はじめに
著者はPython初心者です。TwitterAPIに興味がある人、あまり使ったことが無い人の参考になればうれしいです。今回の記事ではTwitterAPIのアクセス権限がある前提で話を進めていくので、まだTwitterAPIで遊んだことがない人は前回の記事を参考にしていただければと思います。
https://qiita.com/tomo045/items/7aa50b45702f105bcee0
動作環境
OS→Windows10、Pythonバージョン→3.7.8、コードの実行→Jupyter Notebook(VS Code)
コード
import tweepy
# API認証の設定
API_KEY = "*********************"
API_SECRET = "*******************"
ACCESS_TOKEN = "********************"
ACCESS_TOKEN_SECRET = "***********************"
auth = tweepy.OAuthHandler(API_KEY, API_SECRET)
auth.set_access_token(ACCESS_TOKEN, ACCESS_TOKEN_SECRET)
api = tweepy.API(auth)
# 地名とwoeidを紐づけた辞書を作成
woeid = {
"New York":2459115,"London":44418,"Paris":615702,"Rome":721943,
"Tokyo":1118370, "Kenya":23424863, "São Paulo":455827, "Ukraine":23424976,
"Zurich":784794
}
for area, wid in woeid.items():
print("--- {} ---".format(area))
trends = api.trends_place(wid)[0]
for content in trends["trends"][:1]
print(content['name'])
トレンドを調べるためにtweepyのTrendsメソッドを使います。The Yahoo! Where On Earth IDによって場所を設定します。辞書型変数woeidに調べたい都市名(area)とThe Yahoo! Where On Earth ID(wid)を入力しましょう。woeidは以下のサイトで参照しました。
https://muftsabazaar.com/blog/category/?c=WOEID
trends = api.trends_place(wid)[0]
for content in trends["trends"][:1]
print(content['name'])
コードの中でも一番難しいのが上記の部分です。
testTrends = api.trends_place(1118370)[0]
print(testTrends)
trendsをわかりやすく説明するために、このコードを実行して東京のトレンドを取得してみます。
{'trends': [{'name': 'ソッサスブレイ', 'url': 'http://twitter.com/(略)',
'promoted_content': None, 'query': '%E3%(略)', 'tweet_volume': None}
...
{'name': 'パーパット', 'url': 'http://twitter.com/(略)',
'promoted_content': None, 'query': '%E3%(略)',
'tweet_volume': None}],
'as_of': '2021-08-01T08:34:28Z', 'created_at': '2021-07-29T07:05:28Z',
'locations': [{'name': 'Tokyo', 'woeid': 1118370}]}
実行結果が出ました。メソッドの仕様上'trends'の要素は50個取得されるため、...で省略しました。この実行結果から、testTrendsは特殊な辞書型変数だと分かります。なぜ特殊かというと、辞書の要素がリストだからです。
content = testTrends["trends"][:1]
print(content)
上のコードでtrendsキーの要素をcontentに格納します。ちなみに[:1]は50個のトレンド内容から1個だけ取り出すためのスライス操作です。
[{'name': '#ひきこもりたちでもフェスがしたい', 'url': 'http://twitter.com/(略)',
'promoted_content': None, 'query': '%23(略)', 'tweet_volume': None}]
このような結果になりました。ここからnameキーの要素を取り出したいのですが、これはリストなのでなかなか取り出しづらいです。
for content in testTrends["trends"][:1]:
print(content['name'])
なので、for文を使ってリスト型変数を辞書型に変換してcontentに格納します。その後、nameキーの要素を出力させます。
# ひきこもりたちでもフェスがしたい
トレンド内容を取得できることが分かります。
結果(メインコード)
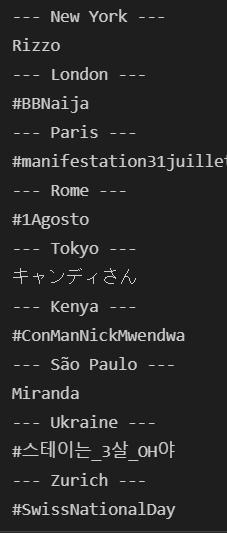
無事に世界各地のトレンドを調べることが出来ました!
Excelに出力
import datetime
import xlsxwriter
# エクセルファイルを作成、または既存のファイルを開く
wb = xlsxwriter.Workbook('trend.xlsx')
# エクセルシートを作成
ws = wb.add_worksheet("sheet1")
# 日付の書式設定
format = wb.add_format()
format.set_num_format('yy/mm/dd')
# セルに書き込み
ws.write(0, 0, "Place")
ws.write(0, 1, "Trend")
ws.write(0, 2, "Data")
j = 1
for area, wid in woeid.items():
ws.write(j, 0, area)
trends = api.trends_place(wid)[0]
for content in trends["trends"][:1]:
#トレンドをプリント
ws.write(j, 1, content['name'])
#日付をプリント
ws.write(j, 2, datetime.date.today(), format)
#改行用
j = j + 1
wb.close()
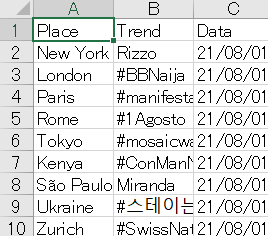
このように場所、トレンド、日付が書かれた表がプログラムファイルと同じ場所に出力されます。
参照サイト
https://www.pytry3g.com/entry/python-twitter-api
https://kurozumi.github.io/tweepy/api.html
https://muftsabazaar.com/blog/category/?c=WOEID