最近はPythonでもMATLABでもGPU処理のアドオンやライブラリが出てきて、以前よりもGPUの活用がしやすくなっています。しかし、なんだかんだ言ってCUDAでプログラミング直書きするのが最も高速なコードを書けます。何故かというと、GPUとCPU間の同期処理や、転送、メモリの確保などを全部ライブラリがやってしまうので、それらの面での最適化ができません。まぁライブラリってそういうもんなのですが、リアルタイムでCGレンダリングするなどのレベルになるとCUDA直書きになってしまいます。
そういった前例のないオリジナル処理をcudaで組む場合、各変数の動きとか配列外参照などを事前にチェックしておきたいということがよくあります。それ自体はどの言語でも一緒だと思いますが、特にcudaは並列処理が基本になっているため、デバッグツールが使いにくく、どこが間違っているのか発見しにくいのでここ最近まで困っていました。
このアドベントカレンダーを主催している@motorcontrolman さんはSimulink過激派として活動されていますが、私はMATLAB原理主義者なのでcudaでのアルゴリズム計画をMATLABで立てる手法を考えてみました。誰に需要があるのかわからないですが、半ば自分のためにここに書いておきます。
1. MATLAB Coderを使うか否か
手っ取り早くcudaにしたいんだったらMATLAB Coderを使う手があります。ゆるゆるgpu実装ならそれでいいのですが、速度を求める方にはあまりお勧めしません。なぜならgpuコーディングとmatlabのようなcpuコーディングでは思想が全く違うことがよくあるのと、メモリコピーなどの最適化まではよほどやってくれないためです。
思想が違うというのは、例えばMATLABで以下のような総和をとる処理を自作したいとしましょう。
入力: a = [a1, a2 , a3, ..., aN]
出力: b = a1 + ... + aN
cpuベースのコーディングならこうするでしょう。
% a, Nは定義済みとする。
for idx = 1:N
b = b + a(idx)
end
※MATLABならsum()で書けるよ!便利だね!
しかしGPUはこの単純に見える処理でさえ工夫が必要です。上記のやり方では1スレッドが配列の参照先をシフトしながら順番に足し算するので、計算量は$O(N)$です。これでは全く並列化できていないのでGPUでは違うやり方をします。
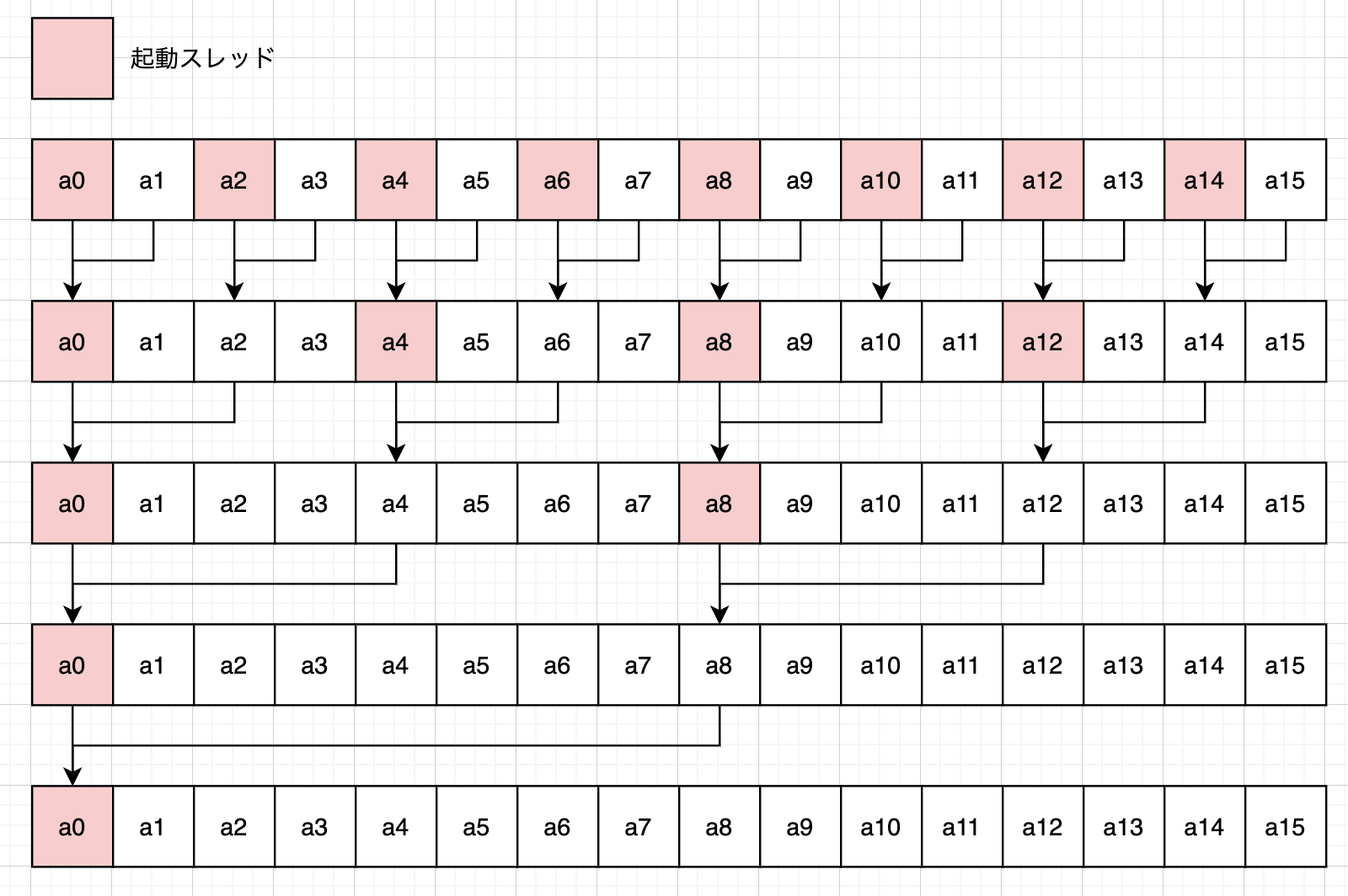
