本内容は、技術書典7 合同本『機械学習の炊いたん2』収録の、「エッジで機械学習」記事を公開したものです。内容は2019年9月時点の調査等に基づきます。
最近Raspberry Pi 4の検証結果などをみていると、エッジ、かつCPUでもそれなりの速度で動くケースもみられます。またこの後にM5StickV(K210)などを触りましたが、専用チップも使い所があります。今後、それらの動きもできれば補足したいと思います。
9/12-22に開催された技術書典9では、新刊『機械学習の炊いたん3』を頒布しました。私は、「AIエンジニア、データサイエンティストのための経営学、ソフトウェア工学」を寄稿しています。他にも機械学習のビジネス、エンジニアリング、数理までもりだくさん。気になられたら、ぜひご覧ください!
他にも、技術書典9「機械学習、データ分析」系の新刊リスト - Qiitaの通り、たくさんの本が出品されています!
はじめに
なぜエッジ?
エッジコンピューティングという言葉が、機械学習・IoTの実課題への適用と普及と共に注目を集めています。「データの発生元する場所に、より近いところで機械学習などの処理を適用する」ことで、「従来のクラウド処理では行えなかったことを行う」 というコンセプトです。
エッジデバイスで機械学習という文脈で、2019年3月に相次いで面白いハードウェアが発表されました。NVIDIAのJetson Nano、そしてGoogleのEdge TPUです。発表後の反響は大きく、しばらくは品薄が続きました。春から夏にかけて徐々に入手し易くなっています。筆者もそれぞれ1台手に入れました。
注目の高まりから、同時期に様々なイベントや勉強会が開催されています。筆者も以下に参加しました。それぞれ紹介先のURLには、発表資料やレポートが公開されています。
2019年6月 TensorFlow User Group ハード部 Jetson Nano, Edge TPU & TF Lite micro 特集
https://tfug-tokyo.connpass.com/event/133310/
2019年7月 インタフェース誌 「エッジAIモダン計測制御の世界」オフ会
https://inteface-meet-up.connpass.com/event/135573/
2019年7月 ML@Loft #4 Edge
https://aws.amazon.com/jp/blogs/startup/event-report-ml-at-loft-4/
その過程で、ばらばらだったエッジの知識、FPGAへの興味、その他がつながりはじめました。
本章でわかること
本章は、以下の構成で進めます。
- まずエッジへの注目の高まりとその背景、構成要素を概観する
- エッジ特有の課題、それに対処する研究を紹介する
- ソフトウェアへの実装、サービスを紹介する
エッジの分野は移り変わりがまだ早く、それぞれ断片的に紹介された情報はありますが、関係性を読み解くことがときに難しいと感じます。これを読むことで、実際に動いているプロジェクトの例などをこれから収集し、整理されるときに、頭の中に一定の地図が作れれば良いな、と思って書いています。
余談ですが、姉妹本である『30日で動かしてわかる! 自動運転』(0.8版)で取り上げるのも、「エッジ」の応用のひとつです。DonkeyCar、DeepRacerなどの自律走行ラジコンカーから、本物の車の自動運転について詳しく掘り下げています。特に自動運転に特化した文脈の「エッジ」は、ぜひそちらを手に取ってみてください。
エッジデバイスとは
機械学習モデルを動かすエッジデバイスと聞くと、具体的に何を思い浮かべるでしょうか。
2019年、エッジデバイス百花繚乱
冒頭でJetson Nanoや、Edge TPUについて話しました。2019年現在、それ以外にも様々なものが、実際に動いています。

2019年3月には、NVIDIA Jetson Nano、Google Edge TPUといった評価用のボードが相次いで発表されました。それぞれ1万円前後か、それを切る価格帯です。これまではRaspberry Piなどの小型コンピュータで、実験レベルでしか行えなかった内容を高速化し、対応できるユースケースの幅が広がりました。
エッジの広がりと、その意味
そもそも、エッジとは何でしょうか。
