はじめに
前回、WindowsへのDeepLearningライブラリKerasの導入と四角形が縦長か横長かの2値分類を行いました。まだ読まれてない方は、そちらからの方が分かり良いかもしれません。
さて、今回はディープラーニングを使ってまで2値の分類では面白くないと思うので、次のステップとしてMNISTという0~9の数字の手書き文字のデータセットを用いて、数字の多クラス分類を行います。この記事でも、ネットワークは前回と同じく多層パーセプトロン(MLP)を使用します。多層パーセプトロンについて説明していなかったので、最初に軽く説明します。初期値や最適化のパラメータ説明はその5あたりで別にとりあげます。
実行環境
- Windows 10(64bit)with only CPU
- Python 3.5.2
- Anaconda 4.2.0(64bit)
- Tensorflow 0.12.1
- Keras 1.2.1
多層パーセプトロンとは
パーセプトロン
パーセプトロンとは一体なんなのでしょうか?参考文献に載せている1番目の書籍によると
パーセプトロンとは、ローゼンブラッドというアメリカの研究者によって1957年に考案されたアルゴリズムで、ニューラルネットネット(ディープラーニング)の起源となるものです。
ということらしいです(多少、表現は変えています)。これだけでは具体的に何なのかわからないと思うので、具体的にパーセプトロン自体が何かを説明します。言葉で説明すると、「複数の信号を入力として受け取り、ひとつの信号を出力するもの」で、出力信号は0か1かの2値をとります。
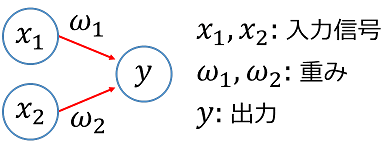
ニューロンでは、送られてきた信号の総和が計算され、その総和がある限界値を超えた場合にのみ1を出力します。これを「ニューロンが発火する」と表現することもあるそうです。その限界値を閾値と呼び、$\theta$で表すと出力$y$は次のような式で表現できます。
\begin{eqnarray}
y=\left\{ \begin{array}{ll}
0 & (\omega_1 x_1 + \omega_2 x_2 \leq \theta) \\
1 & (\omega_1 x_1 + \omega_2 x_2 > \theta) \\
\end{array} \right.
\end{eqnarray}
つまり、パーセプトロンの重み$\omega$は信号の重要度の高さを表し、バイアス$b$は発火し易さを調整するパラメータです。バイアス$b$とは、$b = -\theta$としたもののことです。文脈によってはこのバイアスも重みと呼ばれることもあります。
しかしながら、上式を見るとわかるように単一のパーセプトロンで識別できるのは直線で識別できるものだけです。そのため、非線形の事象には、対応することができません。
多層パーセプトロン
単純なパーセプトロンは、線形問題でしか使えません。しかしながら、パーセプトロンは層を重ねることができるため、非線形問題も扱うことができるようになります。これを、多層パーセプトロンと言います。
ここで、少し気をつけなければならないことがあります。それは、広く多層パーセプトロンと呼ばれるものは、先ほど説明した単純なパーセプトロンとは別物です。多層パーセプトロンは、パーセプトロンが0か1かの出力だったのに対し、出力は活性化関数がシグモイドの場合0から1までの実数が出力値となります。
さて、いきなり活性化関数という言葉を出しました。活性化関数というのは、単純パーセプトロンが閾値で出力が0か1かを決めていたのに対して、多層パーセプトロンでは、入力の総和を変数として非線形の活性化関数$h$をとおすことによって出力の実数を決定します。
\begin{eqnarray}
a =& \omega_1 x_1 + \omega_2 x_2 + b\\
y =& h(a)
\end{eqnarray}
例えば、シグモイド関数は次のような関数で、入力される変数の値によって0から1までの間の実数値を出力します。sigmoid
\begin{equation}
h(x) = \frac{1}{1+\exp(-x)}
\end{equation}

最後に、多層パーセプトロンについてまとめると次のようになります。
- 単純パーセプトロンは、単層のネットワークで活性化関数にステップ関数を当てはめたネットワーク
- 多層パーセプトロンは、ニューラルネットワーク(多層)で活性化関数にシグモイドなどの非線形関数を当てはめたネットワーク
手書き文字の識別
なんとなく多層パーセプトロンについて分かってもらえたでしょうか。ここでようやく多層パーセプトロンを用いた手書き文字の識別を行います。
学習
MNISTは、Kerasでデータセットとして訓練データとテストデータを読み込むことができます。そのため、前回のようにデータセットをダウンロードしてくる必要はありません。次のようなスクリプトで学習とその結果を表示することができます。前回の多層パーセプトロンの活性化関数にシグモイド関数を使っていましたが、今回はReLU関数というものを使用しています。なぜ、ReLU関数を使用している理由についてはこちらの方が精度が良いからなのですが、その理由についてはまた別の記事で詳しく説明します。
また、分類を行いたいときの最終層の活性化関数は必ずソフトマックスにしてください。そうしないと、分類になりません。Jupyter Notebookは、Gistにアップしています。
import numpy as np
import matplotlib.pyplot as plt
