はじめに
前回に引き続き、DollyV2を触る・・・といいつつ、ちょっとDollyから離れた話。
DollyV2とChat(とはいえ、GTX Cudaでお返事を数分待つというテレワーク環境のやりとりのような状態)ができるようになった。しかし、日本語対応というモデルは、他の方のサンプルをみてもあまり賢くない様子。とはいえ、英語でのやり取りは、自分の英語の勉強にはなるがやはりちとつらい。
日本語でチューニングしてDollyV2さんに日本語をお勉強してもらう件は、先達が取り組んでおられるので、別のTransformerモデルを使って翻訳を介して日本語でDollyV2さんとやり取りする方法を試してみた。
翻訳機能
「Python Transformers 101本ノック」(Amazon)に紹介されていたM2M100を使ってみることにした。M2M100は、入力テキスト、ソース言語コード、ターゲット言語コードを指定して翻訳を得るスクリプトを書くことができる。
HuggingFace Transformers で動かす。当然、説明は上述ページを参照してもらいたい。
facebookが提供しているらしく、licenseはMIT。商用利用も可。
def translate(self, text: str = "", src_lang: str = "", tgt_lang: str = "en"):
print(f'debug translate function: {self.text}, {self.src_lang}, {self.tgt_lang}')
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_418M", max_length=512)
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_418M")
tokenizer.src_lang = self.src_lang
encoded_src = tokenizer(self.text, return_tensors="pt")