**「データの発生元する場所に、より近いところで機械学習などの処理を適用する」ことで、「従来のクラウド処理では行えなかったことを行う」**と冒頭述べました。その実現には、クラウド側とデバイス側の計算をどう分担・協調させると対象ユースケースに最適かを設計、適用する必要があります。クラウドと対照し、スマートフォン、組み込み機器などのデバイス側を指します。広義では、そうした機器だけでなく、みなさんのPCのWebブラウザ上で実行することも「エッジ」と言えるでしょう。
ひとつ例を考えてみましょう。みなさんのご自宅にスマートスピーカーはあるでしょうか。Google Homeでも、Amazon Echoでも、何でも構いません。
スマートスピーカーを起動する時には「オーケー、グーグル」などと、あらかじめ決めたフレーズで呼びかけます。一般に、起動のための音声の認識は、スピーカー側に持っているモデルで行います。起動コマンドを含む音声が届くと、スピーカー側のモードが変化します。一定時間の音声を録音し、ストリームでクラウド側の音声認識APIに問い合わせ始めます。その結果、クラウド側で「今日のニュースは?」と言ってる!などと認識します。その結果がスピーカー側に返却されると、スピーカは「ラジオを再生すれば良いんだな」と分かり、ラジオニュースの再生を始めます。
「常時起動し、クラウドに音声を送り続けても良いのでは?」とも考えられます。なぜそうしないのでしょう。
少し考えると、
- 常に家の音声がだだ漏れになる(プライバシーの問題)
- 常にクラウド側と通信が必要(通信量・料金の問題)
- 常にクラウド側での計算が必要(計算資源の問題)
- タイムリーに応答が返せない(リアルタイム性の問題)
色々な問題がありそうです。
クラウドがあればそれで良い、エッジがあればそれで良い、というものではありません。クラウド側では、一定潤沢なリソースを共有して使えます。それがクラウドの本質です。リソースを共有することで遊休部分を減らし、より経済的に提供・調達できます。しかし、エッジ側では、その端末の限られた計算資源を使い処理を完了させる、または、クラウド側へ処理をオフロードする、となります。そうした制約のあるエッジですが、データの発生元に近いところで処理をすることで、クラウド側では得られないメリットがあります。
- 生データを扱うことは現地で完結させられる(プライバシー、セキュリティの利点)
- クラウド側と通信が不要(通信量・料金の利点)
- 一度モデルを配信すればクラウド側での計算が不要(計算資源の利点)
- タイムリーに応答が返せる(リアルタイム性の利点)
先ほど挙げた、スマートスピーカー事例を、ただ言い換えたものです。
また、スマートスピーカーのような機器だけでなく、みなさんの普段使うスマートフォンアプリも、当たり前にスマートフォン側の処理、クラウド側の処理を分担させ、最適なUXを実現しています。例えば、動画アプリで、快適性を損なわないため、全てをダウンロードしてから再生するのではなく、一定ダウンロードしたら再生を始める、先読みをしておく、といったことです。このように、クラウド側とデバイス側の計算をどう分担・協調させると対象ユースケースに最適か、は以前からある課題です。
達成したい目的に合わせて、どのように組み合わせて使うと最適かを、その都度設計します。その実装にあたっては、以下に気をつける必要があります。
- 環境入力をエッジデバイス(スマートフォン、組み込み機器)でどの程度処理するか
- どの程度詳細の結果をクラウド側に送り、その後連携するか
- クラウド側で学習したモデルをデバイス側にどう送るか
それにあたって、エッジデバイス側には、クラウド側と異なる固有の問題があります。
- 計算資源
- 電源
現状、エッジデバイスで機械学習を動かす、と言う時には、基本「学習」は別(クラウド側等)で行い、学習済みモデルを使った「推論用途」に使います。
さて、これらの課題に個別に対応していては効率が悪いものです。エッジに特化したフレームワークが生まれ始めました。その意味をより深く理解するため、まずこれまでの機械学習およびフレームワークの発展、エッジデバイスでの機械学習における「登場人物」を整理してみましょう。
クラウド、エッジそれぞれでの機械学習
機械学習・深層学習熱の高まり
機械学習の今日のブームで、いつも引用される2012年の出来事があります。ImageNet画像データセットを使った画像認識のコンペ(ILSVRC 2012)における機械学習モデルの躍進です。従来モデルに大差で圧勝して有用性が認識され、2010年代半ばにかけ画像を皮切りに、自然言語、音声、様々な分野で研究が盛り上がります。2015-16年は、TensorFlowなどの機械学習の研究開発用フレームワークが相次いで発表、成長しました。その後、実アプリケーションへの適用を視野に、モデルの軽量化などの研究が進みました。2018-19年は、実際にそうした成果が研究段階からいよいよフレームワークに実装され、製品に搭載され始めました。