from keras.utils import np_utils
from scipy.misc import toimage
# MNISTデータセットを読み込むために必要
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation
# 分類するクラス数の設定
class_num = 10
# mnistのデータセットを読み込み
(X_train, y_train),(X_test, y_test) = mnist.load_data()
# 学習データを正規化
X_train = X_train/255
X_test = X_test/255
# 入力するためにデータを整形
# 1画像28ピクセルx28ピクセルの2次元配列を784次元のベクトルに変換
X_train = X_train.reshape(-1,784)
X_test = X_test.reshape(-1,784)
# ラベルをクラス数に対応する配列に変更
# 例:y_train:[0 1 7 5] -> Y_train:[[1 0 0 0 0 0 0 0 0 0],[0 1 0 0 0 0 0 0 0 0],[0 0 0 0 0 0 0 1 0 0],[0 0 0 0 0 1 0 0 0 0]]
Y_train = np_utils.to_categorical(y_train,class_num)
Y_test = np_utils.to_categorical(y_test,class_num)
# 多層パーセプトロンのネットワーク作成
# 入力を784次元(28x28)で、最終的な出力をクラス数に設定
model = Sequential()
model.add(Dense(512, input_dim=784, init='uniform'))
# 活性化関数にはReLU関数を使用
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(512, init='uniform'))
# 活性化関数にはReLU関数を使用
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(class_num, input_dim=512, init='uniform'))
# 分類の場合は最終層には必ずソフトマックスを用いる
model.add(Activation('softmax'))
# 多値分類なのでカテゴリカルを選択,最適化アルゴリズムはRMSpropを選択
model.compile(loss='categorical_crossentropy',
optimizer='rmsprop',
metrics=['accuracy'])
# 固定回数(データセットの反復)の試行でモデルを学習
model.fit(X_train, Y_train,
nb_epoch=5,
batch_size=100)
# 学習後のパラメータを評価
score = model.evaluate(X_test, Y_test, batch_size=100)
print(score)
# テストデータのラベルを推定、返り値はラベルが返ってくる
classified_label = model.predict_classes(X_test[0:10,:])
# 推定したラベルと画像の表示
for i in range(10):
# ベクトルデータをアレイに変換して、それを画像データに変換
img = toimage(X_test[i,:].reshape(28,28))
plt.subplot(2,5,i+1)
plt.imshow(img, cmap='gray')
plt.title("Class {0}".format(classified_label[i]))
plt.axis('off')
plt.show()
# モデルと重みの保存
model_json = model.to_json()
open('mnist_architecture.json', 'w').write(model_json)
model.save_weights('mnist_weights.h5', overwrite=True)
結果
テストデータのはじめから10個の推定したラベルと画像は以下になります。クラスと文字が一致していることが分かります。ちなみに、この画像のテスト結果は正解率97.7%と十分実用できるレベルになっていました。テストの画像を見てみると、一見5なんかは8と間違えそうな気もしますが、正しく分類できてますね。ちなみにシグモイドですると、あまり正解率80%程度しかでなかったので、適切なパラメータを設定することが大切です。

自分で書いた数字で実験
ここまでで、学習はかなりの精度でできているように思えます。しかしながら、やはり自分で書いた文字でテストしてみたいです。そこで、ペイントで56ピクセルx56ピクセルのキャンバスに0から9までの数字を書いた画像を作成しました。それを以下のコードで、学習済みの重みを読み込んでクラスを予測してみました。Jupyter Notebookは、Gistにアップしています。
import numpy as np
import matplotlib.pyplot as plt
from keras.utils import np_utils
from keras.models import Sequential,model_from_json
from keras.preprocessing import image
