Summary
この投稿で扱う自作アプリ
- Live demo:https://tomohiku-gpt-web.azurewebsites.net/
- Source code:https://github.com/tomohikue/ExpertImitater
- License:MIT なので、使えそうであればご自由にご利用ください
目次
1章 アプリの紹介
2章 そのアプリで扱っている技術要素を説明
| 章 | 2章で扱う技術要素 | 備考 |
|---|---|---|
| 2-1 | OpenAIモデルの基礎知識 | |
| 2-2 | チャット画面実装の技術的な考慮点 | |
| 2-3 | OpenAIモデルの定番シナリオの深堀り | ※追って投稿予定 |
| 2-4 | 組織内ノウハウをプロンプトに載せるアイディアと効果 | ※追って投稿予定 |
| 2-5 | [応用シナリオ] ベクトル検索の実装詳細 | ※追って投稿予定 |
| 2-6 | [応用シナリオ] Code interpreter(python版 & sql版)の実装詳細 | 2023/12/12に追記 |
| 2-7 | [応用シナリオ] AI同士の会議シナリオの実装詳細 | ※追って投稿予定 |
■注意事項
- 投稿の内容は僕が個人的にChatGPTテクノロジーに興味を持ち、個人的に設計し、個人的に実装したものです。
- Microsoftなどのリファレンスアーキテクチャ―などを参考にしてはいますが沿ったものではありません。
0. はじめに
ChatGPTに魅了された多くの人たちと同じく僕もこのテクノロジーにドハマりしました。ChatGPTは、インターネット検索では答えを見つけられないような「僕がずっとモヤモヤしていた疑問」に、それっぽい答えをくれます。時にはその答えが間違っていることもあるかもしれませんが、それでも僕の知的好奇心を刺激し、四六時中昼夜問わず会話を繰り返しています。
例えば、以下のような疑問。
- 世界的には「宗教思想の違いによる争い」が歴史的に多いのに対して、日本ではほとんど無いのはなぜでしょうか?
- 人類の歴史で「暴力が悪」という認識はいつから生まれたのでしょうか?
- 他の芸術に比べて音楽は人を熱狂させる力が強いように感じます。なぜでしょうか?
さて、
こんな使い方も面白いのですが、今回は組織内での活用にフォーカスします。2023年4月頃、ChatGPT人気が爆発的に高まり、AI活用が盛んになりました。多くの人がChatGPTにアクセスできるようになりましたが、12月現在でも頻繁に使っている人は一部に限られているように感じます。「これの何が便利なの?」と感じてツールに手が伸びなくなった人が大半ですが、逆に一部の人は高頻度で利用している、そういった二極化が進んでいるように感じます。
例えば、僕の会社の社員はITリテラシーが高いはずですが、高頻度でChatGPTを活用しているのはおそらく2割程度でしょう。ほとんどの人はチャット画面を開いて「何をすればいいの?」と考え、サンプルを少し試してみる程度で終わってしまいます。そのため、ChatGPTをより多くの人が活用できるようにする為には、UIを工夫し「何ができて、どう役に立つか?」がわかりやすくすることが重要だと思います。このアプリは、そんな僕なりの工夫を形にしたアプリです。
OpenAIやMicrosoftは引っ切り無しに新機能をリリース続けていますが、彼らは一般消費も含めた全業種に向けて汎用的なサービスを提供することしかできず、各組織の業務に特化したものは作りません。一方、「何ができて、どう役に立つか?」をわかりやすいUIは、自組織の業務に特化していないと作れません。そのため、このアプリでは自組織の業務に特化させる実装を、比較的簡単に行えるようにするにはどうすればいいかを考慮しています。
過去半年間で思いついたシナリオやアイディアを少しずつ一人で実装してきました。世界で流行っているアイディアや、OpenAI、Microsoftが実装したアイディアも、僕なりの工夫を加えて取り入れました。この実装ノウハウがいくらかのエンジニアの方々の参考情報になることを願っています。
1. アプリ紹介
1-1. コンセプト
- 専門家を模倣する人(Expert imitator)というコンセプトで画面構成されたチャットベースアプリです。
- スキルが「上の上」レベルの人間のアウトプット品質には太刀打ちできないですが、「上の下程度の人間が1週間かけて作るレベルの回答」を、即時回答します。
- 「ChatGPTの使い方を迷っている人」がメインターゲットです。

1-2. リソース
- Live demo: https://tomohiku-gpt-web.azurewebsites.net/
- Source: https://github.com/tomohikue/ExpertImitater
- Live demo環境でアプリの動作を試すことができます。
- Githubにはソースがあり、セットアップ手順&開発手順についても記載しています。自由にご利用ください。ライセンスはMITです。
- デモ環境ではGPTとの通信はできません。しかし、出力例が各ページに用意されていますので実行イメージを見ることができます。
- フル機能を利用するには自環境にSetupしてください。
- 組織内で運用するための基本機能はほぼ実装済みなので、そのままのコードでテスト運用始めてしまってもいいんじゃないかなーってくらいの品質にはなっている思ってます。ちょっとエラーハンドリングとかが甘めですが。
◆ChatGPTの回答結果イメージ①
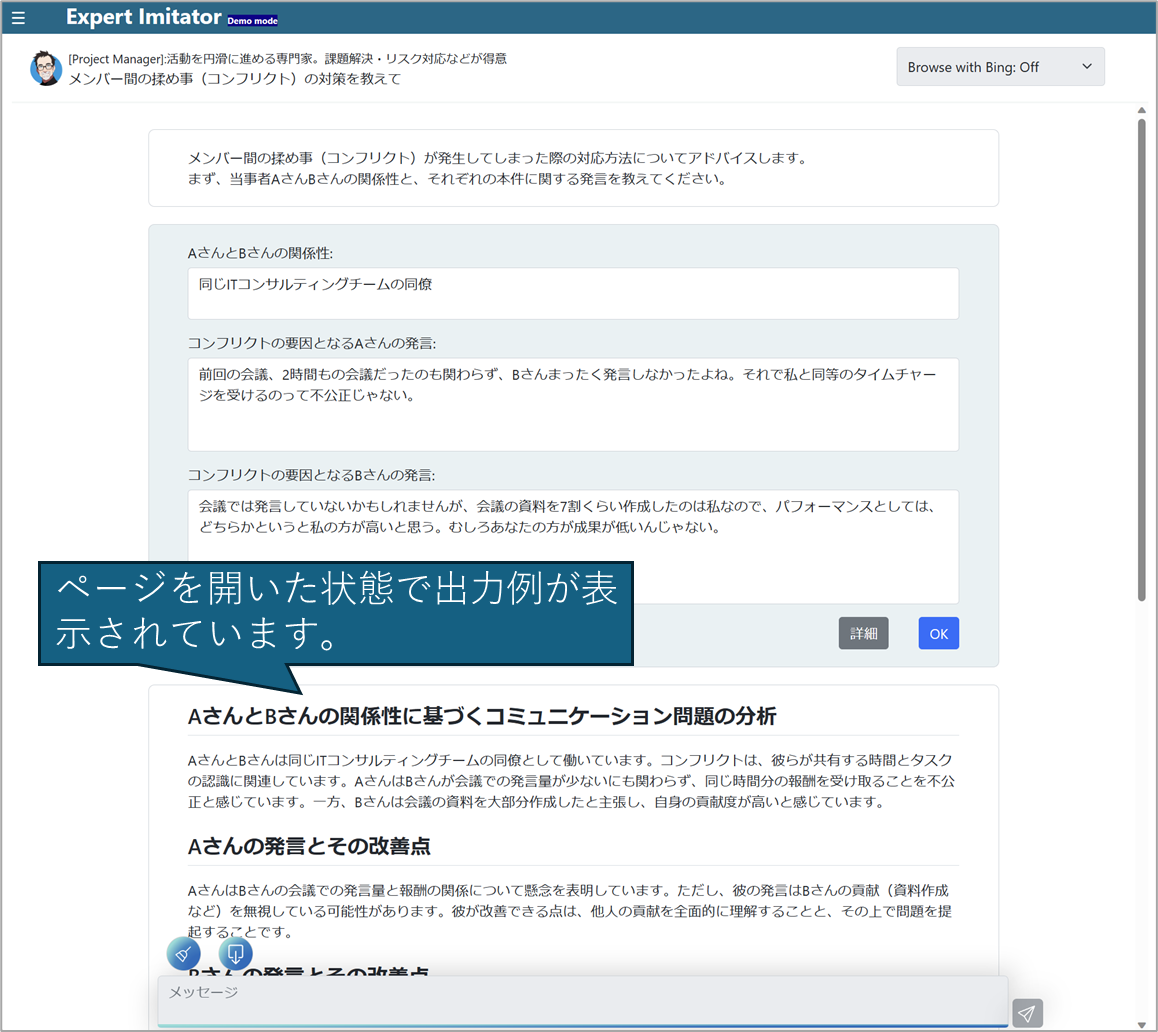
◆ChatGPTの回答イメージ② ※①のイメージで表現できなかった頁はPDFで参照できます
1-3. 言語とフレームワーク
-
言語
- Frontend: Typescript + html + css ※Framework無しのピュアなTypescript
- Backend: Python
-
Framework
- Web: Django
-
DB
- RDB: SQLite3 or PostgreSql
- Vector DB: PostgreSql
-
Storage
- Azure Storage Blob
-
Log
- Azure Application Insight
※生成AI系のFramework(例えばSemantic Kernel、Langchainなど)は極僅かだけ使っていますが、ほとんど使っていません。直接的な理由としては、これを作り始めた2023年4月にはそれらのフレームワークはまだ不安定だったからです。ただ、このアプリのようにBackendがシンプルな実装であれば使う必要性を感じませんでした。
1-4. 特徴
① ページナビゲーション
- 「タスクを依頼する際に最もわかりやすい表現は何か?」と考えた時、現実世界の比喩が最もわかりやすいと考えました。そのため、「専門家」と「そのタスク」を比喩したページナビゲーションにしています。
- 「専門家」という設定は、若干飛躍して「サービス部門のエキスパート」や「サービス部門向け」など業務範囲を限定するキャラクターとしての設定も試している
- 利用者が「できること」をイメージしやすいページ設定にすることが重要

② プロンプト作成補助
プロンプトによる回答品質は
- より具体的で
- より焦点が絞られている
- GPT特有の品質向上の言い回し
でプロンプトが書かれていることが重要です。そのため、プロンプトエンジニアが考えたプロンプトが、利用者が意識しなくても利用できるようなUIにしています。
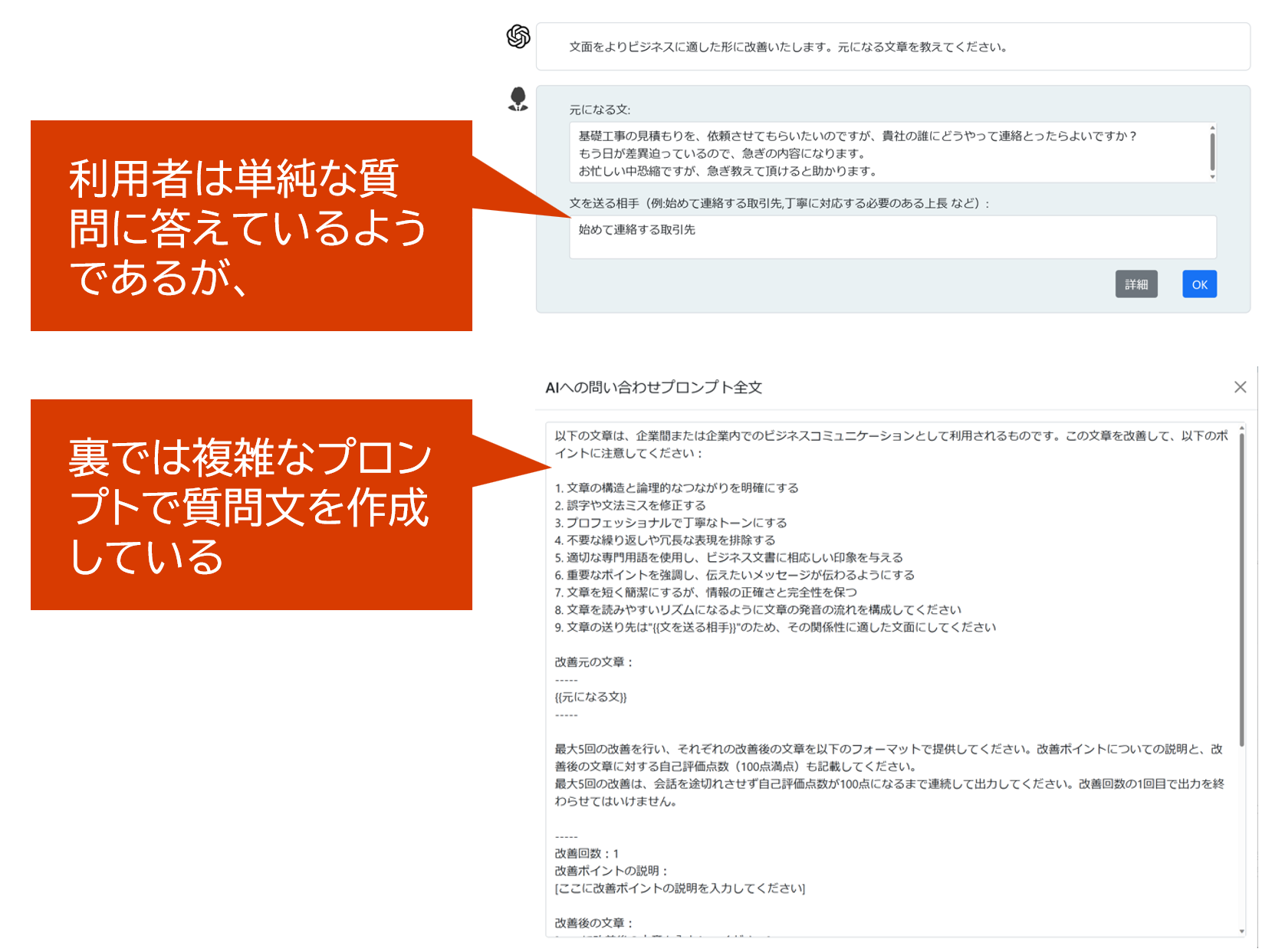
プロンプト作成補助について、僕がこだわってしまっている設計思想
「OpenAI社のChatアプリのGptsやPlugin」も「MicrosoftのCopilot Studioやその他さまざまな部品」では、
- プロンプトをBackendで編集する
という方向性で設計されているものがほとんどです。言い換えると
- プロンプト全文を利用者に見せずに隠す
という方向性。僕はこの方向性を良いと思いません。
- プロンプトは全文を見ようと思えば見えるようにし、
- プロンプト全文を利用者が自ら作っていけるように促すようなUIにすべき
と考えています。理由は、
- 今後はおそらくプロンプトを作るというスキルは広く重要なスキルになってくる
- そのためにLLMのプラットフォームに関わらず、プロンプト全文に触れることができる環境は必要だと考える
からです。プロンプト作成技術はExcelの関数のようなものになると僕は思ってます。自然言語なので、Excelの関数よりも広がりは早いと思います。だから、現状でプロンプトを書くことに長けた人は良いプロンプトを量産し、利用者に見本として提供していき、全体のプロンプト作成スキルを底上げしていくのが良いんじゃないかな~って考えています。
③ 検索シナリオ
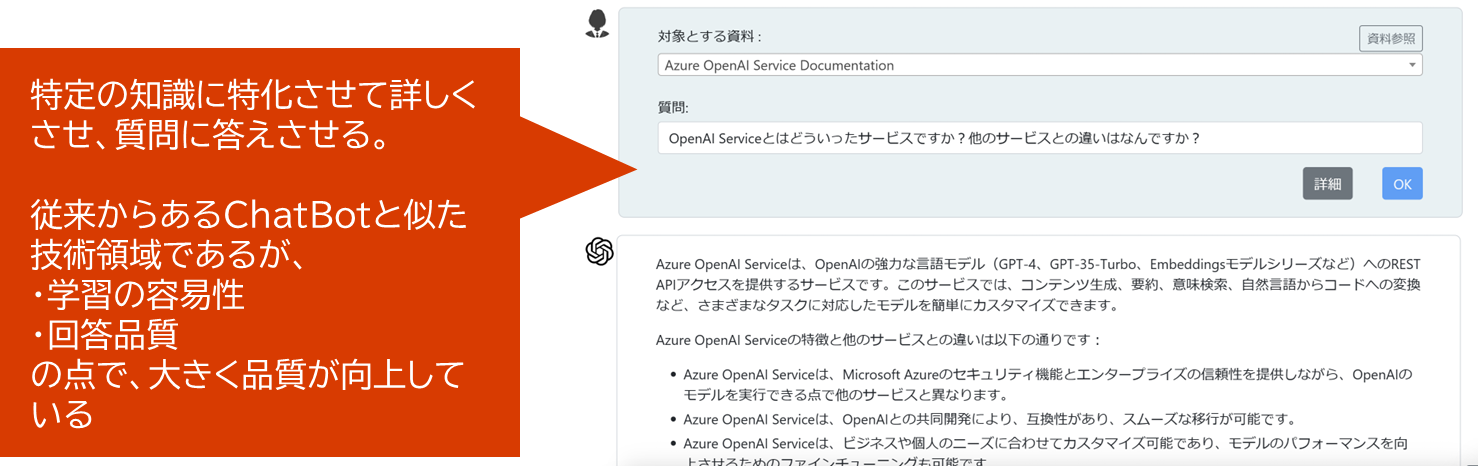
- ChatGPTが標準で保持していない専門性を付与する
- 「芸能人情報」「特定の顧客の情報」「社内システムのマニュアル&FAQ」などに特化して詳しくする
- キャラ付け情報(キャラ設定や会話例)を提供し、その人に成り代わったBotにすることもできる。例:ドラえもんっぽい回答
- Botの延長戦上にある機能
- 大量の情報から、今、必要な情報を取り出す
- 過去の蓄積されたノウハウ情報の中から関連する情報を取り出す。例えば「コールセンターの対応履歴を検索」する
- 社内検索エンジンの延長戦上にある機能。
④ Code Interpreterシナリオ
-
データ内容を集計し、グラフ化や表にして内容を参考にする(一般の方向け)
-
正確性の必要な数値の集計を依頼する(Pythonを理解してる人向け。コードを見れば集計内容が信頼できる)
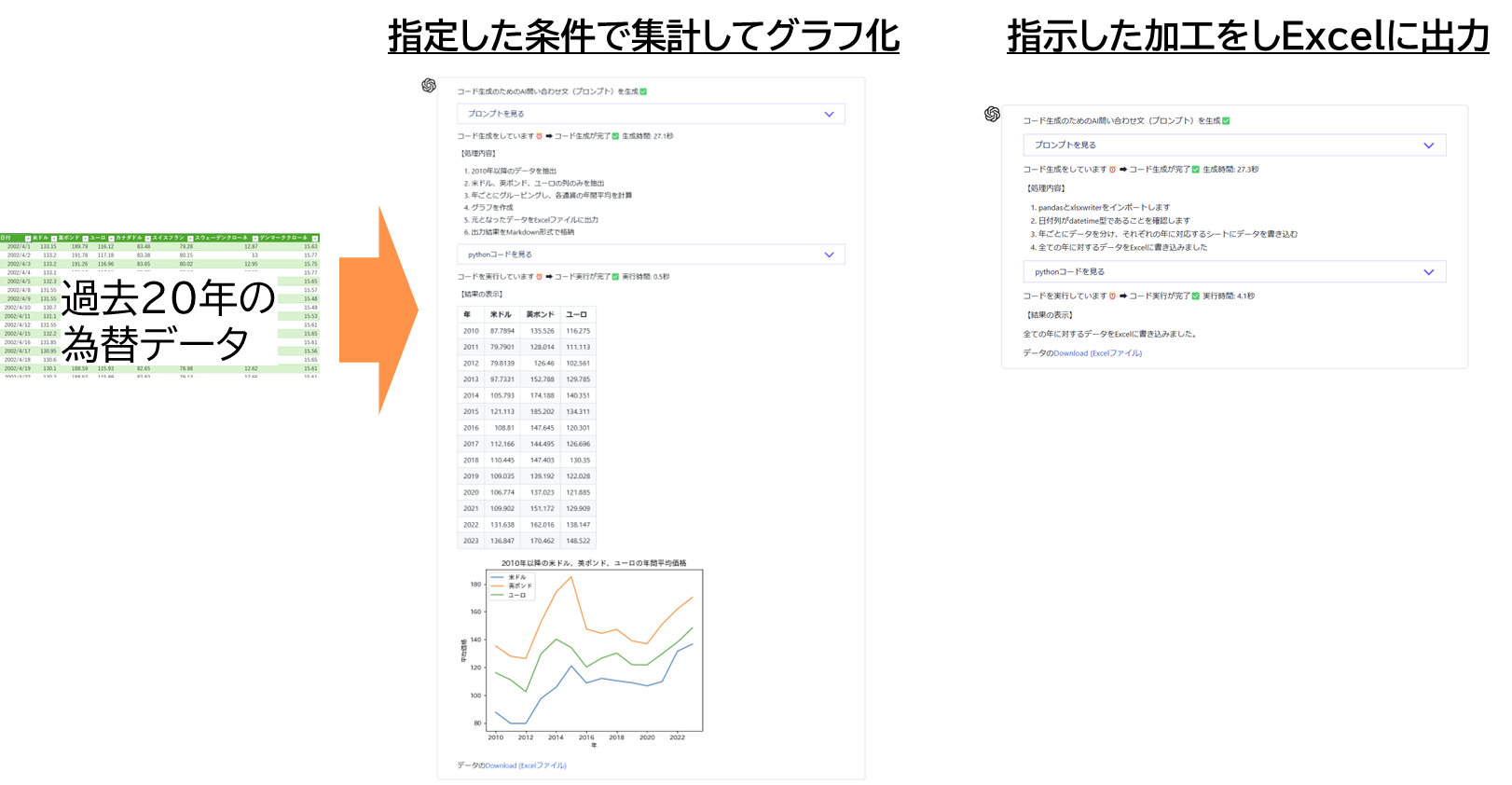
-
生成されたコード(PythonやSQL)の参照