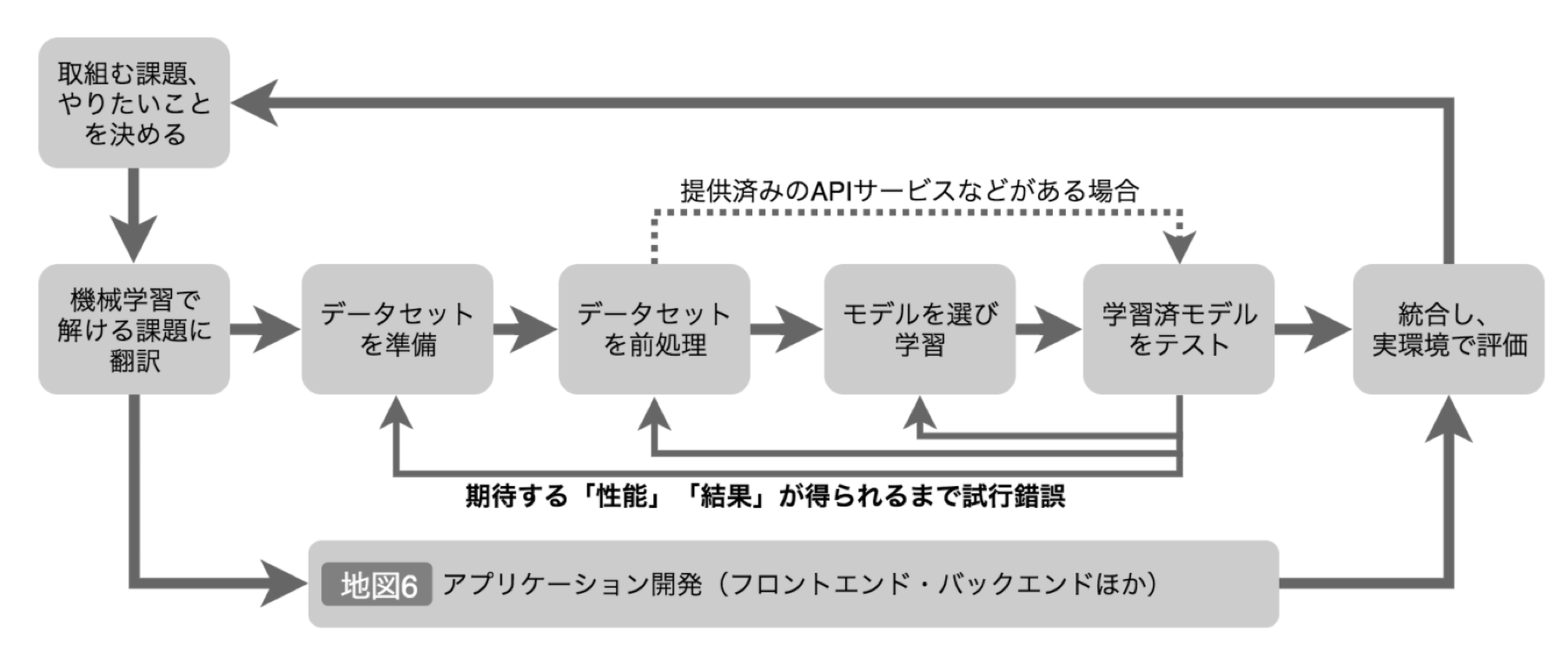
機械学習プロジェクトの流れ
機械学習プロジェクトは、以下の流れで進みます。エッジを考慮するのは、この中でもアプリケーション開発、および統合し実環境で評価する、というフェーズです。
機械学習の適用ユースケース
Paper with code( https://paperswithcode.com/ )というWebサイトがあります。以下のような適用ドメイン別に、今日での最高精度を誇るモデルと、それを生み出した論文、それだけでなく実装の公開場所までがまとめられています。
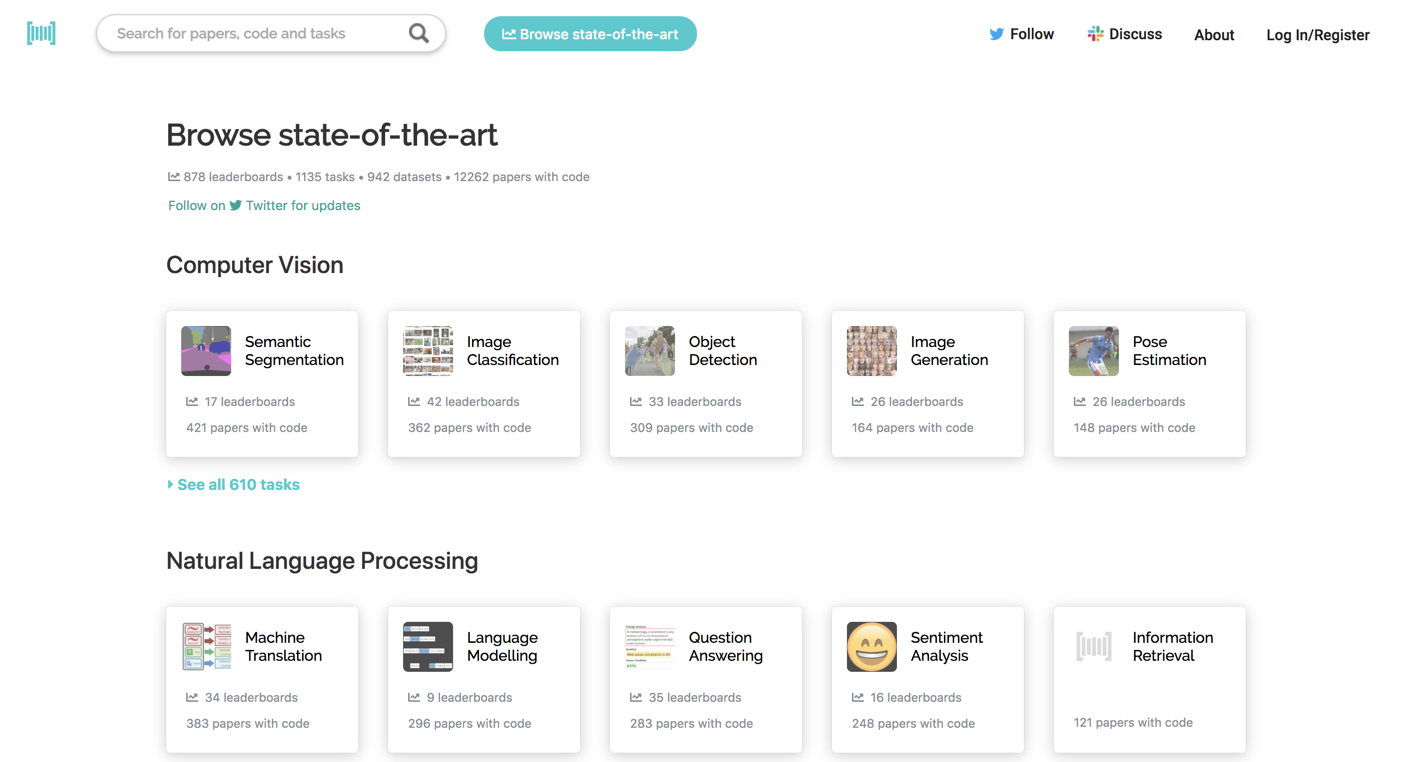
では、適用したい課題に合致するモデルがあれば、こういったサイトでそれを発見し、それをエッジ機器に入れて動かせば終わりなのでしょうか。
いいえ、その前に色々と考えておくべきことがあります。
エッジでの機械学習をとりまく部品
機械学習を適用したエッジ製品、スマートフォンアプリを使っている時、利用者の目には、そのデバイスやスマートフォンしか目に入りません。ですが、その後ろには多くの場合、リアルタイムで、または定期的に協調しているクラウド側があるケースが多いです。データセットの準備や前処理、学習から推論まで、すべてがエッジでは完結しないためです。一般に、相互に接続された以下が、登場人物として出てきます。
- エッジデバイス
- クラウド
- ネットワーク
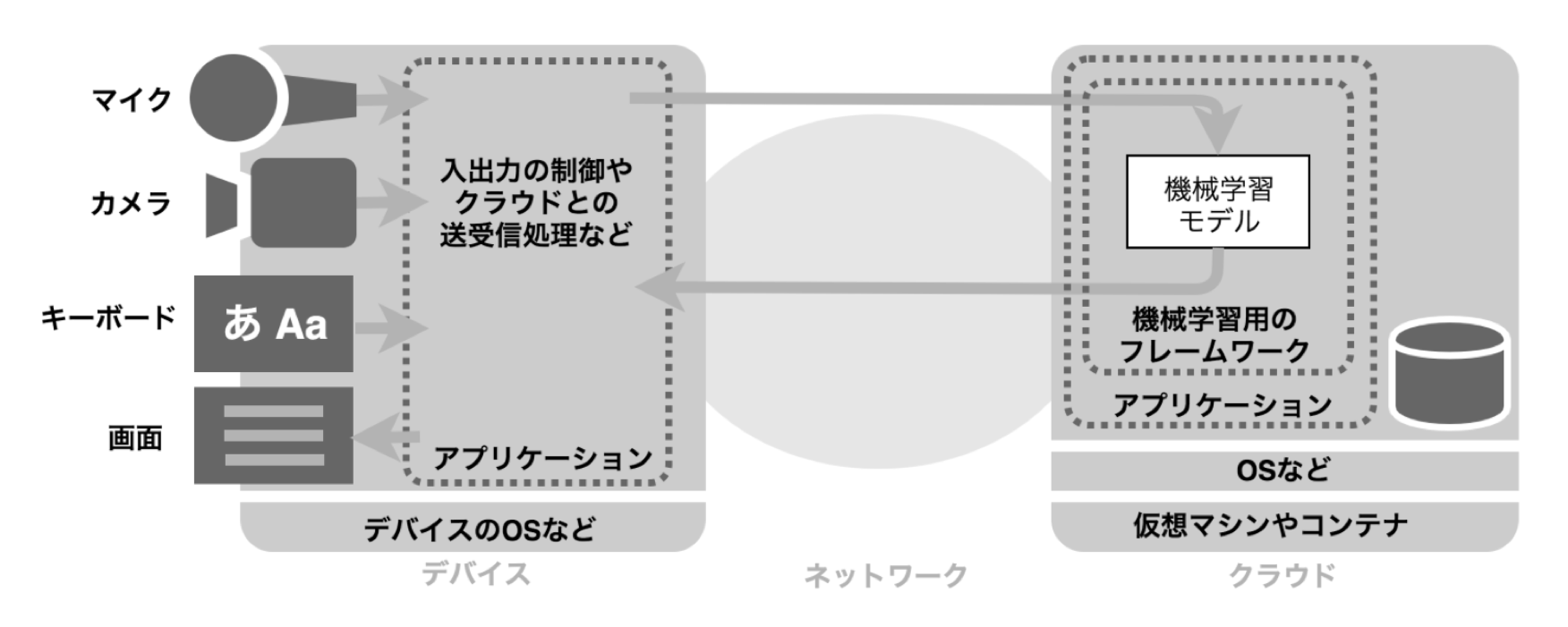
上の図ではクラウド側にモデルを持ち、推論をそちらへオフロードしていますが、エッジでの機械学習では、モデルをエッジデバイス側に持つ選択肢もあります。また後半は、そのための最適化・フレームワークについて取り上げます。
また、特にエッジデバイス、クラウドにはそれぞれ以下の構成要素があります。
- ハードウェア(CPU、GPUなどの集積回路を含む)
- ソフトウェア(機械学習用フレームワークを含む)
- それらを扱うプロセス(構築、運用など)
エッジデバイスでの機械学習をうまく扱うため、それぞれの特徴と役割を把握しましょう。
エッジデバイス
用途に応じて、多種多様なデバイスがあります。組込用途、スマートフォン、Webブラウザも広義ではここに含まれます。スマートフォン向けに、AppleやGoogleがそれぞれ、機械学習向けのフレームワークを提供しています。2010年代後半に進んだ、エッジ推論向けのモデル軽量化の研究が、すでに生かされています。
ネットワーク
基本はインターネットと考えて良いでしょう。ビジネス向けや特定用途では、VPNも選択肢に挙がるかもしれません。プロジェクト個別の要件次第です。デバイスからインターネットに到達するまでにモバイルネットワーク(SIM)を使う場合、アップロード/ ダウンロードの通信量と、そこに対する課金が重要な要件です。MVNO事業者によって、映像などの大量アップロード(ストリームで送るなど)に最適な料金プランを設けるケースもあります。
クラウド
多くの場合、AWS、GCP、Azureその他のパブリッククラウドを用いるでしょう。仮想マシン(VM)やコンテナを使うこともできますし、ここ1-2年に整備が進んだMLaaS(Machine Learning as a Service)も使えます。
エッジデバイスのソフト、ハード、プロセス
エッジデバイス、クラウド共、ハードウェア、動作するソフトウェア、運用のためのプロセスが必要です。
ハードウェア
ハードウェアを構成するのは、主に以下です。
- 実行環境としてのCPUやGPU、または専用チップ
- それらを搭載したサーバ、スマートフォン、組込デバイス等
ハードウェアは用途にあわせて選択します。2015年以前は、クラウド側等ふんだんな計算資源上での実行が前提でした。2016年以降徐々に、組み込み機器やスマートフォンなど、現場の近くで動かすためのソフト、ハード両面の研究、実装が進みました。また、CoreML(iOS)、ML Kit(Android)といったソフトウェアライブラリで、クラウドで学習済みのモデルをスマートフォンで動かす環境が整いました。
ソフトウェア
ソフトウェアを構成するのは、主に以下です。
- フレームワークを活用したコード
- PyTorch, TensorFlow, Chainerなどのフレームワーク
- それらを支えるローレベルのライブラリ
