はじめに
MongoDBにコレクションされたドキュメントに対し、全文検索したくなった。しかし、MongoDBに対して検索をしかけるのではちょっと速度面で難がある。また、検索のためのUIの作成もめんどくさい。
なにか簡単に実用的なツールを構築する手立てはないか、と模索していたところ、Elasticsearchに App Searchというものがある(あった?2020年に名称が変更になっているらしい)ことがわかった。
今回の先達情報はこちら。
こちらの先達の手段で、AppSearch環境は作れる。本投稿では、PythonでMongoDBのデータを読み込み、AppSearchに書き写す機能の開発の説明に重点を置きながら、全文検索調査システムを構築する手順を紹介する。
App Search のセットアップ
docker を使う。dockerで 4GB程度のメモリが使える環境であることが必要らしい。事前準備として、読者の環境でdovkerの環境を調整してほしい。また、ローカル環境個人利用の範囲ということでクラスタを組まずに使うこととする。
先達のお試し環境構築の説明の、ElasticAppSearchの導入のパターン2 に従って、Docker-Composeを使用する。ただし、先達よりも新しいバージョン、7.6.2 を使い、データの永続化にも対応するよう、volumesを確保した。
version: '2.4'
services:
elasticsearch:
image: docker.elastic.co/elasticsearch/elasticsearch:7.6.2
environment:
- "node.name=es-node"
- "discovery.type=single-node"
- "cluster.name=app-search-docker-cluster"
- "bootstrap.memory_lock=true"
- "ES_JAVA_OPTS=-Xms1g -Xmx1g"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- esdata01:/usr/share/elasticsearch/data
- esdictionary01:/usr/share/elasticsearch/config/dictionary
healthcheck:
test: ["CMD", "curl", "-f", "http://elasticsearch:9200"]
interval: 30s
timeout: 10s
retries: 3
start_period: 30s
appsearch:
image: docker.elastic.co/app-search/app-search:7.6.2
environment:
- "elasticsearch.host=http://elasticsearch:9200"
- "allow_es_settings_modification=true"
- "JAVA_OPTS=-Xms2g -Xmx2g"
- "app_search.listen_host=0.0.0.0"
- "app_search.external_url=http://localhost:3002"
ports:
- 3002:3002
depends_on:
elasticsearch:
condition: service_healthy
volumes:
esdata01:
driver: local
esdictionary01:
driver: local
docker-compose での起動には、2~3分かかる。Elasticsearchが起動完了したあとで、AppSearchが起動する。
起動したら、先達の 2.検索エンジンの作成 に倣って、エンジンの命名とLanguage設定を行う。
次にデータの投入だが、ここがJSONファイルではなく、APIをPythonからアクセスしてデータを投入することになる。ここで、USE the API を選んで、画面をみて、Auturization:Bearer のところの private- xxxx... をコピーしておく。(コピーできなかったら、別の画面で取得することもできる)。
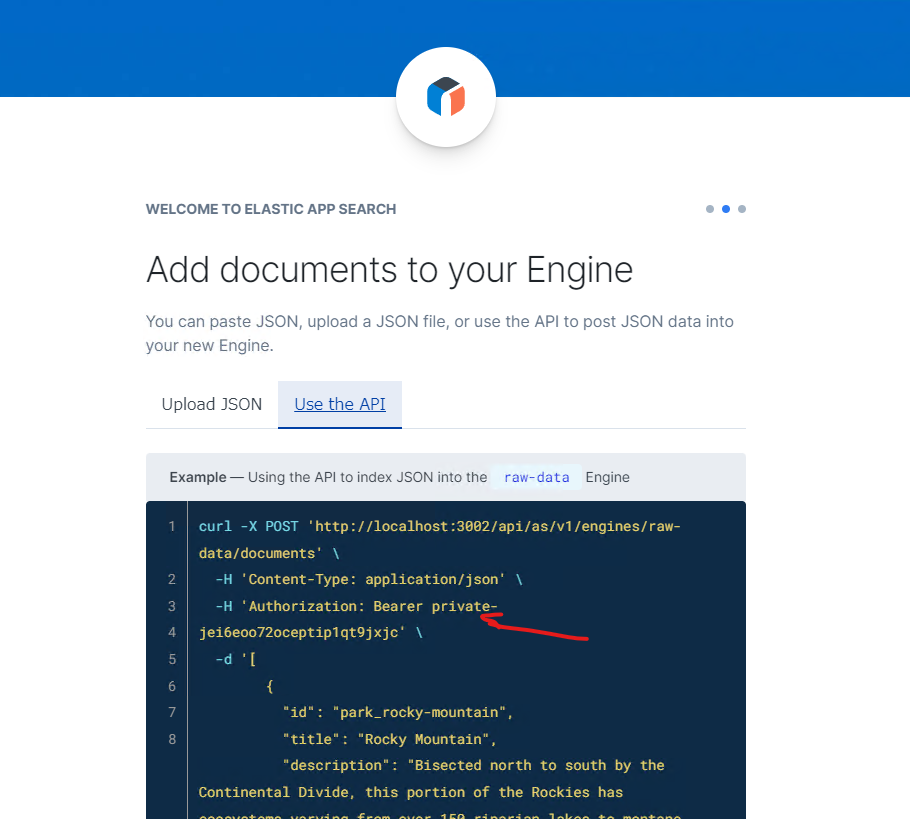
必要な情報をコピーしたら、画面左上、「Skip on Boarding」をクリックしてダッシュボードへ移動。ここまでで下準備完了。
elastic/app-search-python を導入
続いて、Pythonのスクリプトを作る。このスクリプトは、MongoDBのデータを読み出して、App search に転送するためのものだ。
公式からAPI Clientが提供されている。導入は pip で。2022年4月では ver.7.10.0 が入る。説明によると、elasticsearch 7.3 以降であれば、対応するようだ。
python3 -m pip install elastic-app-search
さて、早速、スクリプトを書く・・・。筆者は、MongoDBのデータを読み込んでpandas dataframe に変換した。そこで、このdataframe を app search に送付する仕組みを作っていく。
from elastic_app_search import Client #// app search クライアントを読み込む。
...
