データフレームを一言で説明すると?
データフレーム(DataFrame)とは、Pythonで表形式データを扱うためのクラス(オブジェクト)です。
PandasライブラリのDataFrameクラス(オブジェクト)を指します。
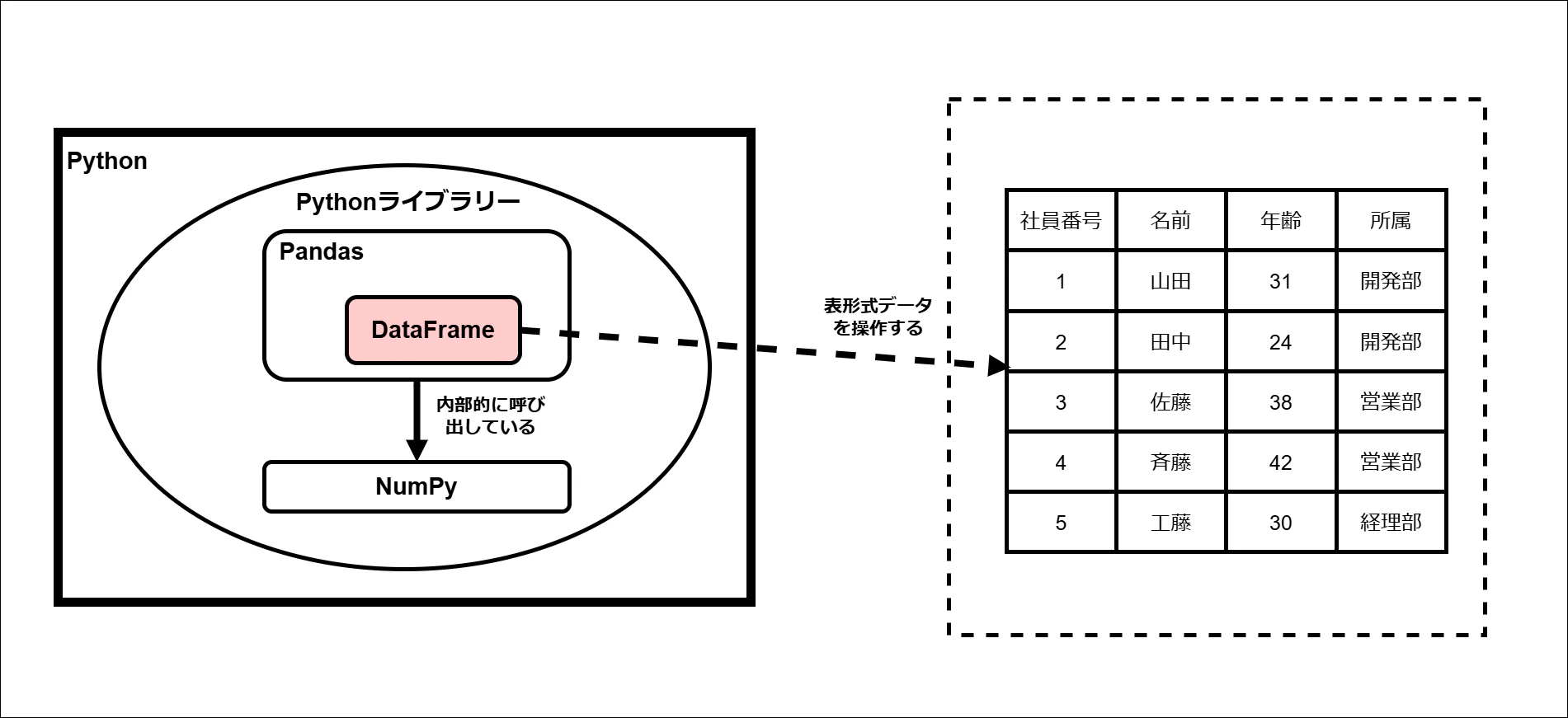
データフレームを扱う利点
データフレームを利用することで、SQLと似た感覚で表形式データを処理できます。
データフレームを理解するために必要な3つの前提知識
① NumPy
② Pandas
③ 表形式データ
① NumPy
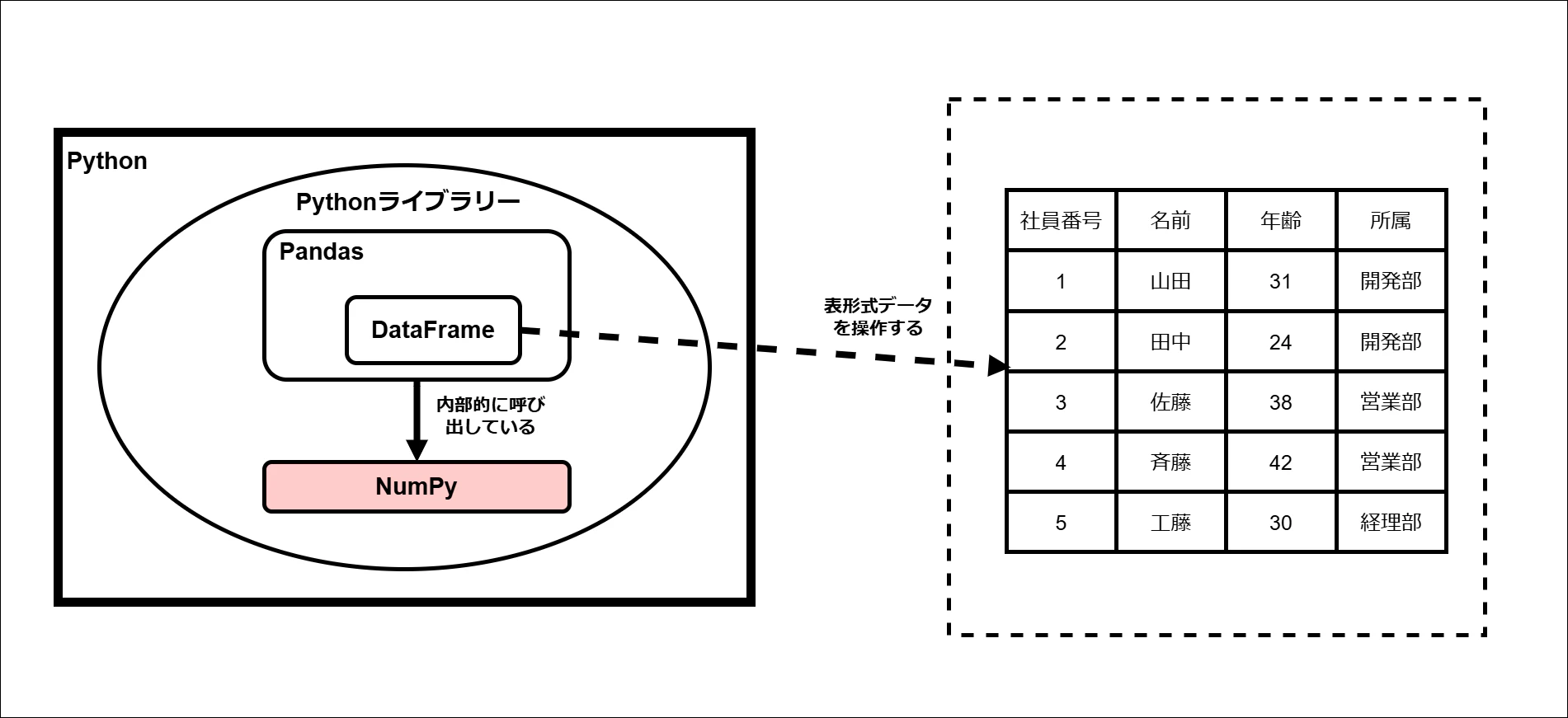
NumPy(ナムパイ)は、Python で数値計算を効率的に行うためのライブラリです。
NumPyを理解する上で最も重要な概念の一つが、ベクトル化です。
ベクトル化とは、ループ処理を使わずに、配列全体に対して一括で演算を行う仕組みのことです。
data = [1, 2, 3, 4, 5]
result = []
for x in data:
result.append(x * 2)
NumPyでは、このようなループ処理をベクトル化により、次のように簡潔に書けます。
