久しぶりに記事投稿します!
最近、実務でNode.js+Typescript×クリーンアーキテクチャで開発していて
その中でDI(依存性の注入)を使っている部分があるのですがメリットがあまりわかっていなかったので本記事で纏めてみようと思います。
クリーンアーキテクチャについて軽く
DIを語る前に軽くクリーンアーキテクチャについて少し説明します。
クリーンアーキテクチャは関心事の分離をするという目的を達成するための1つの手法として提唱されています。
クリーンアーキテクチャでは、4層の円が描かれており、各円はソフトウェアの領域を表しています。そして、最も重要なルールとして、依存性は内側だけに向かっていなければならないとしています。
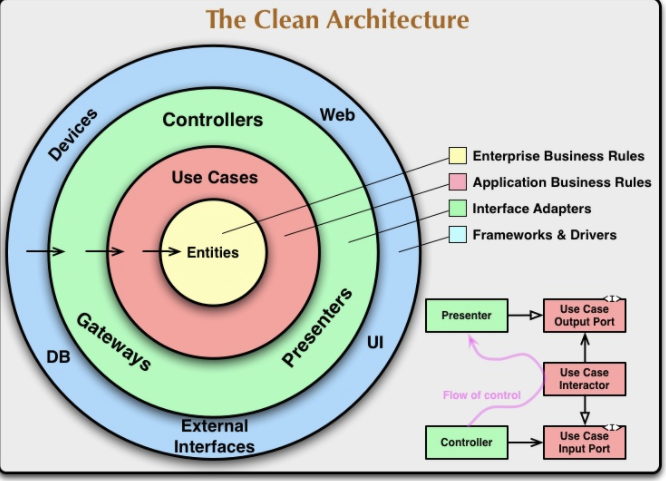
具体的にいうと、
Domain層(Entities)はUseCase層に依存してはいけない。
UseCase層はInfra層(DBや外部API)に依存してはいけない。
UseCase層がInfra層に依存してはいけないのはなぜ?
例えば、UseCaseとして、「タスクを登録する」という振る舞いがあったときを考えてみます。
このときに、「データベースに登録する」や「CSV出力する」といったinfra層の知識が漏れてしいまうと「タスクを登録する」という本来の関心事が読み取りにくくなってしまいます。(ORMやCSV出力の記述があるとコードがややこしくなる)
そのためクリーンアーキテクチャでは関心事を分離をするために依存性を内側だけに向かうようにします。
DIについて
DIを上手く使うことでUseCase層にInfra層の知識が漏れるといった課題を解決することができます。
例えば以下のタスクを登録するUseCaseについて考えてみます。
Infra層の知識が漏れているUseCase
import TaskRepository from '../../../infra/repository/talentRepository'
import TaskDomainModel from '../../../domain/talent/talentDomainModel'
// タスクを登録する
export class CreateTaskUseCase {
execute(
name: string,
accessSource: 'DB' | 'CSV' | 'LOG' // データの保存先を指定:DB保存なのか、CSV出力なのか、LOGを吐くだけなのか
) {
const task = new TaskDomainModel(name)
const taskRepository = new TaskRepository(accessSource)
return taskRepository.save(task)
}
}
こちらはタスクを登録するUseCaseになります。
コードの解説をすると、nameを引数にタスクのDomainModelを生成してRepositoryを使って永続化を行います。
注目したいのが、accessSourceというデータの保存先を意味するInfra層の知識がUseCase層に漏れてしまっている点です。
先程も書いたようにUseCase層にInfra層の知識が漏れるのはクリーンアーキテクチャの関心事を分離するという観点から好ましくありません。
DIを使えばこの課題を解決できます。
改善後のコード
import TaskDomainModel from '../../../domain/talent/talentDomainModel'
import ITaskRepository from '../../../domain/talent/talentDomainRepository'
// タスクを登録する
export class CreateTaskUseCase {
private taskRepository: ITaskRepository
constructor(taskRepository: ITaskRepository) {
this.taskRepository = taskRepository // DIすることでユースケース内にinfra層の知識が漏れなくなった
}
execute(name: string) {
const task = new TaskDomainModel(name)
return this.taskRepository.save(task)
}
}
ITaskRepositoryではインターフェースのみを定義し、実際に保存するという具体的な処理は記載していません。
また、accessSourceという保存先を表すInfra層の知識が漏れていないことがわかると思います。
constructorでITaskRepositoryを受け取り、ITaskRepositoryという抽象クラスに依存している状態になります。
そして、taskRepositoryのインスタンス化は円の外側のレイヤーで行うことになります。(ControllerやCliなど)
ITaskRepository
import TalentDomainModel from './talentDomainModel'
export default interface ITaskRepository {
save(model: TalentDomainModel): Promise<TalentDomainModel>
}
DIのテクニックを使うと、ITaskRepositoryの具体的なクラスがDBに保存するようなDBTaskRepositoryであろうが、 CSV出力するためのCSVTaskRepositoryであろうが、
UseCase内では詳細を気にしなくてよくなります。
実際にはデータを永続化するという抽象的なことには依存しているけど、DBやCSVにデータを永続化するという具体的なことには依存していないため関心事が分離されている状態になります。
このようにDIを使えば、依存関係を整理することができます。
局所的に見れば、「なんでこんなややこしいことするの?」ってなりますが、プロダクトを大きくする上で層ごとの役割を明確にすることで保守性、可読性が上がっていくと思っています。
自分はまだまだこの辺の知識が浅いので頑張って理解します。