機械学習フレームワーク事情は、2-3年で様変わりしました。2014-5年に機械学習を勉強しようとした方は、Caffe, Theanoを多く聞きました。今やその頃は無かった、TensorFlow, PyTorchが2大フレームワークに成長しました。日本ではChainerも使われています。一方、Theanoは開発が停止されました。CaffeはPyTorchエコシステムの中、商用デプロイ用に生きています。
運用プロセス
運用プロセスには、実行効率化の側面と、そもそも達成すべき品質や要件の2つの観点があります。
前者は以下のような観点となるでしょう。
- デバイス管理
- クラウド側での再学習、モデル更新
- デバイス側のモデルバージョン管理、遠隔からの更新
後者は、ソフト、ハードだけでなく、機械学習特有のエンジニアリング手法やプロセスへの注目が高まっています。2018年度、日本ソフトウェア科学会に、機械学習工学研究会( https://sites.google.com/view/sig-mlse )が正式に立ち上がりました。AIプロダクト品質保証コンソーシアムは、2019年5月にAIプロダクト品質保証ガイドライン( http://www.qa4ai.jp/download )を発表しています。
エッジと演算装置(CPU/ GPU/ ASIC/ FPGA/ マイコン)
上にあげたそれぞれの構成要素には、それぞれ演算を担当するIC(集積回路)があります。CPU、GPU、ASIC、FPGA、マイクロコントローラと、複数の種類があり、それぞの得意・不得意があります。また、それぞれを単体で使うだけでなく、得意・不得意分野を補い合うために組み合わせて使います。詳しく見てみましょう。
CPU
CPUは、Central Processing Unit、つまり「中央演算装置」の略です。
みなさんが使われるパソコンの中でも、演算の中心を担うのはCPUです。次に挙げるGPUのように画像専門ではなく、汎用的にコンピュータに必要な様々な処理をバランスよくこなせるよう設計されています。最近では、機械学習用の演算を高速化するようなフレームワークも出てきました。
GPU
GPUは、Graphic Processing Unit、つまり「画像処理装置」の略です。
もともとはグラフィックアクセラレータとして開発されました。画面を高速に描画するためには、大量のピクセルを同時並行で扱い、様々な演算を行う必要があります。CPUとは異なったアーキテクチャをとる方が、より効率よく演算を行えます。そうして開発されたのがGPUです。
例に、NVIDIA社やAMD社の製品が挙げられます。近年はGPUを使う科学計算/機械学習用ライブラリが整ったNVIDIA社のGPU一強とされてきました。しかし、AMDも各種フレームワークの互換対応を進めています。AMD GPUを使う推論用クラウド基盤、という野心的なスタートアップ( https://www.gpueater.com )もあります。機械学習だけでなく、ゲームのフィールドでは、性能、価格面で人気があります。
CPUとGPUの違いの例え話として、分野は違いますがGLSLシェーダの入門に、わかりやすい図解と説明があります。初めの一歩> シェーダーはなぜ速いのかをご覧ください。
The Book of Shaders[日本語訳]
ASIC
ASICは、Application Specific Integrated Circuit、つまり「特定目的用の集積回路」の略です。
CPU、GPUは汎用性に優れます。ですが、特定用途には冗長だったり、回りくどい計算をしているかもしれません。ここには設計のトレードオフがあります。そのため、汎用性を多少犠牲にして、「ある用途にはめっぽう強い」集積回路を作ることもでき、それがASICです。ある特定用途に優れ、一定のスケールで生産できる場合、ASICが選ばれます。少量多品種の場合は、後述のFPGAが使われます。
例に、GoogleのTPUが挙げられます。本稿では深入りしませんが、インターネットには、大量のデータを受信し、適切な宛先に送信する、ルータという装置があります。より高いパフォーマンスを得るために、汎用のプロセッサでなく専用チップが開発されています。これらもASICのひとつです。
FPGA
FPGAは、Field-Programmable Gate Array、つまり「出荷後にも書き換え可能な集積回路」の略です。
ユーザがロジックを自由にプログラミングできる集積回路です。チップを設計する、というとひとつひとつトランジスタの配置を考えていくのかと思いますが、FPGAでは、一定それを抽象化したコードを書き、その「ソフトウェア」を「ハードウェアに焼き込む」ことができます。また、FPGAは、ロジックを何度も変更することができます。ある特定用途に使うロジックをハードウェアで実現することで高速化したいが、それを大量に生産するほどの母数がない場合に向いています。
