複数のCPUとメモリが一つのシステムに乗せられたNUMAアーキテクチャという構成が採用され始めている。
NUMAの目的はI/Oバスの並列化である。
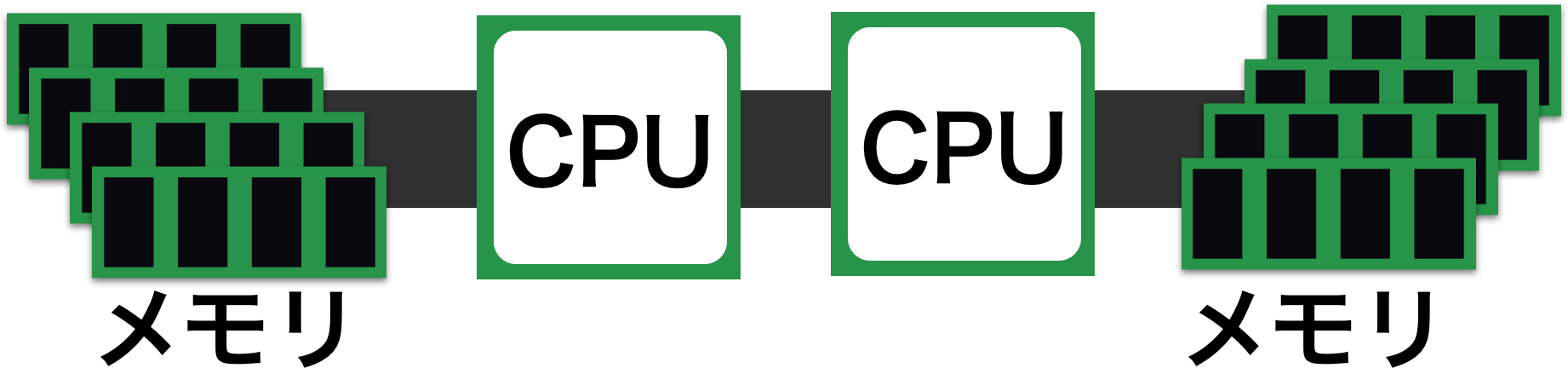
極端に例えると、コア数が50個あった場合、一つのメモリバスを使った構成よりも、
25コア25コアの2CPUで2つのメモリバスを使った構成の方が早くなる。
14GB/sのメモリバスだった場合、メモリバスを2つにすれば28GB/sの性能がでる。
(1秒間に送れるデータ量が増える。)
このようにNUMAは、コア数が増えることによるメモリバスネックの対策であり、マルチコア化も進んでいるため、今後NUMAにふれる機会が増えてくるはずである。
どんな時に考える?
多くのメモリ転送を使う計算をするときは、NUMAによる影響が発生するかもしれない。
設定によってはNUMAの影響を大きく受けてしまう可能性もある。
numaのメモリ割り当てを制御するコマンド
[1] --localallocオプション
numactl --localalloc RUNFILENUMA環境を使っていて、高速化したいのであれば、このコマンドを使うだけで良い。
これで自然とデータがCPUに近い方のメモリに割り当てられる。
[2] --interleaveオプション
numactl --interleave=all RUNFILE環境によっては、このコマンドの方が性能が出る場合もある。
([2]の方が性能が出る場合は、OS側によるメモリ割り当てがあまり賢くなってない場合に多い。