16要素の配列の和を取るときは図のように、まずは隣同志を足して、次に2こ隣を足して・・・とやっていきます。こうすることで$O(\log2(N))$のオーダーで計算が終わります。
MATLAB Coderではこのギャップを埋めてくれないことが多々あるのと、CPU-GPU間のメモリ転送の最適化などはやってくれないので、あくまでゆる実装になってしまいます。
2. 何とかMATLABでCUDA的な記述がしたい!
MATLABでなくともシングルスレッドのプログラミングではこの思想のギャップを自動では埋めてくれないので、私はこんなワークフローでCUDAを組んでいます。
- MATLABで処理の計画立てとチェック
- cudaに自力で実装
という流れをとっています。一見面倒ですがcudaのデバッグの方が厄介なので、MATLABでアルゴリズム検証だけでもやっておくと、結果スピーディーに最適なコードが書けます。特になんかしらのシミュレーションを組むときは式そのものが合ってるかの確認もしたいのでインタプリタ型のMATLABは優秀です。
2-1. blockループとthreadループの2重ループ系にする。
GPUの並列インデックスは少しややこしく、ブロックとスレッドという概念があります。スレッドは皆さんの想像と同じく処理が行われる単位で、ブロックはスレッドを(最近は1024スレッド)束ねているものです。ブロックとスレッドにはそれぞれインデックスがあるのですが、スレッドインデックスが通常イメージするものではなく、ブロック内で閉じたインデックスになっています。
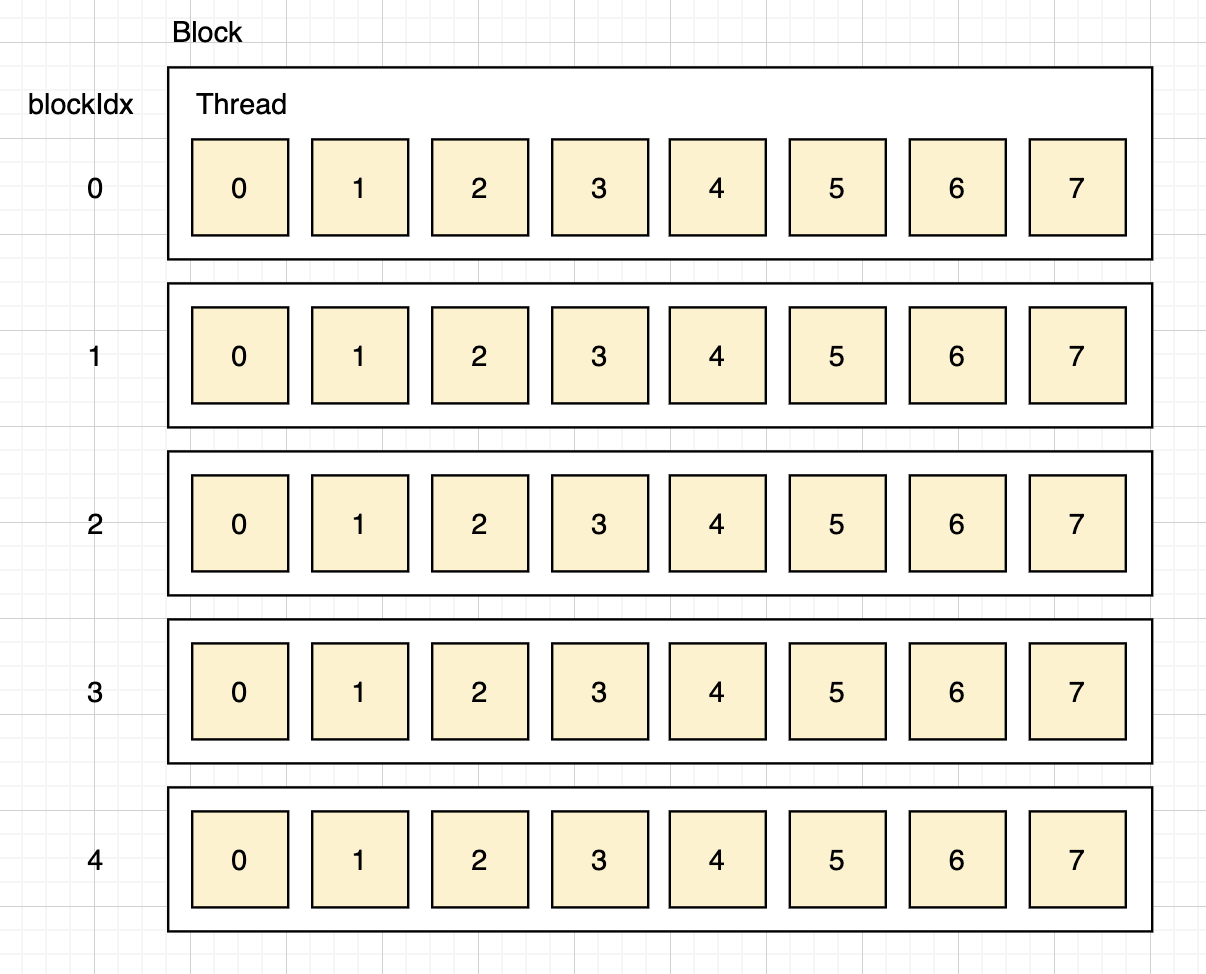
なので、通常イメージするような、処理一つ一つに一対一対応するスレッドインデックスを、CUDAカーネルに突入したときに計算します。
__global__ void Hoge(int num, T* a){
// blockDim.xはブロック内のスレッド総数
const int idx = blockDim.x * blockIdx.x + threadIdx.x;
if(idx >= num){
return;
}
// 以下何かの計算
}
コードを見るとわかりますが、ブロックとスレッドは3次元の値を持つので、その時はまためんどくさい計算が必要です。
そして、ブロックインデックスとかスレッドインデックスを独立に使うこともあるので、単純に大量の並列をするのとは違った考え方をしなければならないことがあります。
