この記事はリクルートライフスタイル Advent Calendar 2016の24日目の記事です。
データエンジニアリンググループ・ゆるふわAwesome機械学習エンジニアのtomomotoです。弊社はリア充が多く、24日だけカレンダーが空いている状態だったので、24日12時53分現在から数少ないリア充ではないエンジニアとしてQiita記事を書き始めています。
本記事では、JapanR2016で発表したLTネタのdplyrで書けるRedshiftSQLについて書きたいと思います。(新しいネタ考える時間なんてありません!)
dplyrで書けるRedshiftSQL
dplyrとは、R言語のライブラリで、データ処理を簡単にパイプ(%/%)を使って書くことができる神ライブラリです。実はこの神ライブラリをつかって、SQLを書かなくても直接RedshiftにSQLを投げることができるのです!イメージは下記の感じです。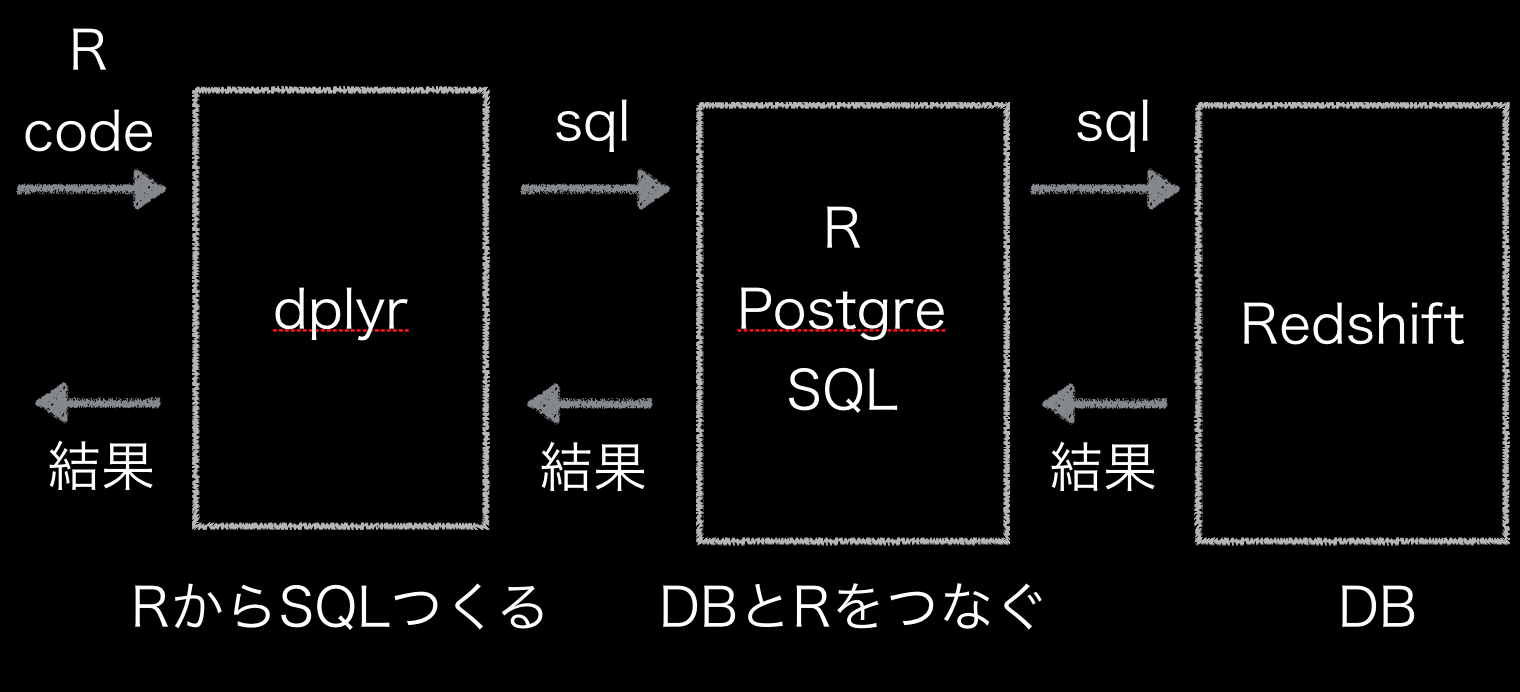
使い方
コード書き方はこうです。ね、簡単でしょ?
connect_rs.R
library(dplyr)
library(RPostgreSQL)
myRedshift <- src_postgres(
dbname="hoge",
host = "XXX.XXX.XXX.XXX",
port = XXX,
user = "hoge_hoge",
password = "hoge_hoge_hoge",
options="-c search_path=hoge_schema_name")
rs_table <- tbl(myRedshift, from ="hoge_table")
rs_table %>% dplyr::filter(hoge_column = "abcd")
どんなSQLに変換されているのか?
では実際dplyrのコードがどのように変換されているのか調べてみましょう!
rs_table
SELECT * FROM hoge_table
rs_table %>%
select(a)
SELECT a AS a FROM hoge_table
rs_table %>%
select(starts_with("a"))
SELECT a AS a, a_1 AS a_1
FROM hoge_table
rs_table %>%
filter(hoge_no="33")
SELECT * FROM hoge_table
WHERE (hoge_no = '33')
rs_table %>%
head(3)
SELECT * FROM hoge_table
LIMIT 3
rs_table %>%
select(a) %>%
head(3)
SELECT * FROM
(SELECT a AS a FROM hoge_table) xauvngdbsq
LIMIT 3
rs_table %>%
group_by(a) %>%
summarise(cnt=length(a))
SELECT a, LENGTH(a) AS cnt
FROM hoge_table
GROUP BY a
rs_table %>%
group_by(a) %>%
summarise(cnt=length(a)) %>%
arrange(desc(cnt))
SELECT * FROM
(SELECT a, LENGTH(a) AS cnt FROM hoge_table GROUP BY a)
hjvzhxrrld
ORDER BY cnt DESC
innerjoin(rs_table, rs_table, by=a)
SELECT * FROM (SELECT a AS a, ..... FROM hoge_table) uqhggwfohi
INNER JOIN
SELECT * FROM (SELECT a AS a, ..... FROM hoge_table) npoulssyev
USING (a)
rs_table %>%
mutate(row_number=row_number(desc(a)))
SELECT a, b, ...,
row_number() OVER (ORDER BY a DESC) AS row_number
FROM hoge_table
rs_table %>%
group_by(b) %>%
mutate(row_number=row_number(desc(a)))
SELECT a, b, ...,
row_number() OVER (PARTITION BY b ORDER BY a DESC) AS row_number
FROM hoge_table
まとめ
- dplyrやっぱり神!(記述量減る)
- データを減らす処理をなるべく手前に(サブクエリで分割してしまうので・・・、いけてないですね)
- 関数系はRedshiftならだいたい担保(してそう)
- Join処理のSQLは、結構雑。自分で書いた方がいいかもしれない。
最後に
現在13:11!意外と時間かからず書けるものですね。みなさんは事前に書いておいてください。明日は、私が前もって準備しておいた記事です。