はじめに
技術チャレンジ部のとも(Tomo)です。
【2024年最終】AMD APUでStable Diffusionを動かす(stable-diffusion-webui編)では、AMD APU上のstable-diffusion-webuiでStable Diffusion 1.5が動くことまで確認できました。
噂のStable Diffusion 3.5を動かすために、グラフ画面がかっこいいComfyUIを試してみます。
画像生成AI花盛りなのに、全く試せておらず、素人です。
ROCmは公式にはAPU非対応で、記事の内容は無保証です
環境
ミニPC(再掲)
- APU: AMD Ryzen 7735HS
- CPUコア: ZEN3+
- iGPUコア: RDNA2
- メモリ: 32GB
- BIOS設定で
16GBをGPUに割り当て最終的には変更することに…(後述)
- BIOS設定で
- SSD: 1TB
ソフト選択
OSは、前の記事のUbuntu 24.04 DesktopにROCmを入れた環境をそのまま利用。
stable-diffusion-webuiの時と同じように、rocm/pytorchのDockerイメージをベースに…と考え試行錯誤、結果Pythonパッケージのバージョン問題の壁にぶつかる…。
ComfyUIのREADMEを見ると、Python 3.12がお勧めとあるけど、rocm/pytorchのDockerイメージのPythonは3.10.15だったのを思い出す。
調べるとUbuntu 24.04のPythonは3.12。 UbuntuのPythonをそのまま使うのがよい気がしてきました。
…というわけで、今回はUbuntu 24.04のPython3.12をvenvで使うことにしてみます。
インストール
venv
sudo apt install python3-venv
venvの準備
python3 -m venv ComfyUI-venv
source ComfyUI-venv/bin/activate
cd ComfyUI-venv
以下はvenvがactivateされた状態で実行。
PyTorch(ROCm)
PyTorch本家のINSTALL PYTORCHのチャートで、Stable-Linux-Pip-Pythonを選ぶと、ROCmは6.2になり、以下の手順が表示されるので、そのまま使用。
入れたROCmは6.3.1だけど、まいっかと軽い気持ちで入れてみます。(+フラグにならないようにお祈り)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/rocm6.2
ComfyUI
git clone https://github.com/comfyanonymous/ComfyUI.git
cd ComfyUI
pip install -r requirements.txt torchsde
torchsdeが足らないっぽいので追加。
モデルの設置
Stable Diffusion 3.5の紹介Blogを見ると、Mediumしか動かなさそうなので、Mediumを選択。
Stable Diffusion 3.5のダウンロードは、Hugging Faceへのログインが必要。
Hugging Faceにログインし、Stable Duffison 3.5のリポジトリにアクセス、私は個人利用なのでCommunity Licenseに同意。
どれをダウンロードすればよいのかよく分からず、適当に以下をダウンロード、
- sd3.5_medium.safetensors -> ComfyUI/models/checkpoints/ に
- text_encoders/*.safetensors -> ComfyUI/models/clip/ に
- vae/diffusion_pytorch_model.safetensors -> ComfyUI/models/vae/ に
それぞれ設置。
実行
ComfyUI
GPUアーキテクチャを適当に設定してお試し実行。
前回と同じく別ホストからアクセスしたかったので--listenを追加。
HSA_OVERRIDE_GFX_VERSION=10.3.0 PYTORCH_ROCM_ARCH=gfx1030 python main.py --listen
ブラウザでアクセス
http://IPアドレス:8188/にアクセス。
デフォルトのグラフが表示され、動いたよ! …という感動も束の間、いろいろ起こるのが当方のお約束。
エラー対応
'NoneType' object has no attribute 'tokenize' - Models`
画像生成が始まらず、上記エラーから進まない。
デフォルトのグラフから、まずは「チェックポイントを読み込む」ノードのckpt名を、sd3.5_safetensorsに変更。
デフォルトのグラフでは、「チェックポイントを読み込む」ノードからCLIPの黄色い線が2本出て、2つの「CLIPテキストエンコード(プロンプト)」ノードに接続されているけど、これを切断、「トリプルCLIPを読み込む」ノードから接続するよう変更。
