概要
panderaを使ってirsiとtitanicのデータをvalidationしてみる。
対応しているのはpandasだけではないので詳しくは公式の冒頭を読むと分かりやすいです。
どうしてこの記事を書いたのか
外部からCSVとかでデータを取得してデータフレームにして整形して分析とか計算とかをするってことを自動化していると、
データフレームは当初の想定と同じ形になっているのだろうかと不安になるし、
型が変わっていたりカラムが増えていたりする事に気づきやすくしたいなって思ったので。
前提
- panderaのバージョンは 0.11.0
- pandasのバージョンは 1.4.1
- Pythonのバージョンは 3.9.10
- irisのデータセットを取得するためだけsklearnをimport
- titanicのデータはKaggleからダウンロードしたtrain.csvを使う
- pandera以外のインストール(Pythonとかsklearnとかpandasとか)は済んでいる
準備
panderaのインストール
pip install pandera
irisのデータをバリデーションしてみる
irisのデータの準備
from sklearn import datasets
data = datasets.load_iris()
df = pd.DataFrame(data.data, columns=data.feature_names)
データは以下の感じ
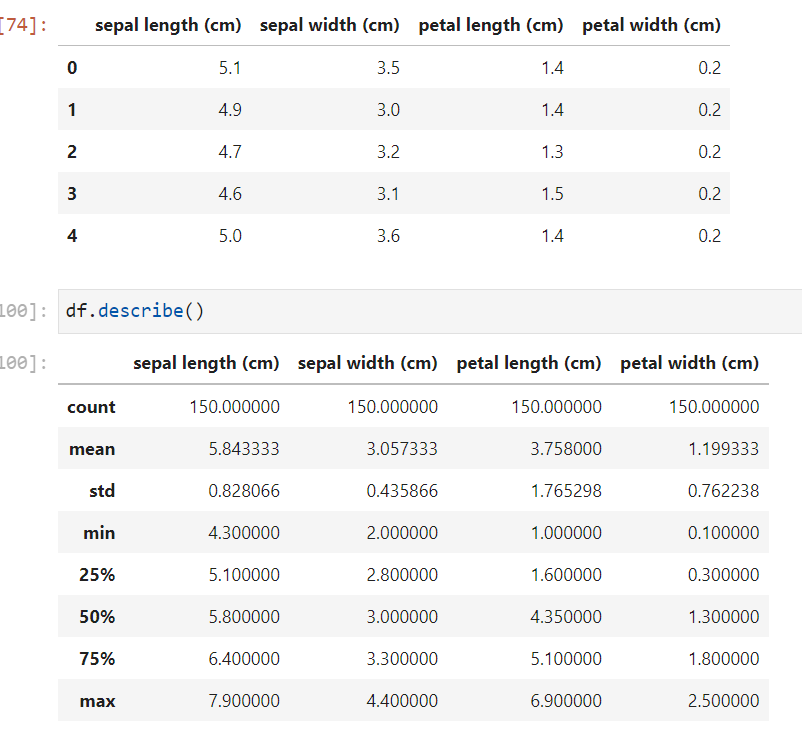
schemaの定義をする
import pandera as pa
schema = pa.DataFrameSchema(
{
"sepal length (cm)": pa.Column(float, checks=pa.Check.le(10)), # 型は浮動小数点で10以下
"sepal width (cm)": pa.Column(
float, checks=[pa.Check.gt(0.0), pa.Check.lt(10.0)]
), # 型は浮動小数点で0.0より大きく、10.0より小さい
"petal length (cm)": pa.Column(float, checks=pa.Check.le(7.0)), # 型は浮動小数点で7.0以下
"petal width (cm)": pa.Column(
float,
checks=[
pa.Check.gt(0.0),
pa.Check.le(2.5),
], # 型は浮動小数点で0.0より大きく2.5以下
),
}
)
validationする
schema(df)
データフレームが返ってくれば定義した要件を満たしている。
エラーが出たら何かしらを満たしていない。
titanicのデータをvalidationしてみる
titanicのデータの読み込み
import pandas as pd
df = pd.read_csv("./train.csv")
データは以下の感じ。
schemaの定義をする_その1
# schemaに無いカラムがあったらエラーにするためにstrictをtrueにする
schema = pa.DataFrameSchema(
{
"PassengerId": pa.Column(int, checks=[pa.Check.ge(1), pa.Check.le(891)]),
"Survived": pa.Column(int, checks=[pa.Check.ge(0), pa.Check.le(1)])
},
strict=True
)
validationする_その1
データフレームにはschemaで定義していないカラムがあるのでエラーになります。
schema(df)
エラーメッセージは以下の感じ。
SchemaError: column 'Pclass' not in DataFrameSchema {'PassengerId': <Schema Column(name=PassengerId, type=DataType(int64))>, 'Survived': <Schema Column(name=Survived, type=DataType(int64))>}
schemaを定義する_その2
今度は全部のカラムを定義します。
schema = pa.DataFrameSchema(
{
"PassengerId": pa.Column(int),
"Survived": pa.Column(int, checks=[pa.Check.greater_than_or_equal_to(0), pa.Check.less_than_or_equal_to(1)]),
"Pclass": pa.Column(int, checks=pa.Check.less_than_or_equal_to(3)),
"Name": pa.Column(str),
"Sex": pa.Column(str, checks=pa.Check.isin(["male", "female"])), # リスト内のいずれかの値に合致することを確認する
"Age": pa.Column(float, checks=pa.Check.greater_than_or_equal_to(0), nullable=True), # nullを許容する
"SibSp": pa.Column(int, checks=pa.Check.isin([0,1,2,3,4,5,8])),
"Parch": pa.Column(int, checks=pa.Check.in_range(min_value=0, max_value=6)), # 範囲で指定する
"Ticket": pa.Column(str, checks=pa.Check.str_length(max_value=30)), # 30文字以内
"Fare": pa.Column(float, checks=pa.Check(lambda s: s.mean() == 32.2042079685746)), # 平均でチェックする
"Cabin": pa.Column(str, checks=pa.Check.str_matches(r'^[A-Z]'), regex=True, nullable=True), # 正規表現を使う
"Embarked": pa.Column(str, checks=pa.Check.str_length(max_value=1), nullable=True) # 文字数をチェックする
},
strict=True # 定義していないカラムがあったらエラーにする。
)
validationする_その2
今度はOK!
schema(df)
おわり
分かりやすく書けるのでとても良いと思います!定義した関数をチェックに使えるみたいなので、
用意されているもので足りなければ色々自分で用意することもできそうです。