例に、Xilinx社やAltera社の生産するFPGAが挙げられます。
マイクロコントローラ
なぜ機械学習の文脈でマイクロコントローラ(マイコン)?と驚かれる方もいらっしゃると思います。マイクロコントローラ(マイコン)は、大分類ではCPUの一つであるともいえますが、用途や設計思想が異なります。こちらの記事に詳しい紹介があります。
【1カ月集中講座】IoTの波に乗るマイコン事情 第1回 ~組み込み向けプロセッサとアプリケーションプロセッサの違い - PC Watch
https://pc.watch.impress.co.jp/docs/column/1month-kouza/682634.html
例に、Arduinoの頭脳部であるAVRのマイクロコントローラなどが挙げられます。
TensorFlowでは実際にマイクロコントローラでの音声認識、Microsoft SeeDotでは文字認識の例があがっています。今後センサーから取得した情報について、マイクロコントローラで機械学習を用いた前処理を適用し、より上流に情報を送る、というようなことも可能になるかもしれません。エッジの、さらにエッジと言えるでしょう。
それぞれの融合
上にあげたそれぞれの集積回路は、独立して存在するわけではありません。周りにそれを支えるメモリなどの他のチップが必要です。また、演算を担当する集積回路間でもそれぞれが協調し、得意分野に集中し、苦手分野を補い合うようなアーキテクチャを取ります。例えば、GPUを使った機械学習、推論という文脈では、背後に必ずCPUとGPUの協調があります。ARM社は、CPUやGPUと周辺のチップセットを組み合わせたモバイル向けSoCで成功をおさめています。スマートフォンで推論を行う場合は、そのSoCを最適に使いこなす必要があります。FPGA SoCという、FPGAとCPUの例もあります。マイクロコントローラとFPGAという例もあります。
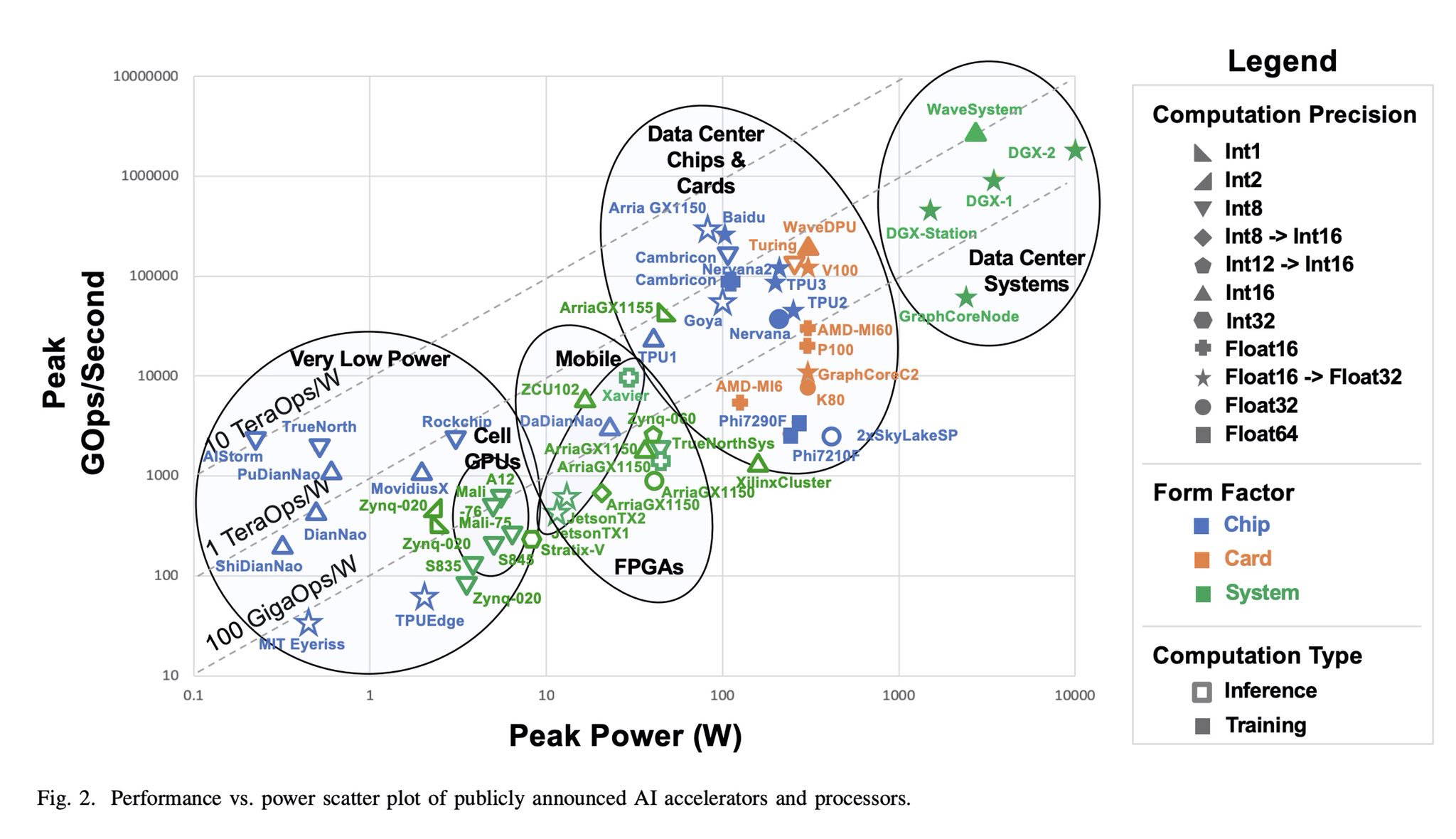
2019年8月にarXivに掲載された、Survey and Benchmarking of Machine Learning Accelerators(機械学習アクセラレータの調査とベンチマーク;
https://arxiv.org/abs/1908.11348 )に、非常にまとまった情報があります。論文や、企業ベンチマークなどの公開情報から、各プロセッサの性能と消費電力の情報がマッピングされたのが、以下です。
エッジのためのモデルとトレードオフ
機械学習におけるトレードオフ
機械学習に取り組む時、まず精度を上げることに必死に取り組みたくなります。しかし、実利用時を考えると、どれだけの計算資源が学習時と推論時に必要かも重要です。
OpenAIのHow AI Training Scales(AIの学習をスケールさせるには;
https://openai.com/blog/science-of-ai/ )では、学習時に意識すべきそのトレードオフに触れられています。精度以外の軸を頭に置く上で、参考になる記事です。
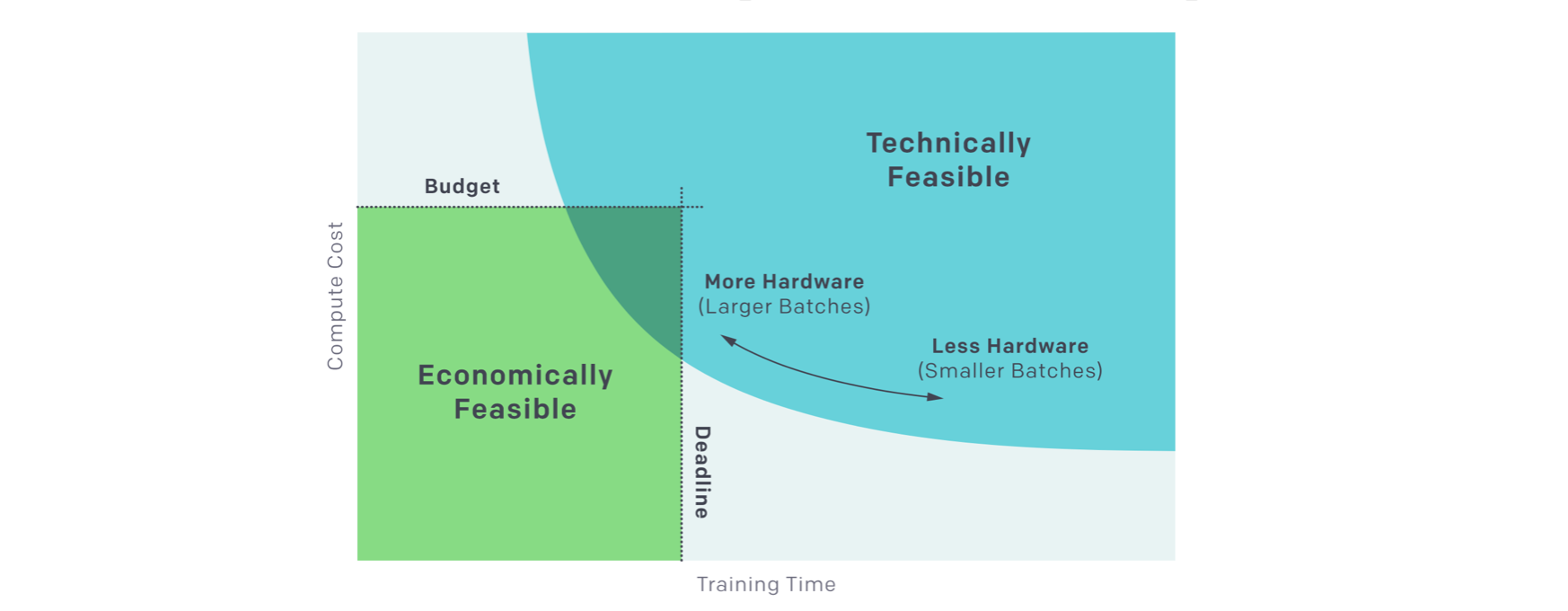
また、各モデルの計算の効率については以下の情報、論文があります。
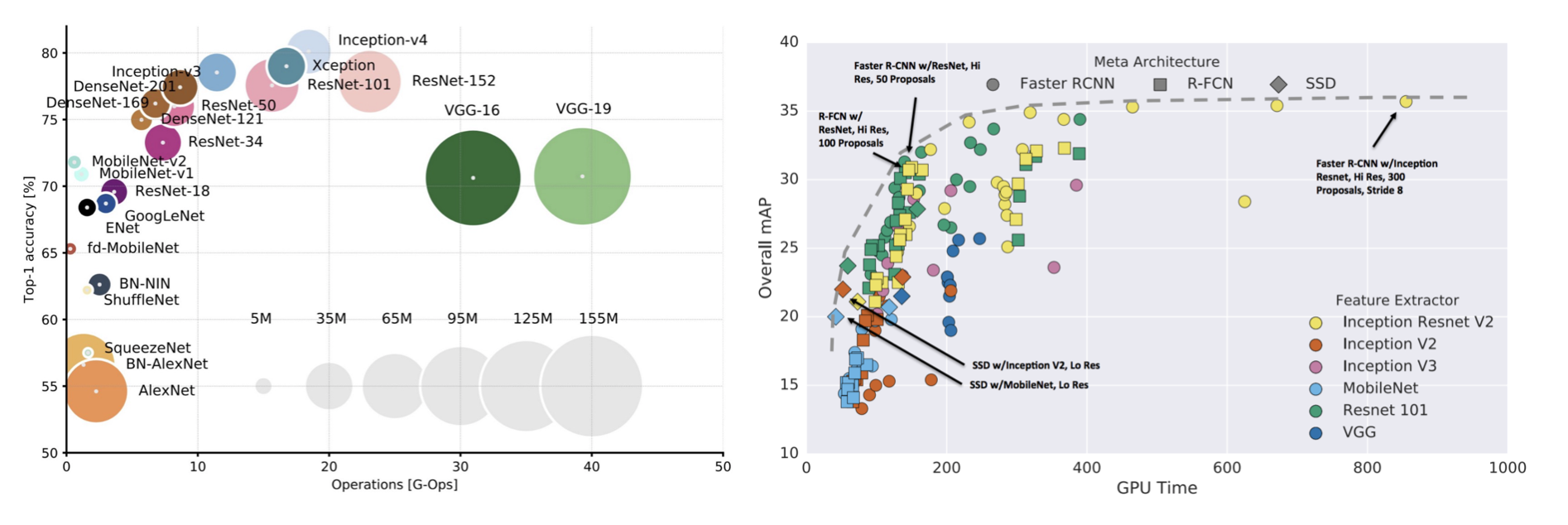
左:https://towardsdatascience.com/neural-network-architectures-156e5bad51ba, 右: https://medium.com/@jonathan_hui/object-detection-speed-and-accuracy-comparison-faster-r-cnn-r-fcn-ssd-and-yolo-5425656ae359
左グラフは、縦軸が画像分類タスクにおける各モデルの達成した精度(ImageNet 1000種類の画像を、各カテゴリに分けるもの)、横軸がオペレーション数です。オペレーション数は、必要な計算資源の量に対応します。右グラフは、縦軸がmAPという物体検知における精度指標、横軸がGPU時間、これも必要な計算資源の量に対応します。
こうしたトレードオフを考慮しないと、どういうことが起きるでしょうか。ある画像を入力し、ある精度の回答がxx ms以内に欲しいという要件があってもに、その目的に合わないかもしれません。また、ある小さな場所に、そのエッジ機器を置きたいのだが、その要件に合う計算資源はその場所にフィットしないかもしれません。
エッジ向けのモデルの最適化とは