「トリプルCLIP」ノードは、右クリック->Add Node->高度な->ローダー->トリプルCLIPを読み込む、で作成。
clip_name1~3は、clip_g.safetensors, clip_l.safetensors, t5xxl_fp16.safetensorsをお試しで設定。
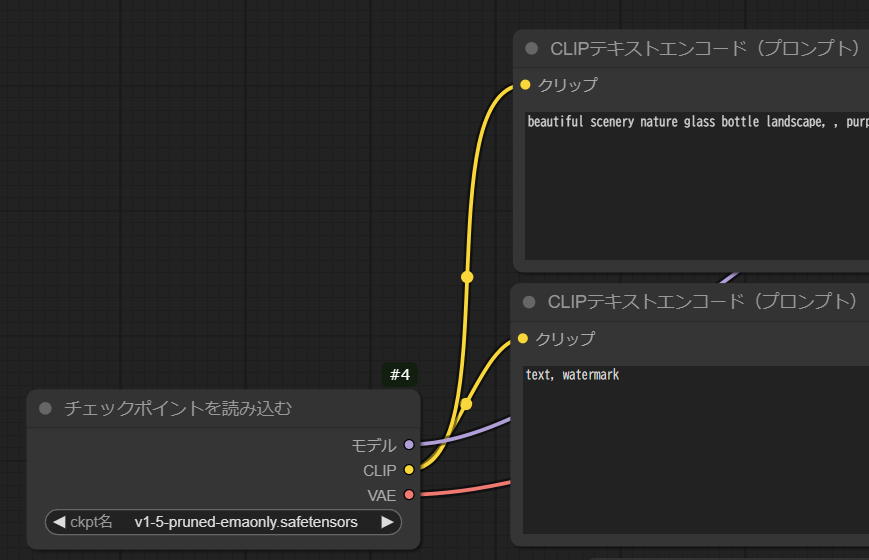
を、
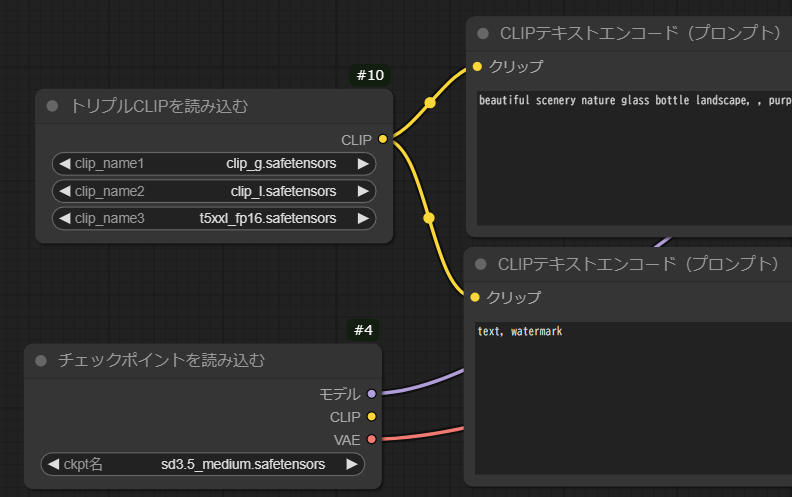
のように変更するイメージ。
OOM(Out Of Memory)
これで生成が始まるようになったが、PyTorchとLinuxカーネルでOOMが出まくる。メモリが足らない。VRAMとメインメモリ、両方足らない?
OOMになるほど大きなメモリが必要となるのは、ある意味期待値なので良いことでもあるのですが…。
fp16からfp8に変更しても、変わらず。
起動時のTotal VRAM 7883 MB, total RAM 15766 MBという表示が気になる。VRAMを16GB分認識していないっぽい。
ComfyUIの--highvramや--gpu-only, --reserve-vramなどのオプションを試すが、OOM発生は変わらず。
rocm-smi --showmeminfo vramで見ると、VRAM Total Memory (B): 17179869184で認識している。
amd-smi metricで見ると、TOTAL_VRAM: 16384 MBで認識している。
カーネル起動パラメーターにamdgpu.gttsize=16384などと追加すると、amd-smi metricのTOTAL_GTT: 7883 MBが変わるけど、ComfyUI起動時のTotal VRAM 7883 MBは変わらず。
色々調べて、APUでPyTorchを動かす際の限界、APU非対応とはこういうこと、と理解…。
そこで。
force-host-alloction-APUの利用
こちらとこちらが大変にお詳しい。
最初全く理解できなかったのが、自分が課題に直面すると、そういうことか…と漠然と理解。
PyTorchのメモリをメインメモリから取るように関数をフックするライブラリのようです。
ビルド
公式にある
CUDA_PATH=/usr/ HIP_PLATFORM="amd" hipcc forcegttalloc.c -o libforcegttalloc.so -shared -fPIC
を試したところ、ld.lld: error: unable to find library -lstdc++で、ビルドが通らず…。
ライブラリパスを追加したところ、ビルドが通りました。
13は適当。14ではダメだった。ちなみにgccは13.3.0でした。
CUDA_PATH=/usr/ HIP_PLATFORM="amd" hipcc -L/usr/lib/gcc/x86_64-linux-gnu/13 forcegttalloc.c -o libforcegttalloc.so -shared -fPIC
実行
メインメモリからVRAMを取るのなら、BIOSによるVRAM確保設定はもはや不要(というか邪魔)、BIOSのVRAM設定はAutoに戻す。
libforcegttalloc.soをComfyUIのディレクトリに設置。
LD_PRELOADでlibforcegttalloc.soを指定。
ROCm 6.0ではHSA_ENABLE_SDMA=0を付けた方がよいようなので、これも追加。
--highvramは、
By default models will be unloaded to CPU memory after being used. This option keeps them in GPU memory.
とのことで、メインメモリから確保するなら引越し不要そうなので、これも追加。
結果
HSA_OVERRIDE_GFX_VERSION=10.3.0 PYTORCH_ROCM_ARCH=gfx1030 HSA_ENABLE_SDMA=0 LD_PRELOAD=./libforcegttalloc.so python main.py --highvram --listen
Total VRAM 15903 MB, total RAM 31806 MBと表示された。やった!
ざっくり時間とメモリ消費
- デフォルトのフローで、100秒, 20GBくらい?
今後の調査ネタ
-
TORCH_ROCM_AOTRITON_ENABLE_EXPERIMENTAL=1+--use-pytorch-cross-attentionの効果(とりあえず有効にしちゃった)
おわりに
Strix Haloが高性能そうとか96GBまで割り当てられそうといった噂にもロマンを感じつつ、きっと買えない…。
RDNA2世代のiGPUでは遅いかもしれないけど、楽しいのと夢があってヨシ!
ROCmがんばって! がんばろう!