from keras.applications.imagenet_utils import preprocess_input, decode_predictions
# テストに用意した画像の枚数
test_num = 10
# モデルの読み込み
model = model_from_json(open('mnist_architecture.json').read())
# モデルの重みの読み込み
model.load_weights('mnist_weights.h5')
for i in range(test_num):
# ファイル名の指定
img_path = str(i)+".jpg"
# 28ピクセルx28ピクセル、グレースケールで画像を読み込み
img = image.load_img(img_path, grayscale=True, target_size=(28, 28))
# 読み込んだイメージをアレイに変換
x = image.img_to_array(img)
# アレイサイズの確認
print(x.shape)
# モデルに入力するために、28x28の2次元配列を大きさ784のベクトルに整形
x = x[:,:,0].reshape(-1,784)
# クラスの予測
classified_label = model.predict_classes(x)
# 予測結果のプロット
plt.subplot(2,5,i+1)
plt.imshow(img, cmap='gray')
plt.title("Class {0}".format(classified_label[0]))
plt.axis('off')
plt.show()
自分の手書き文字の予測結果
予測結果はすべて正解かと思いきや、私が書いた数字では正解率70%という結果でした。これは、データセットの筆跡と異なるからかなと考えられます。どうにもすっきりしませんので、CNNで学習させたものを後日追記でここに掲載します。

CNN学習時の実行環境とソースコード
実行環境
流石にCNNの学習をさせるには、CPUだけの普通のPCでは時間がかかりすぎるのでGPU環境のあるクラウド上で学習させました。その時の実行環境はこのような感じでした。この環境でMNISTの学習なら、1分かからずに終わりました。
- Ubuntu 16.04.1 LTS
- Geforce GTX TITAN X
- Python 2.7.12
- Tensorflow-gpu 0.12.1
- Keras 1.2.0
学習時のソースコード
import numpy as np
from keras.utils import np_utils
from keras.datasets import mnist
from keras.models import Sequential
from keras.layers import Dense, Dropout, Activation, Flatten
from keras.layers import Convolution2D, MaxPooling2D
from keras import backend as K
# バッチ数
batch_size = 128
# 分類するクラスの数
nb_classes = 10
# エポックの数
nb_epoch = 12
# 入力する画像の次元数
img_rows, img_cols = 28, 28
# 畳み込みに使うフィルタの数
nb_filters = 32
# pooling層の大きさを指定
pool_size = (2, 2)
# convolutionカーネルの大きさを指定
kernel_size = (3, 3)
# mnistデータの読み込み
(X_train, y_train), (X_test, y_test) = mnist.load_data()
if K.image_dim_ordering() == 'th':
X_train = X_train.reshape(X_train.shape[0], 1, img_rows, img_cols)
X_test = X_test.reshape(X_test.shape[0], 1, img_rows, img_cols)
input_shape = (1, img_rows, img_cols)
else:
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
X_train = X_train.astype('float32')
X_test = X_test.astype('float32')
# 正規化
X_train /= 255
X_test /= 255
# バイナリ行列に変換
Y_train = np_utils.to_categorical(y_train, nb_classes)
Y_test = np_utils.to_categorical(y_test, nb_classes)
# CNNのモデル作成
model = Sequential()
model.add(Convolution2D(nb_filters, kernel_size[0], kernel_size[1],
border_mode='valid',
input_shape=input_shape))
model.add(Activation('relu'))
model.add(Convolution2D(nb_filters, kernel_size[0], kernel_size[1]))
