はじめに
4月23日にメルカリ 澁井氏(@cvusk )により、機械学習システムのデザインパターンについてのブログポスト、および実ドキュメントがGitHub Pages公開されました。
また、氏の「データ分析基盤Developers Night #4 〜活用されるデータ基盤のつくり方〜」における「メルカリのデータ分析を支える機械学習システムのデザインパターン」の発表が、
にあり、併せて視聴すると、どのように設計パターンという発想に至ったか、またメルカリにおける設計パターン活用の実例に触れられます。
には、ご本人により、こうした機械学習のエンジニアリング、アーキテクチャ面の参考リンクがまとめられています。この設計パターンを読みながら、併せて活用できます。
こうした知見をまとまった形で公開いただいたことに感謝です。
機械学習システムの設計パターン 構成
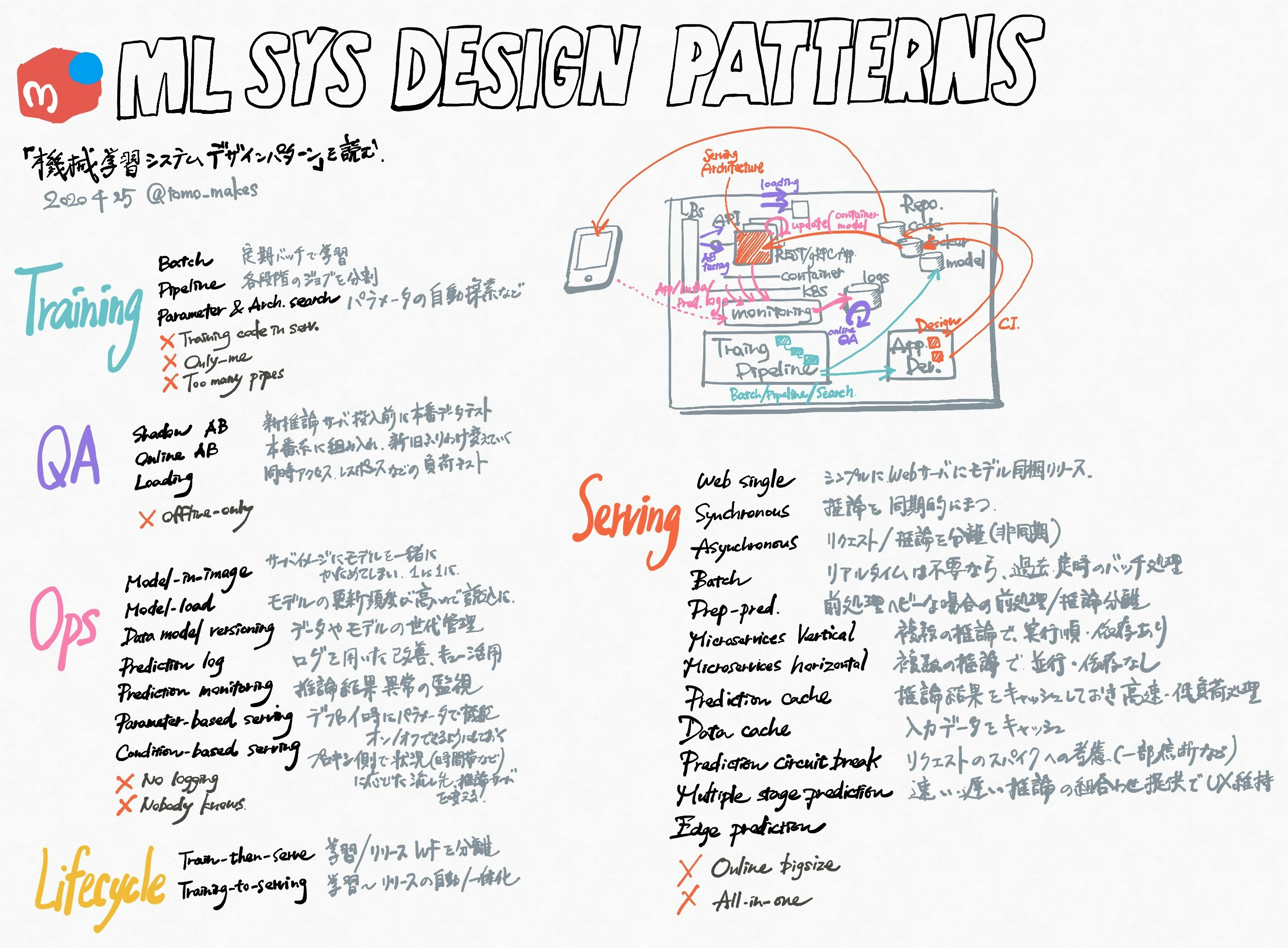
以下の5つの視点からまとめられています。特に、システムの現場の運用からの知見がちりばめられている、Serving, Opsは、情報量が多いです。
- Serving 推論器を本番システムに組み込むパターン集
- Training 学習パイプラインの作り方
- QA テストや品質保証の方法
- Ops モデルやシステムの運用方法
- Lifecycle 各パターンを組み合わせた機械学習システムの全体構成
ざっくりまとめ
まだざっと通読したところなのですが、自分の2回目以降、あと人と話をするときのため、簡単なサマリを作りました。
Serving 推論器を本番システムに組み込むパターン集
利用シーンと制約に合わせたデプロイパターンが紹介されています。
