はじめに
データの取り扱い、前処理、モデル構築、評価までを自分のための備忘録として残しました。
データはこちら
https://www.kaggle.com/kemical/kickstarter-projects
データセット
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib inline
plt.style.use('ggplot')
df = pd.read_csv('ks-projects-201801.csv')
df.head()
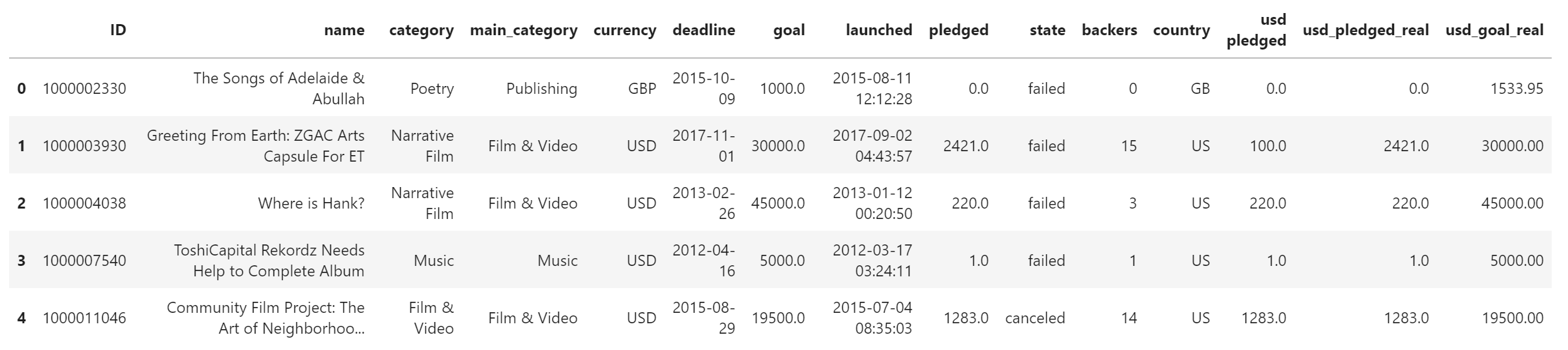
# 型
df.info()

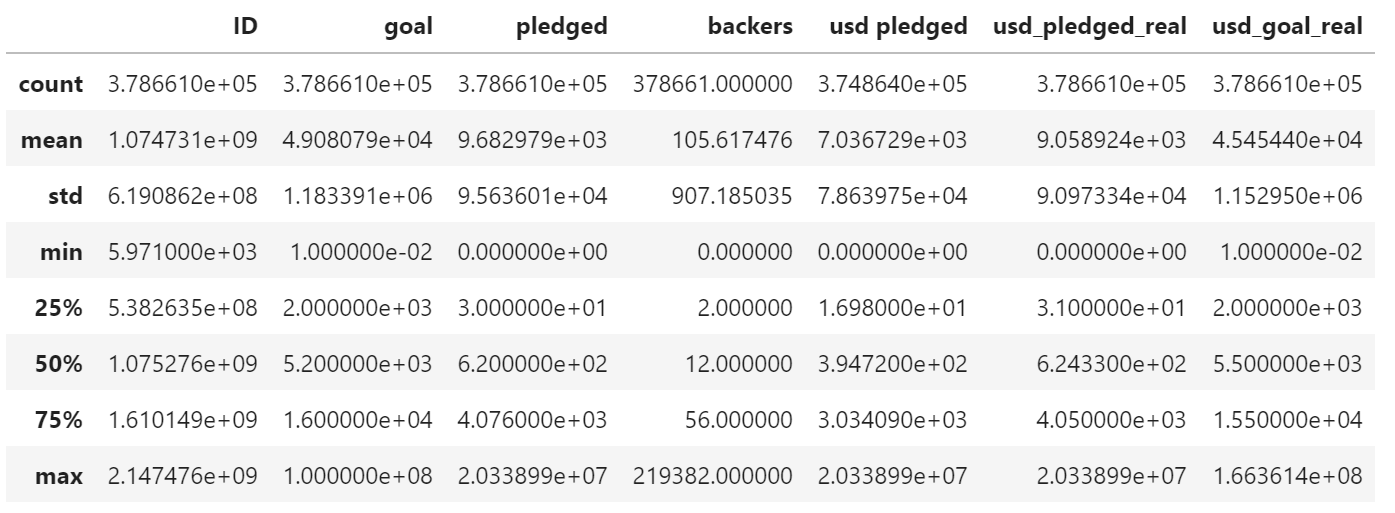
# 基本統計量
df.describe()
# 欠損値
df.isnull().sum()

