はじめに
特化LLMを作ることに取り組むことにした。昨今のLLMはどうやっても有名企業が開発した有料サービスのほうがパフォーマンスが高いに違いない。とはいえ、できる限り低予算で、かつ、”特化”なデータを取り扱うことができ、ローカルで(もしくは企業内LANなど閉鎖的環境で)動作するものを作りたい、と自分なりのハードルを用意したうえで、それに向けて準備を開始した。
開発・動作環境構築について(前置き)
LLM界隈の開発情報をみると、OpenAIのChatGPTの記事が圧倒的に多い。つまりChatGPTに使われているGPT-4を使う前提にすれば、他の人のマネでラクチンにものが作れるはずだ。だが、GPR-4のAPIは一般公開されたとはいえ有料だ。まして私みたいな失敗を繰り返す人間では失敗料込で予算を考えると有料版を最初から使うことには抵抗がある。PythonのLangchainというライブラリパッケージを使うと、OpenAIのAPIだけでなく、HuggingFaceのLLMも使えたりするらしい(例えば、こちら)。Langchainは、できるかぎりコードを共通化しておき、低予算のLLMが使えないときはOpenAIに頼ることもできる、という点でも採用して間違いはなさそうだ。ところで、Cuda処理についてこれまでGTX1080を使っていたが、Langchainは、RTX20xx以降でないと動作しないらしい。しかもLLMはVRAM容量がそれなりに必要だ。中古のGPU、RTX3090を入手することとした。Python開発環境は従来PCを流用する。
特化LLMによる対話型サービスの背景として、”自前データの参照”が必要(例えば、Langchainにおける説明)。もともと、自前データにしようと考えているデータは様々なサイトからクローリングしてMongoDBに保存してあるテキスト。HTMLページごとにドキュメントが作成されていて、その数は200万件近い。このままMongoDBをデータストアとして扱ってもいいのかもしれないが、LLMが読み取るベクタデータに変換することを考えると、その量からして、ベクタデータに変換して保存しておいたほうが処理が早いのではないか、と考えた。この点を含め、パフォーマンス(特に人の問いかけに対する回答までの時間)については継続検討課題であると考えている。Langchainは、このようなベクタデータの管理方法についても準備ができていて、VectorStoreというものを構築するらしい。
さて、VectorStoreの構築にあたって、Langchainで動作するVectorStoreとしていくつかのミドルウェアを選択することができる。たとえば、Redisを使っている人もいた。
大容量データの保存とサーチに実績のあるElasticsearchを、筆者は選んでみた。似た考えですでに動作させている人の記事も見つかった。
以上、本件は、RTX3090を使ってLangchainを動作させ、ElasticsearchVectorStoreを構築するお話であることを前置きとさせていただく。
前処理
テキストのデータ(ドキュメント)を読み込んで、整形して、VectorStoreに書き込む。これが全体の流れだが、ドキュメントを読み込んで整形する部分までを前処理として以下に記録しておく。
まずはMongoDBのデータをPythonで読み込む。200万件を順に読み込んでもいいのだが、私がコードを走らせるたびにMongoDBサーバに負荷をかけることが申し訳なくおもったので、いったん必要と思われるフィールドのデータだけJSONデータで出力、保存しておくことにした。pymongoを使ってアクセスし、10万件ずつ読み込んで、読み込んだ10万件をローカルPCのメモリ上(ローカルPCはRAM32GB)で整形(エスケープキャラクタの処理とか)、それをJSONファイルに出力した。350MBぐらいの大きさのファイルが20個できた。
VectorStore への書き込み
そもそもLangChainにデータをもたせる背景としてのVectorStoreってなんなのか、というかどういう使われ方をするものか、というのを理解する。この公式の図をみてほしい。
次に、ElasticsearchのVectorStoreについては、公式の説明は商用サービスへの対応で書かれているらしい。
どっこい、こちとらは有料サービスを使わない方針だから、ElasticsearchはDockerで動かす。いずれにせよ、まっさらなElasticsearchにPythonでアクセスできる状態になればいいのだ。Elasticsearchの構築については、本件では触れない。別で調べてほしい。
HuggingFaceEmbeddings
さて、langchainからどうアクセスするのか、とおもったら・・・
「えんべでぃんぐ」というやつが必要になることがわかった。公式では、「OpenAIEmbedings」というやつを使ったサンプルを表示している。”OpenAI”用なのだ。
from langchain import ElasticVectorSearch
from langchain.embeddings import えんべでぃんぐ
embedding = えんべでぃんぐ()
elastic_vector_search = ElasticVectorSearch(
elasticsearch_url="http://localhost:9200",
index_name="test_index",
embedding=embedding
)