データを均等に各メモリに分割するコマンド。
この場合、多くのメモリを使うプログラムで、numactlを使用せずに./a.outなどでファイルだけの実行をすると性能の振れ幅が10GFlopsであったり20GFlopsであったりかなり大きくなったりする。)
NUMA(Non-uniform memory access)アーキテクチャとは
複数のCPUによって構成されるアーキテクチャ。
CPUによってメモリ性能が異なるものをNUMAと呼ぶ。
例えばCPUが2つある場合は、このような構成になる。
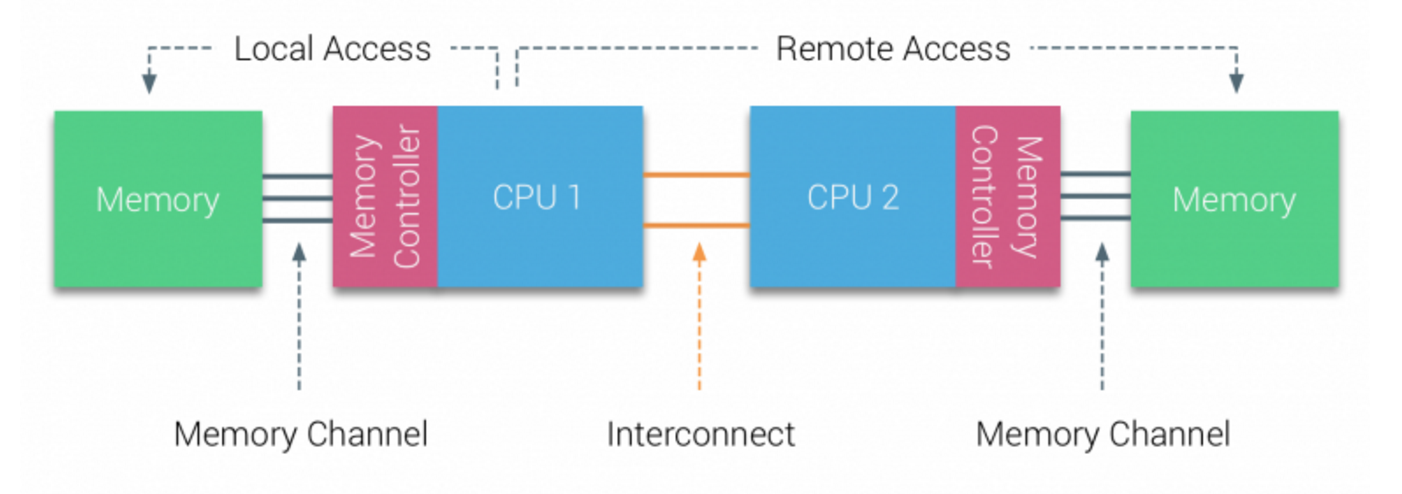
(http://frankdenneman.nl/2016/07/07/numa-deep-dive-part-1-uma-numa/ から参照)
メモリアクセスをするときは、当然Local Accessの方が早くなる。
均等に読み込むデータをメモリに分割し、複数のCPUで同時にLocal Accessするのが一番早い。
逆にRemote Accessが発生してしまうとCPUをまたいでメモリアクセスをするので性能に影響が出る。
ノード(Node)とは
NUMAはCPUとローカルアクセスをするローカルメモリのセットをノードという単位で表す。
NUMAの影響が発生する状況
スーパーコンピュータによるCPUベースで行う演算
サーバで大容量のメモリを使う演算
numactlとは
アプリケーションで使用するメモリとCPUを指定できるLinuxコマンド。
numactlのオプション
numactlを使用して使用するメモリやCPUを操作しましょう!