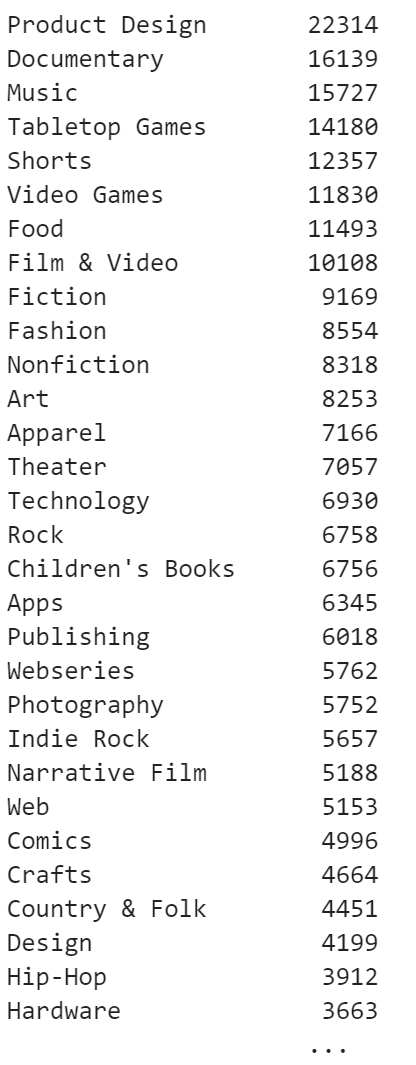
# 何種類含まれているか
df[['category', 'main_category']].nunique()

# それぞれのデータが何個ずつ含まれているか
df['category'].value_counts()
# それぞれのデータを割合でみる
success_rate = round(df['state'].value_counts() / len(df['state']) * 100, 2)
success_rate
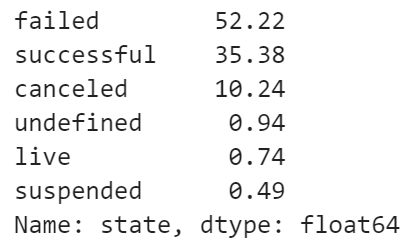
考察
学習に使ってはいけないデータを取り除くことが大事。
-
pledged
-
backers
-
usd pledged
-
usd_pledged_real
前処理
# stateを「failed」「successful」の2種に分ける
print('before: ', df.shape)
df = df[(df['state'] == 'failed') | (df['state'] == 'successful')]
# 文字列は扱えないので、数値に変換
df['state'] = df['state'].map({
'failed': 0,
'successful': 1
})
print('after: ', df.shape)

