はじめに
モチベーション
今回Qiita初投稿です。2019年11月現在、会社を休職して英国で1年間のデータサイエンスの大学院に通っているtomo.tです。
最近各種メディアで食べログが広告出稿店に対して有利になるような点数計算をしているのではないか、というような言説がwebをにぎわせていますね(例:https://togetter.com/li/1414193 )。
なぜ今回この記事を書こうと思ったかと言いますと、
- スクレイピングの練習
- 食べログヘビーユーザーとして実際どうなのか知りたい
「食べログは極めて優れたサービスである」という持論
食べログヘビーユーザー、と書きましたが、私は非常に食べログは優れたサービスと思っています。現在海外在住のため、食べログがないことが非常に不便でならないです。
海外に存在するレストラン評価サービスとしては、
-MichelinやGault Millauのようなプロの評価
-Trip AdvisorやYelp!、(あとGoogle map...)のような口コミサイト
の2種類があります。しかし、両方かゆいところに手が届かないという印象です。
前者は絶対評価としての信頼性は高いが、どうしても高級店に偏ってしまい、普段使いのお店を探すのには適さない。
後者はカバレッジが高いものの、評価のキャリブレーションができておらず(Yelp!はわかりませんが、少なくともTrip Advisorの点数はただの単純平均)、ランキングが信頼に値しません。結局旅行先でのお店を探す際には、日本人の口コミ(味覚が近いことが期待できるため)を探して定性的に評価するという極めて時間のかかる手続きになってしまっています。
その一方、食べログというサービスは両者の長所を併せ持っていて、口コミサイトとしての非常に高いカバレッジと絶対的な物差しとしての点数を提供してくれています。
点数計算の方法は非公表となっていますが、公表されている内容や経験則をもとに推測すると、
・信頼度(投稿数?ブックマーク数?)の高いレビュワーはウェイトが高い
・各レビュワーの点数基準をもとにキャリブレーション (甘いレビュワー、厳しいレビュワーを考慮)
・口コミの絶対数が少ないお店は評価が高くならない
といった要素が織り込まれているのではないでしょうか。
上記のように私は非常に食べログの点数を信用しているため、もしこれが課金という要素で上下されているとすると大問題です。
批判への批判
とはいえ、残念ながら先ほどのtogetterにある批判は、私を食べログから離れるよう納得させてくれるほど説得力があるものではありません。
上のtogetterでの重要な論点は
主張1「食べログに課金しないと3.6以上の点数がつかないのではないか」 <- とある飲食店?の経験則
主張2「実際に分布をみると3.6でガラスの天井があり、3.8にも壁があるようだ」 <- スクレイピング
というところにあるように見えます。
「課金すれば点数を上げると営業をかけられた」のような話は結局は言った言わないの水掛け論ですし、それが広告代理店のサクラの話なのか食べログのアルゴリズムの話なのか定かではないため、論点からは外します。
さて、それぞれの主張をみてみましょう。
主張1ですが、これはファクトとして反証できます。
食べログに課金しているお店は、下記のように見分けられます。
・「公式情報」マークが出る (これは課金していない準会員でも出る)
・大きい写真がトップページに掲載
・大きめのフォントで宣伝文句が掲載
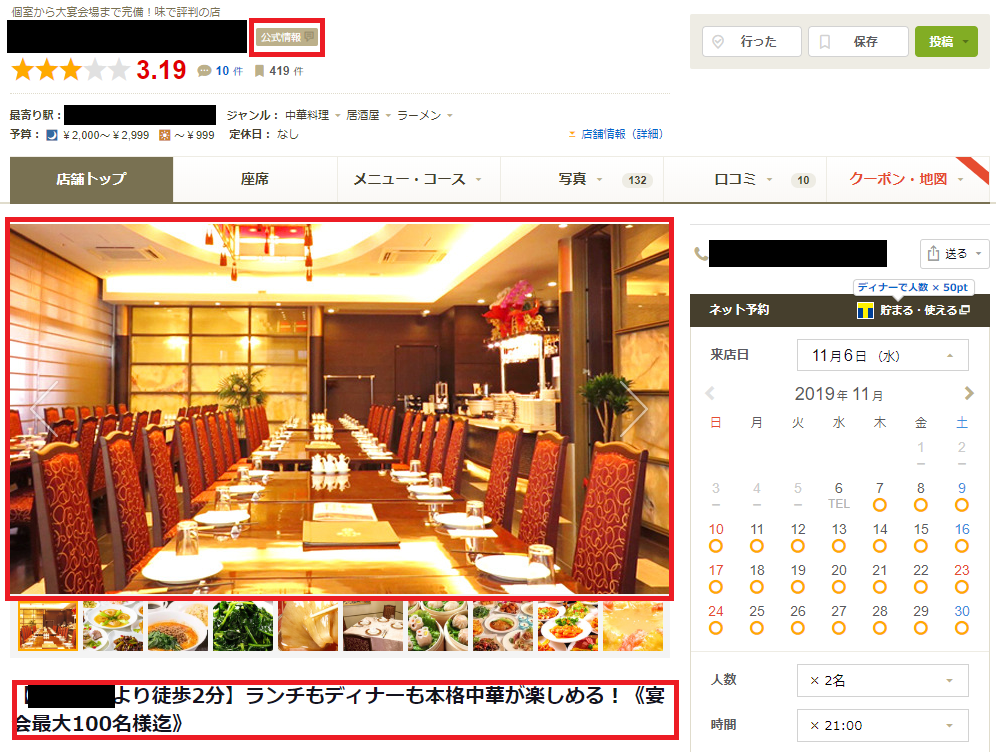
実際に食べログを見てみればわかりますが、高評価店には山のように課金機能を使用していないお店がありますので(例えば京味)、「食べログに課金しないと3.6以上がつかない」というのは間違っているのではないでしょうか。