generated_tokens = model.generate(**encoded_src, forced_bos_token_id=tokenizer.get_lang_id(tgt_lang))
result = tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
return result[0]
作るもの
イメージとしてはこんな感じ。
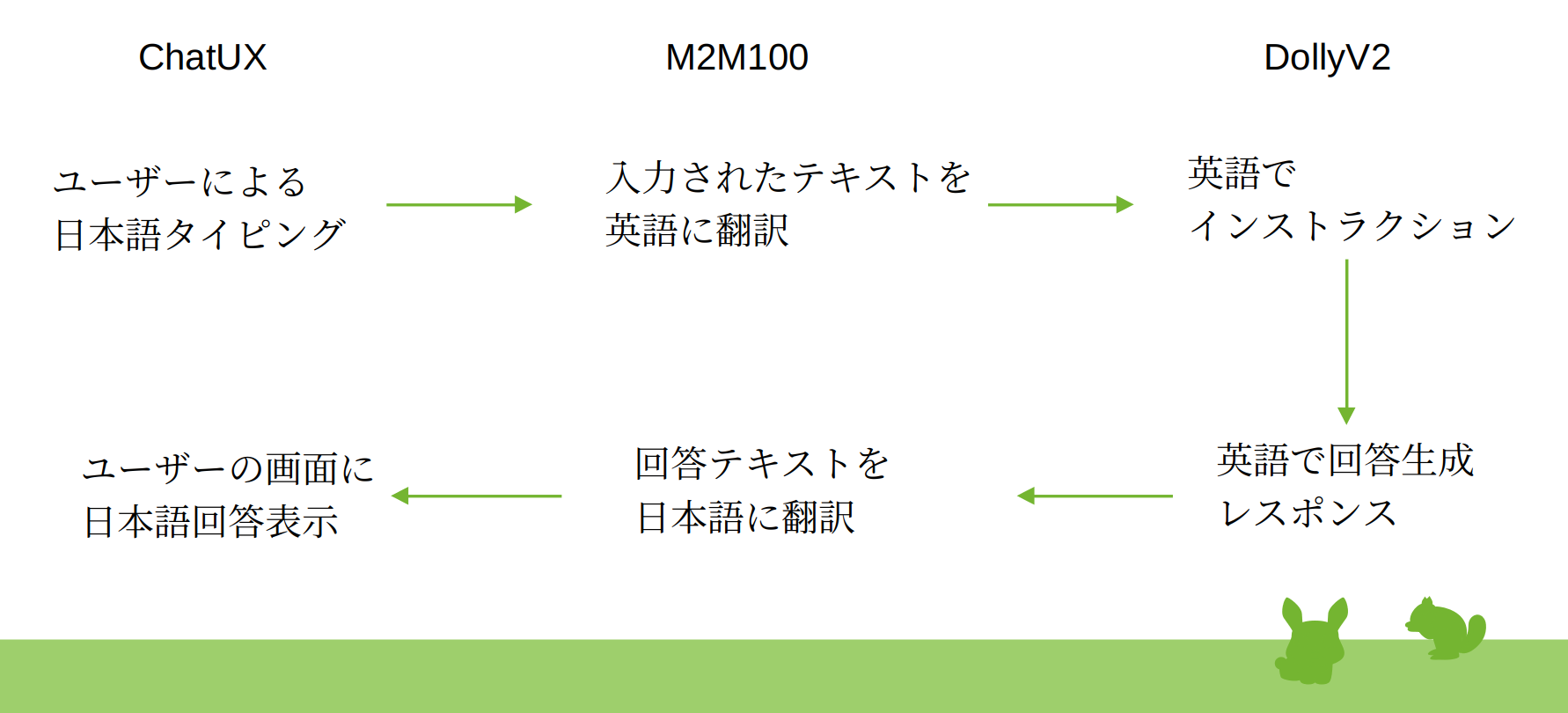
前回、先達のコードを参考に作った自前のコードに上述の翻訳機能を参照利用するように加筆するだけ。
ひと工夫
せっかくなので、入力言語をあらゆる言語に対応させることも考えた。つまり、タイプされた文章の言語種類を自動判別させる機能をさらに追加してみた。
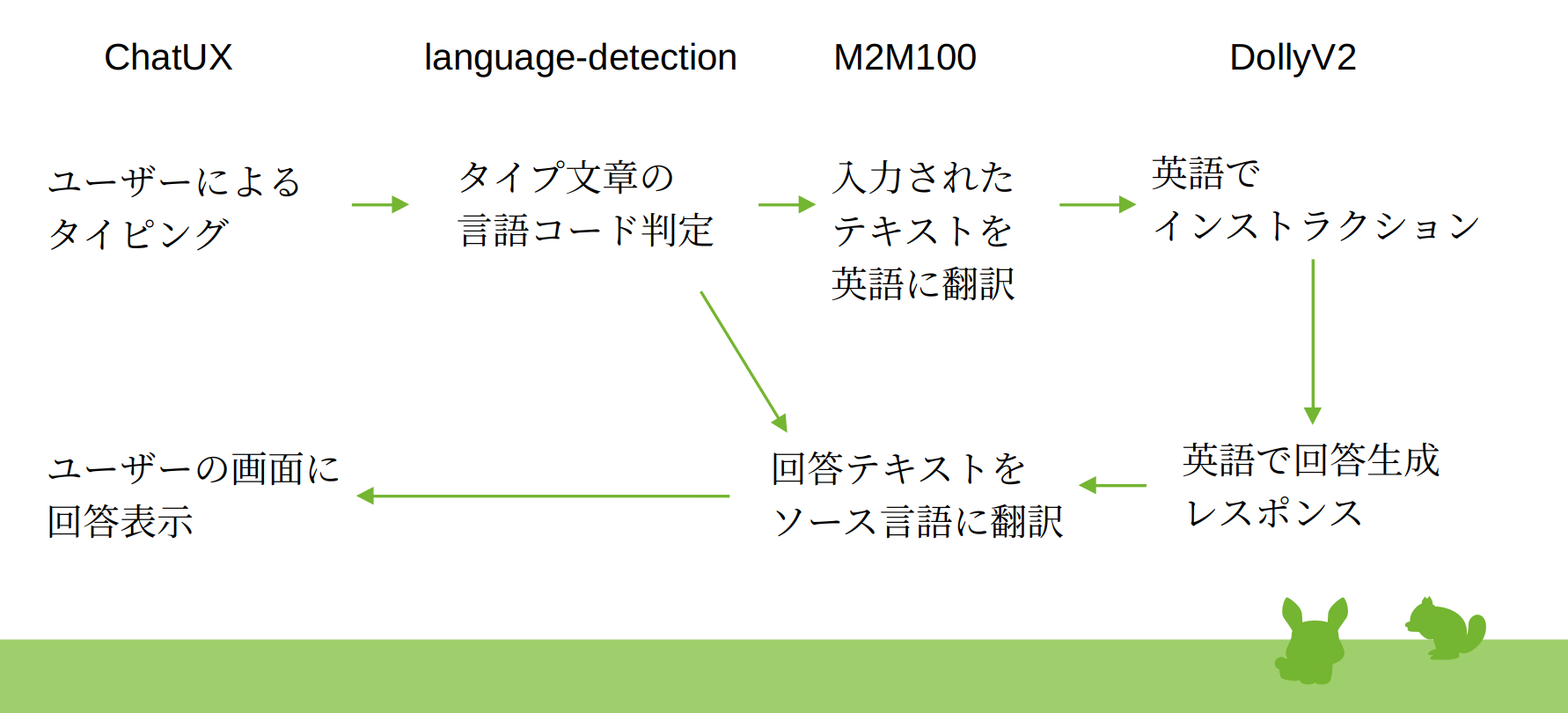
これには、こちらのモデルを使ったSequenceClassificationを使った。
こちらもMITライセンス。Pytorch対応バージョンがVer.1.10とちょっと古い、歴史を感じるモデルだが、Pytorch2.0でも動いた。
def findLanguageCode(self, text: str):
pipeline = TextClassificationPipeline(
tokenizer = AutoTokenizer.from_pretrained('ivanlau/language-detection-fine-tuned-on-xlm-roberta-base'),
model = AutoModelForSequenceClassification.from_pretrained("ivanlau/language-detection-fine-tuned-on-xlm-roberta-base")
)
# prepare input
output_list = pipeline(text)
output = output_list[0]['label']
lang_code = langcodes.find(output)
return str(lang_code)
