はじめに
Lukas Renggli さんが書いた PetitParser はとても便利です。
東京のSmalltalk勉強会でも取り上げられたようですが、その回は休んでしまったし、小ネタとして加減算とシフト演算のポーランド記法のパーサを書いてみます。
ポーランド記法の整数加減シフト演算
どんなパーサを書きたいかというと、EBNFでいうと以下のような感じです。
expr = num | add | sub | lshift | rshift;
num = non zero digit , {digit} ;
add = '+' expr expr ;
sub = '-' expr expr ;
lshift = '<<' expr expr ;
rshift = '>>' expr expr ;
non zero digit = '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9' ;
digit = '0' | non zero digit ;
PolishGrammarクラス
まずはポーランド記法の構文定義を実装します。まとまった構文定義をする場合、PetitParserには PPCompositeParser という便利なクラスがあります。これを使ってみましょう。
PPCompositeParserのサブクラスとしてPolishGrammarクラスを定義します。
PPCompositeParser subclass: #PolishGrammar
instanceVariableNames: ''
classVariableNames: ''
category: 'SmalltalkAdvent2015'
これにポーランド記法の構文を定義していきます。
まずはPPCompositeParserのお約束として、startメソッドを定義しなければなりません。
後でちゃんとした定義をすることにして、まずは空のメソッドで誤魔化しておきます。
start
non zero digit と digit を定義する
まずは non zero digit を定義しましょう。non zero digit を受け付けるパーサを持つインスタンス変数を定義します。
PPCompositeParser subclass: #PolishGrammar
instanceVariableNames: 'nonZeroDigit'
classVariableNames: ''
category: 'SmalltalkAdvent2015'
次に、nonZeroDigit パーサを生成するメソッドを定義します。
nonZeroDigit
^ '1' asParser / '2' asParser / '3' asParser / '4' asParser / '5' asParser / '6' asParser / '7' asParser / '8' asParser / '9' asParser
EBNFでの non zero digit の定義にそっくりですね。PetitParserでは文字列オブジェクトに asParser メッセージを投げることで、その文字列を受け付けるパーサを生成することができます。これを逐次的選択をあらわす / で結合していくと、まずは / の左側のパーサで受け付けられるか試して、成功したらOK、失敗したら右側のパーサを試します。
では、nonZeroDigitを試してみましょう。
PolishGrammar new nonZeroDigit parse: '123'
結果は'1'となります。
PolishGrammar new nonZeroDigit parse: '0123'
こちらはパースに失敗して「'1' expected at 0」というエラーメッセージをもつPPFailureオブジェクトを返します。
続いて、digit を定義します。
digit
^ '0' asParser | nonZeroDigit
ここでポイントは、nonZeroDigitというインスタンス変数にはnonZeroDigitメソッドで定義したパーサが代入されているということです。PPCompositeParserはサブクラスがインスタンス変数を定義していたら、同名のメソッドを探して自動的に初期化してくれます。いちいち「nonZeroDigit := self nonZeroDigit」みたいなことをするボイラープレートを書かなくてもよいです。Smalltalkらしいメタな仕組みですね。
digitの動作を自分でテストしてみてください。
num, add, sub, lshift, rshiftを定義する
同様に、以下のように定義していきます。
PPCompositeParser subclass: #PolishGrammar
instanceVariableNames: 'nonZeroDigit digit expr num add sub lshift rshift'
classVariableNames: ''
category: 'SmalltalkAdvent2015'
num
^ (nonZeroDigit , digit star) flatten trim
digit starは、digitを0回以上連続して受け付けるパーサです。
flattenはパーサが受け付けた元の文字列を返すパーサ、trimは前後の空白文字を空読みするパーサを生成するメッセージです。
add
^ '+' asParser trim , expr , expr```
sub
^ '-' asParser trim , expr , expr
lshift