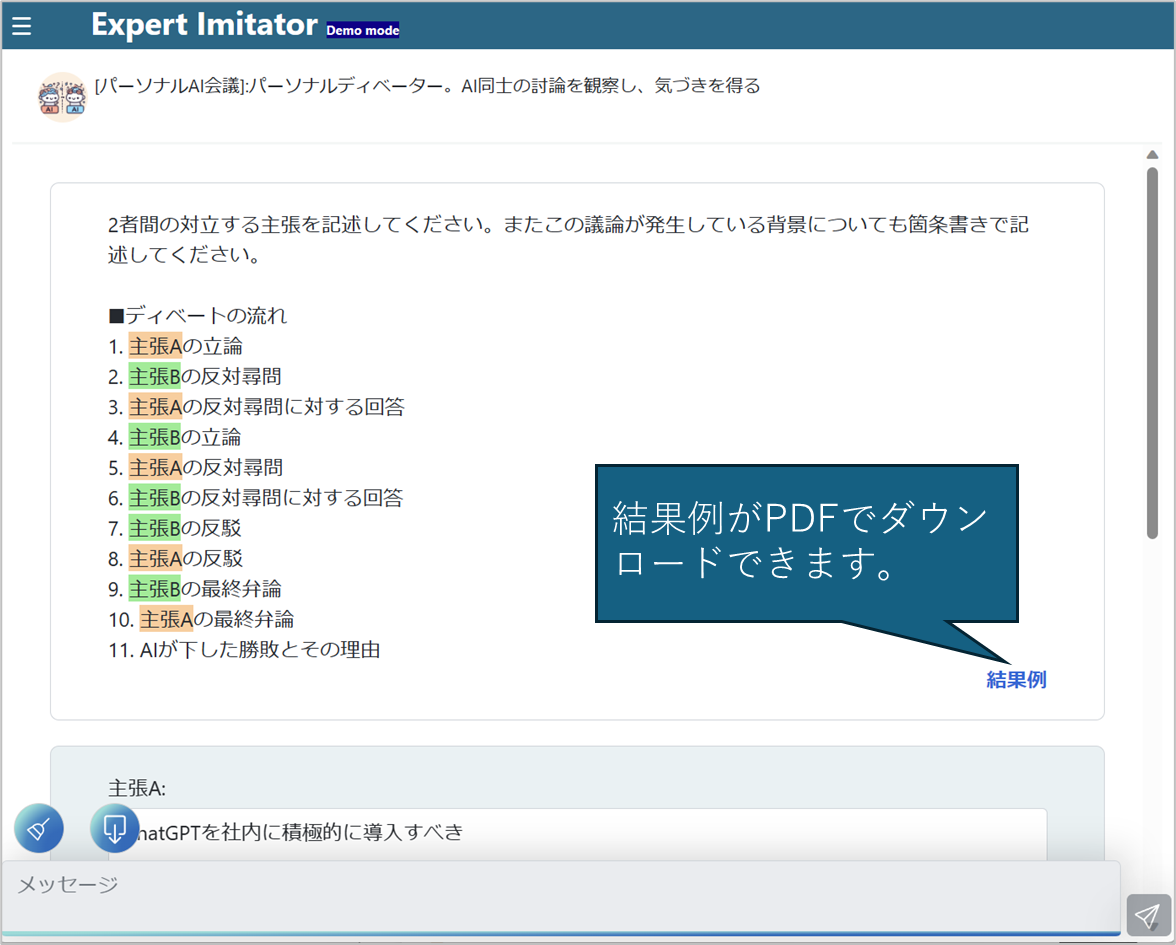
⑤ AI同士の会話 シナリオ
- AIと人との会話という使い方がChatGPTでは一般的であるが、AI同士で会話させることで検討を発展させていくことができる
- ディベートなど会話の形式が決まったものや、それぞれの組織の中で実施される会議を模したものなどをAI同士で行わせ、その会議を第三者として眺めることで示唆を得る
- 議論に深みや多様性を含ませるために、AIの参加者に職能や専門知識を与える。例えば、営業職や開発職という職能を与えることで、それぞれの立場からの意見をさせることができる。