特に、この推論時、軽量なデバイスでの実行を考慮し、トレードオフから程よい着地点を探そうとするのが、エッジ向けのモデル最適化です。エッジの限られたリソースに最適化するため、以下の手法が用いられます。
- モデルの軽量化(量子化、枝刈り)
- 頻出オペレーションのハードウェアロジック化
一定の精度低下の犠牲は払いながら、計算量・時間を削減していきます。これは精度と計算のトレードオフなので、適用ユースケースを見ながら考えます。また実際にはモデルの最適化のみならず、入力サイズの変更、モデルの変更、デバイスの変更などチューニングを行います。
TensorFlowの公式ページにて、モデルサイズと遅延、量子化について紹介されています。
TensorFlow Lite> Performance> Best Practices [英語]
https://www.tensorflow.org/lite/performance/best_practice
以下の記事では、「畳み込み層の構造を工夫してパラメータ数や計算量を減らす」「ネットワークのパラメータを圧縮する」といった工夫の裏側について詳しく解説されています。
MobileNet(v1/2)、ShuffleNet等の高速なモデルの構成要素と何故高速なのかの解説 - Qiita
https://qiita.com/yu4u/items/dc26d220e85279e76157
機械学習のフレームワーク
フレームワークの興りと進化
2019年現在、代表的な機械学習用フレームワークとしては、TensorFlow, PyTorch, Chainer, MXNetなどが挙げられます。2010年代前半には、Caffe、Theano、Torchなど、別のものが主に使われていた時代もありました。
これらのフレームワークは、まずはクラウド側で、大きな行列を扱う、微分計算・最適化といった機械学習の基本ピースが便利にまとまったものとして発展しました。頻出のパターンを、CPUやGPU上で最適に演算できるライブラリ群をまとめています。
次に、利便性を備えた関数や、それを持つラッパーライブラリが増えました。1行で学習済みモデルを扱う、頻出のモデルや最適化手法をすぐ呼び出せる、その他、まず様々なモデルを開発・学習・理由するユーザの「かゆいところに手が届く」機能群です。
さらに、フレームワーク内に完結してエッジへモデルを配信したり、ブラウザなどの広義のエッジ側で実行する仕組みが出てきました。これは、モデルの作成にとどまらず、実利用、その対象のスケールを視野にいれたとき、さらに「かゆいところに手が届く」機能群です。
例えば、TensorFlowを例に挙げましょう。まず、TensorFlow本体が、Googleでの内部利用を経て、オープンソースとして公開されました。その後、TensorFlowに対するラッパーとして、Kerasが登場し人気を集めました。当初はTheano、TensorFlowの両方をバックエンドとして採用していましたが、その後TensorFlowとの結合を深めました。新しいTensorFlow 2.0では、Kerasの書き方でモデルを定義することが標準となりました。また、TensorFlow 2.0では、TensorFlow Serving, TensorFlow Lite、TensorFlow.jsなど、TensorFlowは垂直統合で学習から配信までをよく備えています。TensorFlow.jsは、もともとこちらも独立に開発されていたdeeplearn.jsを、201x年にTensorFlowファミリーに取り込み改称、発展させたものです。
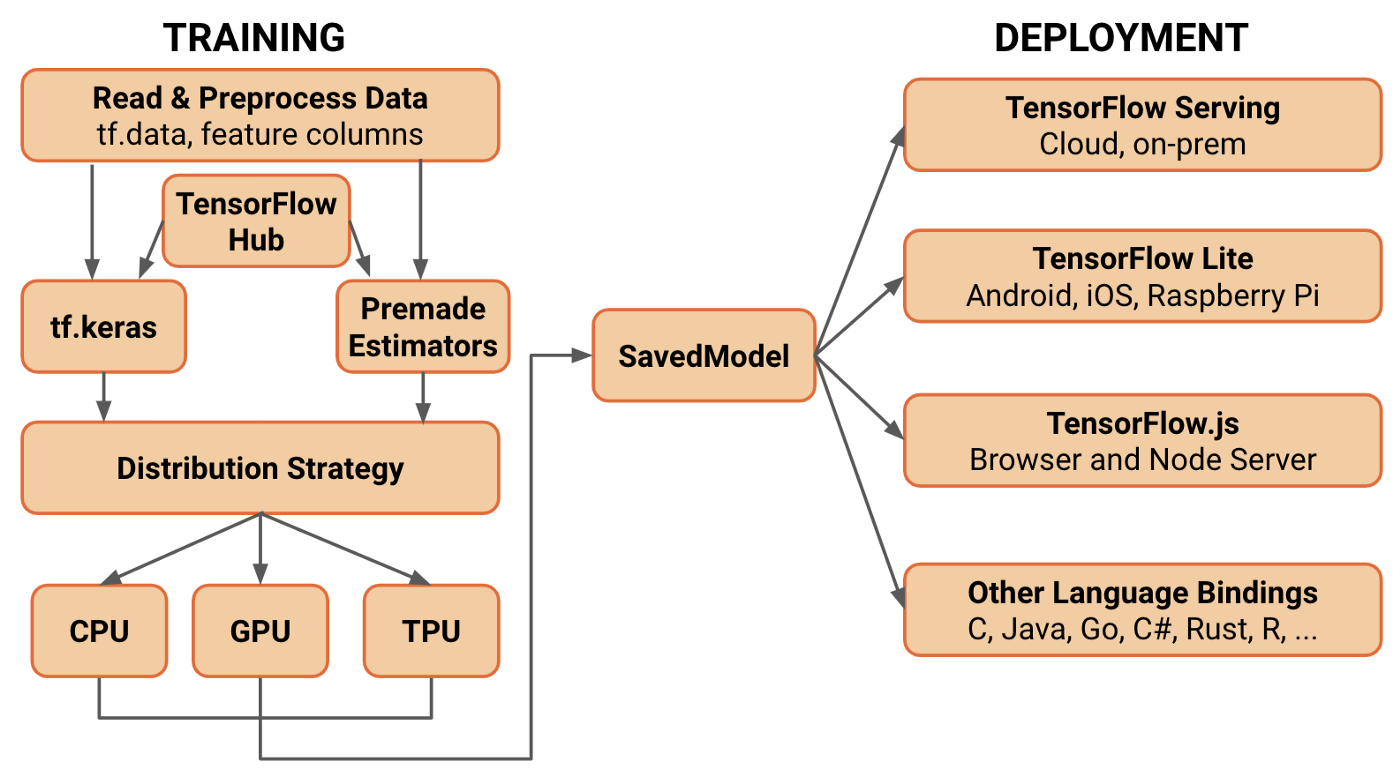
また、各フレームワーク間に完結させず、相互にモデルを受け渡す形式としてONNXがあります。ONNXに変換した上で、モデルをエッジ側に最適化する仕組みもあります。
エッジデバイス用のフレームワーク
エッジを扱うにあたってのハマり所はふたつあると言えるでしょう。
- 各計算資源にどうモデルを最適化するか: エッジ推論効率化のためのフレームワーク
- 散在するエッジデバイスをどう運用・更新するか: エッジデバイス運用のためのフレームワーク
前者は、対象のチップに応じて各メーカがそれぞれライブラリを作っています。後者は、MDM、IoTプラットフォーム、MBaaSが機能を拡張したものが多くあります。
次項から、それぞれについて見ていきましょう。
エッジ推論効率化のためのフレームワーク
エッジ推論効率化のためのフレームワークは、基本以下の流れで使います。
- モデルを選ぶ
- 変換、最適化する
- モバイルまたは組み込みデバイスにデプロイする