主張2ですが、このグラフは逆に食べログの正当性を強調しているとも解釈できます。
皆さんご存知のように3.6オーバーというのはかなりの高評価店です。このクオリティを担保するために、3.6を超えるのが難しいアルゴリズムになっている。例えば、3.5から3.6に上げることは好意的な口コミを多少集めればできるが、3.6を超えるためには本当に多数の信頼できるレビュワーから高評価を得なければいけない、と設定されていると考えれば、このグラフは自然ですし、逆に食べログがリゴラスな評価をしてサクラ対策をしている証拠と言えるのではないでしょうか。
これは食べログに対してかなり好意的な解釈ですが、何が言いたかったかといいますと、ある数字というのは好意的にも批判的にも解釈可能なため、一面的な解釈をして一方的に食べログは点数を操作しているに違いないと決めつけるのは、少なくとも科学的な態度ではないのではないでしょうか。(これをQiitaの賢明なる読者の皆様に言っても釈迦に説法なのですが)
今回の検証内容
さて、最後に念のため今回検証したい「食べログ点数操作疑惑」を定義しておくと、「食べログの点数計算アルゴリズムには、その飲食店が食べログ有料会員であるかどうかがポジティブな形で織り込まれているのではないか」ということです。
この記事(https://news.nifty.com/article/magazine/12193-434794/) のように、プロレビュワーに好意的なレビューを書かせるというようなことは、おそらく実際に実行しようと思えば可能である上、web上での検証が非常に難しいため、今回の分析対象からは外しています。おそらく分析しようとすると、投稿数の多いユーザーで、他のレビュワーとはかけ離れた点数をつけることが多い人を探す、というような形になるのではないでしょうか。(それでも結局は個人の味の好みという話になってしまいますが。。)
手法
分析対象
今回ですが、東京のラーメン店を対象に分析を行います。
なぜ東京のラーメン店かというと、
・全国を網羅するには食べログサーバーへの負荷が高くなるうえ、東京のラーメン店だけで6000店以上あるためnとして十分
・値段のブレが少なく、純粋に味の評価といえる
・国民食であり、好き嫌いはあれど評価基準が比較的一貫している
・店舗の箱の大きさに大きなブレがない
という理由からです。
分析の手法
スクレイピングによるデータ収集
まず、スクレイピングで食べログから東京のラーメン店のデータを集めます。
個別のページに行くと色々知れるかもしれませんが、サーバー負荷と時間の問題で、ランキングの一覧ページからのみデータを集めました。
今回収集したいデータとしては、
・店名
・点数
・レビュー数
・課金の有無
です(理由は後述)。実際にはロケーション等も集めていますが、分析には使用していません。
コードを見ていただければわかると思いますが、今回2度のスクレイピングをしており、1度目で全ラーメン店のリストを作り、2度目で課金店舗だけのリストを作成しています。
まず全ラーメン店のリストですが、食べログのリスト機能の最大表示数は20店/ページ x 60ページ = 1,200店なので、「東京」でくくってしまうと6,000店以上ある全店舗のリストが取得できません。そこで、各エリアごとのランキングから東京の全ラーメン店のリストを取得しています。
課金の有無については、東京全体の「会員店舗優先順」リストを見ることで課金している店舗のリストを作ることができました。このリストの何番目まで課金しているかは食べログを目視(笑)で見つけています。
結果データの分析
さて、いよいよ分析です。
今回は点数をレビュー数と課金の有無で回帰することを考えます。