^ '<<' asParser trim , expr , expr
rshift
^ '>>' asParser trim , expr , expr
expr
^ num / add / sub / lshift / rshift
構文定義が一通り終わったので、ここでstartメソッドをちゃんと定義します。
start
^ expr
これで、PolishGrammarクラスのオブジェクトはデフォルトでexprをパースするようになります。
さて、実験してみましょう。
PolishGrammar new parse: '+ 1 << 2 3'
結果は、
# ('+' '1' #('<<' '2' '3'))
となります。たぶん、あってます。
PolishInterpreterクラス
次に、PolishGrammarを実行する処理系を実装してみましょう。とても簡単です。
PolishGrammar subclass: #PolishInterpreter
instanceVariableNames: ''
classVariableNames: ''
category: 'SmalltalkAdvent2015'
上記のようにPolishGrammarクラスのサブクラスとして定義するのが便利です。
あとは、継承したメソッドを使って、評価実行した結果を返すようなパーサを書けばインタプリタが出来上がります。
num
^ super num ==> [ :str | str asInteger ]
上記を少し説明します。
super num は、自然数を表す文字列を読み込むパーサです。より詳しく言うと、自然数を表す文字列を読んで、受け付けた文字列を出力するパーサです。 ==> [:str | str asInteger]で、そのパーサから出力された文字列にasIntegerメッセージを投げた結果を出力するようなパーサを生成します。結果、文字列を読み込んで、受け付けたら整数を出力するようなパーサが得られます。
この==>を使った仕組みを使って、+, -, <<, >>の評価実行を実装します。
add
^ super add ==> [ :triple | triple second + triple third ]
sub
^ super sub ==> [ :triple | triple second - triple third ]
lshift
^ super add ==> [ :triple | triple second << triple third ]
rshift
^ super add ==> [ :triple | triple second >> triple third ]
インタプリタの完成です。試してみましょう。
PolishInterpreter new parse: '+ 1 << 2 3'
結果は 17 です。
PolishTranslator クラス
さらに、ポーランド記法からSmalltalkへのトランスレータを実装してみましょう。
インタプリタと同じく、PolishGrammarのサブクラスとして定義します。
PolishGrammar subclass: #PolishTranslator
instanceVariableNames: ''
classVariableNames: ''
category: 'SmalltalkAdvent2015'
各メソッドを定義していきます。
add
^ super add ==> [ :triple | '(', triple second, ' + ', triple third, ')' ]
sub
^ super sub ==> [ :triple | '(', triple second, ' - ', triple third, ')' ]
lshift
^ super lshift ==> [ :triple | '(', triple second, ' << ', triple third, ')' ]
rshift
^ super rshift ==> [ :triple | '(', triple second, ' >> ', triple third, ')' ]
試してみましょう。
PolishTranslator new parse: '+ 1 << 2 3'
結果は、'(1 + (2 << 3))'となりました。んー、よくわかりませんね、じゃあ、こうしてみましょう。
Compiler evaluate: (PolishTranslator new parse: '+ 1 << 2 3')
よかった、結果はPolishInterpreterと同じく 17 です。
パーサオブジェクトの可視化
PetitParserで作ったパーサオブジェクトをインスペクタで開くと、以下のような可視化ができます。
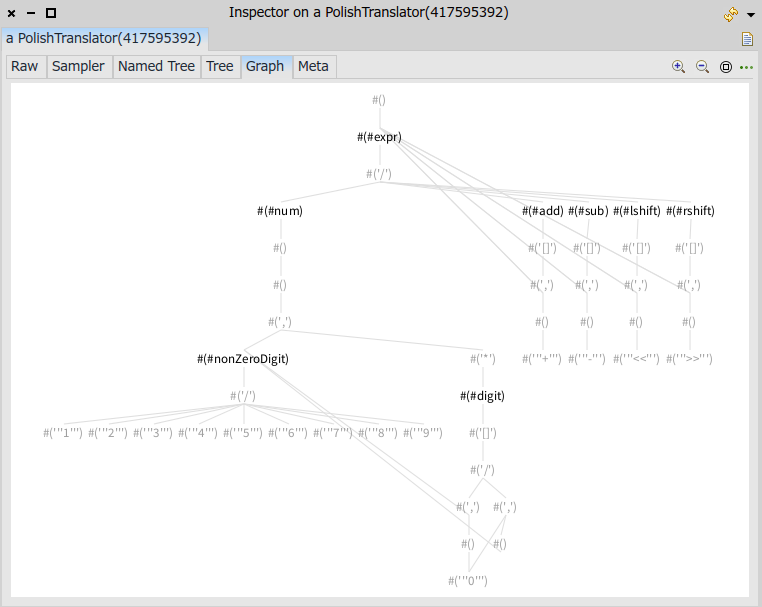
いやー、moldable inspector って、いいですね!
インスペクタで開く対象はEBNFでもクラスでもなく、パーサオブジェクトです。念のため。
まとめ
こんな風に、PPCompositeParser のサブクラスとして構文定義をして、構文解析した結果を利用してインタプリタやトランスレータを構文定義クラスのサブクラスとして定義すると、構文定義と意味定義をうまく分離した実装にできて、なおかつ、文法拡張した時などの対応関係がわかりやすいので便利です。
他にも、PetitParser には PPExpressionParser など、便利な道具が沢山揃っています。
ほーら、オレオレDSLを書きたくなったでしょ?
よい開発ツールはコードを書きたい気分にさせるものなのです。