0:やりたいこと
日向坂46の全曲の歌詞データを元にword2vecを用いて、
自然言語⇒数値
に変換して遊んでみたいと思います。
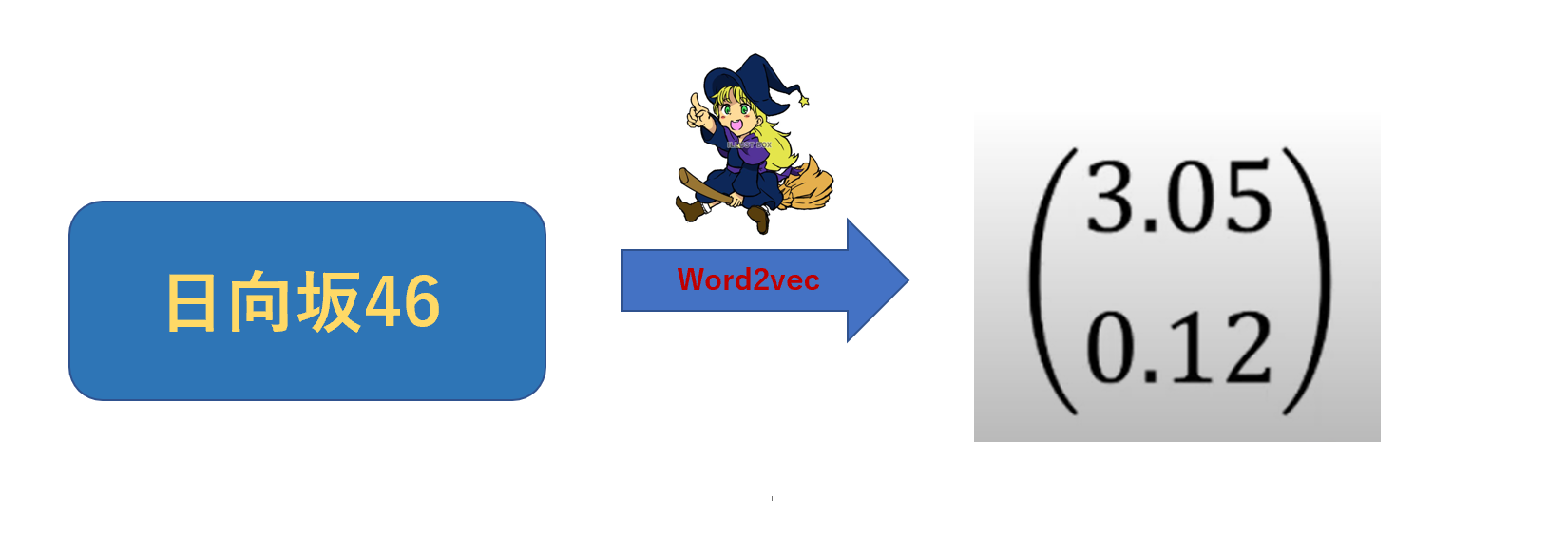
Word2vecとは?
単語をベクトルに変換する魔法
単語がどのようにベクトルに変化するか?
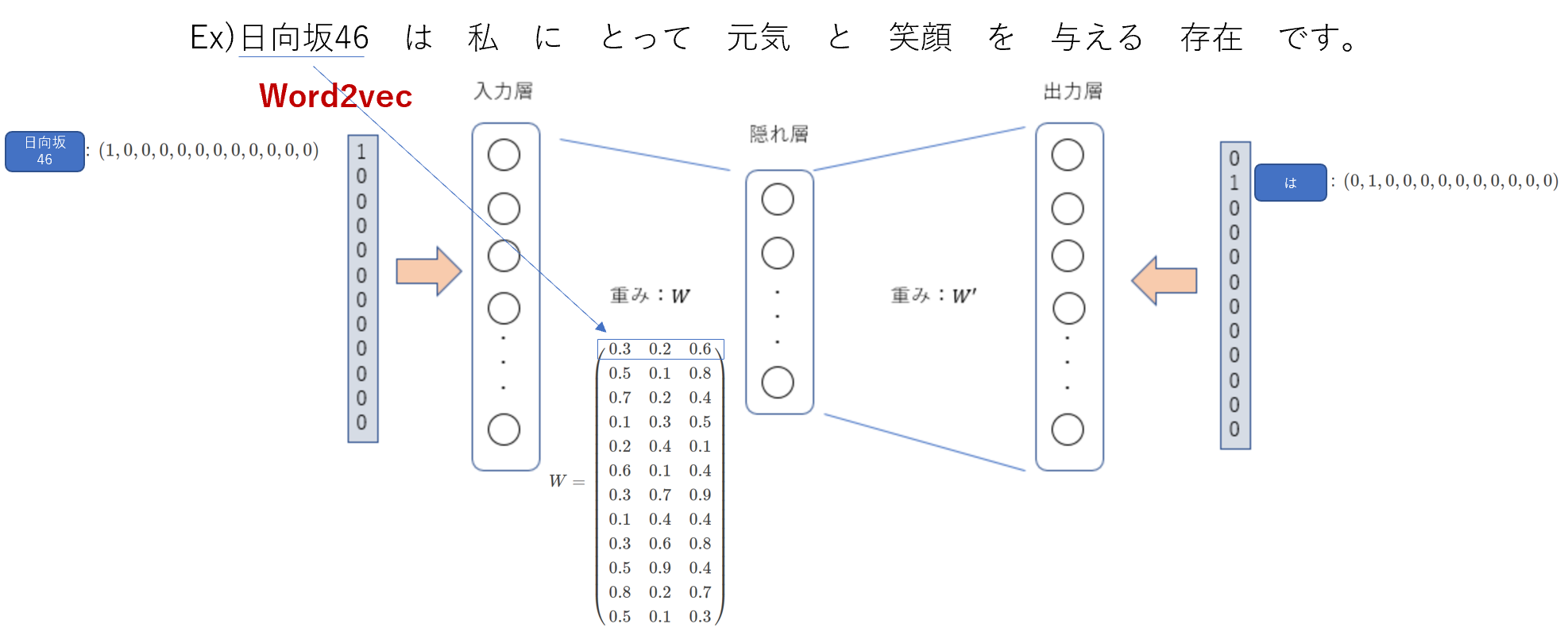
入力単語の周辺の単語(今回は距離1とする)を教師データとすることで、重みW,W"を計算する。
計算された重みWがそれぞれの単語のベクトルを表す。
自然言語処理の流れ
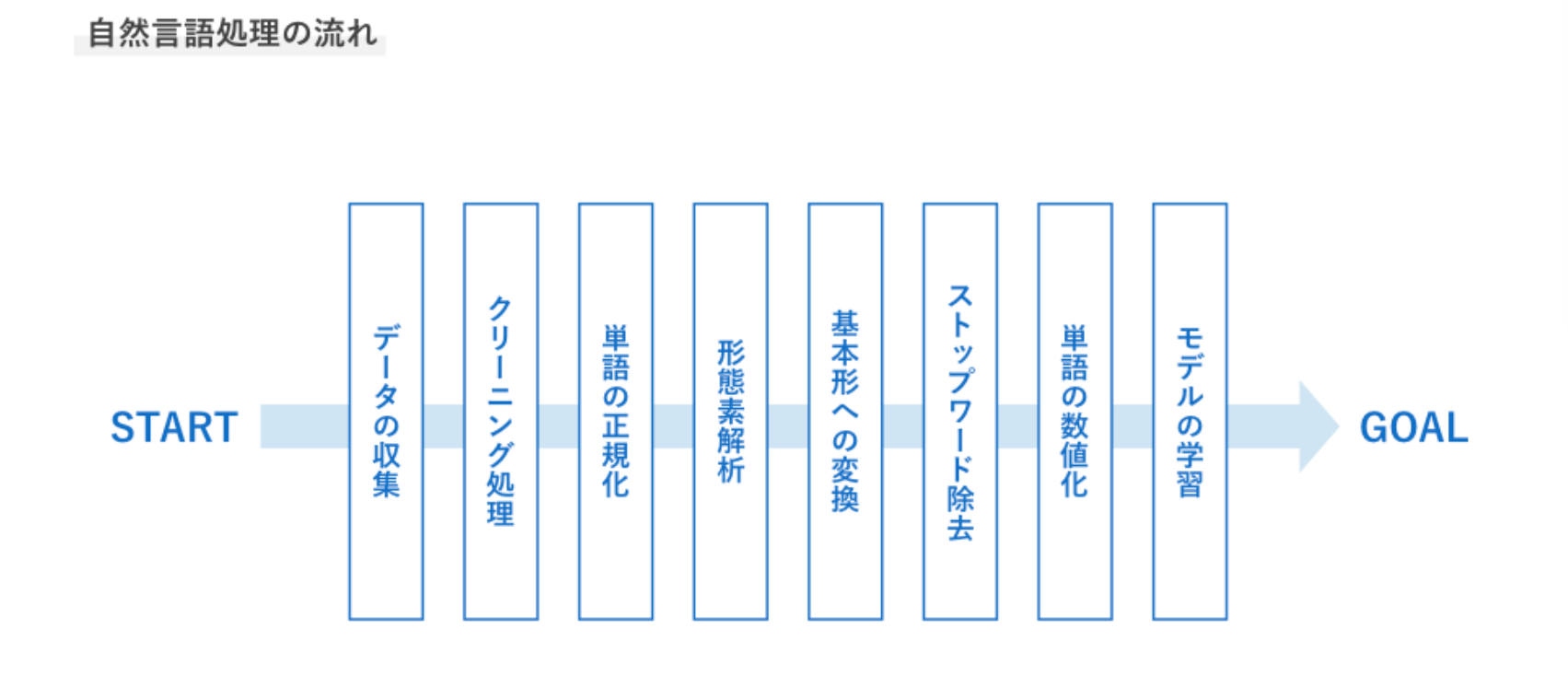
1:データの収集
解決したいタスクに応じてデータを収集する
2:クリーニング処理
HTMLのタグなど意味を持たないノイズを削除する
・Beautiful Soup
・標準ライブラリ re モジュール
1,2:データの収集&クリーニング処理
# 1.スクレイピング
import requests
from bs4 import BeautifulSoup
import warnings
warnings.filterwarnings('ignore')
target_url = "https://www.uta-net.com/search/?Aselect=1&Keyword=%E6%97%A5%E5%90%91%E5%9D%82&Bselect=3&x=0&y=0"
r = requests.get(target_url)
soup = BeautifulSoup(r.text,"html.parser")
music_list = soup.find_all('td', class_='side td1')
url_list = [] #曲一覧から各曲名のURLを取り出してリストに入れる
for elem in music_list:
a = elem.find("a")
b = a.attrs['href']
url_list.append(b)
# <td class="side td1">
# <a href="/song/291307/">アザトカワイイ</a>
# </td>
# <td class="side td1">
# <a href="/song/250797/">居心地悪く、大人になった</a>
# </td>
hinataza_kashi = "" #曲ごとにRequrestを送り歌詞を抽出する
base_url = "https://www.uta-net.com"
for i in range(len(url_list)):
target_url = base_url + url_list[i]