本当は実際のレビュー数のほかに、点数の分布とか単純平均とか入れたかったのですが、その取得には時間と負荷の問題があるのでやっていません。今回食べログから簡単に取得できる役に立ちそうな情報はこれしかなかった、とも言えます。Google mapの点数もAPI叩いて取得してみるとかはやってみていいかもですが、面倒なのと課金が必要なのでしていません。もし他にいいアイデアをお持ちの方はご教示いただくか、ぜひやって結果をQiitaのどこなにまとめていただけましたら幸いです。
このモデル、超超単純ですが、結局何が言いたいかというと、おいしいお店ほど人気でレビューが沢山つくはずだ。その効果を差し引いたときに、課金の有無で点数は違うのか、というのを見ています。
これはなぜかというと、さらに単純なアプローチ、たとえば課金しているグループとしていないグループの平均点や点数分布を比べるという手法はうまくいかないからです。
もし仮に課金グループは非課金グループより点数が高い、という結果を得たとしましょう。これは食べログが点数を操作していることを示しているのでしょうか。答えは否で、これは純粋に「課金の有無と点数には正の相関がある」ことしか言っていません。解釈としては次の四通りくらいがありえると私は思っていて、どれであるかを議論することができません。
1.食べログが課金店舗の点数を恣意的に上げている
2.食べログの課金効果は大きく、お客さんを呼べている。その結果レビュー数が稼げて点数計算アルゴリズム上有利になり、高い点数を得ている
3.食べログは点数が高い(=食べログに好意的であろう)店舗に優先的に営業をかけている
4.繁盛していないと食べログに課金できない
しかし、今回レビュー数(~来客数、人気度)という指標でコントロールすることで、「課金の広告効果」という2の仮説を排除することができます。もし課金の有無の係数が有意に正であったとしましょう。それが意味するのは「課金しているお店は、人気度の割には点数が高い」ということであり、課金により人気度が上がっているという因果関係を排除できています。4の仮説も同様です。
また、3の仮説についても、「レビューが少ない割には点数が高いお店に営業を優先的にかける」というのはビジネス的に若干不自然な解釈なのではないかと感じています。(そういうお店はわざわざ食べログに課金せずともお客さんを呼べそうなため、自分が営業であれば逆の店を優先するはず。。)
また、細かいですが重要な点として、回帰するデータポイントから、以下のお店を外しています。これは、価格帯、知名度等の観点からラーメン店はほぼ横比較可能であるはずだ、という仮定に反してしまうためです。
・大規模チェーン店 (具体的には東京に9店舗以上あったチェーン店を外しました。それ以下の規模は私が名前を見てもピンとこないチェーンだったため、個人営業と変わりないと考えています)
・名前に「中華料理」「餃子」と入る、おそらくラーメンが主体ではない店舗
また、レビュー数が10件未満と、レビュー件数が少なすぎるせいで食べログ的に点数が高く出ないことが確定してしまっているような店舗も外しています。
スクレイピングコード
以下が今回使用したコードです。
人に見せるつもりで当初書いていなかったので美しくないですし、非効率や関数の正しくない使い方等あると思います。
今回ハマった点は、ファイルの書き出しで。飲食店は難しい漢字や英語にないアルファベットなど変わった文字を店名に使いがちなので、何度もエンコーディングのエラーを起こしました。結論としては、csvではなくexcelにutf-8で書き出せば問題なく書き出せ、Rなど他のソフトウェアからも読み込めました。
import requests
from bs4 import BeautifulSoup
import pandas as pd
directory = '' #適当に指定
file_name = 'ramen_tokyo.xlsx'