import numpy as np
data = np.array([1, 2, 3, 4, 5])
result = data * 2 # 全要素を一括で2倍
✅ ベクトル化のメリット
1. 処理の高速化
NumPyの演算処理は C言語で最適化されており、Pythonのfor文よりも圧倒的に高速です。
特に大量データの処理で効果を発揮します。
2. コードの簡潔化と可読性向上
ループ処理を使わずに、数学の式のように配列演算を記述できるため、コードが短くなり、直感的で読みやすくなります。
② Pandas
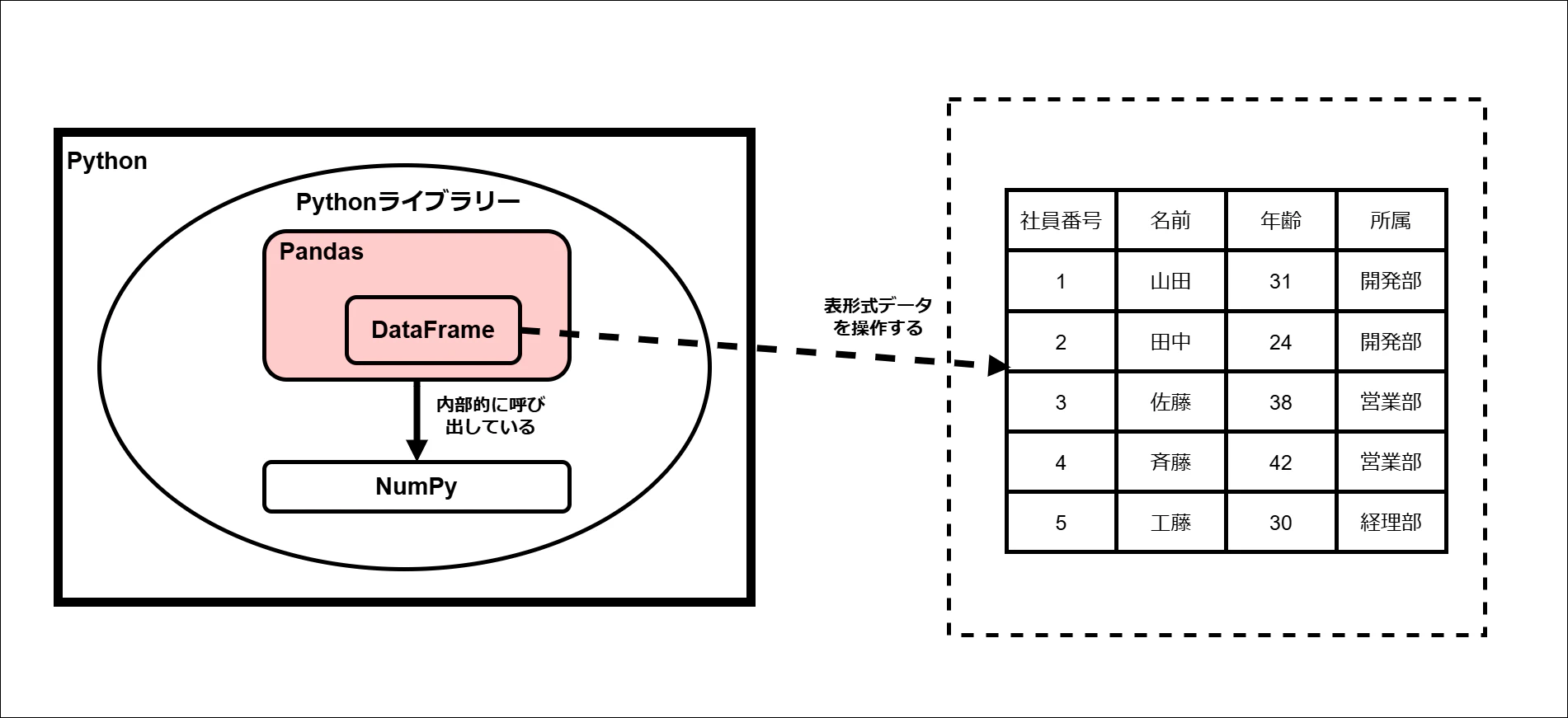
Pandas(パンダス)とは、データ解析を簡単に行うための機能を提供する、Pythonのデータ解析ライブラリです。
内部的には、先ほど紹介したNumPyを利用して処理を行っています。
「データフレーム(DataFrame)」は、このPandasライブラリに含まれる代表的なクラスのひとつです。
③ 表形式データ
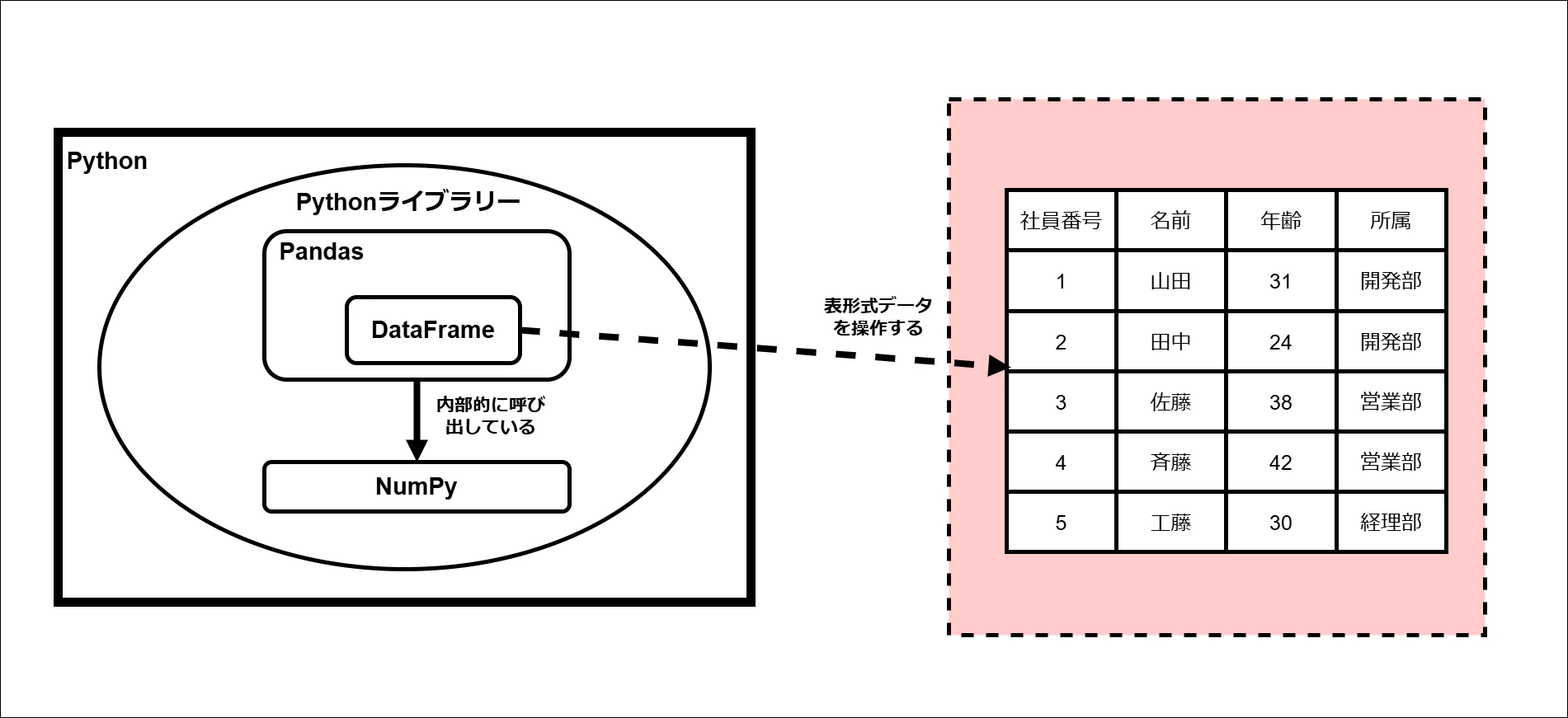
表形式データとは、行と列から構成されるデータのことです。
