はじめに
昨年、惨敗を喫した、自前データに基づく文書分類器の作成にリベンジすることにした。昨年の敗因は、そもそものデータがよくなかった、と判断し、今年は、データを変えてみた。分類ラベル(目的変数)は昨年の13に対し、14と個数が変わった程度。変わったのは説明変数に当たるデータで、これを思いっきり長文を選択してみた。
参考サイト
毎度のことだが、巨人の肩に乗りまくり。ワタシの考えるようなことはすでに先人がその道を切り開いているはず。しかしコードはコピペでもデータはオリジナルだ。そして得られる体験と結果もワタシのものだ。(←誰に対して)
この投稿のみどころ
Transformersのデータ処理の解説は、上記先達に任せる所。この投稿では、上記先達の処理に合わせるための、自前データの前処理の説明を中心に行う。えてして世間の機械学習の説明サイトは、「既存サンプルデータを使って」説明することがおおいので、自前データでどうやって学習させるのか、と悩む人たちの参考になれば幸い。
自前データを前処理までもっていこうじゃないか
参考サイトを読むと、Datasetでなにかのサンプルをダウンロードしているようだ。要は、この部分をどうにかすれば、オリジナルデータの分類器ができるだろ?というところから作業は始まった。
まずはファイルを読み込む
元のデータはMongoDBに入っている。Compassでアクセスして、フィルタをかけてCSVかJSONをダウンロードすればファイルは作られる。世の中の多くのサンプル記事はCSVをPythonで読み込む作業のものが多いが、過去の経験から私はCSVファイルの読み込みを(特に長文データの含まれるフィールドが存在するものを)信じない。カンマが文章の中に存在していたら?と心配になるのだ。よって、データファイルはJSONの一択。そして読み込みはPandasで、データフレームにしてしまう。1.2GBのファイルを10秒程度で読み込んでしまう。ありがたや、この安心感。
import pandas as pd
df = pd.read_json(ファイル名)

読み込んだデータを整形する(まずは目的変数と説明変数をはっきりさせようじゃないか)
読み込んだデータを見て気づいた。目的変数にしようと思っていたデータが、リスト型になってる! MongoDBの中で配列で保存されていたんだな。一応、DBを確認してみると、配列で保存されているけれども含まれている要素は単数。まぁ、将来の拡張性をもたせるための設計だな。・・・というところも踏まえて、この目的変数を文字列オブジェクトに変える。pandasの中のリストからデータを抽出する方法についての勉強になった。
df['label'] = df['main_category_en'].apply(lambda x: ','.join(x))
df['text'] = df['description_en'].copy()
df = df.drop('main_category_en', axis=1)
df = df.drop('description_en', axis=1)
df
私にとって、pandas を使うときは、「データは列で並んでる」と考えると扱い方がわかりやすいのかもしれない。'main_category_en'列を持ってきて、apply で全フィールドに同じ処理をしてやるぞ、とかいちいち整理しながらコードを書いている。いまどきは、ChatGPTに聞けばコードを書いてくれるらしいが、ChatGPTにデータを渡してデータの変形を指示するプロンプトを書くにあたりデータの書式を説明しなければならなかったりしたら面倒だな、と思ってやっていない。地道にググって自分で考えて作り出したコードが上記だ。恥ずかしながらこのコード数行を作るのにざっと6時間ほど悪戦苦闘した。

さらに・・・あとで、Transformersに怒られることになるのだが、ラベル文字列には、"/"や">"など、特にシェルコマンドで使われそうな文字列は使わないほうがいいそうだ。そこで全体を法則性を持って置き換えることにする。
