RDB(リレーショナルデータベース)
複数テーブルを結合する方法を紹介する前に、なぜ複数テーブルを用意するのかについて説明します。
まずテーブルを分割しなかった場合のテーブルを見てみましょう

これを顧客名を顧客ID(外部ー)としてテーブルを2つに分割します。
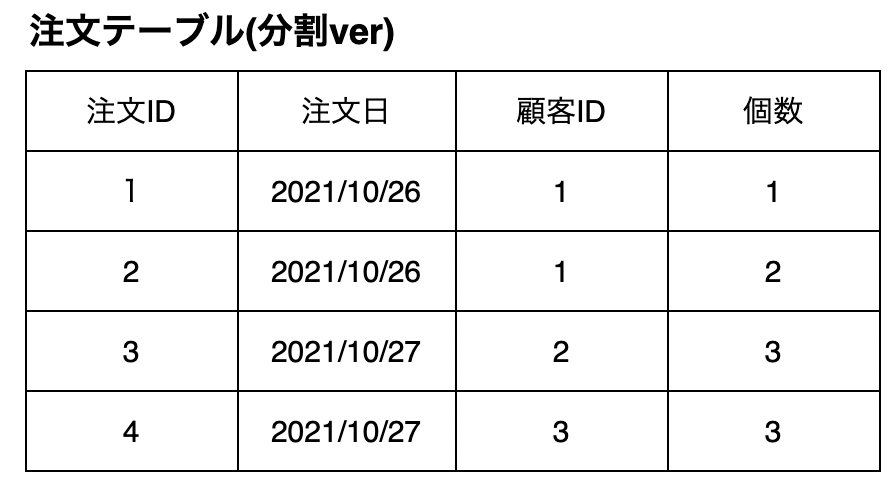

(外部キー:上記の「顧客ID」列のように関連したテーブル間を結ぶために設定する列のこと)
私たちにとっては顧客IDのような数字で書かれるより、元の顧客名のほうが見やすいです。しかし、テーブルが分割されていたほうがデータを安全、確実、高速に取り扱うことができます。
仮に、いまテーブル分割がされていな元のテーブルで顧客名のディオをDIOに変えたいとします。(JOJOがわからない人はごめんなさい)
UPDATE 注文
SET 顧客名 = 'ディオ'
WHERE 顧客名 = 'DIO'
現在は4件ですが注文テーブルに10万件ほどデータが格納されていたとしましょう。このとき上記のコードではDBMSは一行ずつ条件に合致するか調べて書き換えます(合計10万行)。しかし、切り分けた顧客テーブル(登場人物)は10万人もいないので単純に調べる件数が少なく処理にかかる時間が少なくなります。
RDB(リレーショナルデータベース)とはこのように複数テーブルで分けるメリットを生かしたDBMSであると言えます。テーブルを複数分割して用意するメリットがわかったところで、RDBのテーブル結合についてまとめていきます。
テーブルの結合
テーブルの基本的な結合の仕方
SELECT 選択列リスト
FROM テーブルA
JOIN テーブルB
ON 両テーブルの結合条件
例えば最初に紹介したテーブルを結合してみましょう。今注文テーブル(分割ver)と顧客テーブルを結合します。
SELECT 注文ID,注文日,顧客名,性別,個数
FROM 注文(分割ver)
JOIN 顧客
ON 注文(分割ver).顧客ID = 顧客.ID
ここで注意が必要なのが一行目に指定している列名の中に注文テーブル(分割ver)には存在していな顧客名,性別が使われている点です。通常存在しない列名をSLECT分の選択列リストに記入するとエラーになりますが3行目のJOINがあることで結合するテーブルの列名も参照可能になります。