今回は、HuggingFaceのLLM用にしたいので、このえんべディングに何を選べばいいのか調べることになった。えんべディングとはなんじゃい?と、また公式の説明
要はモデルに合わせた「埋め込み」のスタイル(?)を提供してくれるやつのことだな。理屈はたぶんそうだろう・・・だから、何を選べばいいんじゃい!公式の説明は「いろいろあるよ〜」としか言ってない(笑)。
わからないので先達に倣う。LoRのAIサーチを作った先達のコードは、以下のとおり。
from langchain.embeddings import HuggingFaceEmbeddings
def setup_embeddings():
# Huggingface embedding setup
print(">> Prep. Huggingface embedding setup")
model_name = "sentence-transformers/all-mpnet-base-v2"
return HuggingFaceEmbeddings(model_name=model_name)
HuggingFaceEmbeddingsに、sentence-transformersのモデルを読み込ませている。sentence-transformers?よくわからんので、とにかくこの一択以外、選びようがない。
これで、先のコードの えんべでぃんぐ() のところを setup_embeddings() にしてあげてこのEmbeddingsを指定すればいいんだな。
json ファイルを読み込む
これはもうpandasで読み込む方法以外は、私はめったに使わない。そして今回はpandasで読み込むJSONが、JSONLなフォーマットにしてあるので、pandasに読み込ませて行ごとに処理を行う流れとなる。(JSONLがなにかという疑問を持ったひとは別で調べてね)
さらにここで ElasticVectorSearch オブジェクトを生成して、後述の pandasの行ごとの処理 に引数として渡している。
import os
import pandas as pd
from langchain.vectorstores.elastic_vector_search import ElasticVectorSearch
def fileReadProcess(file):
file_path = os.path.join(dir_path, file)
print( '>> file: ', file_path )
# テキスト読み込み
df = pd.read_json(file_path, orient='records', lines=True)
# Elasticsearch へのアクセスURLを構成する。環境に合わせて変数に代入。
url = f"http://{username}:{password}@{endpoint}:{portnum}"
# Huggingface embedding setup
hf = setup_embeddings()
# langchain用のインデックスの名前。
index_name = "langchaindex"
db = ElasticVectorSearch(
embedding=hf,
elasticsearch_url = url,
index_name=index_name
)
# 読み込み情報をサーチストアへ
df.apply(setDocs, axis=1, db_es=db)
pandas行ごとの処理
この処理こそが、データを加工してVectorStoreに書き込む要の部分。Transform, Embed, の部分。

from langchain.text_splitter import RecursiveCharacterTextSplitter
def setDocs(row, db_es):
# チャンクに分割
text_splitter = RecursiveCharacterTextSplitter(chunk_size=chunk_size, chunk_overlap=0)
chunks = list()
for chk in text_splitter.split_text(row['Country'] + '. ' + row['Organization'] + '. ' + row['Title'] + ' ' + row['Article']):
chunks.append(chk)
chunk_count = len(chunks)
if chunk_count > 0:
# メタデータを作成
metadata = [
{
"country": row['Country'], # 記事発信国
"title": row['Title'],
"organization_type": row['Organization_type'],
"organization": row['Organization'],
"timestamp": row['Timestamp'],
"chunk_count": chunk_count, # 合計チャンク数
"chunk_number": i+1 # チャンク通し番号
} for i in range(0, chunk_count)
]
for _ in range(3):
# リストに追加
try:
db_es.add_texts( texts=chunks, metadatas=metadata )
except Exception as e:
print('ElasticVectorSearch.add_texts() exception.')