df['label'] = df['label'].str.translate(str.maketrans({"/":"-", " ":"_"}))
df
これも4時間ほどググって調べて自分で考えて作り出した(笑 。pandas データフレーム の列を選択すると、これはSeries型になる。Siries型の要素がオブジェクト型になっているのを、.str をつけて文字列型として扱う。そこでさらに .translate()を使うことで、変換処理を行うこととし、その変換処理は、 str.maketrans() である、と。やっとこさ具体的な変換の対応を記述することになり、dict型で、"/"を"-"に、" "を"_"にすると記述できた。このdict型に複数書いて同時に変換できるらしいが、再帰的な処理は行わないらしいので重複しないように記述するべし。
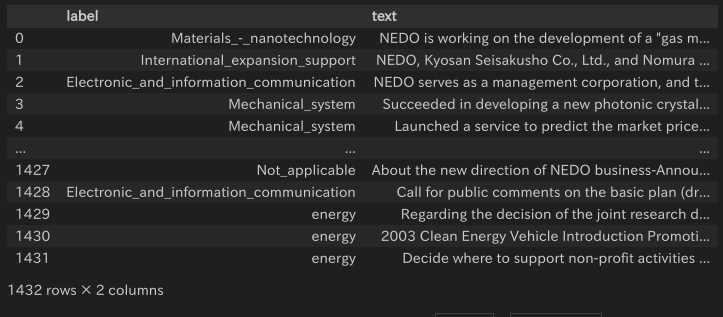
よーし、データの質でも見てやるか。まずは、ラベルごとにグループに分けて何件ずつあるのか見てみよう。
grouped = df.groupby('label')
grouped.size()
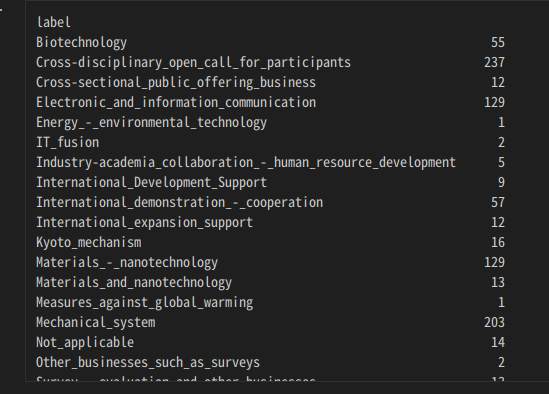
む?1件、2件しかないグループがあるな。こんなん、訓練データかテストデータのどちらかにしか入らなかったりしたらただのおじゃま虫じゃん。今回、こういうデータは「結果として分類できないもの」として扱うこととして、本件取り扱いから除外してしまうことにする。11件以上データがあるものだけを扱うよう、データを整形したい。
・・・ここでも苦戦した。このgroupby でグループ化されたデータの取り扱い方がわからん。ググっても直球の答えがみつからない。試行錯誤して気づいたのだが、groupbyされたデータをforループで回してひとつずつとりだしてtype()をみてみると、タプルになっていることがわかった。
exclude_list = []
for g in grouped:
# print(g[0])
if len(g[1]) < 10:
exclude_list.append(g[0])
exclude_list
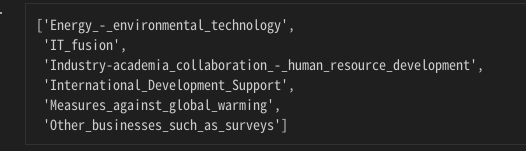
g[0]がラベル文字列、g[1]がそのグループ要素数になっていた。このことがわかるまで、また4時間かかった。これで削除対象にしたいラベルのリストができたので、これを使ってデータフレームから、不要データを削除すればいいや・・・。
ところで。
昨年、データを処理するときに、目的変数(ラベルデータ)を数字に変えていた。アルファベット順に並べて、整数を順に割り当てるという処理を、scikit learn の関数がやってくれたような記憶がある。しかし、どうしても数字で書いていいのか、と気になっていた。これも勉強しておいた。こういうときは、「OneHotBector」というデータ形式を使うのが適切な場合が多いらしい(そういえば、そう習ったな、昔・・・忘れてた)。
こういった記事を参考に自分なりにやってみたのだが・・・今回の場合は、たまたまpandasのget_dummies関数で処理したら理想のデータ形式を作ることができたので、そちらの方を紹介。pd.get_dummies()関数に、ラベル列を指定すると、列見出し(column_index)に、ラベル文字列、そのラベル文字列を目的変数に持てばその行は True、持たなければFalseになるデータフレームを出力してくれる。
df3 = pd.get_dummies(df['label'])
df3['text'] = df['text']
df3
さて、このデータフレームについて、さっきの除外ラベルリストで対応した行データ削除処理をすればよいわけだ。
for el in exclude_list:
