はじめに
以前コードレビューをしたときに、日時形式のバリデーションに正規表現が利用されていたので、 time.Parse 使おうとコメントしました。また、それについて記事にしてみようと伝え、記事も書いてもらいました。
あらためてベンチマークを実行すると、time.Parseによるチェックが高速なことが分かります。
var validater = regexp.MustCompile(`\d{4}(/\d{2}){2} \d{2}(:\d{2}){2}`)
func BenchmarkRegexpPack(b *testing.B) {
b.ResetTimer()
for i := 0; i < b.N; i++ {
validater.MatchString("2012/12/10 12:30:45")
}
}
func BenchmarkTimePack(b *testing.B) {
layout := "2006/01/02 15:04:05"
b.ResetTimer()
for i := 0; i < b.N; i++ {
time.Parse(layout, "2012/12/10 12:30:45")
}
}
// BenchmarkRegexpPack-12 4026220 295 ns/op
// BenchmarkTimePack-12 7007890 171 ns/op
ここでは、なぜ time.Parse は高速に処理ができるのかをチェックするとともに、Goでパターンマッチを高速に行いたい場合にどのように実装すればよいのかを見ていきます。
time.Parse の実装
ソースコードでいうと、主な処理は parse と nextStdChunk にまとめられています。
簡単に説明すると、以下のようなステップで実行されています。
- layoutを元に、日時に関係がある部分の文字を文字列として切り出す
- 切り出した文字列を数値に変換
- layoutを元に、1→2を繰り返す
- 文字列の長さが0になったら、数値への変換プロセスが終了
- これまでの値を元に数値を微調整
- 数値を元に
Date(year, Month(month), day, hour, min, sec, nsec, defaultLocation)としてtime.Timeを返却
この処理のうち、4~5の処理はパターンマッチに関係ない部分です。また1,2の処理も、様々な時間フォーマットに対応するために余分な処理が多く含まれています。しかし、その条件を含めても冒頭のベンチマークでわかったとおりtime.Parseを利用したパターンマッチのほうが高速にできます。
func parse(layout, value string, defaultLocation, local *Location) (Time, error) {
alayout, avalue := layout, value
rangeErrString := "" // set if a value is out of range
amSet := false // do we need to subtract 12 from the hour for midnight?
pmSet := false // do we need to add 12 to the hour?
// Each iteration processes one std value.
for {
var err error
prefix, std, suffix := nextStdChunk(layout)
stdstr := layout[len(prefix) : len(layout)-len(suffix)]
value, err = skip(value, prefix)
if err != nil {
return Time{}, &ParseError{alayout, avalue, prefix, value, ""}
}
if std == 0 {
if len(value) != 0 {
return Time{}, &ParseError{alayout, avalue, "", value, ": extra text: " + value}
}
break
}
layout = suffix
var p string
switch std & stdMask {
case stdYear:
if len(value) < 2 {
err = errBad
break
}
hold := value
p, value = value[0:2], value[2:]
year, err = atoi(p)
if err != nil {
value = hold
} else if year >= 69 { // Unix time starts Dec 31 1969 in some time zones
year += 1900
} else {
year += 2000
}
// ...
}
if pmSet && hour < 12 {
hour += 12
} else if amSet && hour == 12 {
hour = 0
}
// ...
return Date(year, Month(month), day, hour, min, sec, nsec, defaultLocation), nil
}
func nextStdChunk(layout string) (prefix string, std int, suffix string) {
for i := 0; i < len(layout); i++ {
switch c := int(layout[i]); c {
case 'J': // January, Jan
if len(layout) >= i+3 && layout[i:i+3] == "Jan" {
if len(layout) >= i+7 && layout[i:i+7] == "January" {
return layout[0:i], stdLongMonth, layout[i+7:]
}
if !startsWithLowerCase(layout[i+3:]) {
return layout[0:i], stdMonth, layout[i+3:]
}
}
...