print('=== エラー内容 ===')
print('type:' + str(type(e)))
print('args:' + str(e.args))
print('リトライします')
finally:
chunks = None
metadata = None
else:
print('リトライしましたが、成功しませんでした。')
print('===スキップします===')
pass
ポイントは、db_esで渡された ElasticVectorSearchを使って、addTextsするところ。このaddTextsこそがVectorStoreとしてのElasticsearchへのデータの書き込みである。
書き込んでいるデータは、Chunksとmetadata。
chunks は RecursiveCharacterTextSplitterという変換処理(Transformers)のひとつにより、文章を分解したもの。分解するデータは、人それぞれだろう。私の場合は、いくつかのフィールドを連結して一文としたうえで分割させた。分割の長さ(chunk_size)は、変数にしておいて、関数の外から変化させられるようにした。これもどれぐらいの長さが使用するLLMにちょうどよいのかわからないからだ。長すぎるとメモリに入らないことは想像できるのだが、じゃぁ、どれぐらい短いほうがいいのか、できるかぎり長いほうがいいのか、よくわからない。ここはあとで何度か調整・再構成することを覚悟して変数にしたのだ。
あとは、metadataを仕込むところがミソ。上述したRedisを使った先達の真似だ。先達が丁寧にチャンク通し番号とか付けていたのをみならt。記事タイトルは重複がないとすれば、これで書き込むテキストを、開発者が別途Elasticsearchでサーチするときにもうまく”人が読める文章として”再構成して取り出すこともできるだろう。
構築にトライ・・・
さて、これで 360MB/個の JSONLとなった10万件のデータを20個(合計200万件)読み込ませるぞ!と意気込んで、試しに1つのファイルだけ読み込ませてみたところ・・・2時間経っても終わらない。ウッソーん。apply句を書き間違えたかな、とか思ってkibanaで index management を見てみたり、index patternを作って discoverで見てみたら・・・記事は入ってる。つまり、10万件の書き込みは2時間じゃ終わらんってことだ。1秒5~10件として、10,000〜20,000秒=2.78〜5.55時間 ってことは、約3〜5時間半。20ファイルあったら60〜100時間超えか。4,5日PCを専有されるのは面倒だな。
データ書き込み中に nvidia-smi してみると。pythonで使われているメモリは約4GB。お、VRAMに余裕があるな。ってことは、並行処理でファイルを扱って書き込んだらいいんじゃね?
並行処理の検討
大量にファイルを読み込むとき、並行処理、よくやるパターンですよね。ただ、今回はファイルからデータを読み込むだけでなく、データの加工(しかもCuda処理= langchain.vectorsearch の addTexts処理)を行う。はたしてこれがうまくできるのか、と調べたら、あるんですね、できるんですね。
・・・というわけで、作ったコードがこちら。