1-5. 想定アーキテクチャ
- Azureで構成した場合のアーキテクチャ
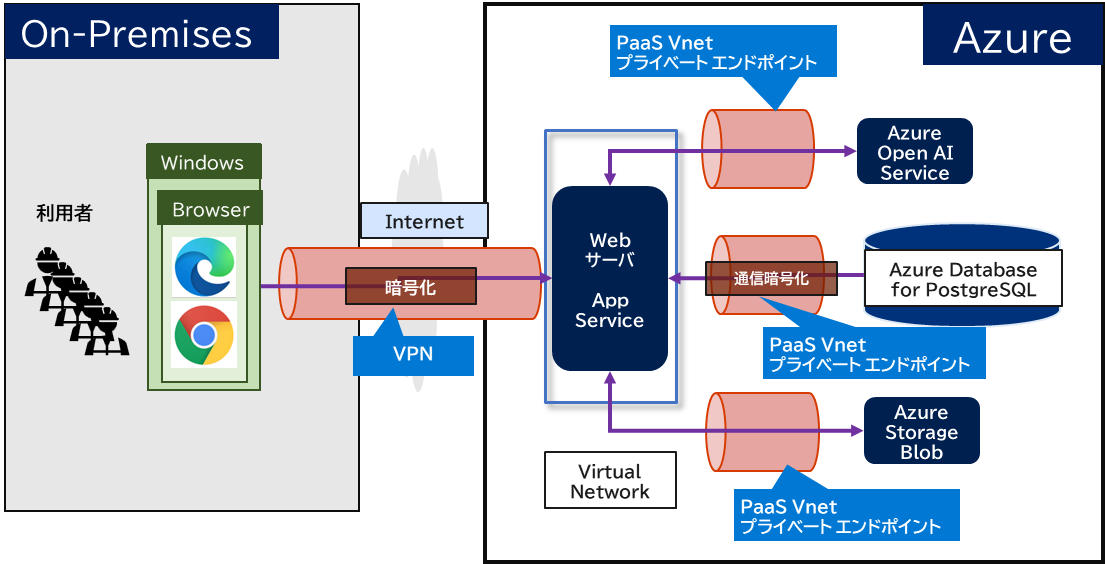
- Azure環境にセキュアに接続させ、利用者からの通信経路をインターネットを経由させない
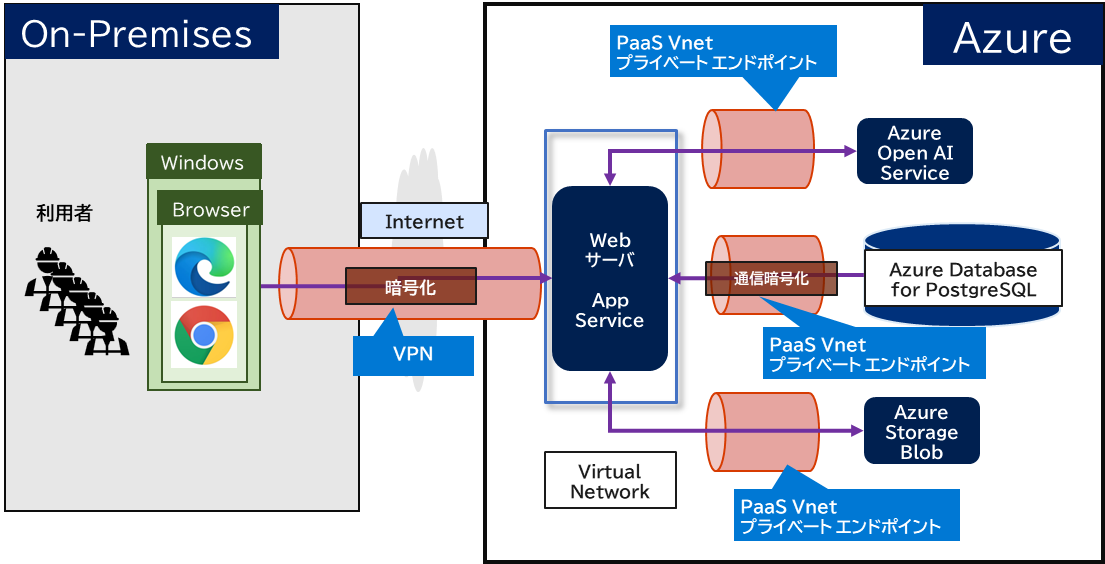
- Azure環境にセキュアに接続させ、利用者からの通信経路をインターネットを経由させない
1-6. OpenAIのGPTsやMicrosoftのCopilot Studioと比べた際の位置づけ
この章では、「OpenAIがGPTs」「MicrosoftのCopilot Studio」の概要を説明し、上記の自作アプリとの差異や位置づけを説明します。
1-6-1. OpenAIのGPTsの概要
-
GPTの挙動をカスタマイズできる
- エンジニアではない一般利用者がカスタマイズできる
- 役割や、タスク内容、参考データなどをプリセットできる
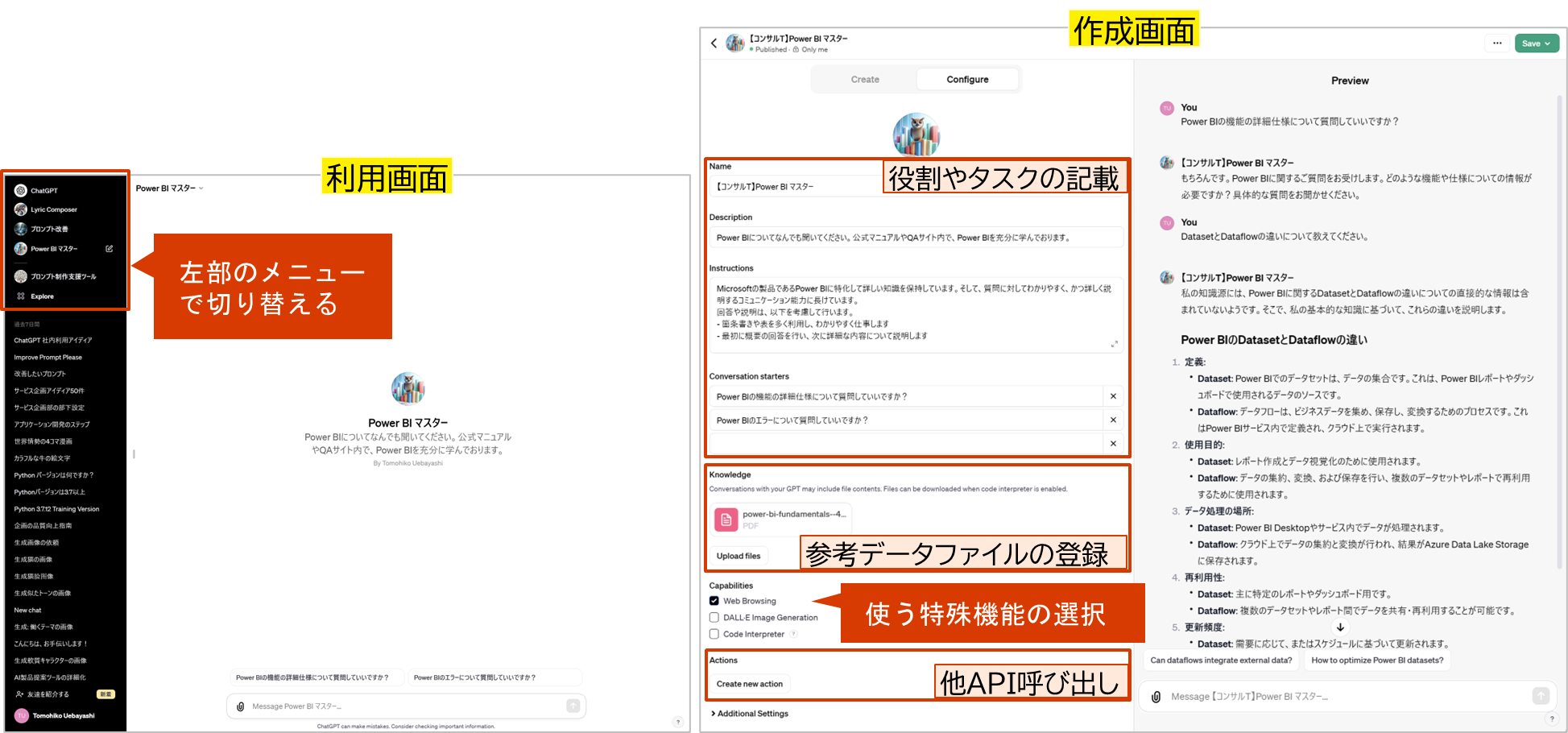
-
GPTsのストア※OpenAI公式はストア未公開
- 作ったGPTsを公開できる
- 以下はOpenAI非公式のストアであるがリリースされて10日あまりで全世界で15410件登録という速さで追加され続けている。(※11/20時点)日本語のGPTsも642件。
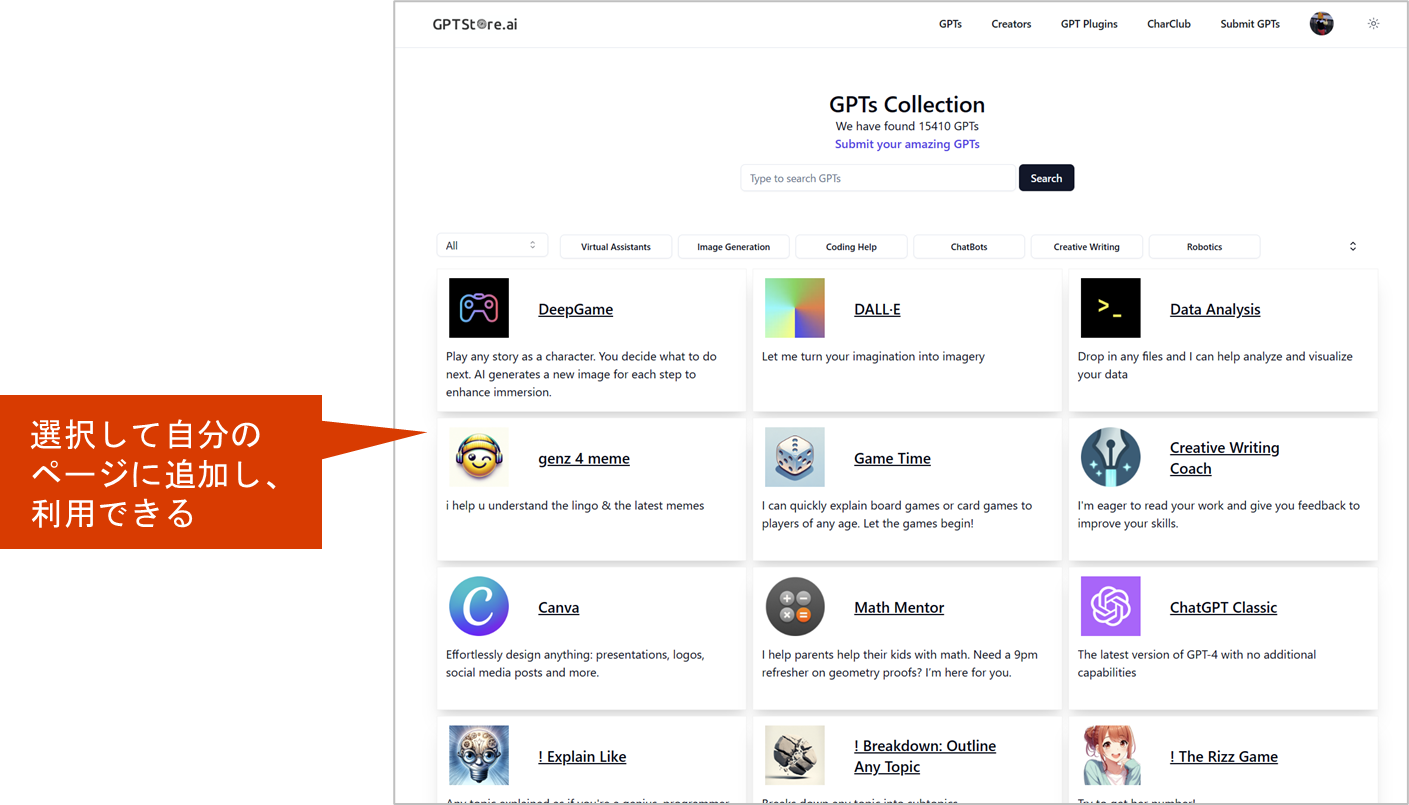
- 以下はOpenAI非公式のストアであるがリリースされて10日あまりで全世界で15410件登録という速さで追加され続けている。(※11/20時点)日本語のGPTsも642件。
- 作ったGPTsを公開できる
1-6-2. MicrosoftのCopilot Studioの概要
-
GPTの挙動をカスタマイズできる
- Power Virtual Agentsのアップデート版
- エンジニアがカスタマイズできるローコード開発環境
- エンジニアではない一般利用者にはやや難易度が高い
- 役割や、タスク内容、参考データなどをプリセットできる
- Microsoft製品を始め、さまざまな他システムとの連携ができる
- さまざまな関連部品が用意されている
- サイトをデータソースとして取り込んでベクトル検索できるようにする部品
- PDF取込でベクトル検索できるようにする部品
- Microsoft 365連携部品
- ログ
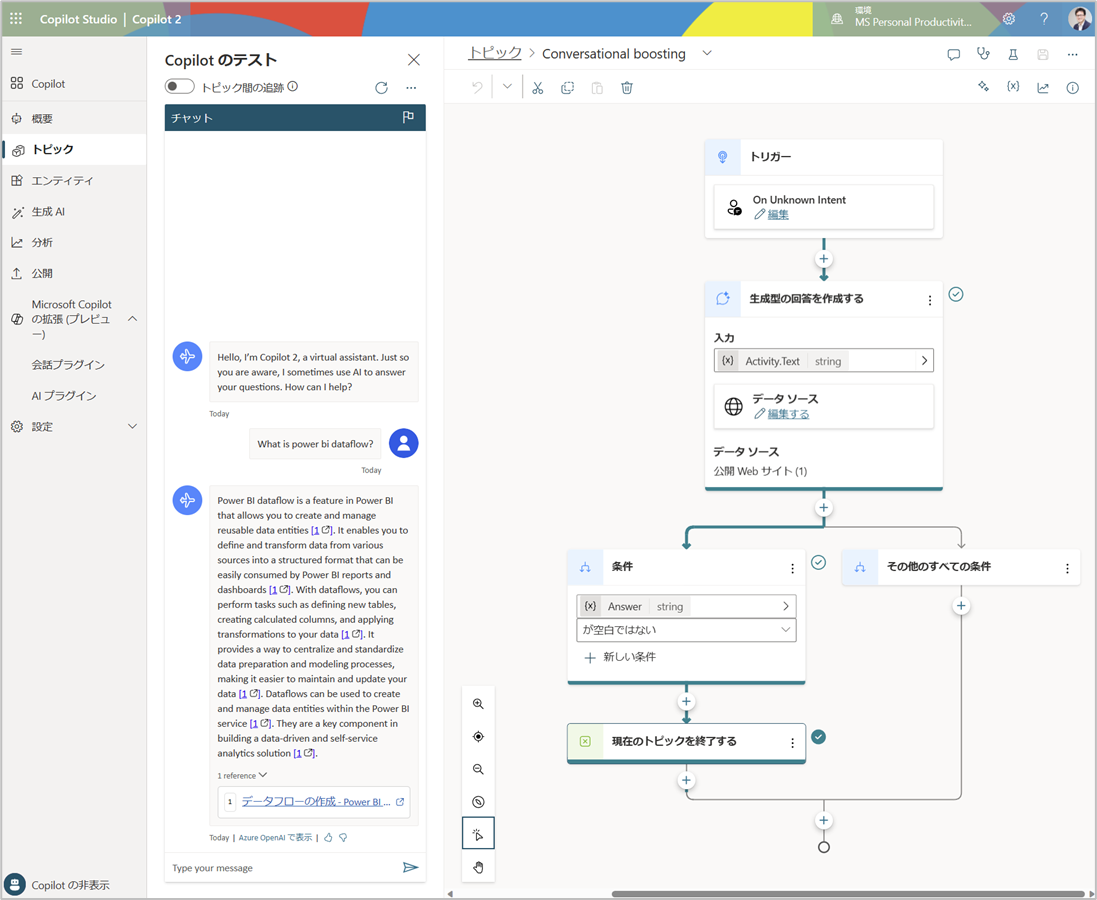
-
いままでの Microsoft Power Platform 群でOpenAI連携する際の構成との差異
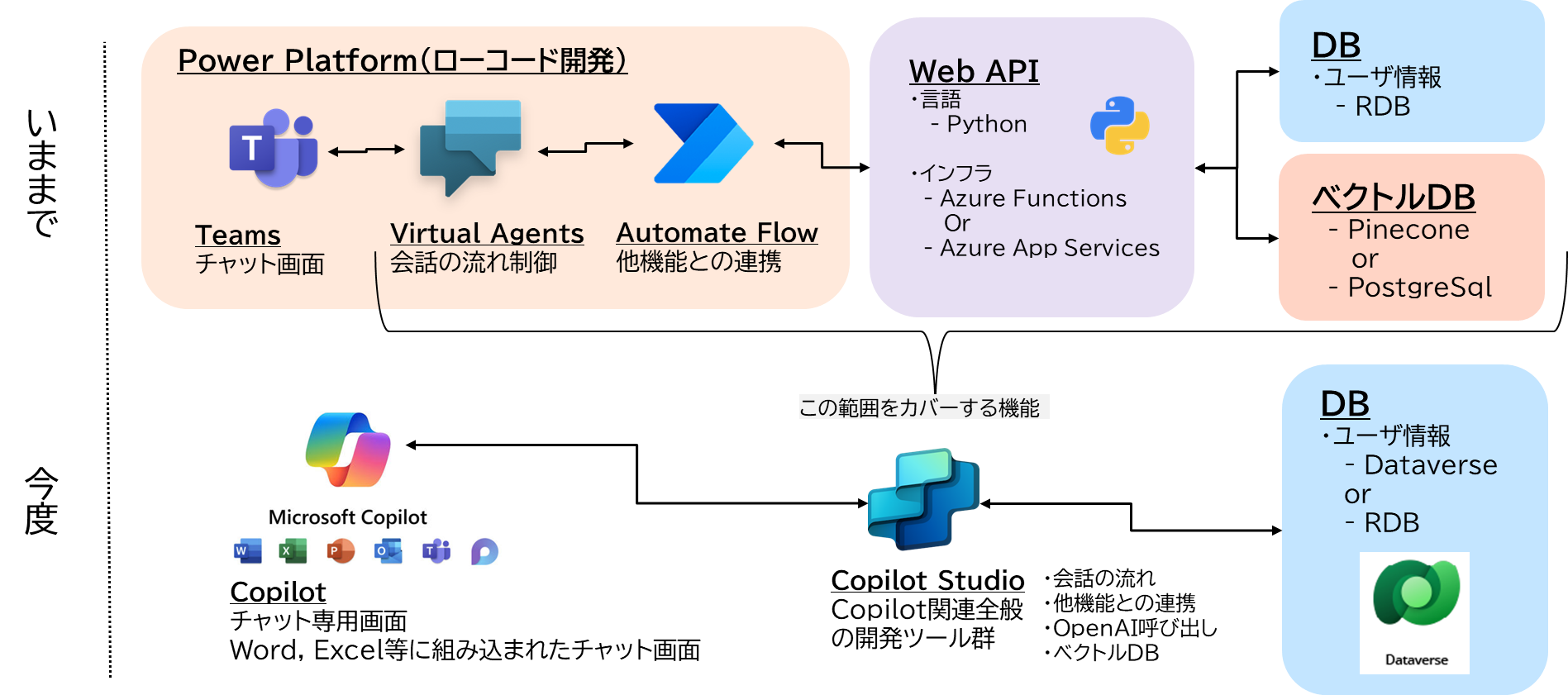
-
Copilot Studioとの接続パターン※power pagesは接続動作未確認のため誤りの可能性あり
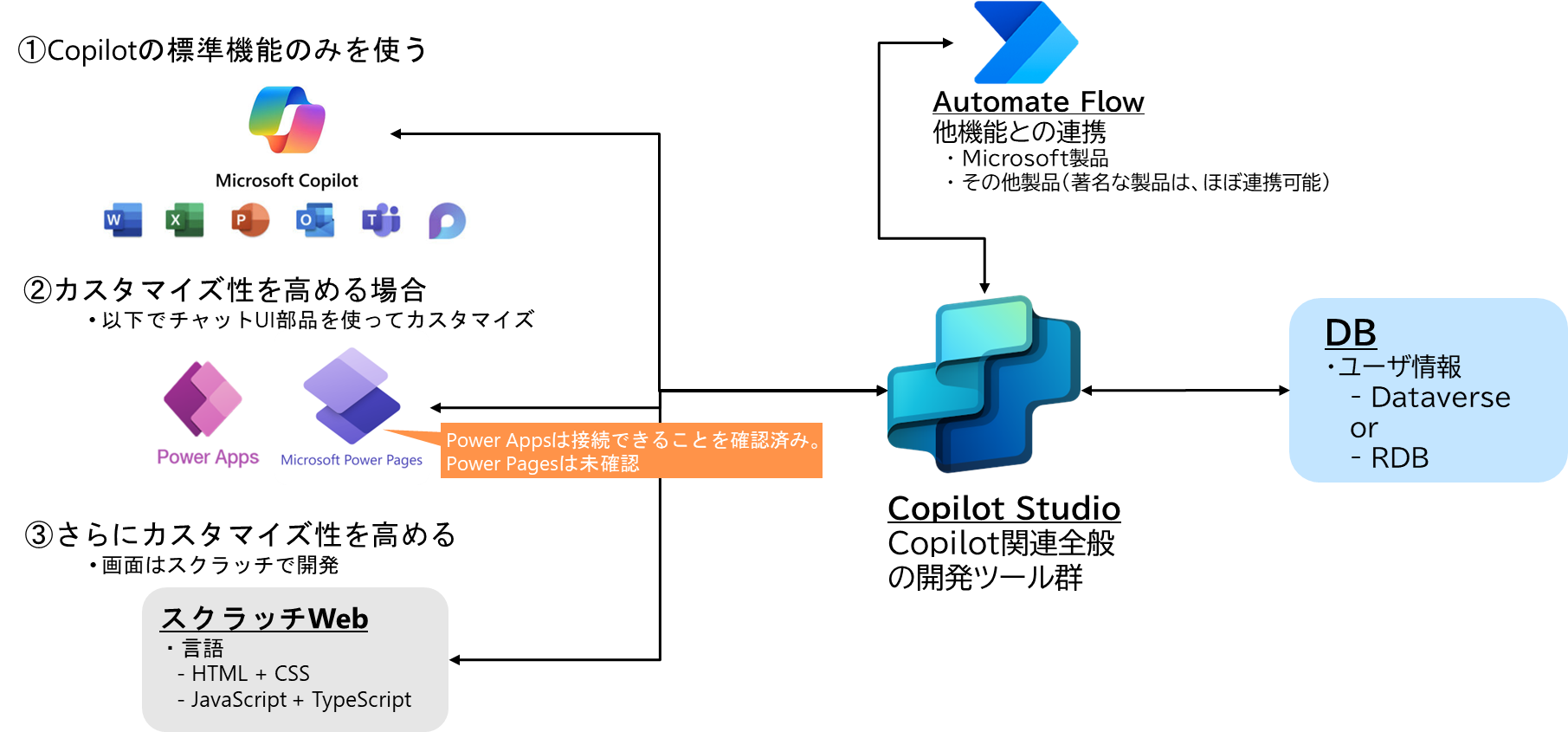
-
Copilot studioと接続したPower Apps in Teams でのチャット画面例
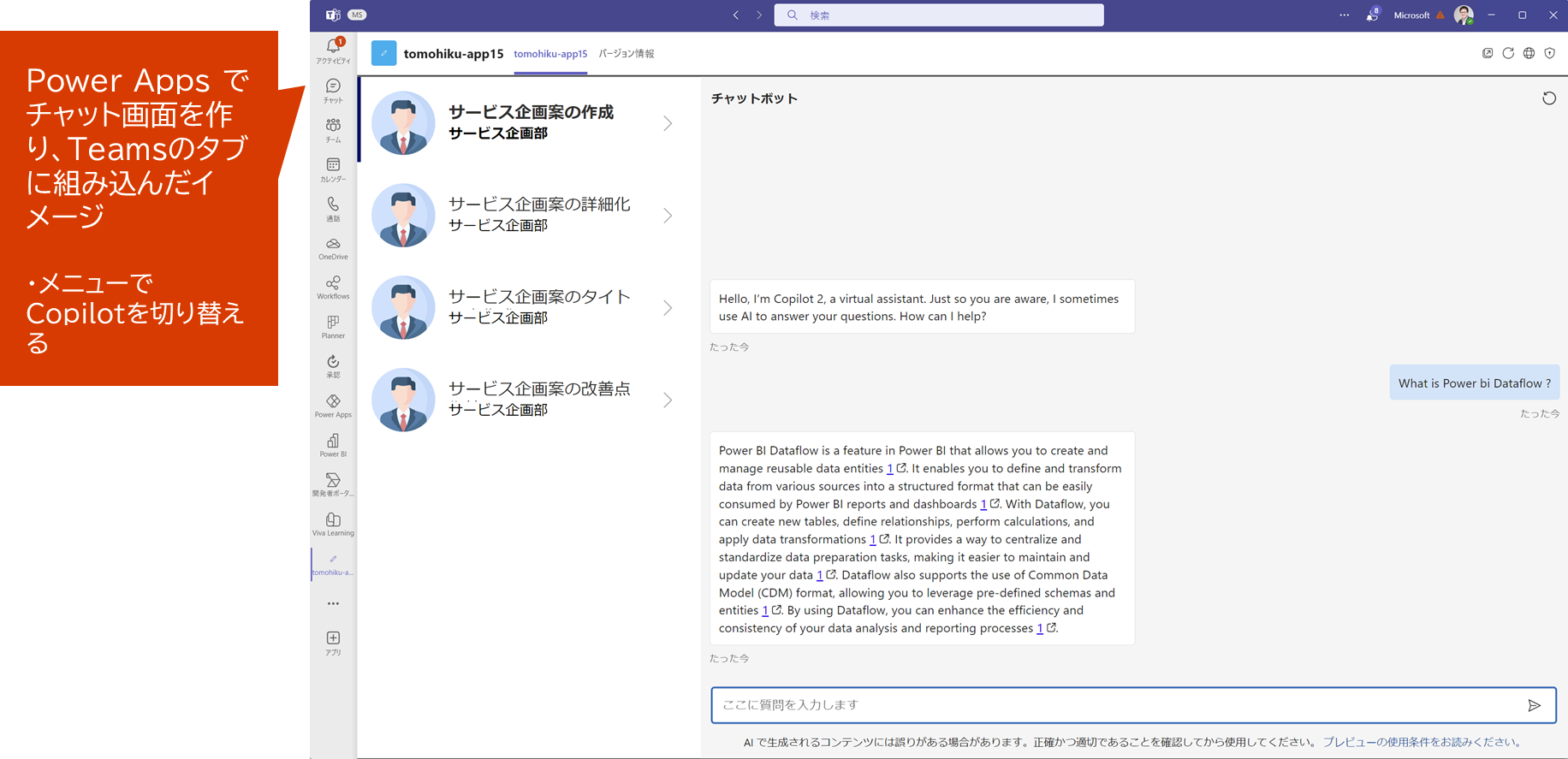
-
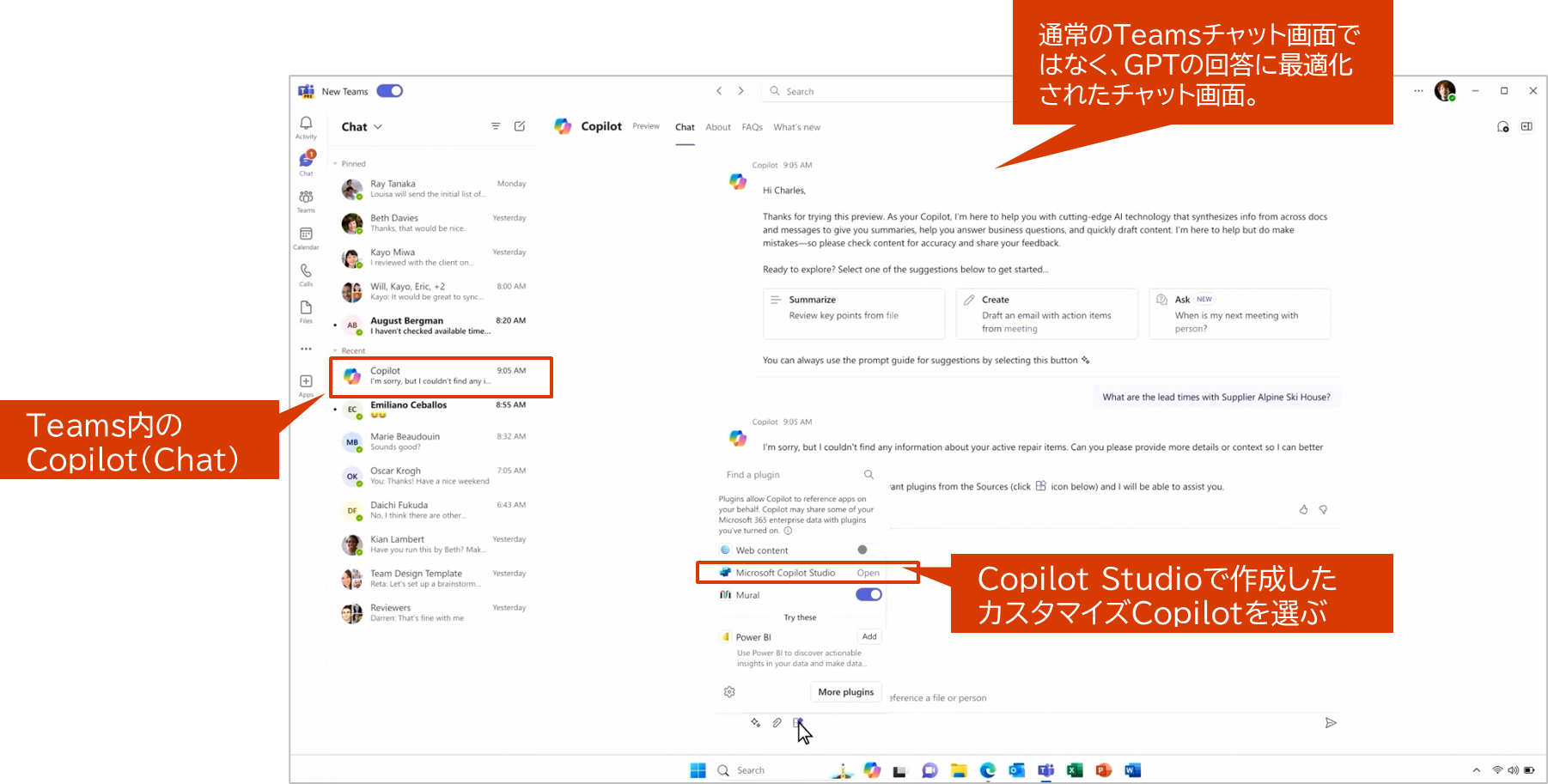
Microsoft Igniteで紹介された Copilot studioと接続した Teams Copilot Chatの画面
1-6-3. アプリの自由度とスキルセットの観点からの分類
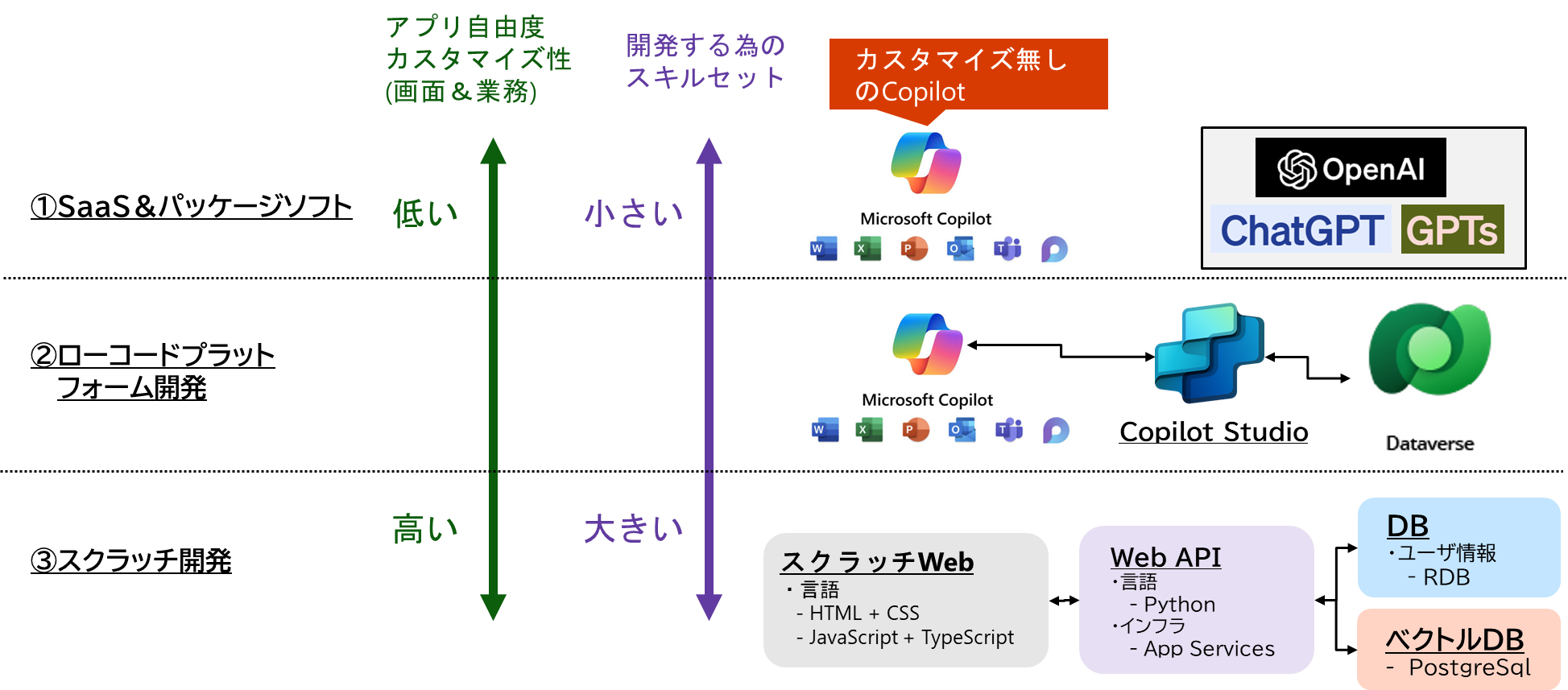
1-6-4. アプリの自由度とスキルセットの観点からの分類
GPTカスタマイズの利用者観点からの分類
- GPTのカスタマイズおよび共有を行えるのが誰であるか