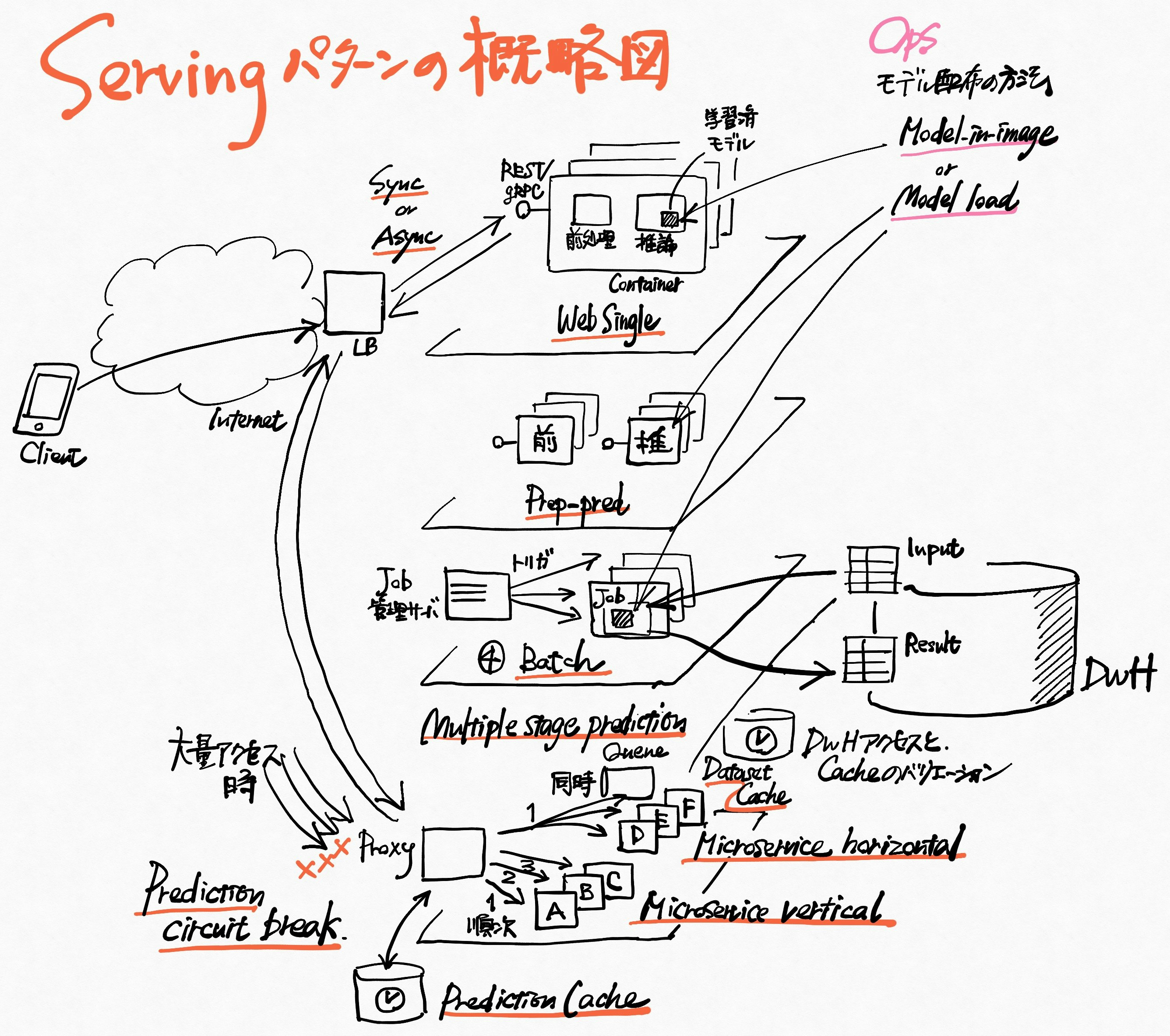
- Web single シンプルにWebサーバにモデル同梱リリース
- Synchronous 推論を同期的に待つ
- Asynchronous リクエスト・推論を分離(非同期)
- Batch リアルタイムは不要なら、過去・定時バッチ処理
- Prep-pred 前処理ヘビーな場合の前処理・推論分離
- Microservices vertical 複数の推論で、実行順・依存あり
- Microservices horizontal 複数の推論で、並列・依存なし
- Prediction cache 推論結果をキャッシュしておき高速・低負荷処理
- Data cache 入力データをキャッシュ
- Prediction circuit break リクエストのスパイク考慮(一部遮断等)