from torch.multiprocessing import Pool, get_start_method, set_start_method
## ファイル読み込み
def readFiles(fileNum:int = None):
files = [f for f in os.listdir(dir_path) if os.path.isfile(os.path.join(dir_path, f))]
if get_start_method() == 'fork':
set_start_method('spawn', force=True)
print("{} setup done".format(get_start_method()))
if (fileNum == None):
with Pool(processes=5) as p:
p.map(fileReadProcess, files)
else:
fileReadProcess(files[fileNum])
if __name__ == "__main__":
torch.multiprocessing.freeze_support()
readfiles()
torch.multiproccessing の Poolを動かした際、warningが2つでて、一つは、start_methodをspawnにしろ、っていうのと、もう一つは、処理開始前にfreeze_support()を実行しろ、とのこと。
実行
さて、実行。単純な処理の連続で60時間以上を要すると予想された処理を、並行処理で行うことで時間短縮するのは間違いないが・・・果たして何時間かかるのか。ちなみに、実行中の nvidia-smi。

...お、鬼のような 357W動作! あんたcap超えて食うねんな、PC本体と合わせたら500W以上はいっとんな・・・。それを何時間続けるって?で、電気代が・・・
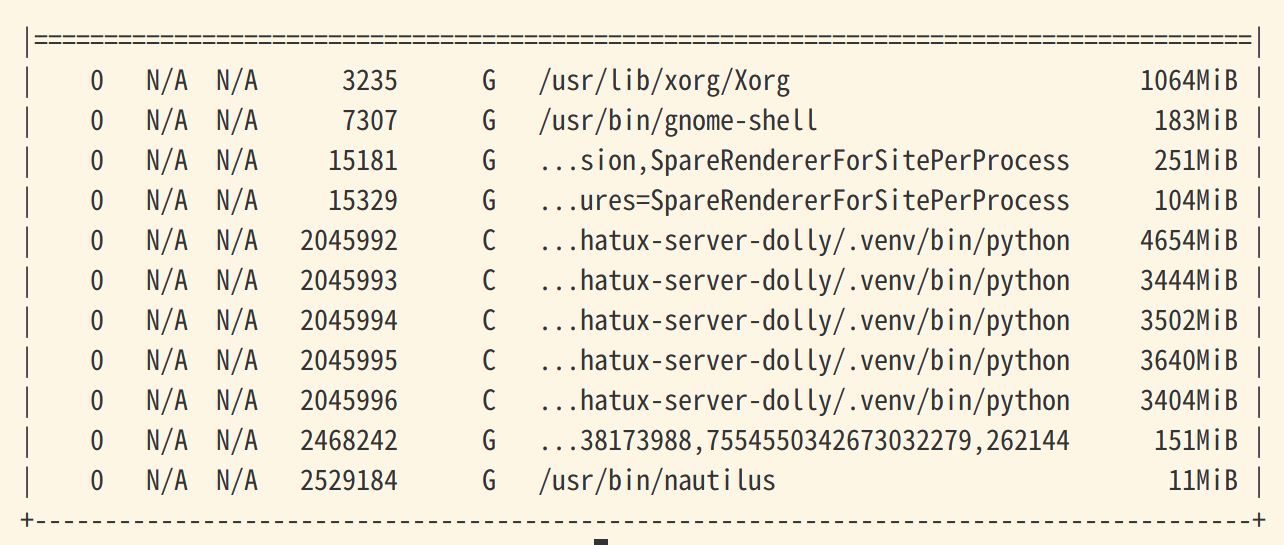
python の4GB前後のプロセスが5つ。RTX3090-24GBVRAMの面目躍如ではあるな。

free -m したところ。メインメモリも18GBほど使っとる。 python3.9.17 メモリくうなぁ。

そして、kibana の index management で見た、Elasticsearchのインデックス。まだ、処理途中で、すでに230GBのディスク容量を食っとる。チャンクサイズ 384 が小さすぎたか? ドキュメントの数(Docs count)が1300万を超えてる(w。なお余談だがhealthがyellowなのは、single-node構成だから。
感想
マシンパワーを全力使ってる感。いやぁ、男のロマンだねぇ・・・。
ElasticsearchをHDD上に構築したので処理が遅いのかな。これ、nvmeのSSDとかでやったら、ディスクIOが10倍は処理が早いだろうから、ディスクも買うべきか・・・。
結果
処理実行開始から26〜30時間ぐらいで終わってるんじゃないかな。実行開始して放置して翌々日に見たら終わっているパターン。
まとめ
LangChain VectorStoreとしてElasticVectorSearchを構築した。データ投入にあたって、addtextsを並行処理させてみた。pythonのコーディングとRTXの動作結果には満足しているが、HDDではなくSSD上にElasticsearchを構築すべきだろうか、と考えている。