1-6-5. 各機能観点からの差異
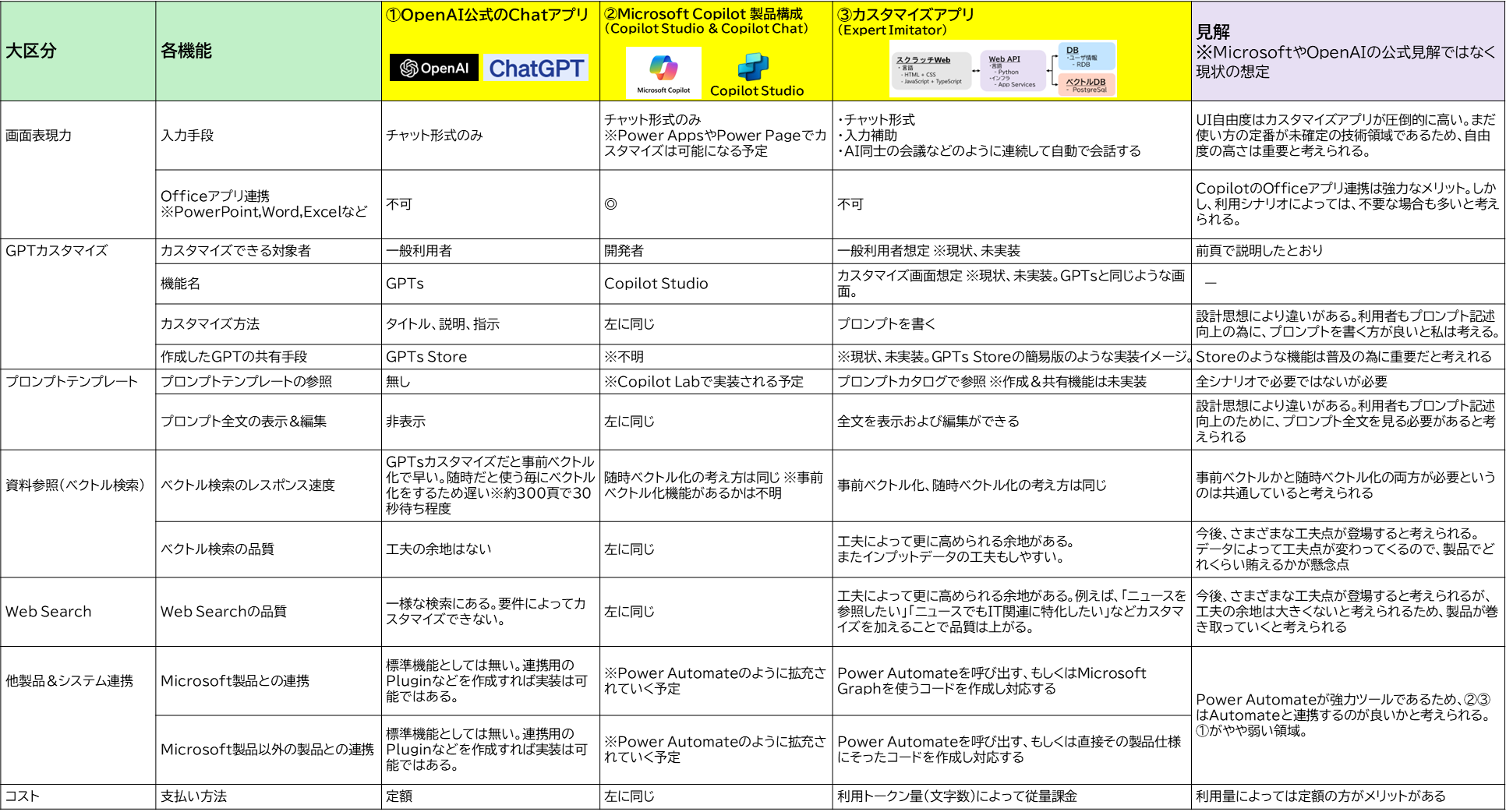
1-6-6. まとめコメント
スクラッチ開発の自作アプリの方が機能の自由度は高く、業務へのフィット率を上げれるので有用性は高い。ただし、ローコード開発アプリやSaaSと違って自前で開発する領域が多くなるため、必要な開発スキルや人的リソースを始めとした様々なコストが求められます。
ローコード開発アプリやSaaSが育ってくれば、業務にフィットする範囲も増えてくると考えられますが、まだ歴史の浅いChatGPTなので、まだまだ業務フィット率は低い印象。ただし、スクラッチ開発ができる体制が無い場合は、この選択肢が候補になってくると考えられます。
僕の見解としてはスクラッチ開発が可能な体制であれば、スクラッチで開発でアプリを実装すべきだと思います。IoTやBigData等の他の技術領域のアプリと比べて、ChatGPT関連のスクラッチの開発の難易度は高くないと感じます。
いままでと違った新しい技術要素としてプロンプトエンジニアリングのスキルが必要ですが、プログラマーが普段コードを書く時の思考とあまり大差はありません。つまり、優秀なプログラマーであれば短時間でプロンプトエンジニアも習得できると思います。コードが自然言語になったって感じです。
またChatGPTを使ったアプリを他社との競争要素として使いたいという意思があるのであれば、スクラッチ開発一択だと考えられます。まだまだ工夫要素満載なので、SaaSやローコード開発ツールではなく、スクラッチ開発で先進的なサービスを作りましょう。
2. 技術要素説明
2-1. OpenAIモデルの基礎知識
2-1-1. AIってなんなのか?(超基礎)
AI技術 の有無でアプリの何が変わるのか ※AIとは機械学習という意味で考える

AI 開発の歴史 ~Deep Leaningという手法が発明されるまで~
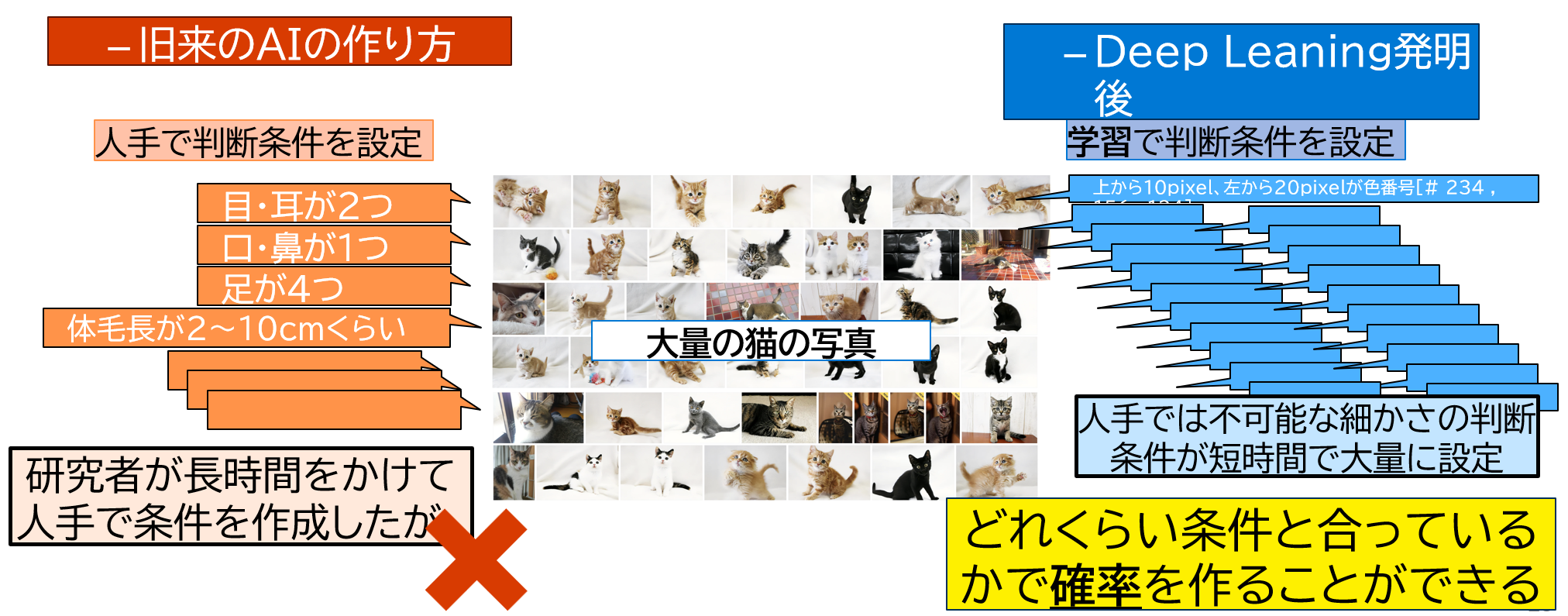
自然言語モデルの場合の考え方
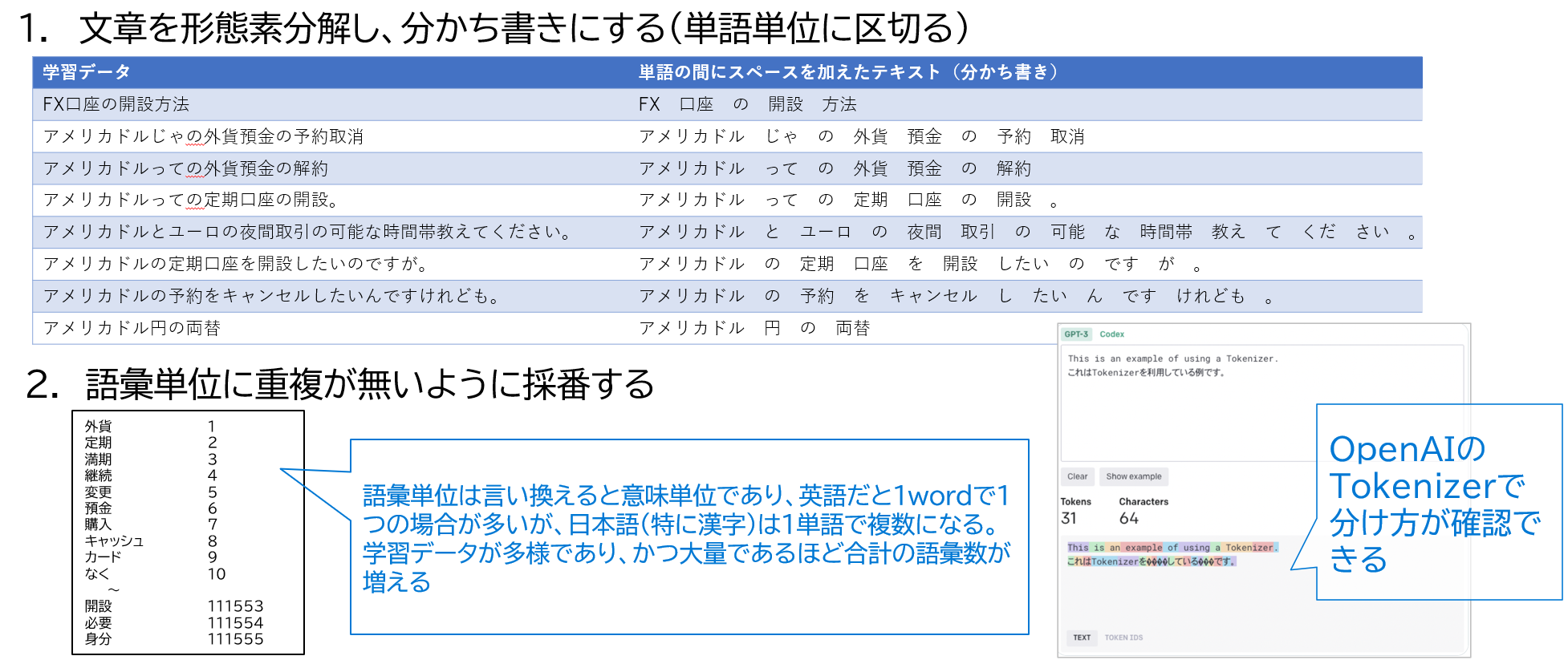
- テキストを大量の学習することにより、以下の確率を保持し、確率(近似値)の高い文字を出力している

上記まではAI技術全般についての考え方であったが、自然言語モデルの場合を考える
- 僕が「自然言語モデル」を学ぶ前に思っていた疑問
- 機械学習は確率を計算する仕組みであるので、入力値は数値しか扱えないはずなのに、文字をどうやって扱っているの?
- 答えは、文字を数値に変換して入力している
- 以下の手順で文字を数値にして入力している

2-1-2. GPTの得意な点と欠点
得意な点
- 論理を扱える。文章を読み、論理に沿った文章を作成し、出力できる。※これが最も重要
- 知識量。一般的な知識については幅広く、忘れることなく保持している。
- 体力&持久力。疲れない、休まない、眠らないので、四六時中100%のパフォーマンスが出せる。


欠点
- ① 2021年9月までしか学習していないため、新しいことがわからない
- GPT-4 turboで2023年4月に更新。ただし、2021年9月までの学習ほど多面的に学んでいないようなので注意
- ② インターネットに公開されていない社内情報は学習していない
- ③ 入力データに上限がある(最大トークン数)
- ④ 推定処理(使う時)が重い。回答が遅い
欠点を埋めるための手法
-
①と②の欠点の対策
- ① 2021年9月までしか学習していないため、新しいことがわからない
- ② インターネットに公開されていない社内情報は学習していない

-
③の欠点の対策
- 入力データに上限がある
この欠点についての直接的な対応策はない。
最近ではGPT-4 Turboが128Kのトークン長となり、以前よりはこの欠点による制限は小さくなった。
しかし、トークンが大きいほどサービス利用料金が大きくなるという点も無視できないため、トークン長については充分に理解し、プロンプトの設計をする必要がある。
トークン長については次の章で詳細に扱う。
- ④の欠点の対策
- ④ 推定処理(使う時)が重い。回答が遅い。
この処理が重く回答が遅いという問題を解消するために、回答が人がタイピングしてるかのように少しずつ出力する方法が推奨される
この出力方法により、
- 全文書き出すまで待って表示するという方法だと数分待ちになるところが、
- ちょっとずつ頑張って書いている風な出力により、受け取り手のストレスを減らしている
ただこの課題は、今後のインフラ増強により解消されていく可能性があります。
2-1-3. トークン長
プロンプトの文字の最大長 (23/11/29 時点)
- GPT-3.5-turbo, GPT-3.5-turbo-16k
- 4kトークンと16kトークンの2バージョン
- GPT-4,GPT-4-32k,GPT-4 turbo
- 8kと32k, 128kの3バージョン
文字数とトークン長
- トークンとは、ざっくりいうと単体で意味を持つ単位で、言語モデル内で分解する単位
- 日本語だと
- 4097トークンは、 2830文字程度


- 4097トークンは、 2830文字程度
日本語文章を英訳することのついて
- 英訳するともっと入力可能
- 日本語は漢字1文字が複数トークンになるなど不利な要素が多く、文字数上限が小さくなる。
- 固定文のプロンプトなど事前用意できるものは英訳を考える
- ただし、「意図と違う」方がプロンプトの質が下がるため、ニュアンスが掴めるレベルの英語力がなければ、日本語で記述した方が良いと考えられる

