理は本気で作り込むと非常に大変ですが、高い信頼性や可用性が求められないシステムであれば、短期間で開発してとりあえずリリースするためにエラー処理を猫に任せるのは合理的です。ユーザーの苛立ちを和らげるにはボートの映像などもユーザー層によっては有効ですが、経験上ベストソリューションは猫です。
いいですか聞こえていますか。鯨や宇宙人ではないのです。猫です。猫をよこすのです。

個人開発もうかるの?
時々聞かれることがありますね、この質問。
学生時代にプログラミングを学び始めてからかれこれ20年ちょっと経ちますが、その間に仕事以外で書いたコードや運用しているサービスで収益を得ようと試みたことは一度もありません。お金を頂く=相応の責任が発生する、ですが、フルタイムでサラリーマンエンジニアをやっている以上当然本業が最優先であり、趣味でやっていることに対して十分な責任を負うことができません。個人運用しているMastodonサーバーも、平日昼間に障害でダウンすると復旧作業ができずに夜までダウンしたまま、ということもありました。有料サービスでそんなサービスレベルなんて論外ですよね。
サーバーの運用費くらいは賄えるとありがたいので寄付ボタン置いたりAmazonの欲しいものリストのリンク置いたりくらいはしてますが、寄付は課金ではないので強制はしないですし、寄付してくれた人に対してもお礼は言いますが優遇することはありません。広告もいろいろ考えたことはあるのですが、自分が本当に意図した以外の情報が表示されることはサイトの凝集度を損なうと思っていて、また単に個人的に嫌いというのもあって現在は一切出していません。本当はCoinhiveみたいなのが理想なんですが、今の日本ではウイルス扱いされてしまうようで困ったものです。
そんなわけで、現在運用しているサービスやWebサイト合算で、月に15,000円ほどを主にAWSに支払っています(為替の影響を受けます)。集まった寄付金額はここ2年で合計500円くらいです。毎月の支払額に今回のサービスの分はこれから加算されるので、来月から2万円くらいになるかもしれません。採算 is 何。
この手の話をする際にいつも思い出すのが、以前某バンドセッションの打ち上げの席で某ギター滅茶苦茶上手い人がなんでそんなに上手いのにプロにならないのかと聞かれて、こういうのはアマチュアで好き勝手やってるから面白いんだよ、と返していた話です。別にプロミュージシャン=報酬を得ながら開発してるエンジニアが、アマチュアミュージシャン=趣味で好きなものを開発してるエンジニアの上位存在というわけではないんですよね。ソフトウェア開発以外の仕事を本業としながら趣味でプログラムを書いている人たちにはぜひ、自分たちはプログラミングで稼いでいる人たちに対して見劣りする存在じゃないんだぞ、と自信を深めていただきたいです。いやむしろすごいよ。
さて、どうして僕が何の得にもならなそうな個人開発をやっているのか。リーナス・トーバルズの伝記書のタイトルで本記事を締めましょう。
「それがぼくには楽しかったから」