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=pool_size))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128))
model.add(Activation('relu'))
model.add(Dropout(0.5))
model.add(Dense(nb_classes))
model.add(Activation('softmax'))
# モデルのコンパイル
model.compile(loss='categorical_crossentropy',
optimizer='adadelta',
metrics=['accuracy'])
# 学習
model.fit(X_train, Y_train, batch_size=batch_size, nb_epoch=nb_epoch,
verbose=1, validation_data=(X_test, Y_test))
# モデルの評価
score = model.evaluate(X_test, Y_test, verbose=0)
print(score)
# モデルと重みの保存
model_json = model.to_json()
open('mnist_cnn_architecture.json', 'w').write(model_json)
model.save_weights('mnist_cnn_weights.h5', overwrite=True)
CNNでの学習結果
先ほどは、クラウド上で実行していましたが、次のスクリプトは最初のWindows環境で
実行しています。
# coding: utf-8
import numpy as np
import matplotlib.pyplot as plt
from keras.utils import np_utils
from keras.models import Sequential,model_from_json
from keras.preprocessing import image
from keras.applications.imagenet_utils import preprocess_input, decode_predictions
from keras.datasets import mnist
# 分類したクラス数
nb_classes = 10
# テストに用意した画像の枚数
test_num = 10
# mnistデータの読み込み
(X_train, y_train), (X_test, y_test) = mnist.load_data()
X_test = X_test.astype('float32')
# データを正規化
X_test /= 255
# バイナリのアレイに変換
Y_test = np_utils.to_categorical(y_test, nb_classes)
# モデルの読み込み
model = model_from_json(open('mnist_cnn_architecture.json').read())
# モデルの重みの読み込み
model.load_weights('mnist_cnn_weights.h5')
# アーキテクチャと重みを読み込んだ後に、モデルの評価を行う場合はコンパイルしないといけない
model.compile(loss='categorical_crossentropy',
optimizer='adadelta',
metrics=['accuracy'])
# モデルの評価
score = model.evaluate(X_test.reshape(-1,28,28,1), Y_test, verbose=0)
print(score)
for i in range(test_num):
# ファイル名の指定
img_path = str(i)+".jpg"
# 28ピクセルx28ピクセル、グレースケールで画像を読み込み
img = image.load_img(img_path, grayscale=True, target_size=(28, 28))
# 読み込んだイメージをアレイに変換
x = image.img_to_array(img)
# アレイサイズの確認
print(x.shape)
# クラスの予測
classified_label = model.predict_classes(x.reshape(-1,28,28,1))
# 予測結果のプロット
plt.subplot(2,5,i+1)
plt.imshow(img, cmap='gray')
plt.title("Class {0}".format(classified_label[0]))
plt.axis('off')
plt.show()
さて、畳み込みニューラルネットワークだと結果はどうなるかですが、このようになりました。Jupyter Notebookでの実行結果はGistにアップしています。

正解率的には、8割ですが、MLPで学習したものの結果と比べると、私の書いた数字の場合6と8・7と1は特徴は似ているので間違いやすいのかもしれません。また、既存の学習データに加えて私の書いたものも加えれば正解するのかもしれませんが、それについてはやる予定はないです。
おわりに
今回は、手書き文字MNISTの分類を行いました。学習・テストの結果は良かったものの、自分の書いた画像での正解率はいまいちでした。次回は、畳み込みニューラルネットワーク(CNN)の話をしようと思います。