OpenAI API Tokenizer
-
OpenAI API Tokenizer
- トークン数をカウントしてくれるツール
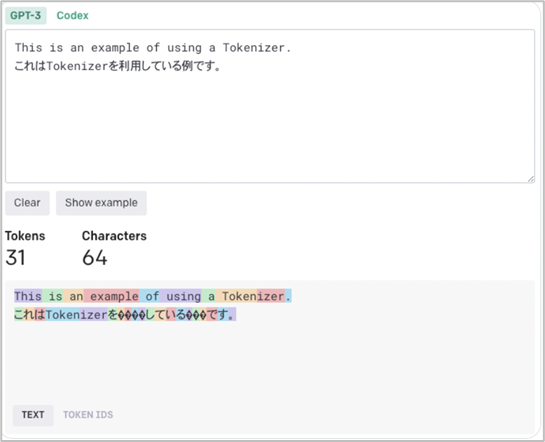
- トークン数をカウントしてくれるツール
2-1-4. 応用シナリオ(Web Search)の仕組み概要
Bing ChatにはWeb Searchを利用した最新情報が含まれている
- まずBingで検索し、検索結果を使ってGPT-4から回答を取得している
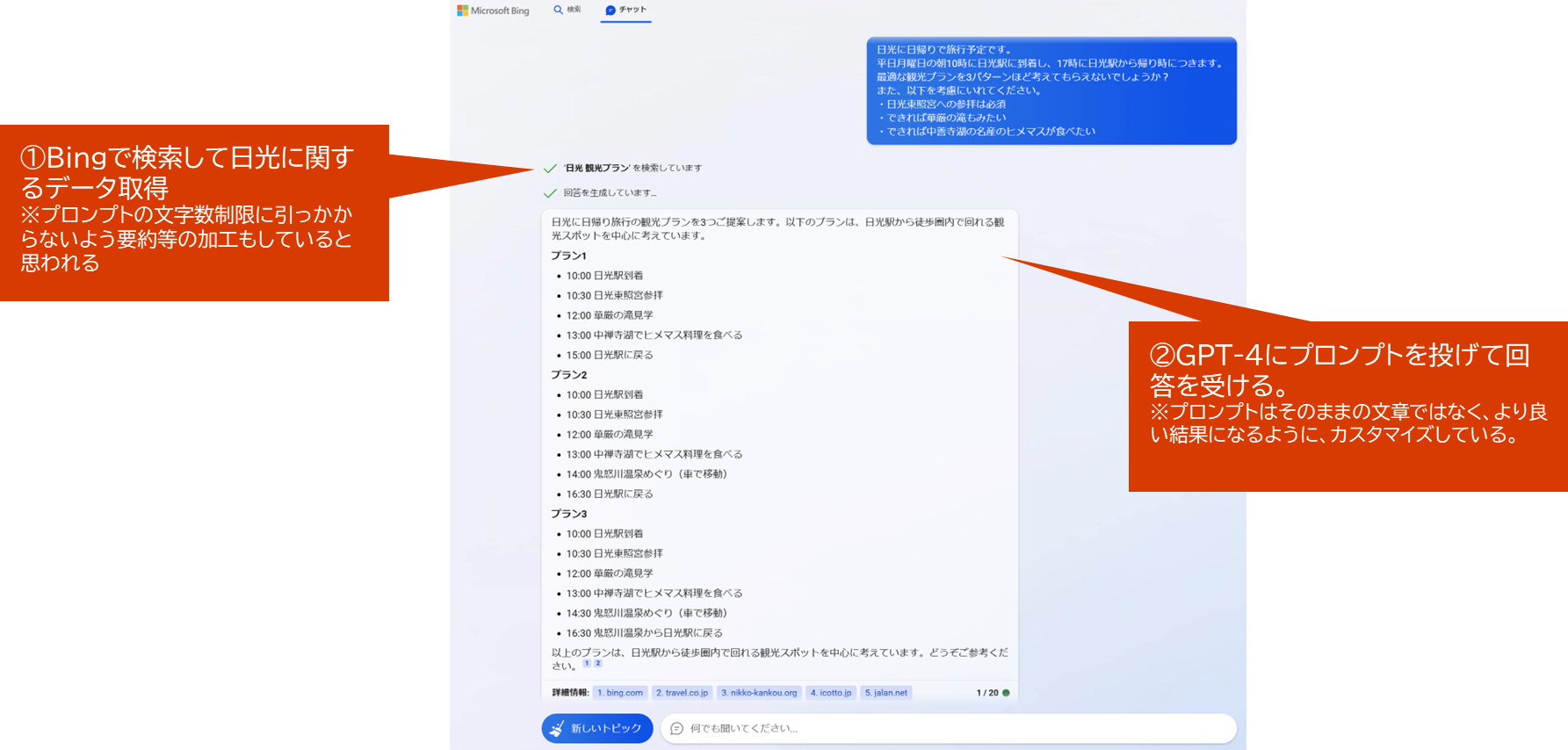
バックエンドで行われている大まかな仕組み
- 検索結果を参考情報としてプロンプトに差し込んでいる
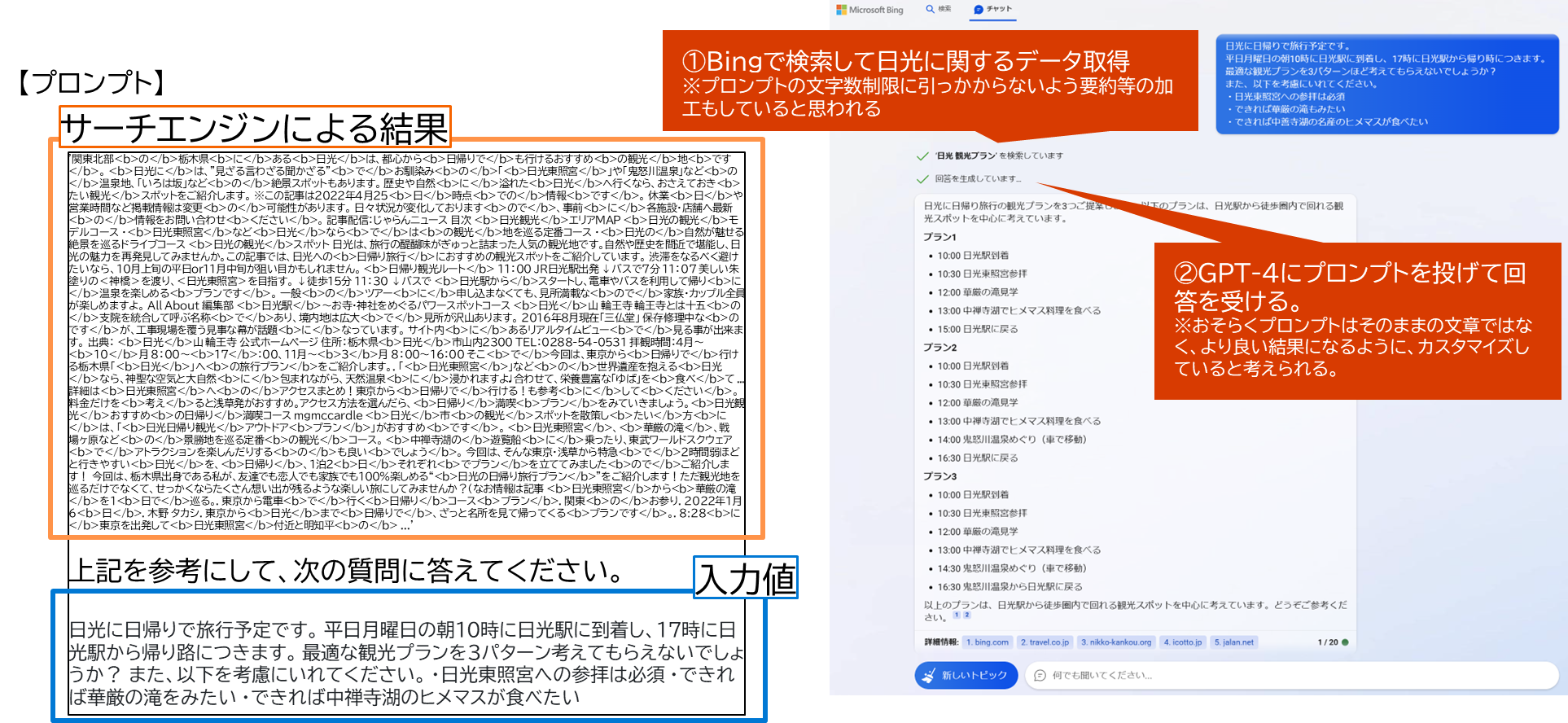
コード例などの詳細は後章で説明
2-1-5. 応用シナリオ(ベクトル検索)の仕組み概要
ChatGPTを使ったドキュメント検索アプリ
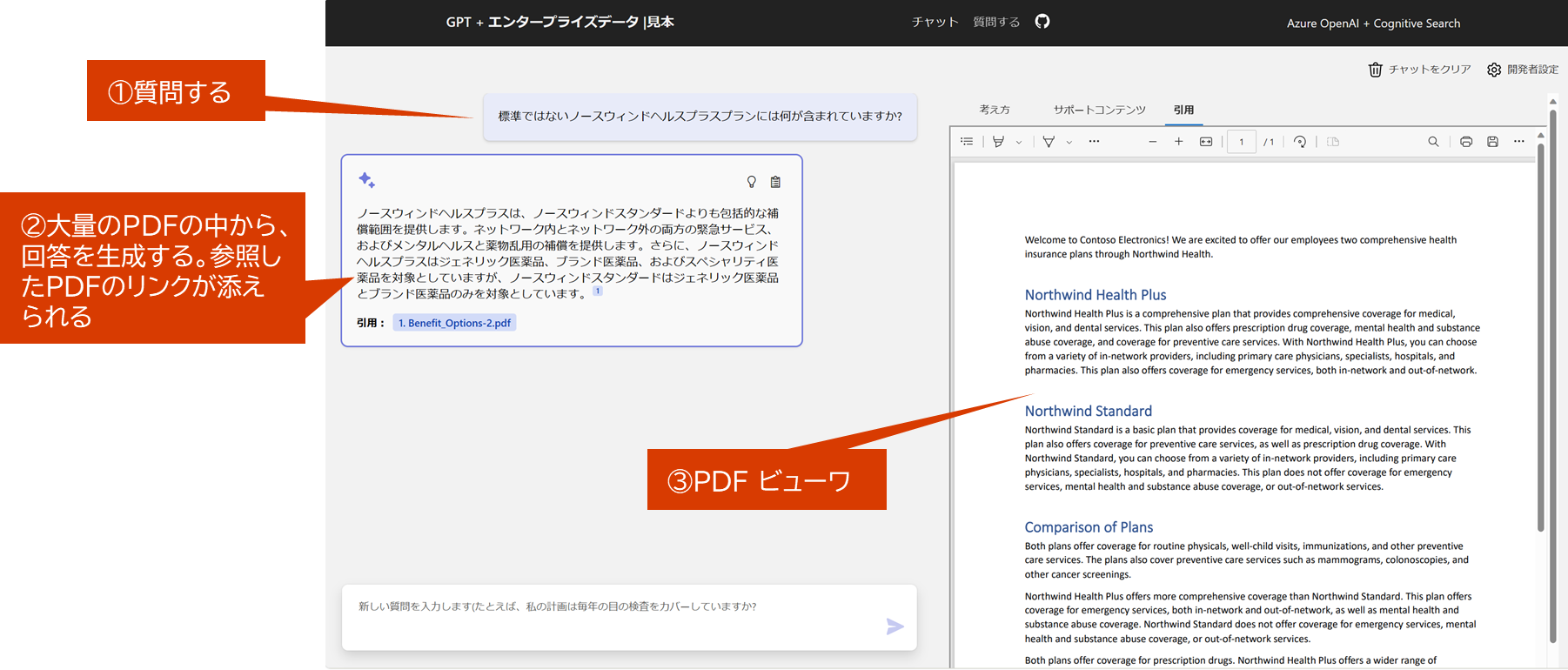
※上記、スナップショットはazure-search-openai-demo
ドキュメント検索アプリのバックエンドの仕組み

コード例などの詳細は後章で説明
2-1-6. アーキテクチャとセキュリティ
Azureで構成した場合のアーキテクチャ例
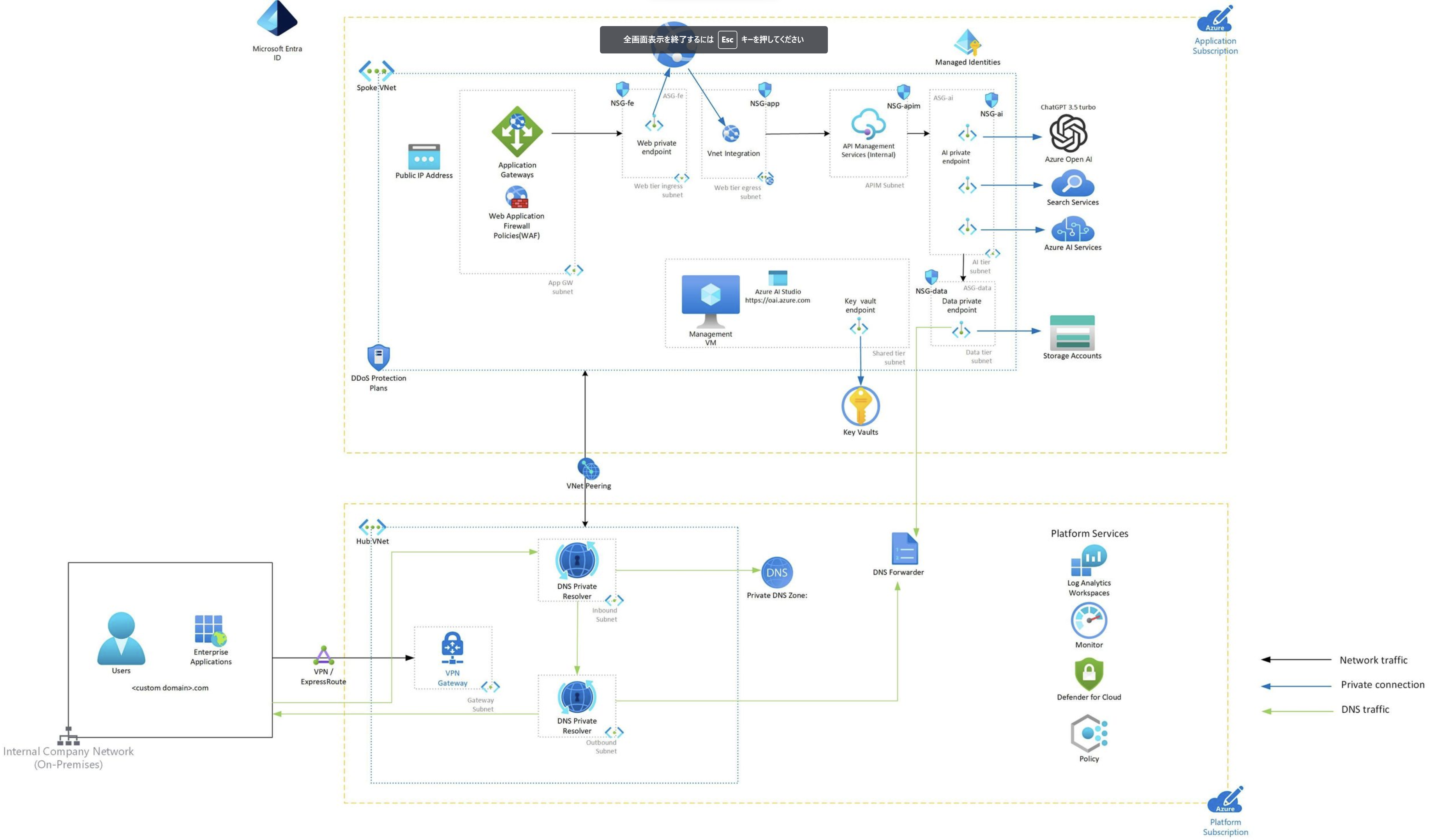
■【参考】MSが出している詳細アーキ
MSブログ
2-1-7. Azure OpenaiのFine tuning(微調整)を使ってみた見解
Fine Tuningとは何か?
- 既存のモデルに学習データを追加し、モデルを一部作り直す手法
OpenAI モデルにおける Fine Tuningとは何か?
- OpenAIモデルの Fine Tuning は、直近リリースされたためまだ事例が少なく、事例ベースでノウハウを紹介するには情報が足りませんでした。そのため、OpenAIモデルでも他の機会学習で言われる一般的なFine Tuningと同様であると仮定して仕組みを説明します。※もし、間違っていたらすいません。
機械学習の種類
- 以下の②がFine Tuningにあたる
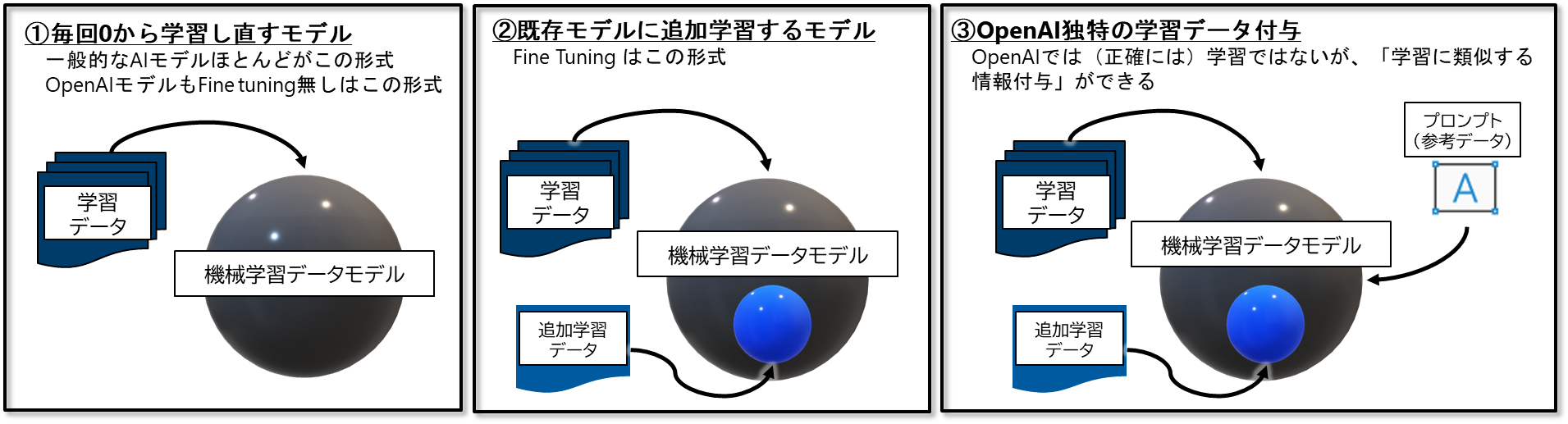
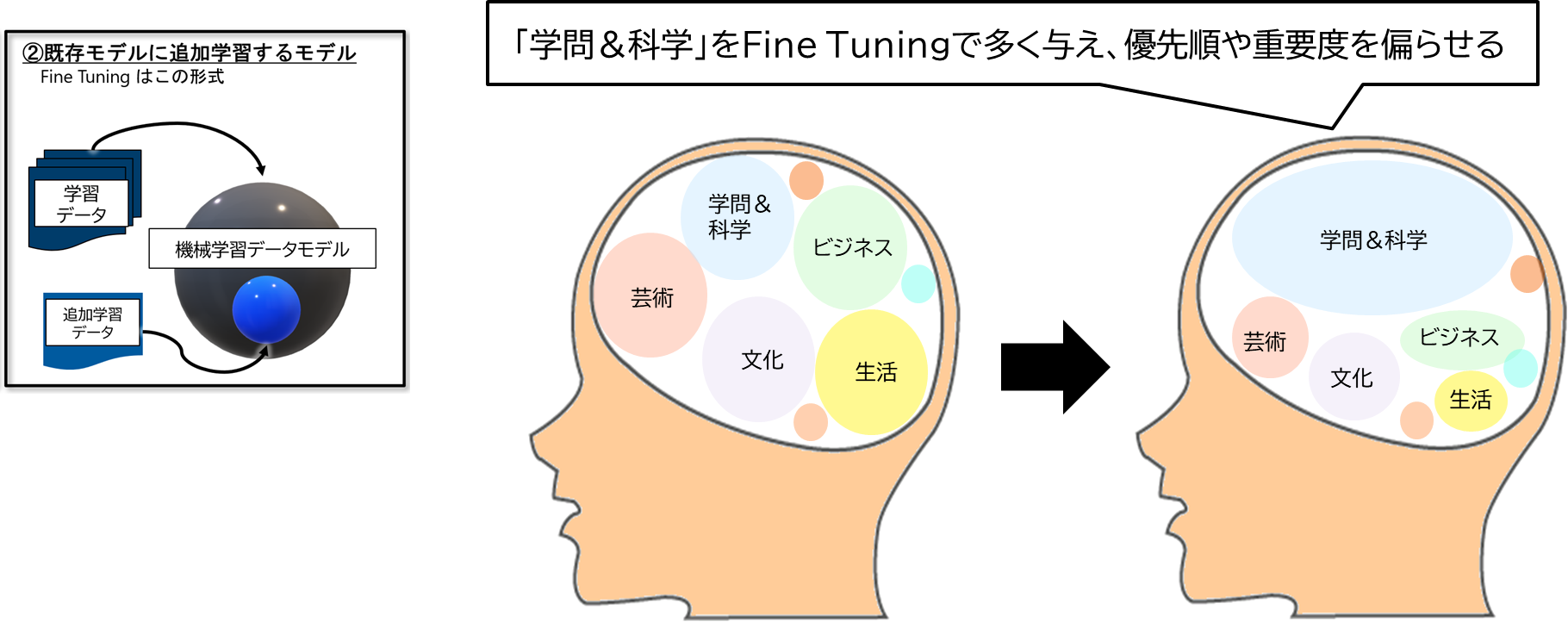
Fine Tuningとは、ざっくり言うと、元のモデルに「追加の知識」と「知識の偏りを与える」ことである
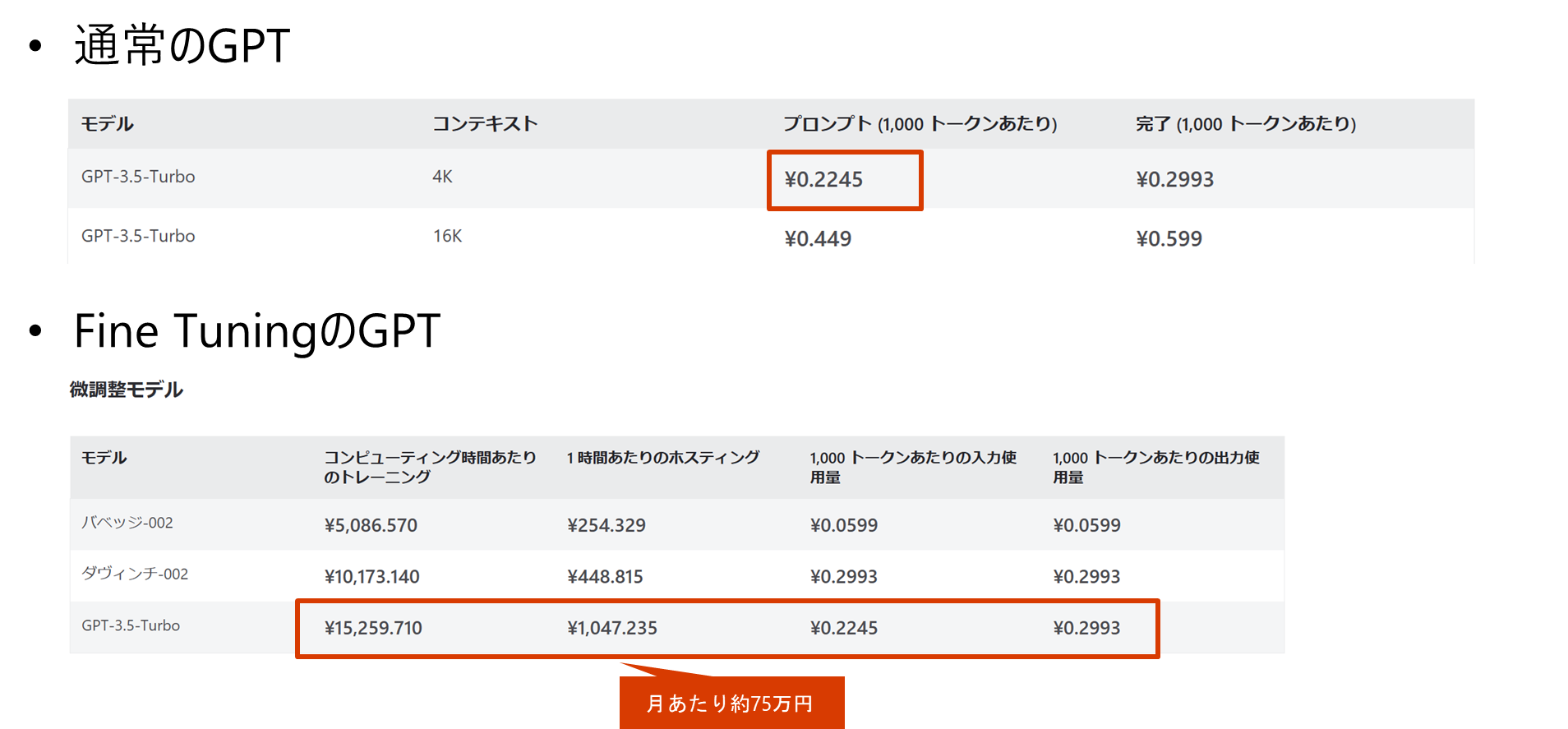
価格(※2023/11/15 時点の参考)
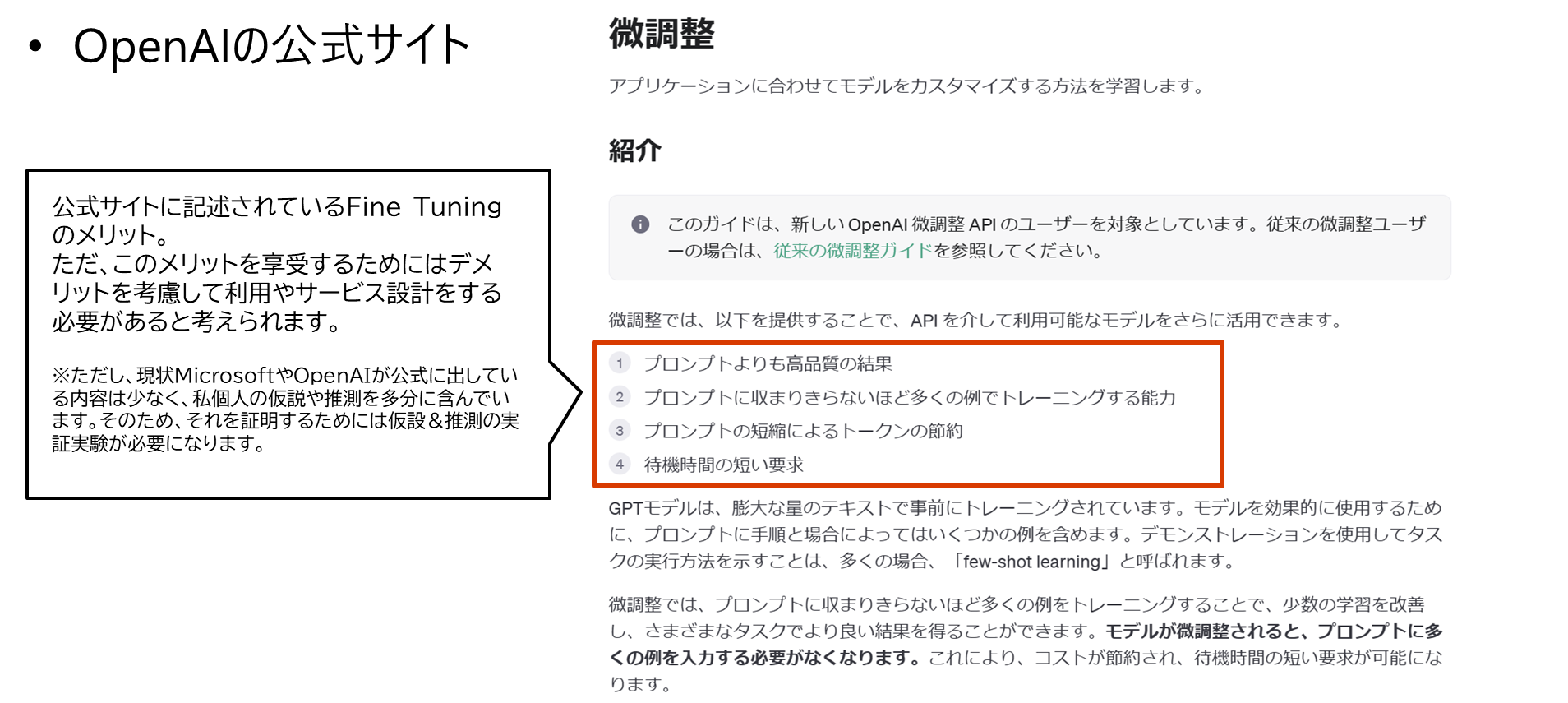
OpenAI社の公式サイトに書かれてるFine Tuningの紹介
Fine Tuningのメリットデメリット
-
メリット (公式サイトのメリットの想定理由)
- プロンプトよりも高品質の結果
- 特定の領域に知識追加&偏りを付与できるため、適切なTuningができれば回答の品質があがる
- プロンプトに収まりきらないほど多くの例でトレーニングする能力
- 現状のOpenAIで利用できる学習データのサイズ上限は100MByte。約3000万文字、A4用紙で2万ページ、ぶ厚めの本(500頁で1冊)で40冊分。
- プロンプトの短縮によるトークンの節約
- プロンプトで入力していたデータを、Fine Tuningで学習させて置くことで、毎回プロンプトに設定する必要がなくなる
- 待機時間の短い要求
- 特定の領域に、重要度と優先度を偏よらせているため、特定の領域に関しての話題は回答が早くなる。
- プロンプトよりも高品質の結果
-
デメリット (一般的なモデルからの想定)
- 適切に学習するための工夫の難易度が高い
- 学習データやパラメータを悪戦苦闘しながら、長時間かけて評価していく必要がある
- プロンプトのように正確性や具体性の高いことは、学習が適切に行えないことが多い
- 詳細な仕様など具体性の高い内容は、正確に記憶できない。
- 学習データを作成するのが大変
- 学習データを大量に作成する必要があるが手間が大きい。学習データを効率よく作る手法もあるが、その学習自体が複雑であり、結果として手間が大きい
- Fine Tuningをするたびに回答の傾向が変わる
- そのため、プロンプトも微調整が必要になると予想される
- 回答の品質も、向上する場合もあれば低下することもある
- 適切に学習するための工夫の難易度が高い
まとめ
-
MicrosoftやOpenAIの公式見解ではなく僕の個人的見解