target = df3.index[df3[el] == True]
df3.drop(target, inplace=True)
df3.drop(el, axis=1, inplace=True)
df3.reset_index(drop=True)
まず、get_dummies で作られたデータ列のフィールドがTrueになっているデータフレームのインデックスを取り出してtargetリストを作り、それをdropの引数に入れて、inplace=Trueを指定して実行すると、データフレームの中で削除処理が行われる。そして、そのラベル列を削除する・・・という処理を、除外ラベルリストデータの数だけ繰り返す。
そしてメタメタに削除が行われたデータフレームのインデックスをリセットして、使わないインデックスをdropさせればいい感じのデータフレームに生まれ変わるってわけだ。
整形したデータフレームを、Transformersのデータセットに
データフレームを学習データ、バリデーションデータ、テストデータに振り分けよう。
from sklearn.model_selection import train_test_split
trates_df, valid_df = train_test_split(df3)
rain_df, test_df = train_test_split(trates_df, test_size=0.1)
次にこれをデータセットにセット・・・
from datasets import Dataset
train_dataset = Dataset.from_pandas(train_df.reset_index(drop=True))
validation_dataset = Dataset.from_pandas(valid_df.reset_index(drop=True))
test_dataset = Dataset.from_pandas(test_df.reset_index(drop=True))
from datasets import DatasetDict
dataset = DatasetDict({
"train": train_dataset,
"validation": validation_dataset,
"test": test_dataset
})
これで、あとは、このブログの初っ端の参考サイトの「マルチクラスクラシフィケーション」のインストラクションのデータセットがダウンロードできたとみなせば、サンプルに従ってBertで処理させるように書いていけば、(環境に合わせて微調整は必要かもしれませんが)できます。少なくとも私はできました。
考察
いやー、なんとか調べて独学でここまでできましたよ。ずいぶん時間がかかりましたが。前処理に何日かかかりましたけど、機会学習(ファインチューニング)は、10分程度で終わってしまったんです。このQiitaでもわかってもらえるでしょうけど、達成感は機械学習ができたことではなくて、自前のデータを前処理してデータセットまで持っていけたことにあります。ダサくてもいい。ただ、このpandas データフレームの変形処理はテクニックは他でも使えるハズなのでヨシとしましょうよ。
まとめ
自前でデータセットを構築して、Transformersに読み込ませ、文書分類器を作成しました。自前データの前処理に随分と時間がかかりましたが、この投稿記事が自分または誰かの備忘録として、役に立てば幸いです。今後は、Transformersを使ってモデルとタスクの組み合わせを色々と試して、より自分の理想にあつツールを開発していきます。
おまけ
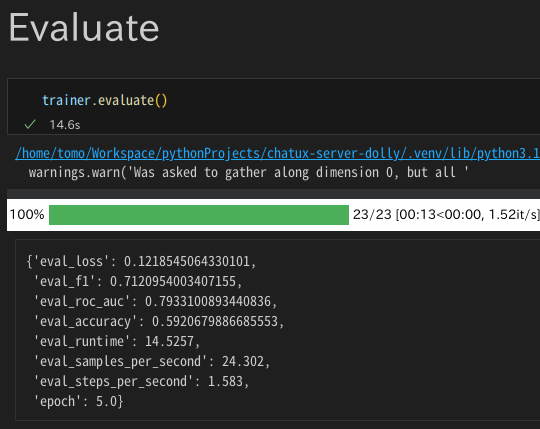
出来上がった文書分類器の性能評価。去年の手法より、よい成績になっているのは、やはり前提データの質がいいのだろう・・・。自前データでいろいろできるとわかると、今後の発展型開発も楽しみになりますな。段取り八分。前処理大事。