このGPUの特殊性をいかにしてMATLABで模擬するかですが、ポイントは以下の通りかなと思います。
- スレッド間(配列の要素間と読み替えて差し支えない)の同期が保証されない。
- blockIdxとthreadIdxが特別な処理を挟まずに使えること。
- あくまでアルゴリズムの検証がしたい。
1.について、GPUは並列計算だとはいうのですが、各スレッドが完全に同時に動くわけではなく、内部的に自動でスケジューリングされて実行されます。なので、MATLABでいう以下のような処理は使わないようにしなければいけません。
a = [1, 2, 3, 4, 5];
b = [6, 7, 8, 9, 10];
a = a + b;
b = a + b;
これをGPUで同期を気にせずに書くと、a = a + bまでは重複読み出しなどが起きないので上手く行くのですが、あるスレッドがa = a + bをやってる最中に他のスレッドがb = a + bを行うことがあるので、GPUではこの間に明示的に同期を取らなければなりません。
2.について、CUDAではblockIdxとthreadIdxで配列のインデックスidx = blockDim * blockIdx + threadIdxを求めるわけですが、先も述べた通りblockIdxとthreadIdxを単体で使用することもあるため、これがさらりと使えるようにしたいところです。
3.についてですが、MATLABでやりたいことはあくまでアルゴリズム検証であってGPU最適化ではないです。CUDAでは先程の同期にいくつか種類がある(block内だけで同期をとるのか、GPU全体で同期をとるのかなど)のですが、どの同期を使うかは最適化の領域なので、MATLABでは区別しなくてもいいです。
これらを成立させるいい方法がblockループとthreadループの2重ループ系を作ることです。コード的にはこんな感じになります。
% 扱う配列の要素数
N = 1000;
blockDim = 512;
blockNum = floor((N + blockDim - 1) / blockDim);
for blockIdx = 0:blockNum - 1
for threadIdx = 0:blockDim - 1
% forの中身がほぼそのままCUDAカーネルになる。
% CUDAでよく使うインデックスの算出方法をそのまま使える。
idx = blockDim * blockIdx + threadIdx;