--hardware, -H
使用してる環境でのNUMAの構成を表示する。
numactl --hardware
numactl -H
available: 2 nodes (0-1)
node 0 cpus: 0 1 2 3 4 5 6 7 8 9 10 11 12 13
node 0 size: 130958 MB
node 0 free: 84791 MB
node 1 cpus: 14 15 16 17 18 19 20 21 22 23 24 25 26 27
node 1 size: 131072 MB
node 1 free: 101191 MB
node distances:
node 0 1
0: 10 21 --show, -s
numaのノード数やコア数を表示
numactl --show
numactl -s
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27
cpubind: 0 1
nodebind: 0 1
membind: 0 1
physcpubindは合計のコア数がわかる。
cpubind,nodebind,membindは0,1の、2つのノードがあることがわかる。
policyには、--interleaveオプションをつけるとinterleaveと表示される。(メモリ割り当ての状態が分かる。)
--interleave=nodes, -i nodes
指定したノードのメモリに均等にデータを分割して保存するようにする。
numactl --interleave=all ./a.out
numactl --interleave=0,1 ./a.out
numactl --interleave=0-1 ./a.out
--membind=nodes, -m nodes
使用するメモリをノード単位で指定する。
numactl --membind = 0-1 ./a.out
numactl --membind = 0,1 ./a.out
numactl --membind = 0 ./a.out
--cpunodebind =nodes, -m nodes
使用するCPUをノード単位で指定する。
numactl --cpunodebind = 0-1 ./a.out
numactl --cpunodebind = 0,1 ./a.out
numactl --cpunodebind = 0 ./a.out
--physcpubind=cpus, -C cpus
使用するCPUをコアの単位で指定する。
numactl --physcpubind = 0-5 ./a.out
numactl --physcpubind = 0,1,2,3,4,5 ./a.out
numactl --physcpubind = 0 ./a.out
numastat
各ノードでのNumaの状態を表示する。
numastat node0 node1
numa_hit 5932784098 10154919387
numa_miss 645547781 144163554
numa_foreign 144163554 645547781
interleave_hit 364243 403249
local_node 5917757532 10154664878
other_node 660574347 144418063
free -m
メモリの状態をMB単位で表示する。
free -m total used free shared buff/cache available
Mem: 257675 29175 175486 652 53013 202381
Swap: 20003 0 20003
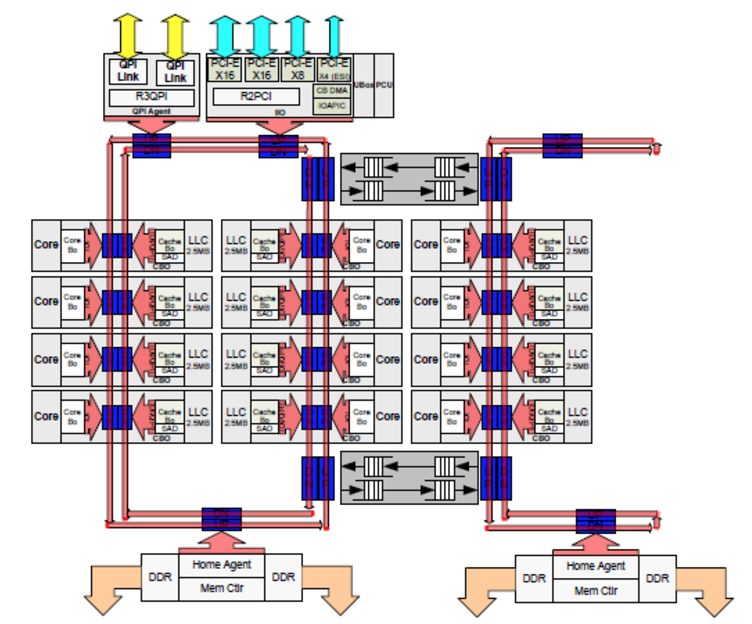
CPUの構成
サーバでなどで使われているHaswell-EPシリーズのCPUの内部の構成はこうなっている。
NUMAでは、このQPIによってCPUとCPUを繋いである。
QPIはCPUとCPUを繋ぐバスである。
DDRはCPUとメモリを繋ぐバスである。
実はHaswellアーキテクチャなどではCPUのチップの内部でもさらにNUMA構成となっている。
コア1とコア15だと、各コアから近いメモリがそれそれ存在する。
参考文献
Introduction 2016 NUMA Deep Dive Series
http://frankdenneman.nl/2016/07/06/introduction-2016-numa-deep-dive-series/
numactlリファレンス
https://linux.die.net/man/8/numactl
redhat numactl, numastatの説明
https://access.redhat.com/documentation/ja-JP/Red_Hat_Enterprise_Linux/6/html/Performance_Tuning_Guide/main-cpu.html
CPUアーキテクチャの種類
http://kowadaru.com/codename-list
NUMAアーキテクチャ_WIKIPEDIA
https://ja.wikipedia.org/wiki/NUMA
ルーフラインモデル
https://people.eecs.berkeley.edu/~waterman/papers/roofline.pdf