はじめに
今回はWebAPIの中のTwiiter APIを扱っていきます。
Twiiter APIを利用すると以下の2点作業が自動でできるようになります。
①特定の条件を満たす投稿を取得
②自分のアカウントで自動的に投稿
今回は①を実行してみます。
AV女優として活躍され、自分が一番お世話になっている七沢みあさんのTweetの中から、投稿された画像を自動で取得していきます。
TwitterのKeys&Tokensを取得
# API key
consumer_key = "???"
# API secret key
consumer_secret = "???"
# Access token
access_token = "???"
# Access token secret
access_token_secret = "???"
# 各々取得して???に代入してください。
# 「pip install tweepy」を実行して下さい
import tweepy
auth = tweepy.OAuthHandler(consumer_key, consumer_secret)
auth.set_access_token(access_token, access_token_secret)
api = tweepy.API(auth)
七沢みあさんのTwitterアカウント&フォロワー数を取得
下記のコードの詳細は
https://kurozumi.github.io/tweepy/getting_started.html#hello-tweepy
に書かれています。
def show_user_profile():
user = api.get_user('mia_nanasawa')
print(user.screen_name) #アカウント名取得
print(user.followers_count) #フォロワー数取得

下記のTwitter画像から、正しくアカウント名,フォロワー数を取得できていることが分かりますね。

七沢みあさんのTweet情報を取得(複数の画像)
user_timelineの使い方は
https://kurozumi.github.io/tweepy/api.html
に書かれています。
import json
user_id = "mia_nanasawa"
statuses = api.user_timeline(id=user_id, count=4)
for status in statuses:
#jsonを見やすくするためのワザ
print(json.dumps(status._json, indent=2))
entitiesとextended_entitiesの中にurlが入ってることがわかる。
一つの投稿に複数の写真が含まれている場合は、extended_entitiesにのみ複数の写真が含まれることが調べてみると、分かった。

def show_media_url():
user_id = "mia_nanasawa"
statuses = api.user_timeline(id=user_id, count=4)
for status in statuses:
for entity in status.extended_entities["media"]:
img_url = entity["media_url"]
print(img_url)
break
画像をダウンロード
def download_image(url, file_path):
r = requests.get(url, stream=True)
if r.status_code == 200:
with open(file_path, "wb") as f:
f.write(r.content)
実行
Cursorの使い方は
https://kurozumi.github.io/tweepy/cursor_tutorial.html
に書かれています。
import requests
import tweepy
def main():
user_id = "mia_nanasawa"
for page in tweepy.Cursor(api.user_timeline, id=user_id).pages(20):
for status in page:
try:
for media in status.extended_entities["media"]:
media_id = media["id"]
img_url = media["media_url"]
print(media_id)
print(img_url)
#カレントディレクトリに"imagesフォルダ”を作成しときます。
download_image(url=img_url, file_path="./images/{}.jpg".format(media_id))
#tryの中でエラーが発生したら、例外が出力されループを回す
except Exception as e:
print(e)
#動画を含むツイートの際にエラーが起きてる可能性がある。
if __name__ == "__main__":
main()

上記の出力から、いくつかエラー処理が発生していることが分かります。
恐らく、画像ファイルではなく、動画がTweetに含まれていることが予想されます。
(因みに、Tweetされた画像は正しく取得できています。)
結果
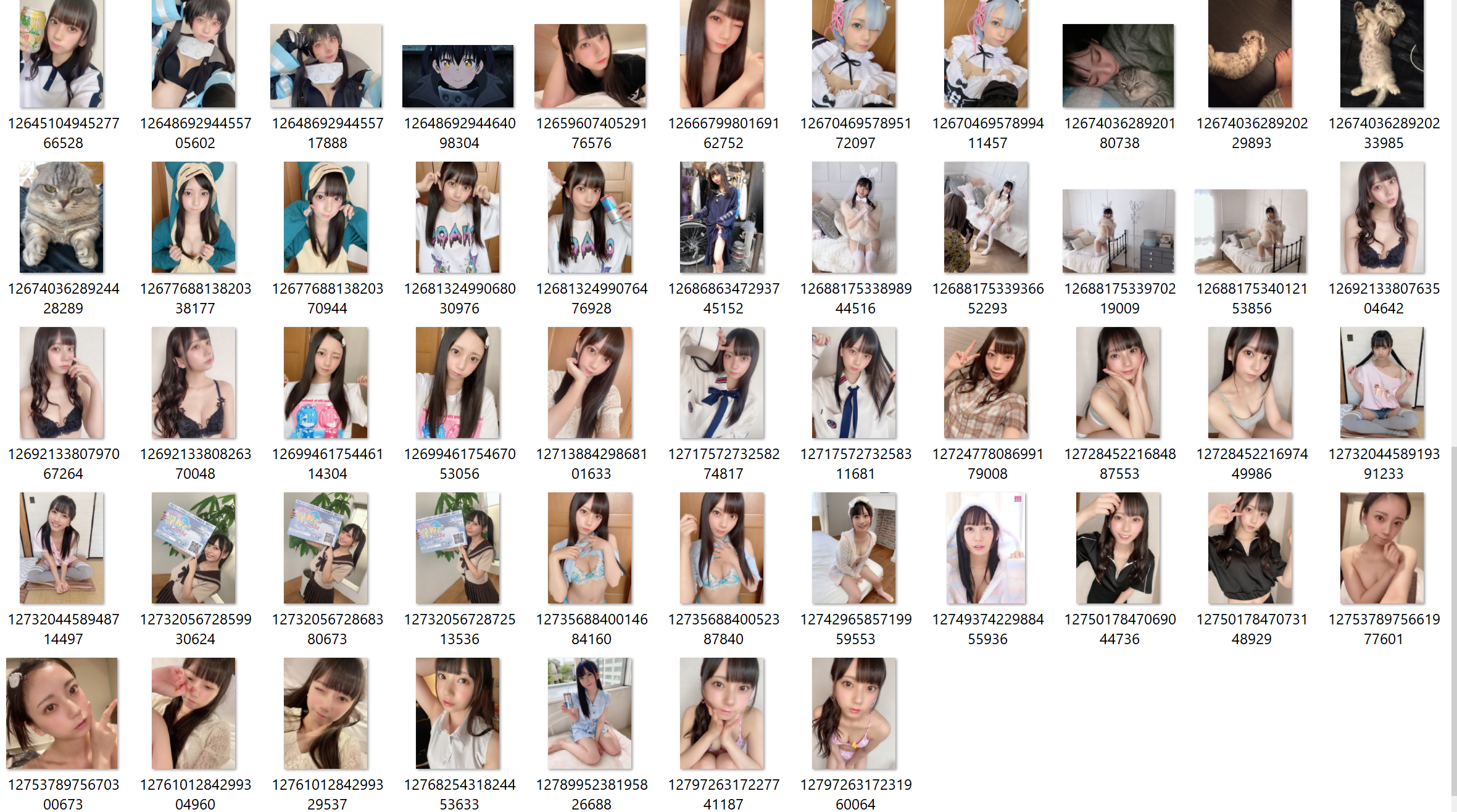
正しくimagesファイルに保存されていることが確認できました。
これで目の保養ができましたね。