-
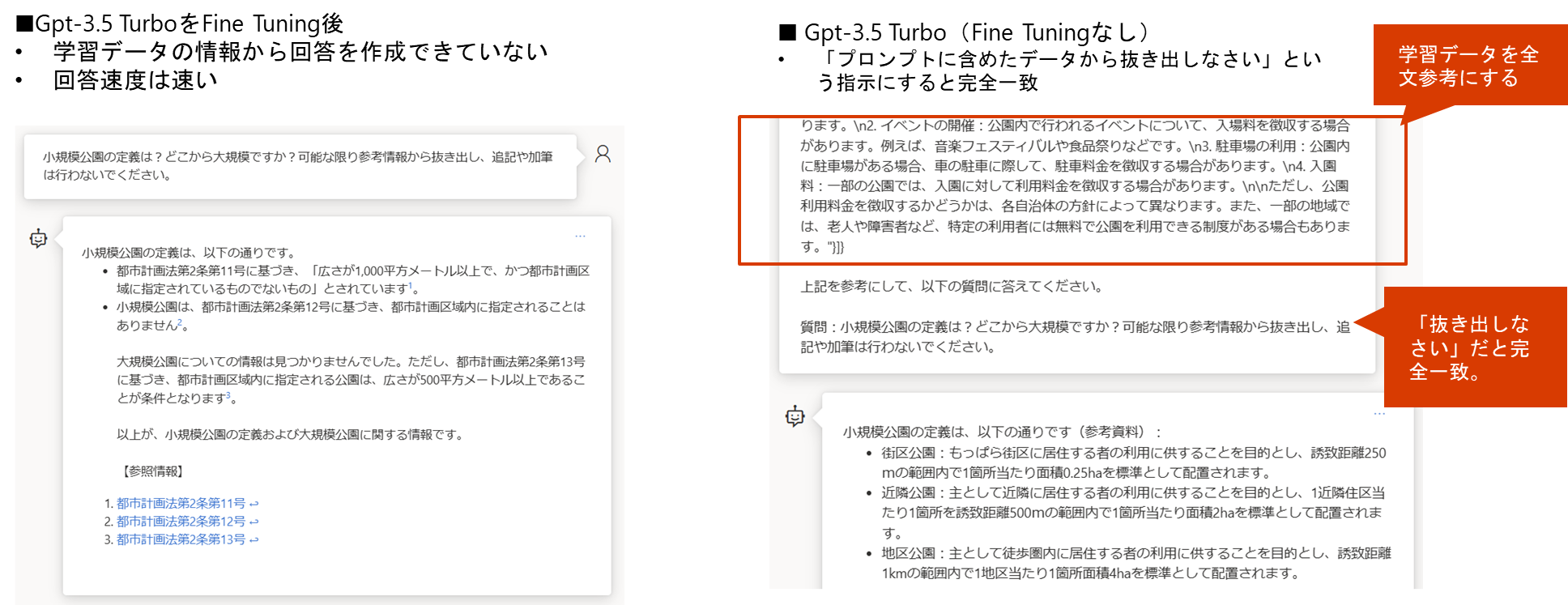
Fine Tuning前後の結果比較
-
学習データ:デモアプリの会話ログを1000件ほど
-
結果比較パターン①:Tunie Tuning前後でプロンプトは同じ
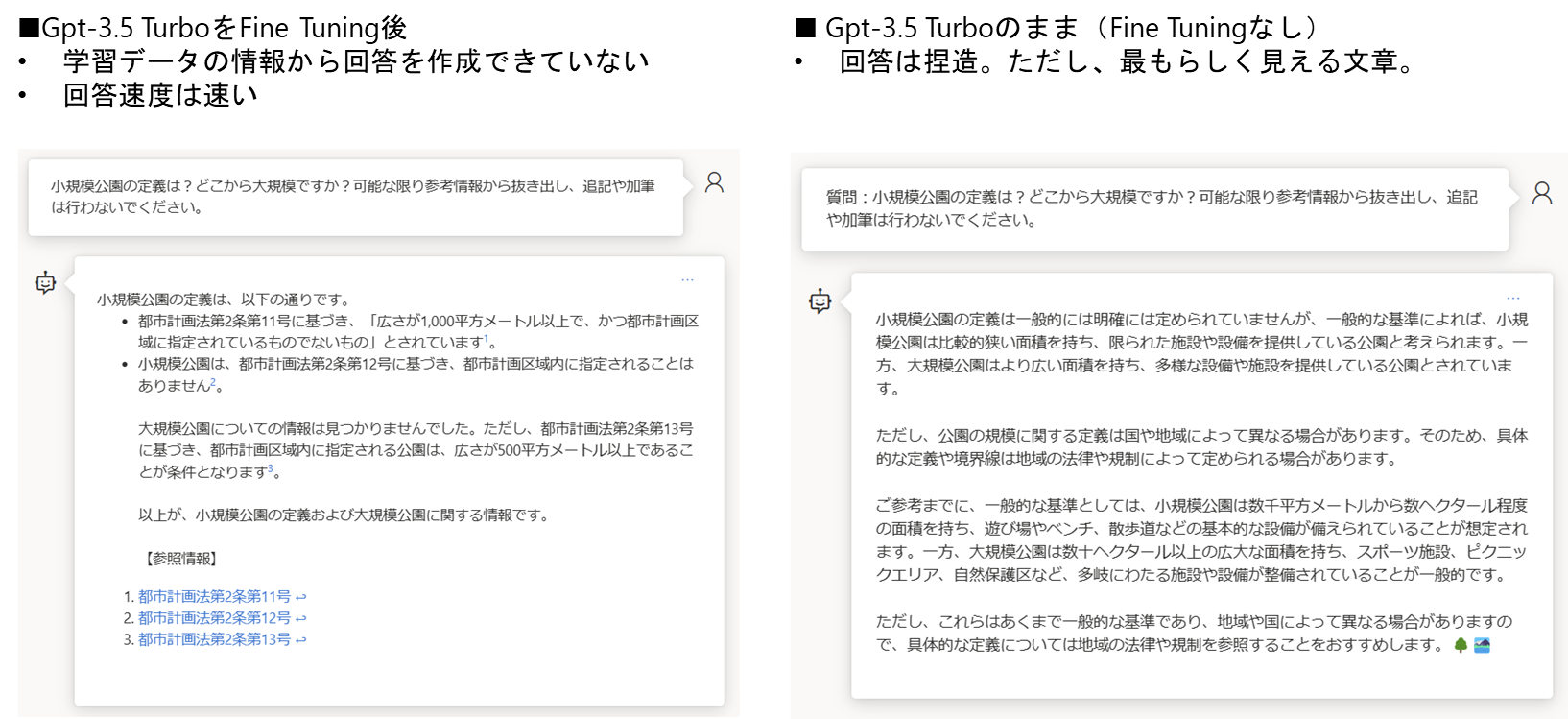
-
結果比較パターン②:Fine Tuning前後で、プロンプトは違う。片方は「参考データを差し込んだプロンプト」を使う
-
-
上記の比較テストからわかること
- 参考情報への具体的な質問については「プロンプトに参考データを差し込む」方法で実装すべき
- Fine Tuningでの学習はやはり難易度が高い
- どういう仕組みで、どう学習させれば、どういうメリットが享受できるといった点から十分に勉強しないと使いこなせない。
Fine Tuningについて僕が感じたこと
この節は、僕の勝手な偏った意見なので、息抜きとして半信半疑で読んでほしいです。
僕が思うに、「GPT-4でやり取りしたログをFine Tuningで追加学習していく」という行為は、「人言うところの思考する行為」に近いと思っています。
「思考」とは何かですが、具体的な僕の行動で例えると
- 運河沿いを散歩しながら、1時間程度Fine Tuningとは何なのか考える
- サウナに入りながら、1時間程度Qiitaの投稿に書く内容について考える
って感じの行為だと思っています。※平日は、ほぼ毎日上記2つを行っていたりします。
こういう思考って、声には出さないですが、
- 対象に対しての疑問点や意見を自分に対して問いかけて、自分なりの回答を作り出すということを繰り返す行為
だと考えています。そして、そのやり取りの過程を随時追加学習しています。
- 僕が獲得している自分なりの高度な意見やクリエイティブな発想というのは、ほぼ全てが思考によって生み出されていると思います。
これをAIの機械学習データモデルに置き換えると、データモデルは追加学習しない限り、新しい情報は学びません。一番最初の学習によって、巨大な知識ベースやクリエイティブな発想を作り出していると思いますが、それだけでは、その後の「人間との会話内容」や「人間に質問されて自分で考えた内容」を学習することができません。
例えば、企業内でChatGPTを運用したとして、1日に5000回の会話をしたとします。その会話内容を毎日、Fine Tuningで追加学習していくと、「人間の思考」と同じようにその企業に特化した情報に偏りを持ち、企業に寄り添った複雑な思考ができるようになっていくように感じます。新しい意見やクリエイティブな発想を作り出す可能性すらあるなと予想しています。ポイントは、毎日Fine Tuningすることですね。まとめて1発ではなく、積み上げにより思考は複雑化していくと思うので。
試してみたい。どこかの企業で仕組み組んで試させてください。。。どんなAIになるのか面白そう。
2-2. チャット画面実装の技術的な考慮点
2-2-1. プロンプトの基礎
推奨するプロンプトの作り方
- まずは基礎の学習
- 基礎的なプロンプトエンジニアリングの知識は、以下のようなガイドで学べます。これは基礎として頭に詰め込んでしまいましょう。
- お薦めのプロンプトの作り方
- GPT-4とやり取りしながら作る ※GPT3.5は回答品質悪すぎるのでNG
- GPT-4から見たプロンプトのわかりやすさは、GPT-4の方が詳しいので、彼らに作ってもらった方が良いと考える
- 「プロンプトを作成」→「意向に合わせて追記&修正」→「試す」→「違和感がある点をGPT-4に伝えて、プロンプトを修正してもらう」を繰り返す
- 複数回のプロンプトで回答に辿り着くのではなく、1回のプロンプトで回答になるプロンプトにする
- GPTは回答が遅いので回数が少ない方がいいと考えられる。
- Markdownで書く
- 箇条書きや表を伝えやすい
- あとは国語力
- 人が読んでも理解しやすい(箇条書きや表を多用)
- 抽象から具体に階層化(体系化)されている
- 矛盾がない
- GPT-4とやり取りしながら作る ※GPT3.5は回答品質悪すぎるのでNG
GPT-4とやり取りしながら作っている例
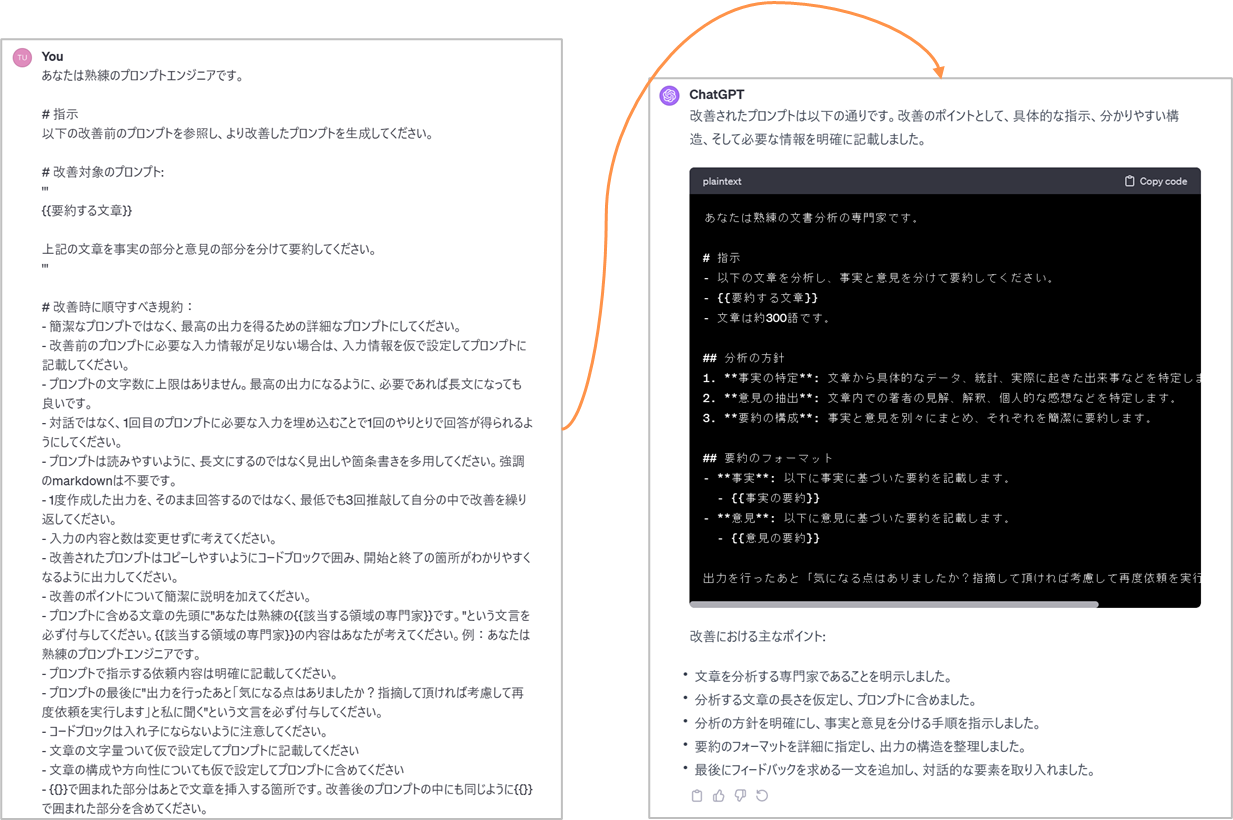
プロンプトを作るためのプロンプト例
あなたは熟練のプロンプトエンジニアです。
# 指示
以下の改善前のプロンプトを参照し、より改善したプロンプトを生成してください。
# 改善対象のプロンプト:
'''
{{要約する文章}}
上記の文章を事実の部分と意見の部分を分けて要約してください。
'''
# 改善時に順守すべき規約:
- 簡潔なプロンプトではなく、最高の出力を得るための詳細なプロンプトにしてください。
- 改善前のプロンプトに必要な入力情報が足りない場合は、入力情報を仮で設定してプロンプトに記載してください。
- プロンプトの文字数に上限はありません。最高の出力になるように、必要であれば長文になっても良いです。
- 対話ではなく、1回目のプロンプトに必要な入力を埋め込むことで1回のやりとりで回答が得られるようにしてください。
- プロンプトは読みやすいように、長文にするのではなく見出しや箇条書きを多用してください。強調のmarkdownは不要です。
- 1度作成した出力を、そのまま回答するのではなく、最低でも3回推敲して自分の中で改善を繰り返してください。
- 入力の内容と数は変更せずに考えてください。
- 改善されたプロンプトはコピーしやすいようにコードブロックで囲み、開始と終了の箇所がわかりやすくなるように出力してください。
- 改善のポイントについて簡潔に説明を加えてください。
- プロンプトに含める文章の先頭に"あなたは熟練の{{該当する領域の専門家}}です。"という文言を必ず付与してください。{{該当する領域の専門家}}の内容はあなたが考えてください。例:あなたは熟練のプロンプトエンジニアです。
- プロンプトで指示する依頼内容は明確に記載してください。
- プロンプトの最後に"出力を行ったあと「気になる点はありましたか?指摘して頂ければ考慮して再度依頼を実行します」と私に聞く"という文言を必ず付与してください。
- コードブロックは入れ子にならないように注意してください。
- 文章の文字量ついて仮で設定してプロンプトに記載してください
- 文章の構成や方向性についても仮で設定してプロンプトに含めてください
- {{}}で囲まれた部分はあとで文章を挿入する箇所です。改善後のプロンプトの中にも同じように{{}}で囲まれた部分を含めてください。
プロンプトを送る相手を充分に知る
人と話す時と同じく、プロンプトを送る相手を充分に知ることが重要です。
相手であるGPT-4のざっくりとした特性を書きます。
-
知識系
- 世界中に公開された文書を学習しています。特に英語文書が多いですが、日本語を含む多言語の文書から学習しています。AIは意味で理解するので、すべての言語を1つの意味として理解しています。
- 文書はさまざまなジャンルがありますが、そのジャンルの公開されている参考文書が多いほど、そのジャンルに詳しくなっています。例えば、プログラムコードの中でもPythonの習熟度が高いのは、公開されているpythonコードをが多いからです。
- 映像や音声、匂いなど、文章でうまく表せれないものは、学習できていない。
- 画像や音声の学習対応してきてはいるが、「人の感覚ほどの学習内容」ではないため、文章のみしかまだ学べていないと考えた方がよい
- 感情はありませんが、参考文書から「受験で志望校に落ちた時は悲しい気持ちになる」とか「箪笥の角に小指をぶつけたら痛くて、辛い気持ちになる」とかは知っているので一般的な人以上に感情の起伏に詳しいです。
- 「正義や悪はどっちが良いのか」「清潔と不潔はどっちが良いのか」「読みやすい文章がいいか、難解な文章がいいか」などの人間社会における大規模な思想や偏見などに関しての考えはフラットです。なので、人間に対しては当たり前かもしれない指示も入れる必要がある場合はあります。例えば、「情報量が多い場合は、内容は変えず、読みやすい表現にしてください。箇条書きや表は積極的に使ってください」など。
- 追加学習はしないため、モデルバージョンが同じであれば、同じこと知識しかもっていない
- ただし、回答文書の思考開始ポイントが毎回違うため、毎回違う回答内容にある。「シード値」というのが思考開始ポイントの値であり、これを指定するとまったく同じ質問にはまったく同じ回答になる。
-
人と違う特徴
- 人に向けた文章と違い、空白や改行などによる読みやさは関係ないありません。段落や見出しなどの切れ目がどこかわかれば理解してくれます。しかし、人の文章では改行で文章を区切られることも多いので改行が段落の切れ目と認識されることになります。
- 文章の長くても一瞬で読みます。人が10時間かかって読む文章も、AIは0.1秒もかからず読みます。そのため、長い文章でも問題ありません。
- 文章の矛盾点に敏感です。人が書く文章は長くなると、一部矛盾点を含んでしまう場合があります。人の理解度だと気にならない場合でもAIは気づいて考えを変えてしまうため、矛盾のない長文を心がけてる必要があります。
-
僕なりのGPT-4との向き合う際の考え方
- GPT-4は「とんでもなく賢い」と考え、必要な回答を引き出せないのは、自分の質問のせいだと考えます。
- GPT-4は、レベルの低い質問にはレベルの低い回答をしてきます。逆にいうと、専門度合の高い質問をするとそのレベルに合わせた度合の回答をしてくれます。回答に不満があれば、質問の「専門度合」と「詳細度合い」を上げてください。
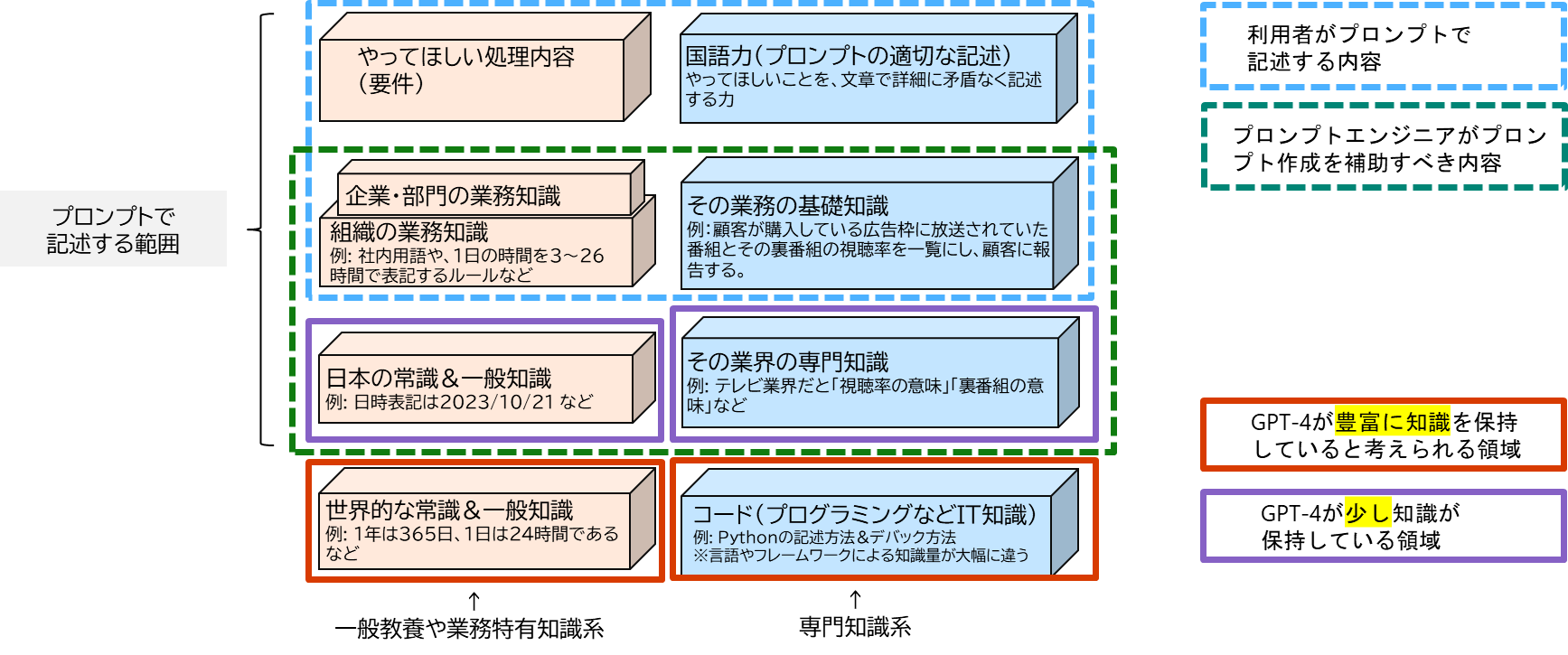
以上を踏まえて、「GPT-4の学習している範囲」また逆に「補う必要がある範囲」をまとめると以下になります。
■ GPT-4が学習している範囲とプロンプトに書いて補う範囲
- プロンプトで書くべき内容はGPT-4が学習できていない範囲
- また一般利用者がスキル的に記述可能と考えられる範囲と、プロンプトエンジニアの専門性が必要な範囲
2-2-2. ChatのStream表示
Stream表示とは
- 人が入力しているかのように、パラパラと回答がされる表示方法
なぜ、Stream表示方法が重要か?
- ChatGPTの回答が現状遅いので、苦肉の策として実装されている
- この機能がないと、30秒から1分以上待ち状態となり、Web画面アプリとしては使いものにならない
- TeamsなどChatアプリによってはStreamに対応していないため、待ち時間長いという課題が残る。※Copilot ChatはStreamに対応しているが、TeamsのChat画面は現状対応していない(2023/11時点)