- Multiple stage prediction 速い・遅い推論の組合せ提供でUX維持
- Edge prediction
Training 学習パイプラインの作り方
バッチ、パイプライン化、パラメータやアーキテクチャサーチをパターンとして取り上げています。
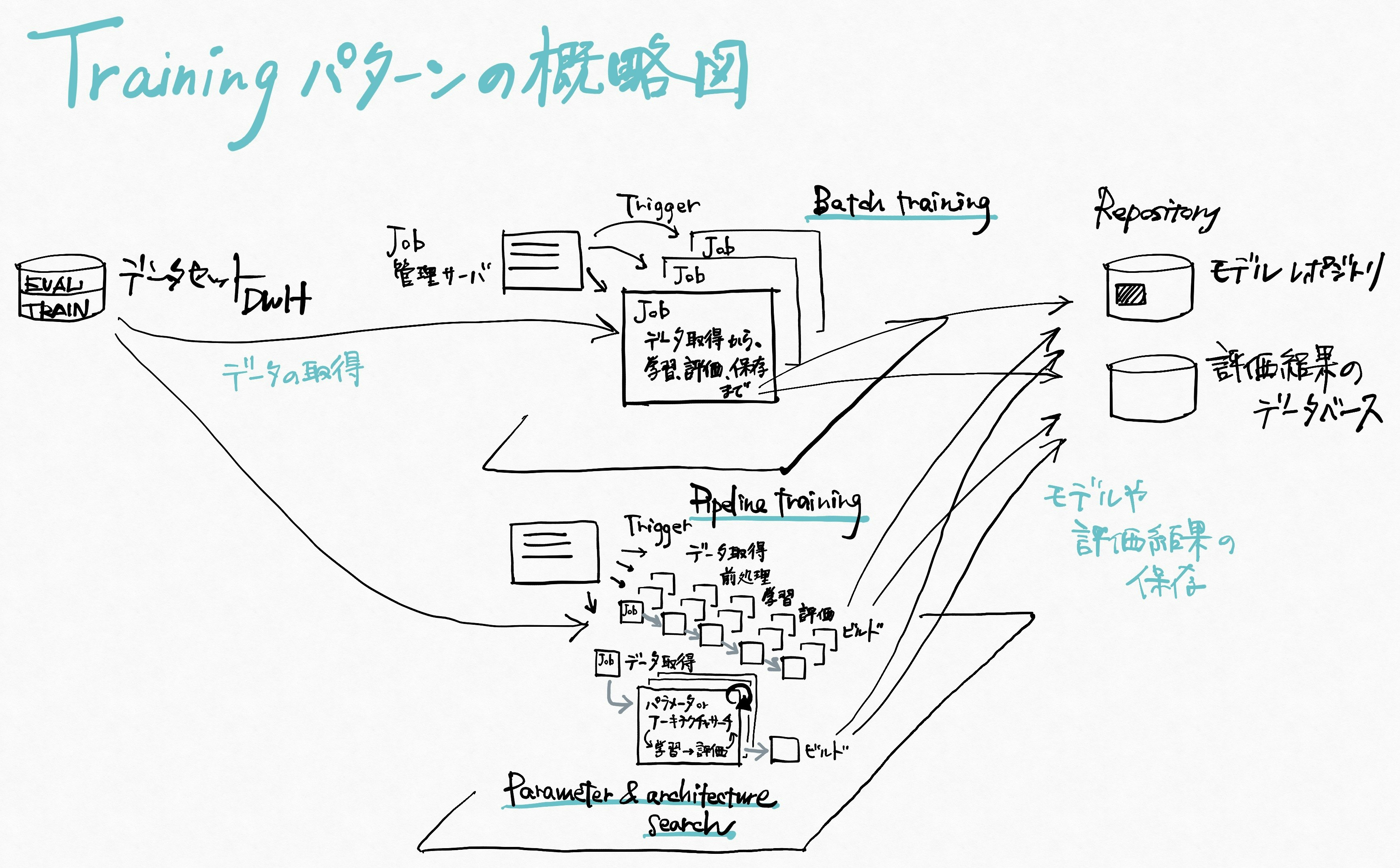
- Batch 定期バッチで学習
- Pipeline 各段階のジョブを分割
- Parameter and architecture search パラメータの自動探索等
QA テストや品質保証の方法
主に本番環境投入前、または段階的投入のテストパターンが紹介されています。
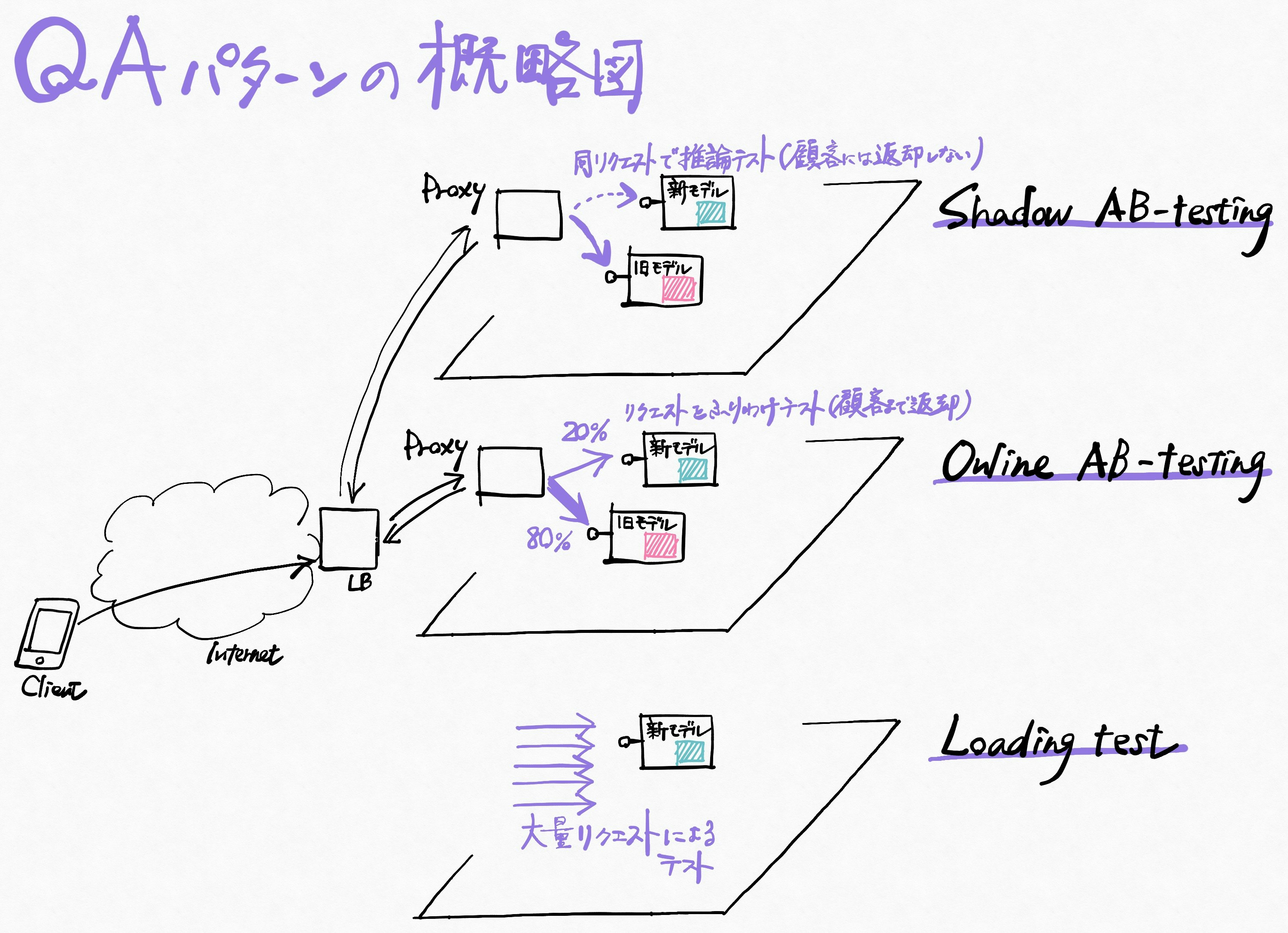