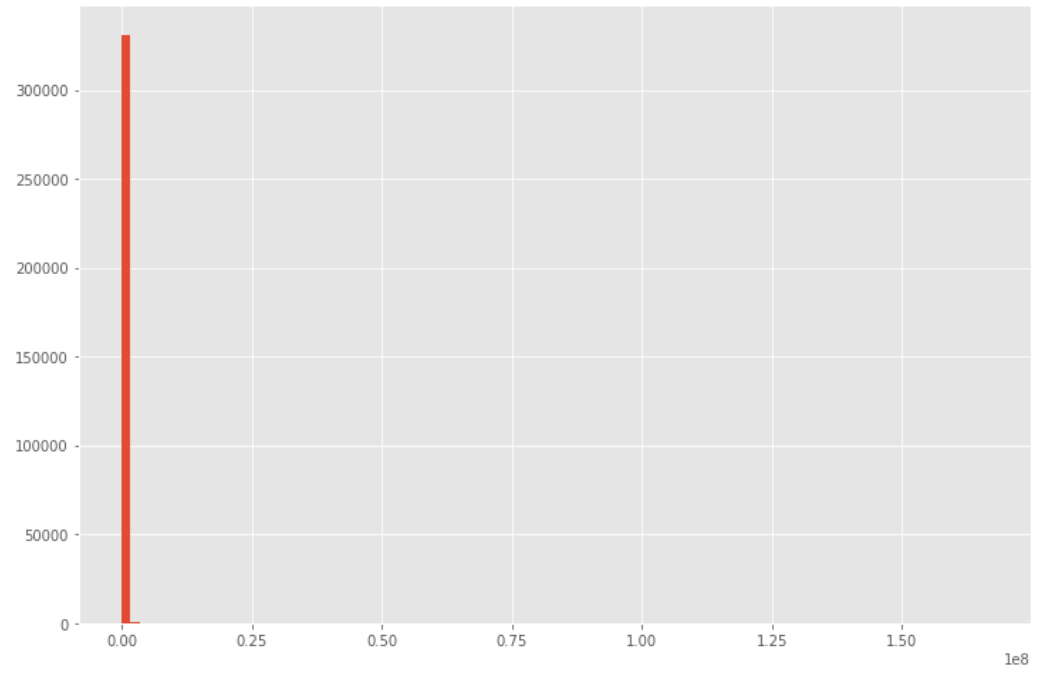
plt.figure(figsize=(12, 8))
plt.hist(df['usd_goal_real'], bins=100)
plt.show()
# 偏ってる時の対処法
# ①四分位範囲で処理
# ②対数をとって処理
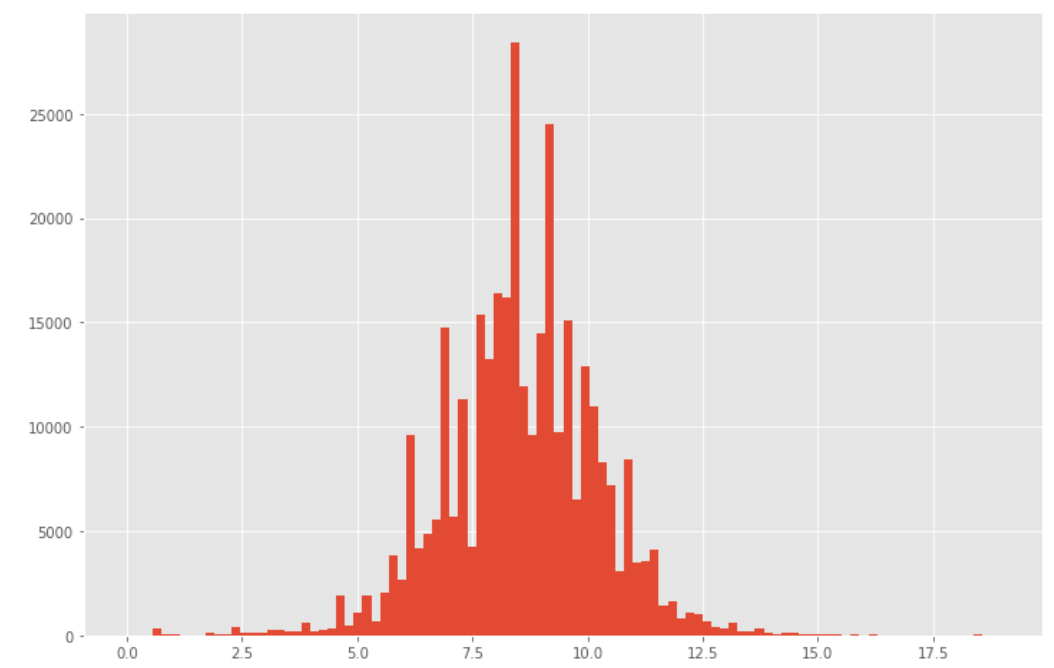
# np.log1p(a)…底をeとするa+1の対数
df['usd_goal_real'] = np.log1p(df['usd_goal_real'])
plt.figure(figsize=(12, 8))
plt.hist(df['usd_goal_real'], bins=100)
plt.show()
# なぜ正規分布にしたい?
# >>>モデルの中には正規分布を仮定しているものもあるから
df['deadline'] = pd.to_datetime(df['deadline'], format='%Y-%m-%d %H:%M:%S')
df['launched'] = pd.to_datetime(df['launched'], format='%Y-%m-%d %H:%M:%S')
# 何日間クラウドファンディングが行われているか?
df['duration']=(df['deadline'] - df['launched']).dt.days
# 1~3月=1,4~6月=2…と四半期に分けている。
df['quarter']= df['launched'].dt.quarter
df['month']= df['launched'].dt.month
df['year']= df['launched'].dt.year
# * Series.dt.dayofweekを使うと、月曜日= 0、日曜日= 6にして返してくれます
df['dayofweek']= df['launched'].dt.dayofweek
df.head()
# 不要カラムを削除
# IDは意味ない
# goalはusd_goal_realで代用できる
# launched,deadlineも他で代用できる
# その他は使ってはいけない
df = df.drop(columns=['ID', 'deadline', 'goal', 'launched', 'pledged', 'backers', 'usd pledged', 'usd_pledged_real'])
df.head()
# 名前(文字列)の処理
# 文字数を取得
df['name_len'] = df['name'].str.len()
# 単語ごとに分割して単語数を取得
df['name_words'] = df['name'].apply(lambda x: len(str(x).split(' ')))
df.drop(columns=['name'], inplace=True)
df.head()