output_file = directory + file_name
page_n_s = 1
r_name_list = []
r_rank_list = []
r_link_list = []
r_rate_list = []
r_loc_list = []
r_pref_list = []
r_zone_list = []
r_nreview_list = []
pref_id = 13
pref_name = '東京'
num_zone = 30
zone_name_head = 'のラーメンのお店'
max_page = 60
for zone_n in range(1,num_zone+1):
link = 'https://tabelog.com/tokyo/A'+str(pref_id).zfill(2)+str(zone_n).zfill(2)+'/rstLst/MC/1/?Srt=D&SrtT=rt&sort_mode=1'
result = requests.get(link)
c = result.content
soup = BeautifulSoup(c, "html.parser")
tot_rest_soup = soup.find_all("span", class_ = "list-condition__count")
tot_rest = int(tot_rest_soup[0].text)
page_n_f = min((tot_rest-1)//20+1, max_page)
zone_name_soup = soup.find_all("strong", class_ = "list-condition__title")
zone_name = zone_name_soup[0].text
zone_name = zone_name[:-len(zone_name_head)]
rank = 1
for page_n in range(page_n_s, page_n_f+1):
link = 'https://tabelog.com/tokyo/A'+str(pref_id).zfill(2)+str(zone_n).zfill(2)+'/rstLst/MC/'+str(page_n)+'/?Srt=D&SrtT=rt&sort_mode=1'
result = requests.get(link)
c = result.content
soup = BeautifulSoup(c, "html.parser")
#Rank, Name, URL
try:
r_bs_lists = soup.find_all("a", class_ = "list-rst__rst-name-target cpy-rst-name js-ranking-num")
for elem in r_bs_lists:
r_name_list.append(elem.text)
r_rank_list.append(rank)
r_link_list.append(elem.get('href'))
print(str(rank)+":"+elem.text)
rank+=1
except:
print(str(page_n) + " does not exist")
#Rating
try:
r_bs_lists = soup.find_all("span", class_ = "c-rating__val c-rating__val--strong list-rst__rating-val")
for elem in r_bs_lists:
r_rate_list.append(elem.text)
except:
print(str(page_n) + " does not exist")
#Location
try:
r_bs_lists = soup.find_all("span", class_ = "list-rst__area-genre cpy-area-genre")
for elem in r_bs_lists:
loc_str = elem.text
r_loc_list.append(loc_str)
except:
print(str(page_n) + " does not exist")
#review
try:
r_bs_lists = soup.find_all("em", class_ = "list-rst__rvw-count-num cpy-review-count")
for elem in r_bs_lists:
n_review = elem.text
r_nreview_list.append(n_review)
except:
print(str(page_n) + " does not exist")
if len(r_rate_list)<len(r_rank_list):
k=len(r_rank_list)-len(r_rate_list)
for j in range(k):
r_rate_list.append("None")
if len(r_loc_list)<len(r_rank_list):
k=len(r_rank_list)-len(r_loc_list)
for j in range(k):
r_loc_list.append("none")
if len(r_nreview_list)<len(r_rank_list):
k=len(r_rank_list)-len(r_nreview_list)
for j in range(k):
r_nreview_list.append("-")
while len(r_pref_list)<len(r_rate_list):
r_pref_list.append(pref_name)
r_zone_list.append(zone_name)
df = pd.DataFrame({'restaurant_name': r_name_list, 'rank': r_rank_list, 'tabelog_link': r_link_list, 'rating': r_rate_list, 'location': r_loc_list, 'prefecture': r_pref_list, 'zone': r_zone_list, 'num_review': r_nreview_list })
df.to_excel(output_file, index = False, encoding="utf-8")
page_n_s = 1
# 手動で見た広告出稿店と非出稿店の境界
page_n_f = 19
restaurant_n_f = 6
restaurant_in_a_page=20
end_rank = (page_n_f-1)*restaurant_in_a_page + restaurant_n_f
pr_name_list = []
pr_link_list = []
rank=1
for page_n in range(page_n_s, page_n_f+1):
link = 'https://tabelog.com/tokyo/rstLst/MC/'+str(page_n)+'/'
result = requests.get(link)
c = result.content
soup = BeautifulSoup(c, "html.parser")
try:
r_bs_lists = soup.find_all("a", class_ = "list-rst__rst-name-target cpy-rst-name")