TensorFlow、PyTorchなどのフレームワークを使い、Pythonでモデルを定義し、学習、推論させる。クラウド側で活用するのと同じ方法をなぜ取らないのでしょうか。それは、エッジ側の制約が関係しています。
基本的には全て、推論の最適化・実行のためのライブラリです。餅は餅屋ですので、それぞれのチップを使うときには、基本各メーカ準備のライブラリを使うのが近道です。ONNXなどのオープンなモデル定義は学習済みモデルの受け渡しに使えますし、各機械学習フレームワーク独自にエッジ側フレームワークとのインテグレーションを行なっているものもあります。

https://opensourceforu.com/2019/06/onnx-helping-developers-choose-the-right-framework/ より引用、一部改変
このように各フェーズが連携していると理解できるでしょう。
そもそもGPU用のフレームワークとは
GPUは、もともとグラフィックスの処理用に最適化し、設計・開発されていました。大量の行列演算が得意なので、より汎用的な用途に活かそう、としたのがGPGPU(General-purpose computing on GPU; GPUによる汎用計算)です。まずHPC(high-performance computing)という、スーパーコンピュータなどの高性能計算を扱うフィールドで盛り上がりを見せました。
NVIDIA製GPU向けにCUDAが開発されました。これはNVIDIA製GPU上でGPGPUを行うためのライブラリです。また、機械学習の特化して、その上にcuDNNというライブラリが登場しました。より低いレイヤを気にしなくても、抽象度の高い(といってもKerasやTensorFlowなどと比べると被レイヤなのですが)コードで、機械学習の学習・推論を行えるようになりました。
今我々の触れるフレームワークは、先人たちのミルフィーユのような一層一層の積み上げに支えられています。さて、下のチップが変われば、その間を埋めてやる必要があります。それはエッジについても、同様に発展が必要であることがわかります。
NVIDIA TensorRT
公式サイト: https://developer.nvidia.com/tensorrt
対象: NVIDIA製GPU
NVIDIAは、もともとJetsonというエッジ向けのGPUラインナップを従来より展開してきました。TensorRTは、そうしたエッジGPU向けにモデルの最適化を行います。
TensorRTやってみた](1): TensorRT とは何か? - Fixstars Tech Blog /proc/cpuinfo
http://proc-cpuinfo.fixstars.com/2018/03/tensorrt-00/
記事に示されているように、「複数レイヤ処理を1レイヤ処理にまとめる」「量子化」「並列化」「メモリ最適化」「カーネル最適化」が駆使され、高速化が実現されます。オペレーション。ニューラルネットで必要な演算が一通りサポートされます。ただしここはフレームワークにより対応状況が異なるので、学習を行う際に、最終的な実装を考え、モデル内にどういったオペレーションを使うか、使っているかを把握して進めなければいけません。
Intel OpenVINO
公式サイト: https://software.intel.com/en-us/openvino-toolkit
対象: Intel CPU/ GPU/ Altera FPGA/ ASIC(MYRIAD)
NVIDIAが大きく先行した深層学習におけるチップメーカの主導権争いですが、IntelはOpenVINOで巻き返しを図っています。
IntelはもともとCPUに強みがあり、GPUも生産しています。さらに、Intel社は、2015年にFPGAメーカのAltera社を、2016年に深層学習に特化したASICを開発していたMovidiusの買収を発表しています。買収によるポートフォリオ拡充、強化です。もともと一定の強みのあるCPU、GPUに加え、 FPGA、ASICと広範なプロダクトポートフォリオを手に入れました。それらをそのまま、OpenVINOでサポートしています。具体的には、Intel CPU/GPU、MYRIAD(Movidius)、Altera FPGAが対象です。最適な計算を最適な場所で、というエッジの広がりの波で、勢いがあります。
Xilinx DNNDK
公式サイト: https://www.xilinx.com/products/design-tools/ai-inference/edge-ai-platform.html