このモデルの出力する言語の種類は、「言語コード」ではなくて、「言語名称」で返すモデルという点に注意。言語コードを出力するモデルがあれば変えたほうがいいかも。機能でモデルを探す方法がHuggingFaceにあればいいのだが・・・。そこで、langcodesライブラリを使って、モデルの出力する言語名称(label)から言語コードに変更した。
さて動かしてみると・・・
Transformerで、1)言語種類判定、2)翻訳、3)DollyV2と3つのモデルを動かす仕組みなので、VRAM容量が心配。DollyV2を3Bのモデルにし、M2M100を418Mモデルにして・・・と。スピードは遅いが、なんとかChatが楽しめるレベルに・・・。
だが、翻訳の前後のテキストをデバッグ的に見てみると(コンソールにprintすると)、M2M100の出力が短く切り捨てられている感じがする。大きなトークンが扱えないのか?Google検索してみるけど情報がみつからない・・・。
まとめ
Transformersモデルを使いまくって、日本語でDollyV2とチャットする仕組みを実装してみた。ライセンス的には、外部向けサービスとしての運用も可能ではあるが、さすがに個人のPCでスピードやVRAM容量を気にしながら運用するのは難しそうだ、と感じた。
おまけ
Meta(Facebook)は、NLLB-200という多言語対応翻訳モデルも制作している。こちらは、ライセンスが、cc-by-nc-4.0。 非商用利用の制限。
「NLLB-200は55種類のアフリカ言語をサポートし、高品質な翻訳を生成します。つまり、この1つのモデルだけで、世界の数十億の人々に話されている言語について、高品質な翻訳を提供できるのです。」
このNLLB-200という名前、No Language Left Behind (NLLB)プロジェクトからきているとのこと。アフリカで話されている55種類の言語を含む、世界200言語に対応し、翻訳機能で「誰一人取り残さない」を実現するという思想が込められているという。ソフトウェアで情報の平等、ひいては人権の擁護、SDGsにつながっているんだな、と考えさせられた。