類似の事例
その他の標準ライブラリで見ると、 url.Parse もシンプルに実装されています。ソースコードはこちら。
URLスキーマをチェックする部分では、パターンマッチではなく、 'a' <= c && c <= 'z' || 'A' <= c && c <= 'Z' のように文字列をbyte型として取り出し、byteの比較を用いて実装されています。
func getscheme(rawurl string) (scheme, path string, err error) {
for i := 0; i < len(rawurl); i++ {
c := rawurl[i]
switch {
case 'a' <= c && c <= 'z' || 'A' <= c && c <= 'Z':
// do nothing
case '0' <= c && c <= '9' || c == '+' || c == '-' || c == '.':
if i == 0 {
return "", rawurl, nil
}
case c == ':':
if i == 0 {
return "", "", errors.New("missing protocol scheme")
}
return rawurl[:i], rawurl[i+1:], nil
default:
// we have encountered an invalid character,
// so there is no valid scheme
return "", rawurl, nil
}
}
return "", rawurl, nil
}
Goで正規表現をあつかう場合
Goの正規表現が遅いのは、Perl, Ruby, PythonなどがCのライブラリを利用しているのに対し、Goの標準ライブラリはC言語を排除して実装されていることが一因です。
基本的には、言語を抽象化するほど速度は犠牲になるので速度の面ではC言語が有利です。例えばGoから高速に正規表現マッチを利用したい場合、Perl経由でC言語のライブラリを扱えるものを利用するのも手です。様々な言語で正規表現のベンチマークをとったページを参考にすると、go-pcreを利用した正規表現は113個中21番目に位置しており、それほど悪い成績ではないことが分かります。
(それにしてもRustの成績が優秀なので、このあたりは別記事で深堀りしたい)
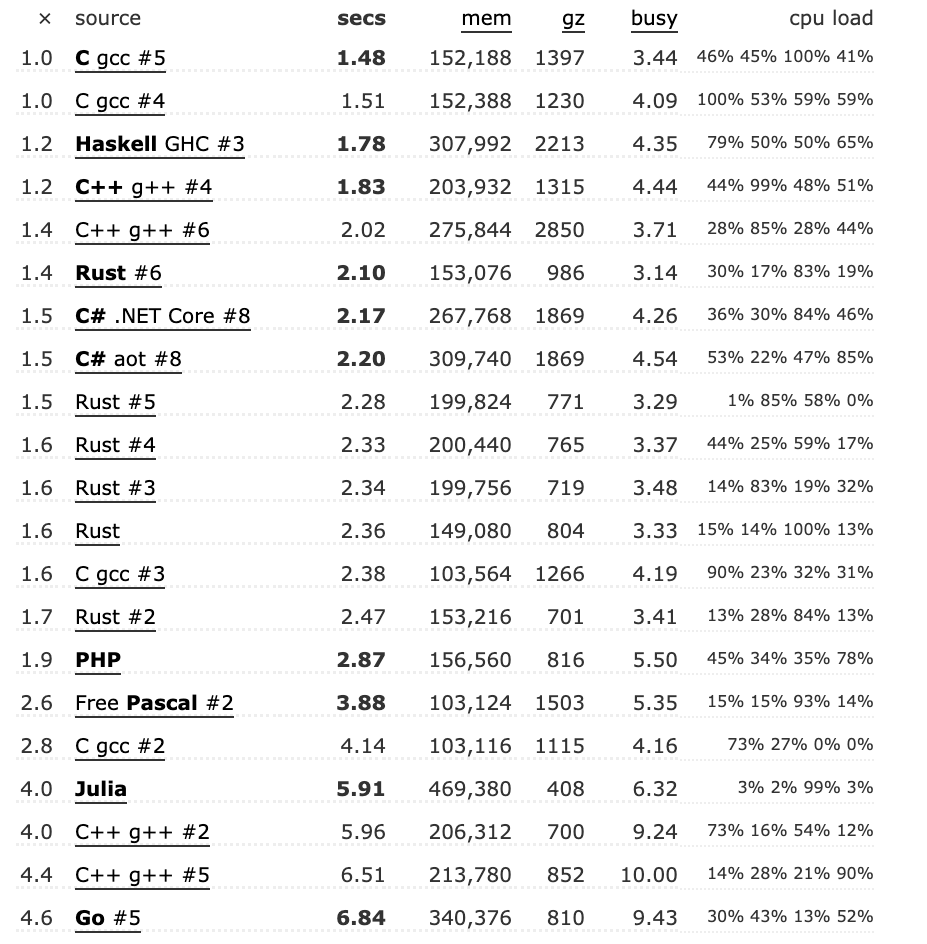
https://benchmarksgame-team.pages.debian.net/benchmarksgame/performance/regexredux.html
ただし、Goの正規表現はNFA(Nondeterministic finite automaton)を利用して作られています。これは、Perl, Ruby, Pythonなどで利用されている再帰的にバックトラッキングしていく方法 O(2^n) に比べ、Goで採用されているのは最悪のパターンのときでも比較的速度を担保(O(n^2))できます。
利用する正規表現によっては、Goの方が早くなることもあるので見極めが必要です。
まとめ
Go言語は、C言語のライブラリを利用している正規表現エンジンに比べて低速になりやすいです。
単純なパターンマッチしているかのチェックであれば、標準ライブラリで利用されている方法のように、文字列チェックして処理すると高速になります。
Goの正規表現を責める前に、まずはprofileの分析を行い、本当にパフォーマンスがクリティカルな部分で正規表現が問題になっているのかをチェック → 問題になっていれば、今回確認したような標準ライブラリを参考にして実装してみるとよいと思います。