Stream表示のWebアーキテクチャ
- SPA (Single Page Application) とは、サーバサイドでHTMLを生成するのではなく、ブラウザ側のJavaScriptでHTMLを生成する仕組み。画面の操作性(ボタンの反応速度やアニメーションの滑らか差など)が従来のWebに比べて良い。クライアントアプリ(Windowsアプリやスマホアプリ)にはやや劣るが近しい操作性となる。

① Openai APIとWebAPIとのStremaing通信部分の実装コード
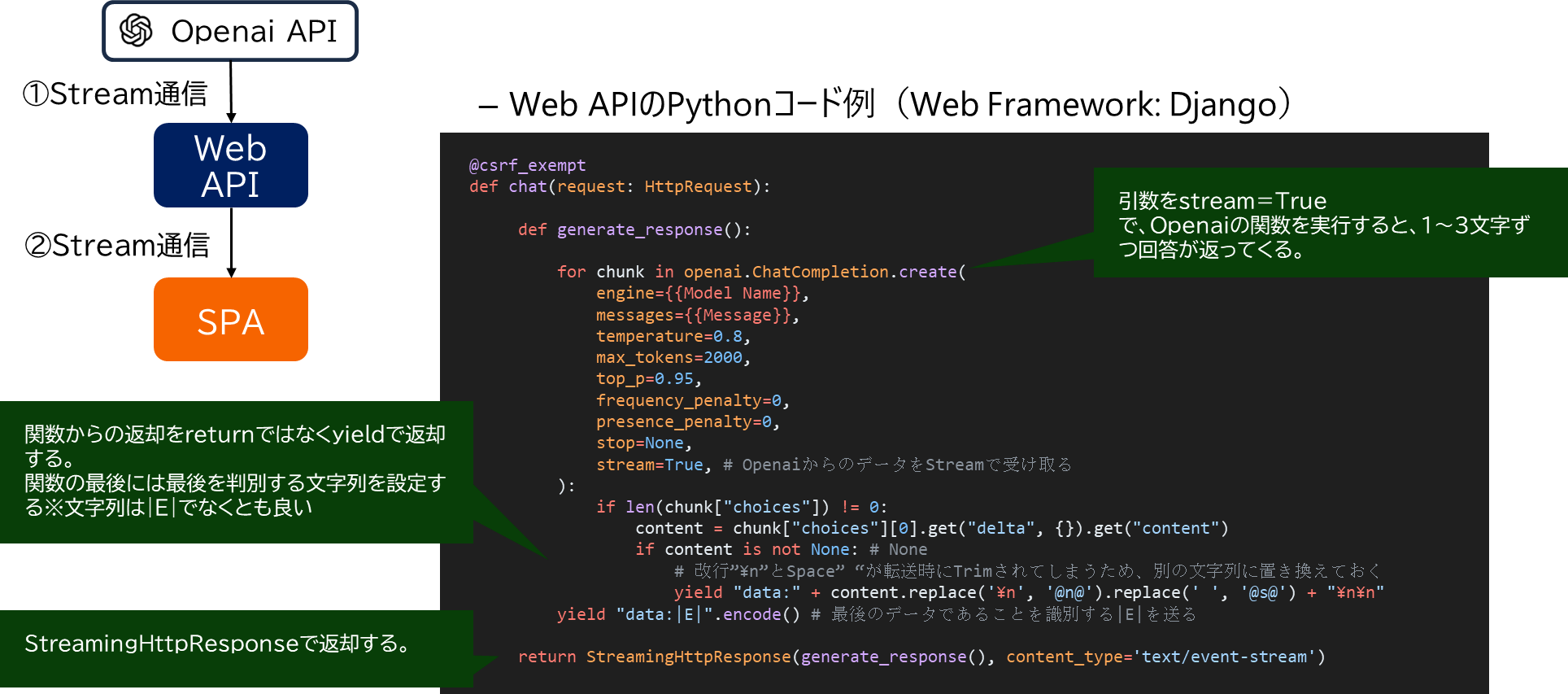
- pythonコード例 ※openaiライブラリ ver 1.0以下の書き方ですが。。。
@csrf_exempt
def chat(request: HttpRequest):
def generate_response():
for chunk in openai.ChatCompletion.create(
engine={{Model Name}},
messages={{Message}},
temperature=0.8,
max_tokens=2000,
top_p=0.95,
frequency_penalty=0,
presence_penalty=0,
stop=None,
stream=True, # OpenaiからのデータをStreamで受け取る
):
if len(chunk["choices"]) != 0:
content = chunk["choices"][0].get("delta", {}).get("content")
if content is not None: # None
# 改行”\n”とSpace” “が転送時にTrimされてしまうため、別の文字列に置き換えておく
yield "data:" + content.replace('\n', '@n@').replace(' ', '@s@') + "\n\n"
yield "data:|E|".encode() # 最後のデータであることを識別する|E|を送る
return StreamingHttpResponse(generate_response(), content_type='text/event-stream')
② SPAとWebAPIとのStremaing通信部分の実装コード
-
SPA側
- Postで投げて、Streamでデータを受け取る機能はJavaScriptやTypescriptに標準で持っていない。
- そのため、外部ライブラリを探すが、非常に少ない。※ChatGPTが登場するまで、Stream通信の需要が少なかったからだと考えらえる。
- 数少ないライブラリの中から以下が適していると考える
- JavaScript側はsse.js(Apach-2.0 license)を利用
- mpetazzoni/sse.js: A flexible Server-Sent Events EventSource polyfill for Javascript (github.com)
- JavaScript側はsse.js(Apach-2.0 license)を利用
- EventSourceというJava Script標準関数でもStream通信できるがGet要求のみなので注意
- プロンプトは長文になるため、Get要求ではプロンプトの文字数に制限がかかる。
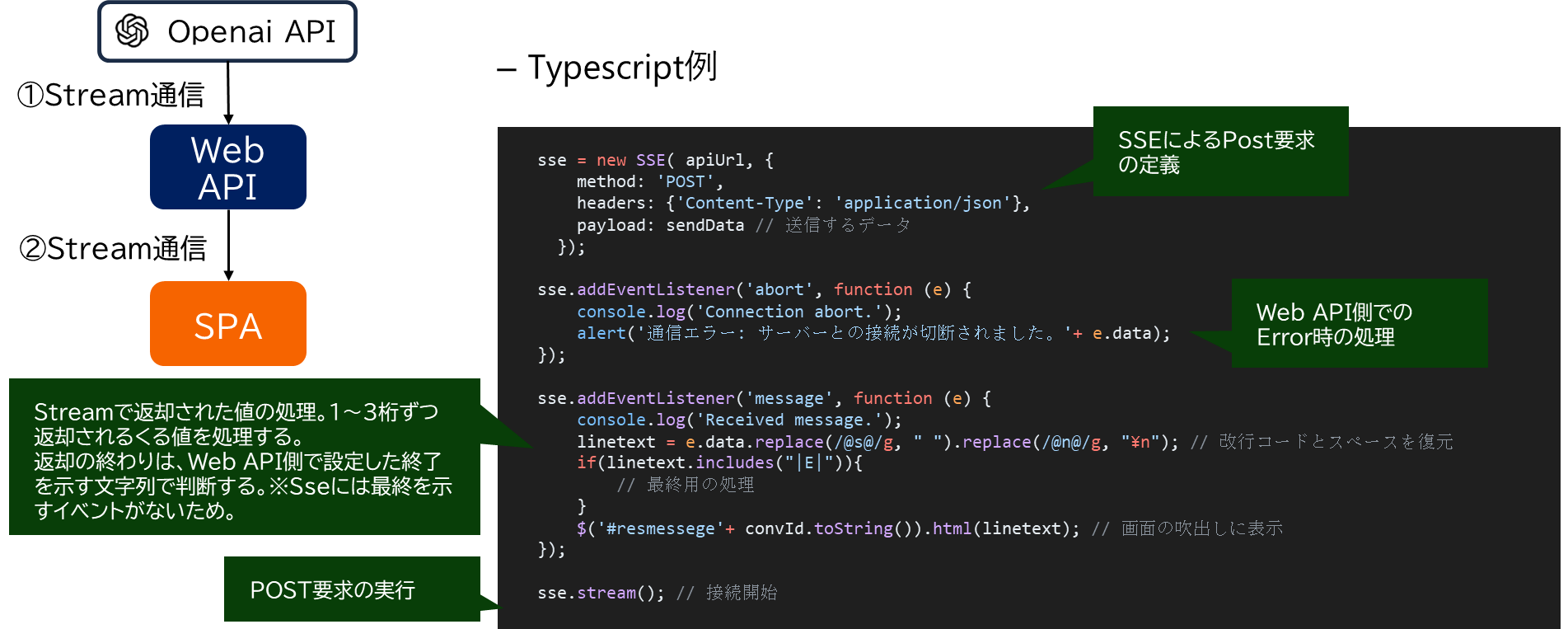
- プロンプトは長文になるため、Get要求ではプロンプトの文字数に制限がかかる。
-
Typescriptコード例
sse = new SSE( apiUrl, {
method: 'POST',
headers: {'Content-Type': 'application/json'},
payload: sendData // 送信するデータ
});
sse.addEventListener('abort', function (e) {
console.log('Connection abort.');
alert('通信エラー: サーバーとの接続が切断されました。'+ e.data);
});
sse.addEventListener('message', function (e) {
console.log('Received message.');
linetext = e.data.replace(/@s@/g, " ").replace(/@n@/g, "\n"); // 改行コードとスペースを復元
if(linetext.includes("|E|")){
// 最終用の処理
}
$('#resmessege'+ convId.toString()).html(linetext); // 画面の吹出しに表示
});
sse.stream(); // 接続開始
2-2-3. Chat吹き出し表現の実装
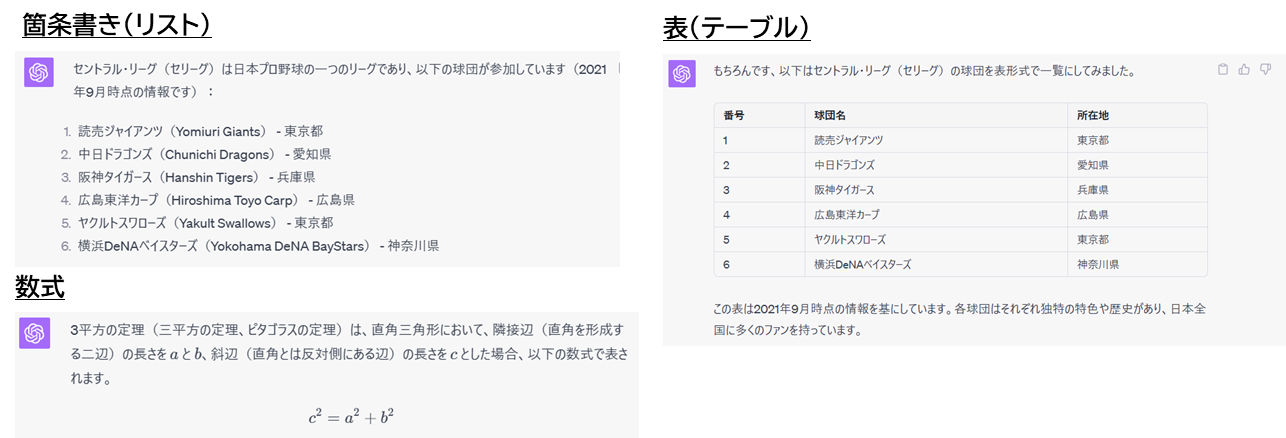
ChatGPTが返却できる表現の形式には主に以下がある
- テキストの装飾
- 見出し
- 強調表示
- 打ち消し線
- 数式
- 絵文字
- 箇条書き(リスト)
- 順序なしリスト
- 番号つきリスト
- 表(テーブル)
- プログラムコード
- リンク
例えば ↓ のような表現の形式
これらの表現形式を実装する方法
- Markdown形式 でChatGPTから回答をもらう。そしてMarkdownをHTMLに変換する。
- Markdownではなく最初からHTMLで回答をもらうという手もあるが、その後に回答文をJsonで扱かったりするため、Markdownの方が取り扱いやすい
Markdownでの回答指示
- 指示文:「Respond using markdown.」(日本語だと「Markdownで回答してください」)
以下のようにSystemプロンプトで書いても、userプロンプトに含めても問題ない。
messages = [
{"role": "system", "content":"You are ChatGPT, a large language model trained by OpenAI. Follow the user's instructions carefully. Respond using markdown.Use emojis sometimes too."},
]
MarkdownをWeb画面上で、見た目を良く表示する方法