% 以下なんかしらの処理
end
end
このやり方のいいところは2重for内がCUDAカーネルの記述に近いところです。これで検証できればfor内をほぼそのままCUDAに写せば動きます。ただしインデックスとかには注意です。
最初に示したポイントを満たすか見てみると
スレッド間(配列の要素間と読み替えて差し支えない)の同期が保証されない。
forループなので配列要素間の同期は保証されないどころか全く同期しません。クリアです。
blockIdxとthreadIdxが特別な処理を挟まずに使えること。
blockIdxの配列を作るとかthreadIdxの配列を作るとかはしていないのでクリアです。
あくまでアルゴリズムの検証がしたい。
懸念していた同期についてはforを分けることで実現できるので弊害はない。
3. 問題点もいくつかある。
forループを2重にすることでMATLABでもCUDAの検証ができるようになりました。
でもいいことばかりではありません。ここで気をつけるべきこととあんまり良くないところをあげておきます。
3-1. おっせぇ
CUDAでやらせようとしているものをCPUで組んでみるだけでも遅いのに、MATLABのようなインタプリタ型の言語で組んだら当然ですが遅いです。しかもMATLABの得意な配列計算をわざわざforに分けているので余計に遅い。。。ここは良くないところ。
3-2. インデックスが1スタート
CUDAはc++に則っているのでインデックスは0スタートです。MATLABで検証しているとたまにこんがらがります。できる限り0スタートで記述して、配列の読み書きの時だけ+1するようにして回避しています。
4. いいところ
ここまで聞くとc++ とかpythonでデバッグ実行するのと何が変わらんのやという感じがしてきますが、ここはMATLABのハードルの低さが活きてくれます。いいところも紹介しておきましょう。
4-1. グラフとかが簡単に出せる。
MATLABの豊富なグラフィック群を使って、GPU内部の動きを可視化することができます。重複読み書きが起こっていないかなどをすぐ確認できるので便利です。
4-2.ドキュメント化できる。
ライブエディタで組んでおけば数式や図も交えた解説書が勝手に出来上がります。アルゴリズム検討→テスト実装→検証→解説ドキュメント作成のフローを、全て同時にこなせてしまいます。手間激減。
4-3. 最後に
とはいえやはりインデックスが1スタートの問題は結構足を引っ張ってきます。何かいい方法があったら教えて欲しいです。