ON句での結合条件について
先程のコードでは
ON 注文(分割ver).顧客ID = 顧客.ID
で結合条件を指定しています。これは
1. 注文(分割ver)の各行について顧客ID列のデータに注目する。
2. 顧客テーブルからそれと等しいIDを持つ行を取り出してつなぐ
といった条件指定になります。イメージとしては下記のイラストになります。
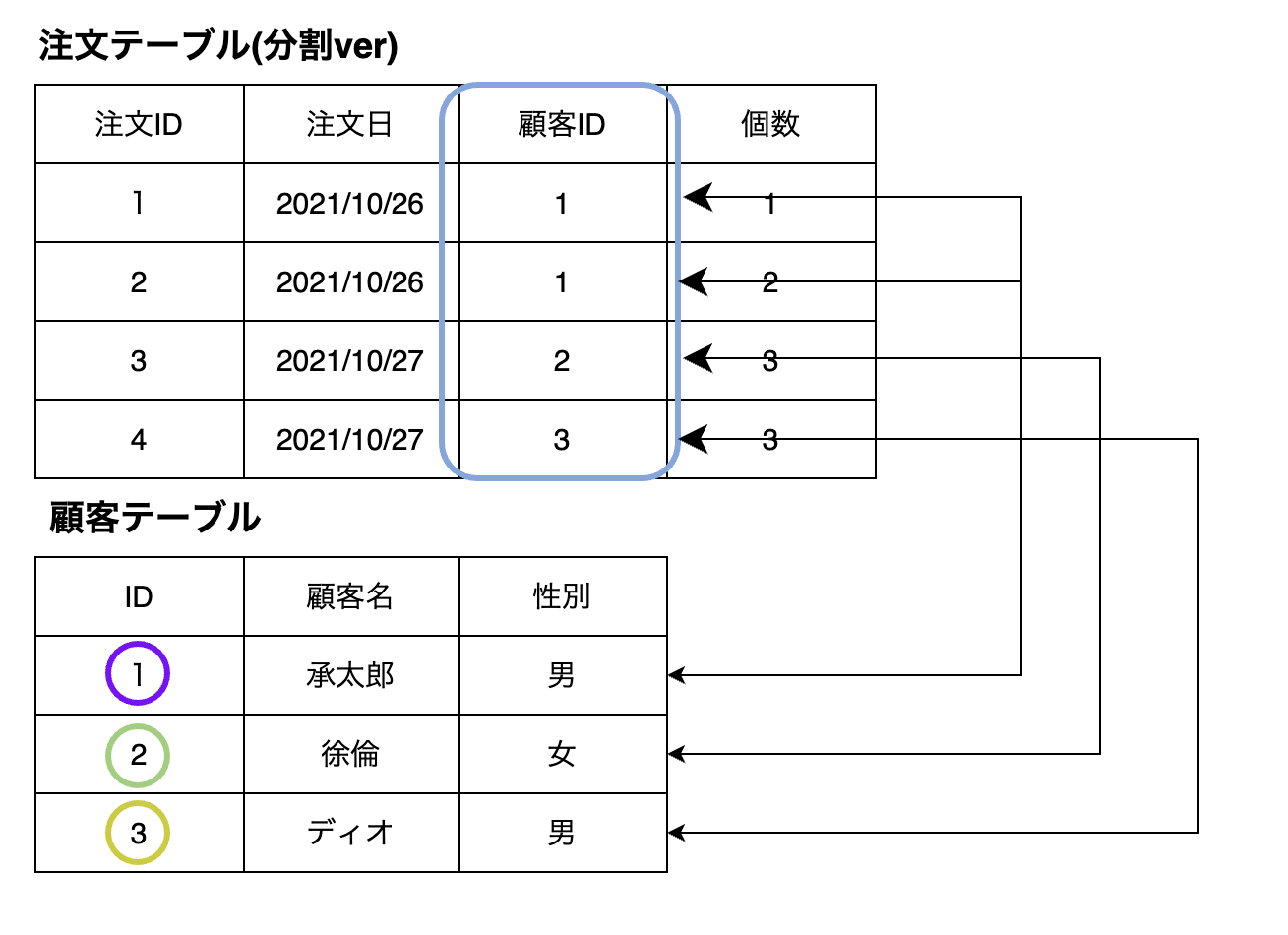
DBMSは注文(分割ver)を1行ずつ処理しながら「この行につなぐべき顧客IDはどれか」と探しながら行と行を結合しています。
それでは大まかな結合の概念がわかったところで具体的な特殊ケースでのDBMSの動き方をくわしく見ていきましょう。
結合相手が複数行の場合
今までの例では結合結果が常に1行になりました。その理由としては右辺に指定している列(顧客テーブルのID列)は主キーでありユニークな値であったからです。しかし右辺に重複する値を含む列を指定した場合はどうなるでしょうか。例えば以下のテーブルを用意します。

1つの行に2つの行をつなぐことはできません。このようなケースは左表の行数が足りないので足りるまで足されます。つまり今回のケースでは

このように右表の行数に合わせて左表の行を複製して結合します。したがって、左表に対して重複がある列を対象とした結合を行うと結合前より行数が増えます。
結合相手の行がない場合
以下のテーブルを用意します。

右表にはID4が存在しません。結合の際に次のようなクエリを実行したとしても結果は常に0行になります。
SELECT * FROM 費目 WHERE 4 = 費目.ID
このようなケースではDBMSはこの行の結合を諦め次の行の処理に進みます。したがってもともと左表(家計簿)にあった費目ID4の行は実行結果から消滅してしまいます。

では、このようなクエリを実行した場合はどうなるでしょうか。
SELECT * FROM 費目 WHERE NULL = 費目.ID
この場合、NULLの箇所が結合されそうに思えますが実行結果から消滅してしまいます。その理由としてはNULLはどのような値と比較しても等しくならない特別な存在だからです。
次回に続く、、。
参考
書籍: スッキリわかるSQL入門 第2版 ドリル222問付き!
中山 清喬 著/飯田 理恵子 著