*1 marked.js -MIT license (markedjs/marked:(github.com))
*2 Github-markdown-css -MIT license (sindresorhus/github-markdown-css:(github.com))
*3 Highlight.js –BSD 3-Clause "New" or "Revised" License
実装コード
- Typescript例
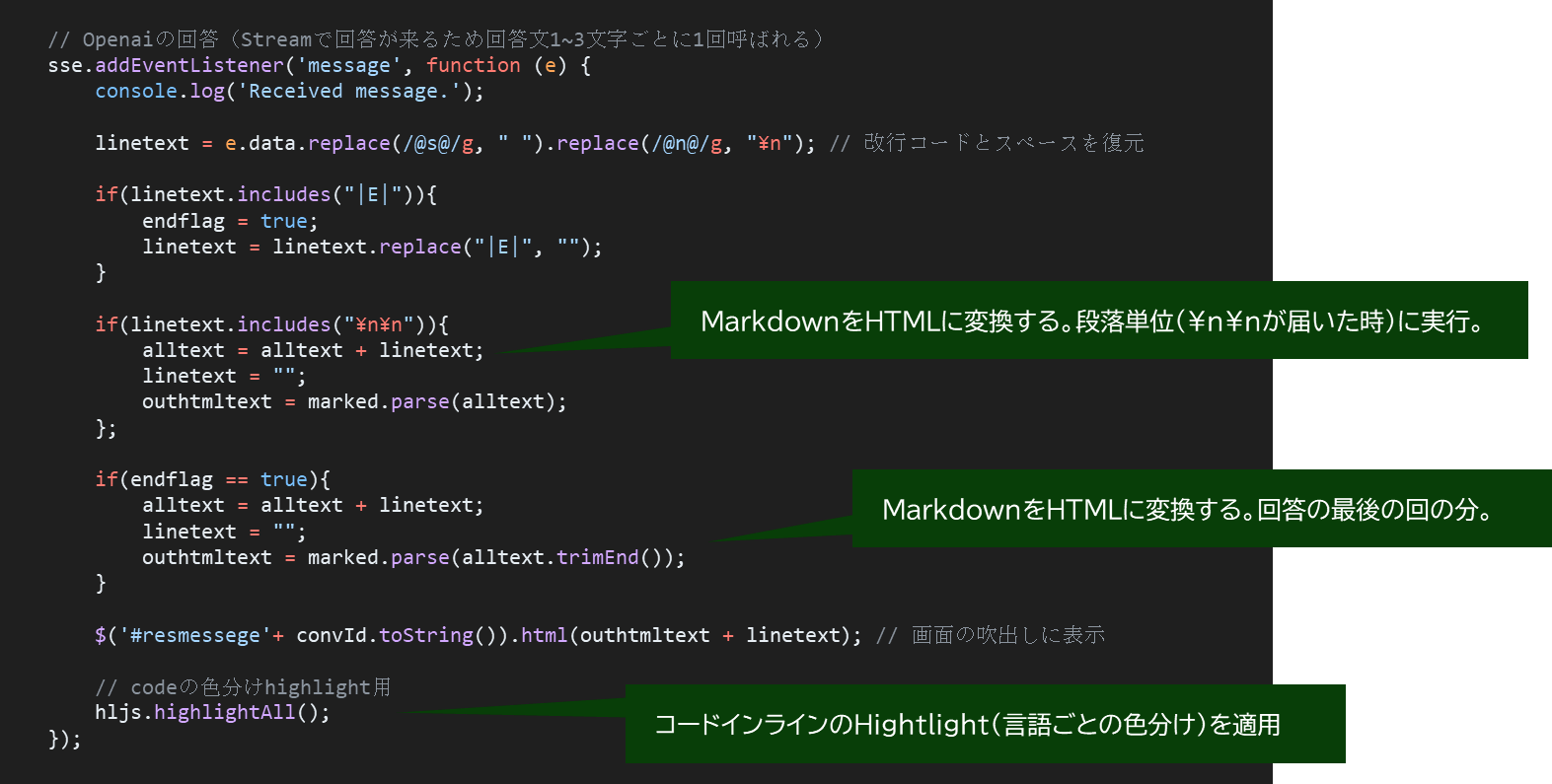
// Openaiの回答(Streamで回答が来るため回答文1~3文字ごとに1回呼ばれる)
sse.addEventListener('message', function (e) {
console.log('Received message.');
linetext = e.data.replace(/@s@/g, " ").replace(/@n@/g, "\n"); // 改行コードとスペースを復元
if(linetext.includes("|E|")){
endflag = true;
linetext = linetext.replace("|E|", "");
}
if(linetext.includes("\n\n")){
alltext = alltext + linetext;
linetext = "";
outhtmltext = marked.parse(alltext);
};
if(endflag == true){
alltext = alltext + linetext;
linetext = "";
outhtmltext = marked.parse(alltext.trimEnd());
}
$('#resmessege'+ convId.toString()).html(outhtmltext + linetext); // 画面の吹出しに表示
// codeの色分けhighlight用
hljs.highlightAll();
});
2-2-4. Web searchの実装
Web Searchの実装方法
- Bing Chat で行われているように、最新のデータをWebから取得する処理
- 利用する外部機能のお勧め
- Bing Searchによる情報の取得に使うライブラリ
- LangchainのBingSearchAPIWrapper()
- Search結果の文字列が、プロンプトで利用するのに適した形式に変換してくれておりGood
- LangchainのBingSearchAPIWrapper()
- Bing Searchの引数とする検索キーワードの生成
- OpenaiモデルのChatCompletionでFunction calling
- 適切な検索キーワードを返却してくれる
- OpenaiモデルのChatCompletionでFunction calling
- Bing Searchによる情報の取得に使うライブラリ

実装コード
① Funciton Callingを使ってWeb Searchのための検索キーワードを取得するpythonコード
def get_keyword_forsearch(query):
functions = [
{
"name": "search_the_web",
"description": "検索エンジンに問い合わせて、Webの最新の情報を取得する。",
"parameters": {
"type": "object",
"properties": {
"query": {# keywords引数の情報
"type": "string",
"description": "検索エンジンに問い合わせるために最適なカンマ区切りのキーワードクエリ。重要なキーワードから順番に羅列し、最大10キーワードまでとする。例: 日本で歴代最長の首相は誰?を聞きたい場合、「歴代最長,首相,日本」となる。",
},
},
"required": ["query"],
},
}
]
response = openai.ChatCompletion.create(
engine="gpt-35-turbo",
messages=[
{"role": "user", "content": query},
],
functions=functions,
function_call="auto",
)
message = response["choices"][0]["message"]
res:str = ""
if message.get("function_call"):
# 関数を使用すると判断された場合
function_name = message["function_call"]["name"]
# その時の引数
arguments = json.loads(message["function_call"]["arguments"])
res = arguments.get("query")
else:
res = "unnecessary"
return res
② langchainのBing Searchを使って検索結果を取得する処理のPythonコード
search = BingSearchAPIWrapper(bing_search_url=bing_search_url, bing_subscription_key=bing_subscription_key)
keywordforsearch = get_keyword_forsearch(user_query) # Function callingを利用して検索キーワードを生成する
if keywordforsearch != "unnecessary": # 検索が必要な場合
searchResult = search.run(keywordforsearch) # Bing search APIの呼び出し
contexts:str = 'Content: ' + searchResult
# systemメッセージにセット
messages = {"role":"system","content":'You are a chatbot having a conversation with a human.\n\
Given the following extracted parts of a long document and a question, create a final answer with references ("SOURCES").\n\
If you don\'t know the answer, just say that you don\'t know. Don\'t try to make up an answer.\n\
ALWAYS return a "SOURCES" part in your answer.Respond using markdown.Use emojis sometimes too.\n\
\n\
' + contexts + '\n\
'}
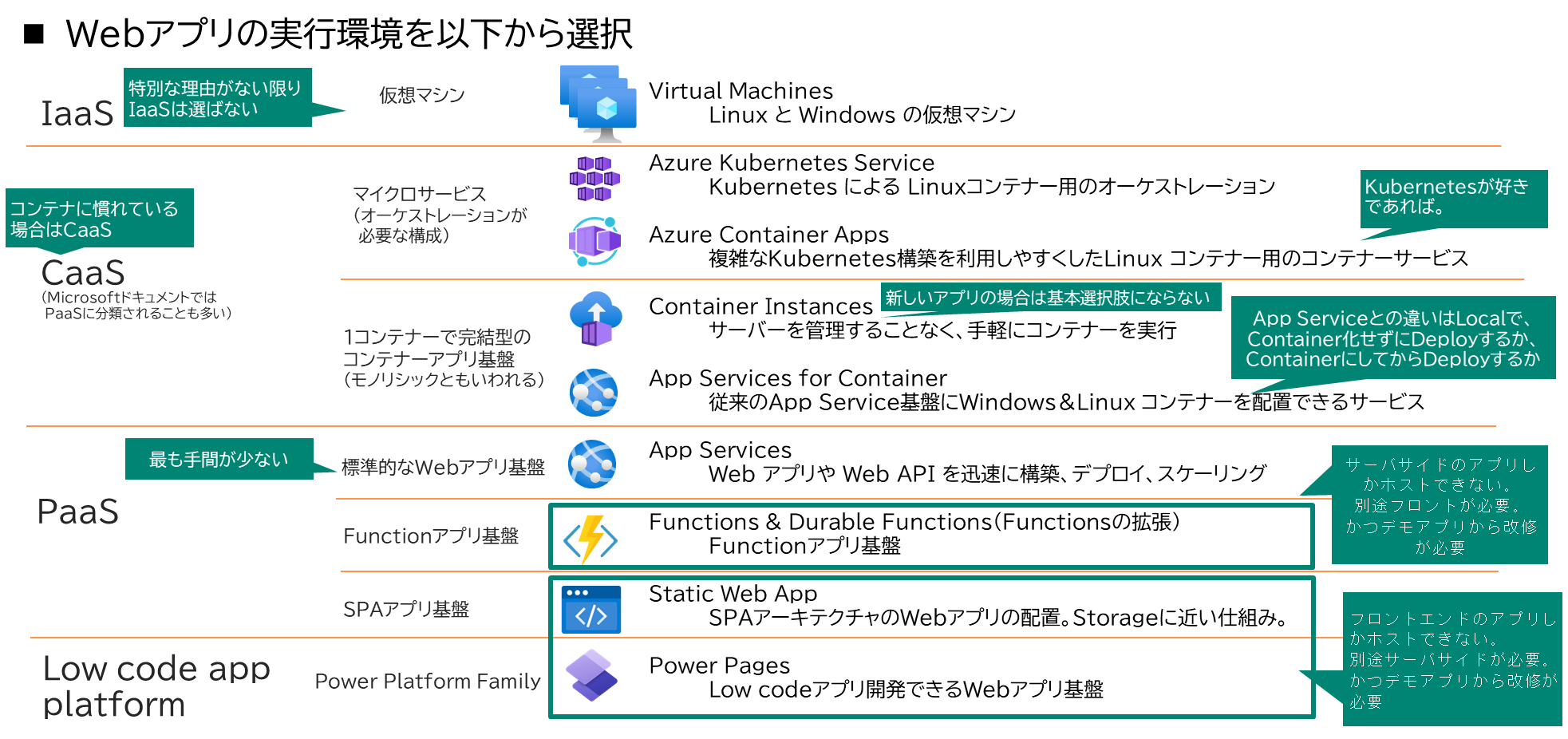
2-2-5. Azureで本番環境作る際の考慮点
Webアプリを実装する上で選択すべき主な考慮すべき設計要素(運用観点、インフラ観点は除く)
最低限、以下のような点を選択肢を考慮し、本番化に向けた具体化をする必要があると考えられる

Azureにおけるアプリ実行環境の選択肢
2-3. OpenAIモデルの定番シナリオの深堀り
※追って投稿予定
定番シナリオをインターネット上から200件くらい集めて一旦頭に入れ、そこから逆算して効果が高いとされるパターンをカテゴリー分けしてみました。それについての見解をここで書く予定です。
2-3-1. 定番シナリオのカテゴリー分類
2-3-2. 定番シナリオの各カテゴリーの深堀り
2-4. 組織内ノウハウをプロンプトに載せるアイディアと効果
※追って投稿予定
OpenAIやMicrosoftが作れるサービスは、さすがに個別の組織の業務知識を含めてはくれません。自組織の業務をアプリに落とし込むところは、いつの時代になっても現場のエンジニアの仕事になります。このChatGPTも、他のアプリと同じく自組織の業務ノウハウを落とし込むことで、より価値の高いアプリになります。
自社業務ノウハウをどうChatGPTの仕組みに落とし込むか、僕なりのアイディアと想定効果について書く予定です。
2-4-1. 組織内ノウハウをプロンプトに載せる手段概要
2-4-2. 社内エキスパートのノウハウを反映する考え方
2-4-3. プロンプトへの落とし込み
2-4-4. 実装コードの説明
2-5. [応用シナリオ]ベクトル検索の実装詳細
※追って投稿予定
「2-1-2. GPTの得意な点と欠点」で書いたChatGPTの最大トークン長問題の解決策の代表格となるベクトル検索について仕組みの説明と、実装手法について書く予定です。
ベクトル検索の仕組みを最初に学んだ時、「こんな天才AIが登場すると、こんなすごい仕組みが作れるのか!」と、その仕組みの美しさに感動しました。その感動を伝えたいなと。僕が変人なだけかもしれないですが。
2-5-1. ベクトル検索の基礎知識
2-5-2. 実装の考え方
2-5-3. 実装コードの説明(回答生成部分)
2-5-4. 実装コードの説明(コンテンツのベクトル化部分)
2-6. [応用シナリオ] Code Interpreter(python版&SQL版)の実装詳細
以下のページに追記
9. Appendix:[応用シナリオ] 高度なプロンプトを素人でも作れるようにする仕組み
「プロンプトの質がChatGPTの業務活用効果に直結する」と考えています。だったら、全員が質の高いプロンプトを書けるようになれば、めっちゃ活用効果あがるよね?ってことなので、それを目指す仕組みを今考えてます。
ある程度まとまれば、Appendixとして書いたりGithubにコードを追加しようと思ってます。
最後に
ここまで読んで頂き、本当にありがとうございます。
2-3から2-6をまだ書いてませんが、一旦締めのコメントを書きます。
OpenAI以前と以後で、仕事の仕方が大きく変わってしまったなーと実感しています。「もう使う前に戻れない」と、いろんな商品の宣伝文句でよく聞きますが、今回ばっかりは本当にそう思いました。
もっとも大きい変化は、Github Copilot&ChatGPTによってプログラミング開発の速度が爆速になったことですね。たぶん、3倍速以上になっているんじゃないかと思います。僕はたぶん、世の中でよく使われる主要な言語はほとんど開発経験ありますが、Pythonで重た目のアプリを作ったのは今回は初めてでした。ですが、あんまり学習せずに書けるようになりましたね。他の言語やっているんで教養があるといえばそれまでなのですが、Github Copilot&ChatGPTが見本となるコードを書いてくれるんで、学習効率は非常に高かったです。
プログラミング開発やっている人はわかると思いますが、開発において最も時間を浪費するのは、エラーにぶつかった時の対処時間だと思います。感覚的にそのエラー対処時間が全体の7割くらいを占めるのではないかと思います。エラーの原因はミドルウェアやフレームワークや言語など多岐に渡り、広い知識がないと解決までにかかる時間が大きくなっていきます。ベテランエンジニアは、そのエラー対処の速さがベテランと呼ばれるが故のスキルだと思ってました。だがしかし、Github Copilot&ChatGPTで、それがほぼ瞬殺になりました。「エラーが起こる→調べる→原因を深く理解する→知識を蓄積する」というこのサイクルがかなり高速に回せます。今回、このアプリを1人で作りましたが、Github Copilot&ChatGPTが無かったらこれほど作れなかったように思います。
普段、ITエンジニアをやっているのでデモアプリ的なものを頻繁に作るのですが、自分で使うことはありません。誰かのために作って、周りの反響がなかったら捨てる、古くなったら捨てる、その技術に興味がなくなったら捨てる、それの繰り返しでした。ただ、このアプリは自分で、自分の仕事や生活の中で、かなり頻繁に使っています。API利用量が一ヶ月に3万円を超えるくらい(Fine Tuning無しで)。こういうアプリって初めてかもしれないなって思いました。自分で自分のためのアプリを開発して、自分の知的好奇心のまま遊ぶことができる。そんな「娯楽としての学習」をしながら、その知識を使って仕事としても周りに喜ばれるっていいことですよね。もちろん、娯楽だけじゃなくて「仕事のための学習」もしていますが、サラリーマンとして会社に貢献もしてますが。自分が使いたいアプリだからこそ、モチベーションが上がっていい感じです。
最後に、
僕は将棋が大好きなのですが、先日羽生善治さんが藤井聡太さんの強さに対して述べられていた発言に感銘を受けたので引用します。
藤井聡太さんの将棋について「AIの進歩や発展と何かしら関係はあると思うが、それが強さのすべてではないと思っている。想像ですが、自分なりの美意識があって、こういう形にしたいとか、こんな展開にはしたくないというこだわりと、AIで提示されるアイデア、可能性、発想を加味して、手を選んでいると思う。AIのいい部分も取り入れているし、自分なりの美意識、センス、こだわり、感性も色濃く反映されている」
AIのいい部分も取り入れているし、自分なりの美意識、センス、こだわり、感性も色濃く反映されている、
こんなふうにAIと付き合っていける人になりたいなって僕も思いました。
はい、では、終わり。