- Shadow AB test 新推論サーバ投入前に本番データでテスト
- Online AB test 本番系に組み入れ、新旧振分けをプロキシで変えていく
- Loading test 同時アクセス、レスポンス等の負荷テスト
Ops モデルやシステムの運用方法
Servingと連携する部分がありますが、デプロイした後の監視、および運用上の工夫がまとめられています。
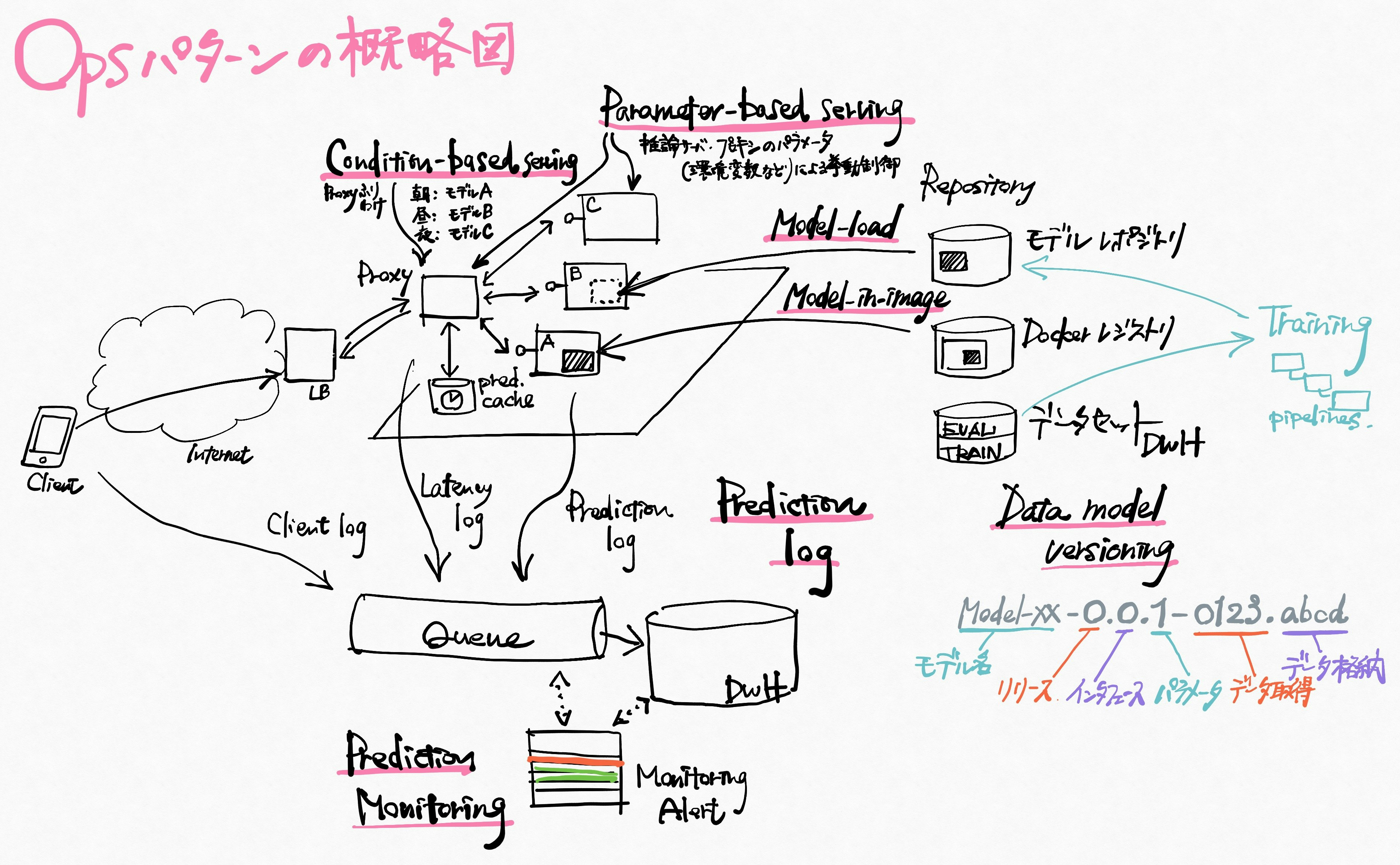
- Model-in-image サーバイメージにモデルも一緒にかためてしまう
- Model-load モデルの更新頻度が高いので読込とする
- Data model versioning データやモデルの世代管理
- Prediction log ログを用いた改善、キューの活用
- Prediction monitoring 推論結果、異常の監視
- Parameter-based serving デプロイ時にパラメータで機能オン・オフできるようにしておく
- Condition-based serving プロキシ側で状況(時間帯等)に応じて流し先、推論サーバを変える
Lifecycle 各パターンを組み合わせた機械学習システムの全体構成
- Train-then-serve 学習とリリースのワークフローを分離
- Training-to-serving 学習からリリースの自動・一体化
おわりに
同設計パターンは英語版も公開されています。また、 https://github.com/mercari/ml-system-design-pattern にてContribution(PR)が受け付けられています。