# app search client 確立
client = Client(
base_endpoint='localhost:3002/api/as/v1',
api_key='private-xxx ...', #// ご自身の環境に合わせて。
use_https=False #// localhost ssl なしなので。
)
# App Search の APIの制限で一度に読み込めるドキュメント最大数は100。
CHUNK_SIZE = 100
# 引数df に pandas dataframe を渡すと、App Search API向けJSONを生成する関数。
# App Search ドキュメントIDを MongoDB のドキュメント _id と同じにする処理付き。
def app_search_update(df):
records = [d[1] for d in df.iterrows()]
doc_es = []
for doc in records:
doc_key = {}
for key in doc.keys():
if key == '_id':
doc_key['id'] = str(doc['_id'])
else:
doc_key[key.lower()] = doc[key]
doc_es.append(doc_key)
return doc_es
...
gendata = app_search_update(last)
client.index_documents("raw-data", gendata)
index_document"s" と s がつくほうが複数のドキュメントを書き込めるコマンド。
・・・さて、100万件のデータの転送について、100件が1秒で処理できたとしても1万秒。約3時間。App search API の上限変更の方法がわからんかったので、まぁ、待つか。もし情報があったら、コメントでお知らせいただけたら幸いです。
検索UI
先達の解説 3.検索エンジンのUIの作成 に記述があるように、UIを作ってくれる機能が App Search にある。作成した WebUIを zip でダウンロード。
このダウンロードしたWebUIは、nodejs の プロジェクトになっているので、これもdockerで起動するようにしてしまおう。(筆者はdocker-compose 好き?かも)なにせ、このプロジェクト、python2.7とnodejs8 で動かすものだから。dockerだからこそ対応できるといえる。
フォルダ配置
|-node-docker
| |
| - Dockerfile
|
|-node-react(この下に、ダウンロードした WebUI のZIPファイルを展開。)
| |-bin
| |-public
| |-scripts ....
| |....
|
|-docker-compose.react-app.yml
Dockerfile
FROM nikolaik/python-nodejs:python2.7-nodejs12-alpine
WORKDIR /usr/src/app
docker-compse.react-app.yml
version: '3'
services:
node:
build: ./node-docker
volumes:
- ./node-react:/usr/src/app:cached
command: sh -c "npm install && npm start"
ports:
- "3000:3000"
考察
このUIを外部に公開する場合は、 nodeプロジェクトの src/config/engine.jsonの endpointBase を、外部からアクセス可能な App Search のアドレスに変更する編集を行えばよい。外部公開に対応するには、Elasticsearchのバージョンを上げて、xpackのセキュリティ機能を使うなどを検討すべきだろう。そうすると、App Search ではないソリューションで対応する必要がある。
UIは、カスタマイズが可能なようだ。必要に応じて改変するのもよいかもしれない。
また、今回の方法では、MongoDBのデータ更新に追従するためには、定期的にMongoDBからデータを転送する必要がある。今回の方法では差分アップデートを考慮していない。Pythonクライアントを使った更改手段もあるようなので、研究・開発してみるとよいかもしれない。
まとめ
全文検索システム構築を比較的容易に行うことのできる Elasticksearch の App Search とそのPythonクライアントを使って、MongoDBのデータを転送して全文検索するシステムを構築した。
外部公開するためのセキュリティ、データの更新の方法についてさらに研究、開発すれば、MongoDBのデータの更新に追従した検索サービスシステムを提供することもできるだろう。