r = requests.get(target_url)
soup = BeautifulSoup(r.text,"html.parser")
div_list = soup.find_all("div", id = "kashi_area")
for i in div_list:
tmp = i.text
hinatazaka_kashi += tmp
# <div id="kashi_area" itemprop="text">
# 釣られてしまいました (一目でYeah, Yeah, Yeah)
# <br>
# 僕が勝手に恋をしてしまったんです
# <br>
# 君のせいじゃない

# 前処理(英語や記号を正規表現で削除)
import re
kashi=re.sub("[a-xA-Z0-9_]","",hinatazaka_kashi)#英数字の削除
kashi=re.sub("[!-/:-@[-`{-~]","",kashi)#記号の削除
kashi=re.sub(u"\n\n","\n",kashi)#改行の削除
kashi=re.sub(u"\r","",kashi)#空白の削除
kashi=re.sub(u"\u3000","",kashi)#全角の空白を削除
kashi=kashi.replace(' ','')
kashi=kashi.replace(' ','')
kashi=kashi.replace('?','')
kashi=kashi.replace('。','')
kashi=kashi.replace('…','')
kashi=kashi.replace('!','')
kashi=kashi.replace('!','')
kashi=kashi.replace('「','')
kashi=kashi.replace('」','')
kashi=kashi.replace('y','')
kashi=kashi.replace('“','')
kashi=kashi.replace('”','')
kashi=kashi.replace('、','')
kashi=kashi.replace('・','')
kashi=kashi.replace('\u3000','')

with open("hinatazaka_kashi_1.txt",mode="w",encoding="utf-8") as fw:
fw.write(kashi)
3:単語の正規化
半角や全角、小文字大文字などを統一する
・送り仮名によるもの
「行う」と「行なう」
「受付」と「受け付け」
・文字の種類
「りんご」と「リンゴ」
「犬」と「いぬ」と「イヌ」
・大文字と小文字
Apple と apple
※今回は無視する
4:形態素解析(単語分割)
文章を単語ごと分割する