for elem in r_bs_lists:
pr_name_list.append(elem.text)
pr_link_list.append(elem.get('href'))
rank += 1
if rank == end_rank:
break
except:
print(str(page_n) + " does not exist")
file_name = 'ramen_tokyo_pr.xlsx'
output_file = directory + file_name
df2 = pd.DataFrame({'restaurant_name': pr_name_list,'tabelog_link': pr_link_list})
df2.to_excel(output_file, index = False, encoding="utf-8")
分析用のコード
念のためRで結果を分析したコードも載せておきます。
library(openxlsx)
library(dplyr)
# データの読み込み
data <- read.xlsx("ramen_tokyo.xlsx")
data_pr <- read.xlsx("ramen_tokyo_pr.xlsx")
data_pr$pr <- 1
data_pr <- data_pr[,c(2,3)]
data <- dplyr::left_join(data , data_pr ,by="tabelog_link")
data$pr[is.na(data$pr)] <- 0
data$rating <- as.numeric(data$rating)
data$num_review <- as.numeric(data$num_review)
# 除くデータポイントの設定
data$exclude <- 0
exclude_key = c("中華料理","餃子","日高屋","王将","幸楽苑","一蘭","一風堂","天下一品","スガキヤ","くるまや","花月","来来亭","山岡屋","壱角家","じゃんがら","ちりめん","舎鈴","福しん","せい家","三田製麺所","太陽のトマト麺","博多風龍","武蔵家","蒙古タンメン中本","俺流塩らーめん","どさん子","揚州商人","麺屋武蔵","野郎ラーメン","TETSU","らーめん大","東京油組","つじ田","魁力屋","大勝軒","博多天神","味噌一","由丸","XI’AN","江川亭","万豚記","AFURI","春樹","田中そば店","野方ホープ","珉珉","リンガーハット")
for(elem in exclude_key){
data$exclude[grepl(elem,data$restaurant_name)] <- 1
}
review_threshold <- 10
data$exclude[data$num_review < review_threshold] <- 1
ramen <- data[data$exclude==0,]
# ヒストグラム描画
hist(ramen$rating)
hist(ramen$rating, col = "#ff00ff40", border = "#ff00ff")
hist(subset(ramen, pr==1)$rating, col = "#0000ff40", border = "#0000ff",add=TRUE)
# 散布図描画
ramen_pr <- subset(ramen, pr==1)
ramen_no_pr <- subset(ramen, pr==0)
plot(log10(ramen_no_pr$num_review),ramen_no_pr$rating, col="blue")
