この記事では、東証株式高頻度データ(FLEX Historical)の加工/分析ツール「jpxlab」を利用して、東証の銘柄取引高をビジュアライズしてみます。サンプルのノートブックはこちらを参照してください。
メタデータの準備
FLEX Historicalにも株式の銘柄を特定する情報も含まれますが、本サンプルではより詳細なメタデータを提供する東京証券取引所が公開しているファイルを利用します。
こちらのファイルは銘柄の多様な情報が含まれており、銘柄コードや社名をマッピングしたり、セクター・TOPIXなどで銘柄をカテゴリーに分類するのに有用です。
セクターごとに取引高をビジュアライズする
ヒストリカルデータとこのファイルが提供するメタデータを組み合わせて利用するには、サンプルjpxlab demo -sector volume.ipynbが良いスタートポイントとなるでしょう。
このノートブックはセクター情報を活用して、銘柄をどのようにグルーピングするかを示しています。下図は2019年9月のセクターごとの取引高を統合したものです。
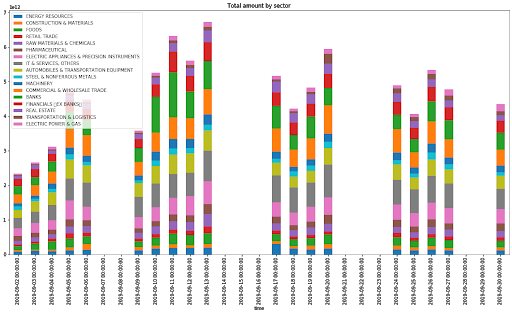
シンプルなビジュアリゼーションですが、2019年9月5日において、17業種区分の商社・卸売が増えたことや、2019年9月10日において、17業種区分の銀行が増えたこと等がひと目で確認できます。また、少しの変更で9月の取引高上位100社だけをフィルターすることも可能で、ノートブックに例示されています。
1日の取引高を予測する
マーケットデータ解析において最も興味深いトピックの一つは「予測」でしょう。統計分析や機械学習など様々なアプローチが考えられますが、1ヶ月分だけのデータで株価の複雑なモデルを構築するのは少々無理があります。そこで、今回はあくまで方法論のご紹介に留め、簡単なデータ分析から始めてみることにします。
まずトヨタ(7203)の日次の取引高の自己相関をプロットしてみます。
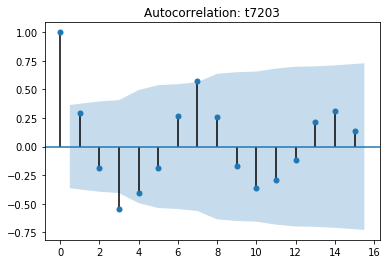
水色の領域は信頼区間で、そこを突き抜けた値が出ていると有意な自己相関があると言えます。自己相関は、自身の遅延したコピーとの相関ですので、ここで高い相関係数が観測されると、周期性があると言えます。残念ながら上記の例では有意な相関は観測できませんでした。
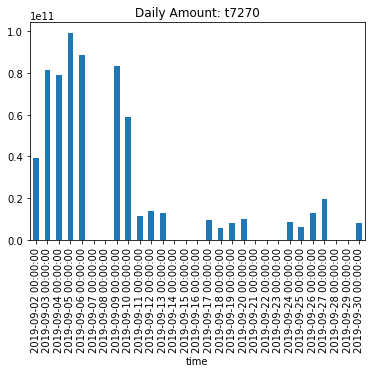
次に、実際に自己相関が高い銘柄を選択し、どのようなプロットになるかを見てみます。例では、トップ100銘柄の中から、スバル(7270)を選択しました。
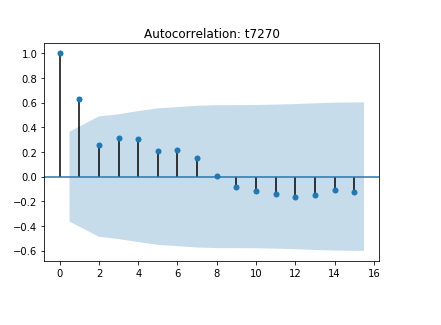
プロットの通り、leg1にて比較的高い正相関が見られます。この例では非常に限られたサンプルであるため、実際の有用性は度外視ですが、より多くのサンプルが得られるようなケースでは、このようなデータはARIMAモデルのような自己回帰モデルである程度予測が可能であるケースが多いです。
念の為、もとの取引高の推移をプロットすると以下のようになります。
クラスタリング
もう一つ踏み込んだ分析をしてみましょう。売買高の推移のパターンによりクラスタリングすることで、連動する銘柄やその傾向の移り変わりを観測することにチャレンジしてみます。ただし、毎度のことながら学習に利用できるサンプルが非常に限られているため、あくまで方法論をご紹介することで今後の実験に役立てて頂けたらと思います。ノートブックはjpxlab demo -cluster analysis.ipynbです。
T-SNEによる次元圧縮
クラスタリングを行う対象はベクトルです。今回は銘柄ごとの売買高の推移パターンの類似度を分析したいため、売買高の推移という時系列データを何らかの方法でベクトル化する必要があります。
ただこのプロセスが肝で、ベクトルの次元は多ければ多いほど次元の呪いに陥って本質的な特徴を抽出することが困難になるため、次元圧縮というテクニックを用いて出来るだけ低次元に落とすことになります。
次元の圧縮方法として最も知られているのはPCAやMDSですが、ここではT-SNEという非線形な関係を持つ対象に対しても有効なアルゴリズムを用います。入力は銘柄ごとの生の売買高推移をスライディングウィンドウで抽出したスナップショットです。これを、ビジュアリゼーションのために2次元まで圧縮します。
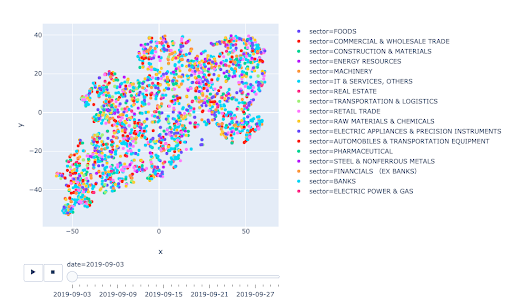
詳しくはNotebookをご参照頂くとして、この期間では意味の有りそうなクラスタを視覚的に捉えることは難しいものの、シンプルなコードで、クラスタリングからその時系列変化をアニメーションつきでビジュアライズするところまで出来てしまうという、非常に強力なツールであることはご覧頂けたのではないかと思います。
このように、jpxlabを入り口として、予測モデルの設計や検証等様々な応用につなげていける可能性を垣間見て頂けましたら幸いです。