・MeCab
・Janome
・JUMAN++
5:基本形への変換
語幹(活用しない部分)への統一を行う
例:学ん(だ)→学ぶ
昨今の実装では基本形へ変換しない場合もある
4,5:形態素解析(単語分割)&基本形への変換
path="hinatazaka_kashi_1.txt"
f = open(path,encoding="utf-8")
data = f.read() # ファイル終端まで全て読んだデータを返す
f.close()
# 3.形態素解析
import MeCab
text = data
m = MeCab.Tagger("-Ochasen")#テキストをパースするためのTaggerインスタンス生成
nouns = [line for line in m.parse(text).splitlines()#Taggerクラスのparseメソッドを使うと、テキストを形態素解析した結果が返る
if "名詞" or "形容動詞" or "形容詞" or"形容動詞" or "動詞" or "固有名詞" in line.split()[-1]]

nouns = [line.split()[0] for line in m.parse(text).splitlines()
if "名詞" or "形容動詞" or "形容詞" or "形容動詞" or "動詞" or "固有名詞" in line.split()[-1]]

6:ストップワード除去
出現回数の多すぎる単語など、役に立たない単語を除去する
昨今の実装では除去しない場合もある
my_stop_word=["する","てる","なる","いる","こと","の","ん","y","一","さ","そう","れる","いい","ある","よう","もの","ない","しまう",
"られる","くれる","から","だろ","その","けど","だけ","つ","て","まで","つて","じゃ","たい","なら","たら","なく","られ","まま","たく"]
nouns_new=[]
for i in nouns:
if i in my_stop_word:
continue
else:
nouns_new.append(i)

import codecs
with codecs.open("hinatazaka_kashi_2.txt", "w", "utf-8") as f:
f.write("\n".join(nouns_new))
7:単語の数値化
機械学習で扱えるよう文字列から数値へ変換を行う
8:モデルの学習
タスクに合わせ、古典的な機械学習~ニューラルネットワーク選択する
それでは、この流れのうち前処理にあたるものを把握する。
7,8:単語の数値化&モデルの学習