# 欠損値
df.isnull().sum()

# 欠損値を0で埋める
df["name_len"]=df["name_len"].fillna(0)
# カテゴリカルなデータの処理(ダミー変数化)
# 頻繁に使う手法
df = pd.get_dummies(df , ['category', 'main_category', 'currency', 'country'])
df.columns

モデル構築
import xgboost as xgb
from sklearn.model_selection import train_test_split
X = df.drop(columns=['state'])
y = df['state']
print(X.shape)
print(y.shape)

X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2,
random_state=0)
print(X_train.shape, y_train.shape)
print(X_test.shape, y_test.shape)

# デフォルト
params = {
'silent': 1,
'max_depth': 6,
'min_child_weight': 1,
'eta': 0.1,
'tree_method': 'exact',
'objective': 'binary:logistic',#ここだけ注意(2分値)
'eval_metric': 'logloss',
'predictor': 'cpu_predictor'
}
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
model = xgb.train(params=params,
dtrain=dtrain,
num_boost_round=1000,
early_stopping_rounds=5,
evals=[(dtest, 'test')])
# どのくらいの精度か確認
# 「正解率」を用いて確認
from sklearn.metrics import accuracy_score
# 一番良いモデルで予測
y_pred = model.predict(xgb.DMatrix(X_test), ntree_limit=model.best_ntree_limit)
# 確率を表しているので、「0 or 1」にするために「0.5より大きいとき1」「0.5より小さいとき0」
prediction = [round(pred) for pred in y_pred]
acc = accuracy_score(y_test, prediction)
print(round(acc * 100, 2))