points(log10(ramen_pr$num_review),ramen_pr$rating, col="red")
# モデル作成
model <- lm(rating ~ num_review + pr, ramen)
summary(model)
model2 <- lm(rating ~ log10(num_review) + pr, ramen)
summary(model2)
結果
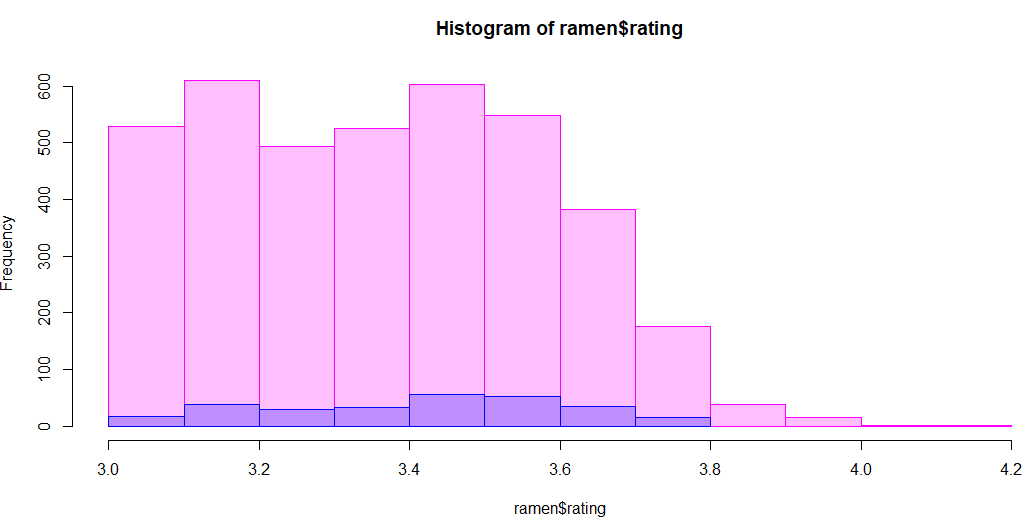
まずはじめに、点数の分布を全体と課金店舗で比較してみた図が下のグラフです。横軸に点数を0.1刻みでとり、縦軸が店舗数です。ピンクが全体で、青がそのうちの課金店舗です。
割合など計算してみたくなりますが、計算はこれから来る回帰式に任せてまずこのグラフだけ眺めてみると、そんなに違和感は感じないのではないでしょうか。少なくとも、課金店舗だけとても右(高得点)に寄った分布になっているようには見えません。
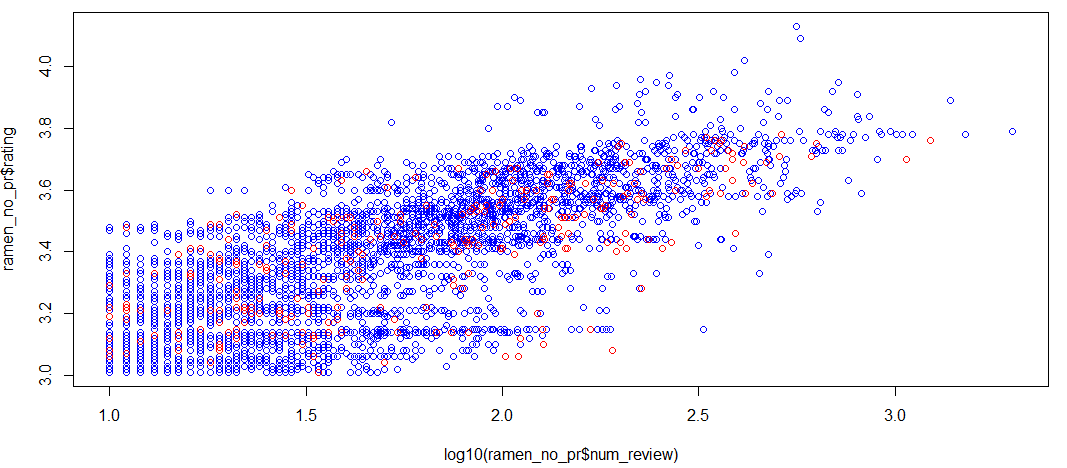
次に、レビュー数と点数の関係です。各店舗が点に対応しており、赤が課金店舗、青が非課金店舗です。横軸がレビュー数の常用対数で、縦軸が点数です。
これを見ると、当初の仮説通り、レビュー数と点数には正の相関があるような気がしてきますね。どうやら人気店ほどレビューが増え、点数も高い、という図式は大まかには成り立ちそうです。
さて、最後にお待ちかねの回帰式です。レビュー数の対数を取った方が$R^2$が高かったため、そちらを採用しています。
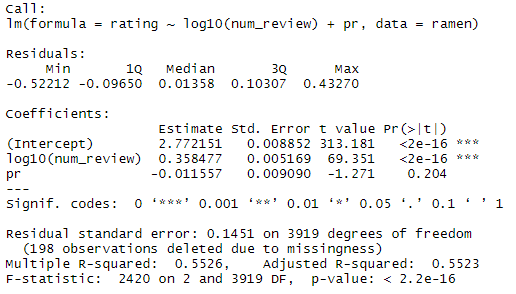
なんと、課金の有無は点数には影響していないという結果が得られました。課金の有無の係数がプラスどころか-0.01となっている上、p値が0.204と有意ではないので、この分析の範囲内では課金の有無によって食べログが点数を恣意的に操作しているとは言えないという結論が得られたのではないでしょうか。決定係数も0.55と、実質1変数しか効いていない割には高くなっているのが驚きです
おまけ:課金とレビュー数は相関しているか
ちなみに、課金の有無とレビュー数の関係性を見るために下記のコードを実行しています。
最初に両群の平均値を確認した後、マン・ホイットニーのU検定でその差が有意かを検証しています。
mean(ramen_pr$num_review,na.rm=TRUE)
mean(ramen_no_pr$num_review,na.rm=TRUE)
wilcox.test(ramen_pr$num_review,ramen_no_pr$num_review,paired=F)
その結果がこちらで、
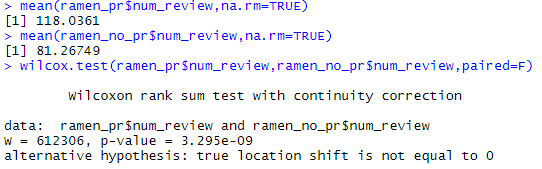
どうやら有意に課金店の方がレビュー数が多いようですね。
解釈の余地としては、
- 食べログが課金店のレビューは掲載されやすくしている/非課金店のレビューを削除している
- 食べログの課金広告効果が出ている
- 繁盛している店でないと食べログの広告費が払えない
などあり、食べログの陰謀論を論じることは難しいのではないでしょうか。個人的には3の解釈がもっともしっくりきます。
まとめ
・今回の分析からは、食べログが課金の有無によって点数を恣意的に操作していることへの積極的な証拠は得られなかった。むしろ、課金の有無は点数の計算式に直接的には影響していないことが示唆された
・一方、例えば課金店舗へは有効なレビューを増やしたり、批判的なレビューを削除するといった方法での点数操作も可能ではあるため、この結果が完全な潔白を意味するところではない
・とりあえず当面は食べログを参考にし続けます
・一本の記事を書くのに相当疲れたので、日常的に投稿されている皆さんを尊敬します