from gensim.models import word2vec
corpus = word2vec.LineSentence("hinatazaka_kashi_2.txt")
model = word2vec.Word2Vec(corpus, size=100 ,min_count=3,window=5,iter=30)
model.save("hinatazaka.model")
model = word2vec.Word2Vec.load("hinatazaka.model")
# ドライバーと類似している単語を見る
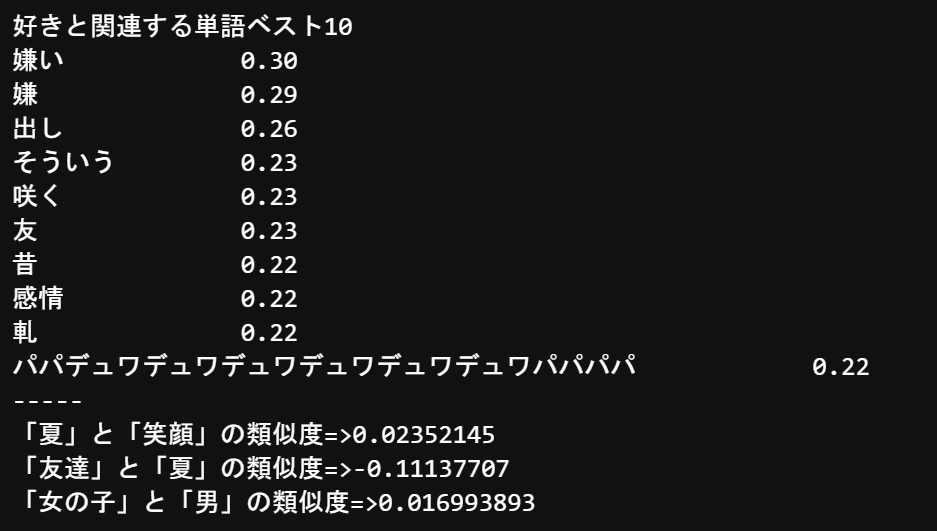
print('好きと関連する単語ベスト10')
similar_words = model.wv.most_similar(positive=[u"好き"], topn=10)
for key,value in similar_words:
print('{}\t\t{:.2f}'.format(key, value))
print('-----')
# # 2つの単語の類似度を計算
similarity = model.wv.similarity(w1=u"笑顔", w2=u"夏")
print('「笑顔」と「夏」の類似度=>' + str(similarity))
similarity = model.wv.similarity(w1=u"友達", w2=u"夏")
print("「友達」と「夏」の類似度=>" + str(similarity))
similarity = model.wv.similarity(w1=u"女の子", w2=u"男")
print('「女の子」と「男」の類似度=>' + str(similarity))
類似度
この中で出てくる類似度というのは、cos類似度のことを言っています。
cos類似度とは簡単にいうと、2つのベクトルがどれだけ同じ方向を向いているか(類似しているか)を数値化したものです。cos類似度が0のときには、類似度が低く、1のときには類似度が低いことを示しています。
cos類似度は以下のような計算式で表されます。

【総評】
***「パパデュワデュワデュワデュワデュワデュワパパパパ」***ってなんやねん。
歌詞じゃなくてメンバーのブログからデータを取得するとメンバーの仲良し度も分かるんじゃないかな。(次回やってみようかな…)
参考文献
2:[uepon日々の備忘録]
(https://uepon.hatenadiary.com/entry/2019/02/10/150804)
3:[Np-Urのデータ分析教室]
(https://www.randpy.tokyo/entry/word2vec_skip_gram_model)