| ID | 氏名 | 年齢 | 都市 |
|---|---|---|---|
| 1 | 佐藤 太郎 | 25 | 東京 |
| 2 | 鈴木 花子 | 30 | 大阪 |
| 3 | 高橋 次郎 | 28 | 名古屋 |
上記のように、1行が1件のデータ、1列が属性(項目)を表す構造になっています。
ExcelやCSVファイル、データベースのテーブルなどがこれにあたります。
✅ 表形式データの特徴
- 構造が明確で、人にもコンピュータにも扱いやすい
- 行単位で「データのまとまり」、列単位で「データの属性」を表現する
- CSV・Excel・SQLなど、多くの形式で活用されている標準的なデータ構造
PandasのDataFrameは、この「表形式データ」を効率よく扱うために設計されています。
データフレームの代表的な機能まとめ
Pandasのデータフレーム(DataFrame)は、表形式データをPythonで柔軟かつ効率的に扱うための強力なクラスです。以下では、日常的なデータ処理でよく使われる代表的な機能を5つに分類して紹介します。
| 機能カテゴリ | 説明 |
|---|---|
| ① 読み込み・書き出し | 外部データとのやり取り |
| ② 選択・抽出 | 必要なデータを取り出す |
| ③ 集計・統計・グループ化 | データの傾向やグループ分析 |
| ④ 欠損値処理 | データの品質管理・前処理 |
| ⑤ 整形・結合・並べ替え | 分析しやすい形にデータを加工する |
① データの読み込み・書き出し
外部ファイル(CSVやExcelなど)からデータを読み込んだり、保存したりできます。
import pandas as pd
# CSVファイルの読み込み
df = pd.read_csv("data.csv")
# Excelファイルへの書き出し
df.to_excel("output.xlsx", index=False)
② データの選択・抽出
列の選択、行の指定、条件による抽出が可能です。
# 列の選択
df['売上']
# 行の選択
df.iloc[0]
# 売り上げの値が1000を超える行を抽出する
df[df['売上'] > 1000]
③ 集計・統計・グループ化
平均や合計などの統計量の取得や、グループ単位での集計が可能です。
# 列「売り上げ」の平均値
df['売上'].mean()
# 支店ごとの売上合計
df.groupby('支店')['売上'].sum()
④ 欠損値(NaN)の処理
欠損データの確認・補完・削除ができます。
# 欠損値の確認
df.isnull().sum()
# 欠損値を0で埋める
df.fillna(0)
# 欠損値を含む行を削除
df.dropna()
⑤ データの整形・結合・並べ替え
列の追加・削除、ソート、データの結合や転置などができます。
# 列の追加
df['利益'] = df['売上'] - df['コスト']
# 並べ替え(降順)
df.sort_values(by='売上', ascending=False)
# データの結合(縦方向)
df_all = pd.concat([df1, df2])
# データの結合(横方向)
df_all = pd.merge(df1, df2, on='ID', how='inner')
# 転置(行と列を入れ替える)
df.T
まとめ
Pandasのデータフレームは、「読みやすい」「速い」「柔軟」なデータ操作を可能にする、Pythonにおけるデータ分析の中心的ツールです。基本機能を理解することで、より実践的な分析や可視化へとスムーズに進むことができます。