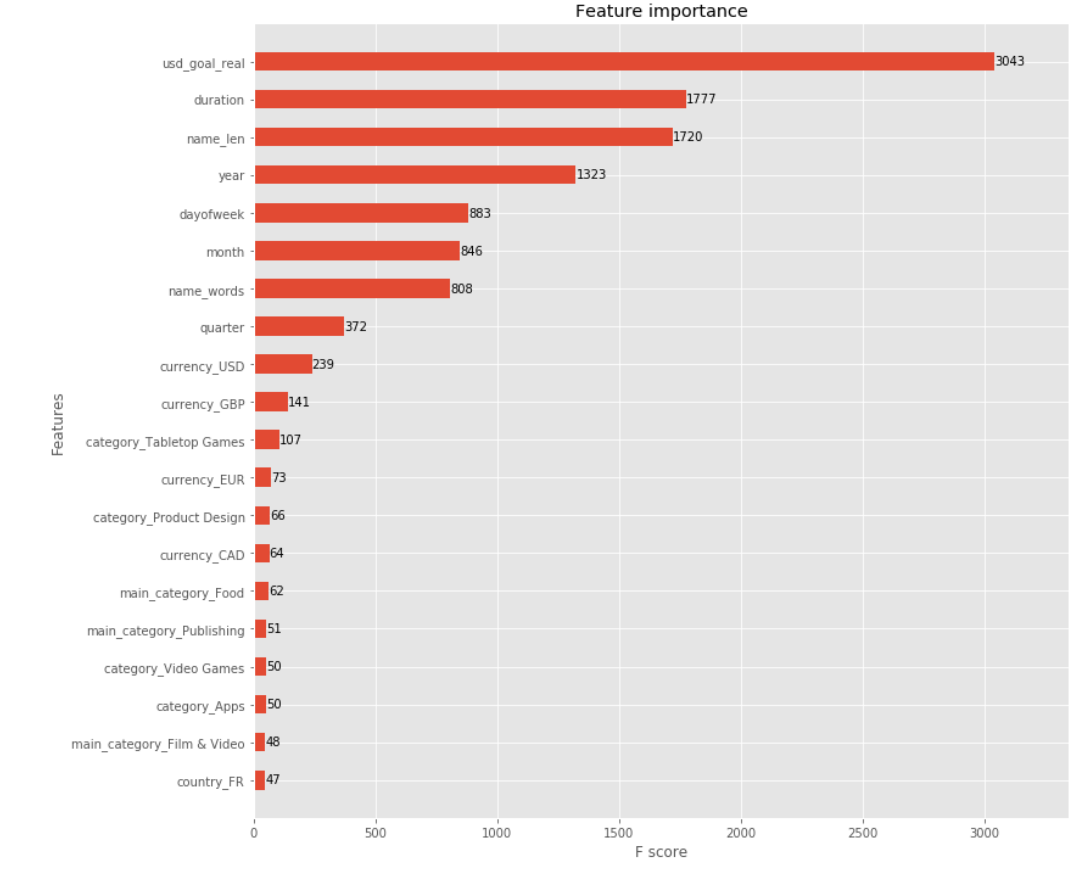
fig, ax = plt.subplots(figsize=(12,12))
xgb.plot_importance(model, max_num_features=20, height=0.5, ax=ax)
plt.show()
アンサンブル学習で正解率を上げる
# モデルを4つ作ってアンサンブル学習
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, \
AdaBoostClassifier, GradientBoostingClassifier
class SklearnHelper(object):
def __init__(self, clf, seed=0, params=None):
params['random_state'] = seed
self.clf = clf(**params)
def fit(self, x, y):
return self.clf.fit(x, y)
def predict(self, x):
return self.clf.predict(x)
def predict_proba(self, x):
return self.clf.predict_proba(x)
# ランダムフォレストのパラメータ
rfc_params = {
'n_jobs': -1,
'n_estimators': 500,
'warm_start': True,
'max_depth': 6,
'min_samples_leaf': 2,
'max_features' : 'sqrt',
'verbose': 1
}
# エクストラツリーのパラメータ
etc_params = {
'n_jobs': -1,
'n_estimators':500,
'max_depth': 8,
'min_samples_leaf': 2,
'verbose': 1
}
# アダーブーストのパラメータ
ada_params = {
'n_estimators': 500,
'learning_rate' : 0.75
}
# グラディエントブーストのパラメータ
gbc_params = {
'n_estimators': 500,
'max_depth': 5,
'min_samples_leaf': 2,
'verbose': 1
}
SEED = 0
rfc = SklearnHelper(clf=RandomForestClassifier, seed=SEED, params=rfc_params).fit(X_train, y_train)
etc = SklearnHelper(clf=ExtraTreesClassifier, seed=SEED, params=etc_params).fit(X_train, y_train)
ada = SklearnHelper(clf=AdaBoostClassifier, seed=SEED, params=ada_params).fit(X_train, y_train)
gbc = SklearnHelper(clf=GradientBoostingClassifier, seed=SEED, params=gbc_params).fit(X_train, y_train)
# 予測値を出力
rfc_pred = rfc.predict_proba(X_train)
etc_pred = etc.predict_proba(X_train)
ada_pred = ada.predict_proba(X_train)
gbc_pred = gbc.predict_proba(X_train)
# 「失敗の確率,成功の確率」と2列で出力される
# 成功の確率のみを抽出
preds_train = pd.DataFrame({'rfc_pred': rfc_pred[:, 1],
'etc_pred': etc_pred[:, 1],
'ada_pred': ada_pred[:, 1],
'gbc_pred': gbc_pred[:, 1]})
preds_train.head()
preds_train
y_train

preds_test_array = np.load('preds_test.npy')
preds_test = pd.DataFrame(preds_test_array, columns=['rfc_pred', 'etc_pred', 'ada_pred', 'gbc_pred'])
preds_test.head()
# Xgboost利用
params = {
'silent': 1,
'max_depth': 2,
'min_child_weight': 1,
'eta': 0.1,
'tree_method': 'exact',
'objective': 'binary:logistic',
'eval_metric': 'logloss',
'predictor': 'cpu_predictor'
}
dtrain = xgb.DMatrix(preds_train, label=y_train)
dtest = xgb.DMatrix(preds_test, label=y_test)
model = xgb.train(params=params,
dtrain=dtrain,
num_boost_round=1000,
early_stopping_rounds=5,
evals=[(dtest, 'test')])
from sklearn.metrics import accuracy_score
y_pred = model.predict(xgb.DMatrix(preds_test), ntree_limit=model.best_ntree_limit)
prediction = [round(pred) for pred in y_pred]
acc = accuracy_score(y_test, prediction)
print(round(acc * 100, 2))

考察
4つのモデルを組み合わせたアンサンブル学習によって正答率が69.76→69.81に上がったことが確認できた。