対象: Xilinx FPGA
Xilinx社はDeePhi Tech社を2018年に買収しました。DeePhi Tech社は、もともとXilinx社のFPGAを使って、独自にDPU(Deep Learning Processor)というアクセラレータを開発していました。そこからXilinxの傘下に加わりました。経緯はこちらの記事( https://news.mynavi.jp/article/deephi-2/ )に詳しいです。こちらも、FPGAハードウェアに強みを持つ会社が、ソフトウェア部分のポートフォリオを買収で拡充、強化した例です。
Microsoft SeeDot
公式サイト: https://github.com/microsoft/EdgeML/tree/master/Tools/SeeDot
対象: ArduinoなどのAVRマイコン等
SeeDotは、浮動小数点演算を行わず、整数演算のみで固定小数点演算を行うよう機械学習モデルをコンパイルします。モデルはKB単位のサイズまで圧縮され、マイクロコントローラ上などでも推論を実行できるようになります。実際に、文字認識を x KBのサイズまで小さくし、Arduino上で動かすデモがあります。
Google TensorFlow Lite, TensorFlow.js
公式サイト: https://www.tensorflow.org/lite, https://www.tensorflow.org/js
対象: Android、iOSスマートフォン、ASIC(Edge TPU)、マイコン、ブラウザ(JavaScript)ほか
TensorFlow Liteは機械学習モデルを、モバイルデバイス、IoTデバイスなどさまざまな場所にデプロイするためのフレームワークです。モデルの選択、変換、デプロイ、最適化をサポートしています。ブラウザでの実行、という意味ではTensorFlow.jsを使うことができます。
ML KitとCore ML
ML Kit公式サイト: https://developers.google.com/ml-kit/
Core ML公式サイト: https://developer.apple.com/documentation/coreml
対象: Android、iOSスマートフォン
スマートフォン向けの機械学習フレームワークも、ベータ版を経て、実用に耐えるものが広がってきました。iOS、Android共に、初出では単純な画像分類などのモデルをAPIとして備えただけでした。その後、数年を経て、実際に実用やゲームのアプリケーションに組み込んで使えるものに進化しました。ML KitはAndroid、Core MLはiOSデバイス上で走るアプリケーション向けの機械学習適用を最適化するためのライブラリです。
エッジデバイス運用のためのフレームワーク
運用のためのフレームワークは、以下のような機能を持つケースが多いです。
- デバイス管理
- クラウド側での再学習、モデル更新
- デバイス側のモデルバージョン管理、遠隔からの更新
これを行うためのアーキテクチャとして、デバイス側にエージェントプログラム、またはアプリを動かしているケースが多くあります。そのエージェントプログラムやアプリと、クラウド側のサービスを、APIを介して連携させることで、上を実現します。
具体的には、モバイルアプリ向けのバックエンドサービス(MBaaS)であるGoogle Firebaseには、機械学習モデルを配信する仕組みが組み込まれています。AWS SageMaker Neo/ Greegrassの組み合わせや、Azure IoT Hub/IoT Edgeの組み合わせもあります。これらは、クラウド側の管理サービスで、学習済みモデルをクラウドやエッジ様々なところで実行しやすいように最適化し、その上で機械学習モデルをエッジ側へ配信できます。
まとめ
本稿では、まずエッジへの注目の高まりとその背景について概観したあと、様々なエッジの形態について説明しました。エッジ特有の課題、それに対処する研究や、ソフトウェアへの実装、製品について紹介しました。
ここまでのキーワードを元に、それぞれの利用シーン、今後の発展はみなさま自身のデスクトップリサーチで多くの情報が得られるでしょう。
エッジにおける機械学習活用は、IoT同様、いわゆるフルスタックの知識が求められます。それもフロントエンド、バックエンドだけではなく、組み込み、ハードウェア、そのアーキテクチャといった類です。私自身、この記事はそのあたりの足りない知識を補強することも兼ね、サーベイした結果をまとめたものです。内容についての修正、コメント、フィードバックをいただけると幸いです!