前提
サンプル
こんなHTMLドキュメントがあったとして、
<html>
<head>
<title>Lightweight language</title>
</head>
<body id="test_id">
<h1>Lightweight language</h1>
<div>
<ul>
<li>
<a href="link_ruby" title="ruby">Ruby</a>
</li>
<li>
<a href="link_python" title="python">Python</a>
</li>
<li>
<a href="link_php" title="php">PHP</a>
</li>
<li>
<a href="link_perl" title="perl">Perl</a>
</li>
</ul>
</div>
</body>
</html>
ここから「各言語とそのリンク」を抽出したい
require 'open-uri'
require 'nokogiri'
html = Nokogiri::HTML.parse(URI.open('/tmp/test.html'))
# 親タグとして `body(id="test_id") 直下に div 直下に ul 直下に li` を持つ `aタグ` を取得
# ちなみに、`直下` 限定せずに `配下` にあれば良い場合は、`>` の代わりに ` ` を指定する
# html.css('body[id="test_id"] a').each do |a|
html.css('body[id="test_id"] > div > ul > li > a').each do |a|
p a.text.strip
p a[:href]
end
=>
"Ruby"
"link_ruby"
"Python"
"link_python"
"PHP"
"link_php"
"Perl"
"link_perl"
他にも色々できて、例えば、対象ドキュメントのテキスト内容を全てくっ付けて返してくれる
html = Nokogiri::HTML.parse(open('/tmp/test.html'))
p html.text
=>
"LightweightlanguageLightweightlanguageRubyPythonPHPPerl"
利用方法の大枠
ツリーを構築/検索して、ノードを参照する
- ツリーの構築
- HTMLやXMLのドキュメントを解析して
Nokogiri::HTML::Documentに変換
- HTMLやXMLのドキュメントを解析して
- ツリーの検索
- 検索系メソッドを利用して探索を行い、目当てのノードを特定する
- ノードの参照
- 取得できた
Nokogiri::XML::NodeSetまたはNokogiri::XML::Elementから目当てのデータを抽出する
- 取得できた
ツリーの構築
解析の種類
DOMの他にもSAXやReaderやPullがあるらしいけど、有名どころのDOMについて説明する
DOM 解析
Nokogiri では HTML/XML ドキュメントのどちらも解析できる
doc = Nokogiri::HTML.parse(html_document) # HTML ドキュメントの解析
doc = Nokogiri::XML.parse(xml_document) # XML ドキュメントの解析
- 第1引数には、IO オブジェクトまたは文字列オブジェクトを指定する
- open_uri を直接 Nokogiri に渡すことも可能(文字列を使用するより若干効率は上がるらしい?)
- 第3引数には、対象ページの文字コードを指定する
- 解析対象の文字コードが UTF8 以外の場合、大抵解析が失敗するので指定する
- 第2引数はURL、第4引数はオプション、どちらも大抵は指定せず事足りる
オブジェクトの可視化
html = Nokogiri::HTML(open('/tmp/test.html'))
メモリ上ではどのようなオブジェクトが作られているのか
簡略化するとこんなツリー状のオブジェクトが作られている
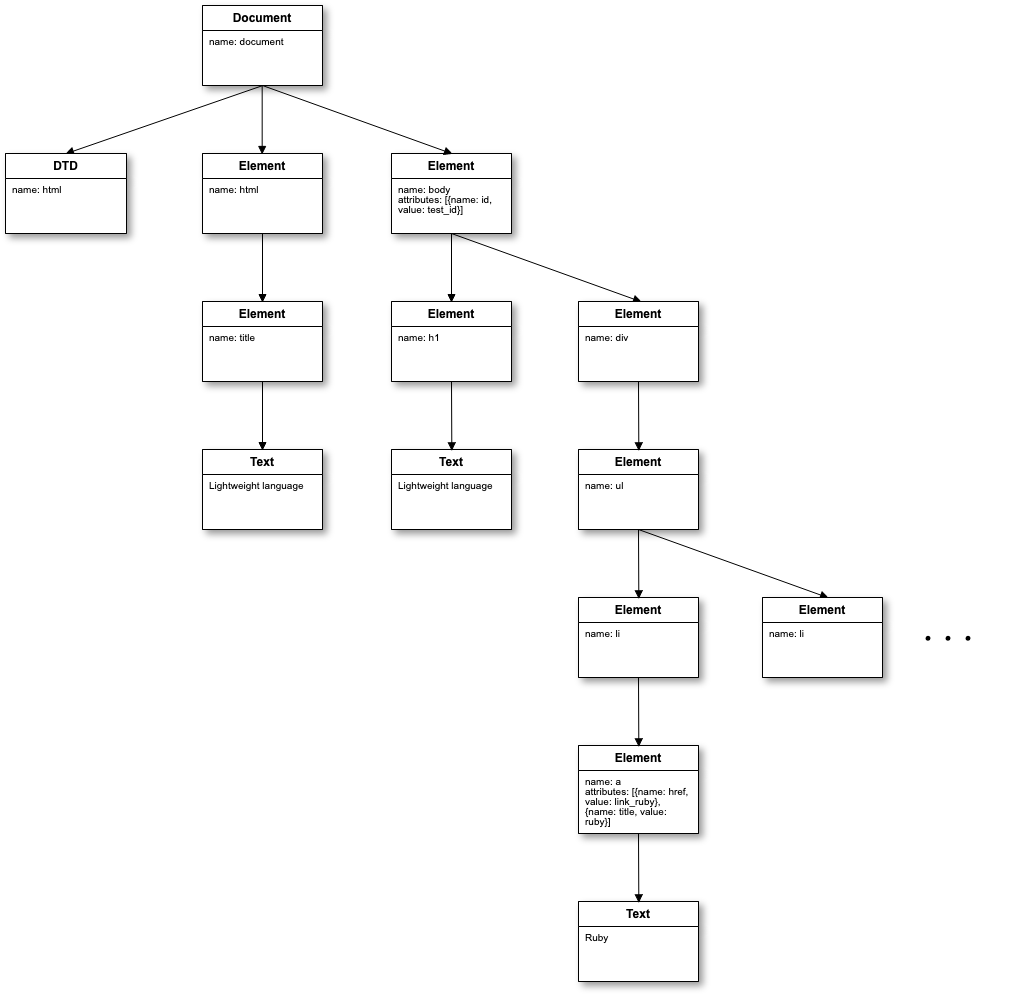
各オブジェクトについて
- Nokogiri によって、複数のオブジェクトが作成されている
-
Nokogiri::XML::DocumentとかNokogiri::XML::Elementとか
-
- 全てのオブジェクトがノードである
-
Nokogiri::XML::Nodeを継承している- Nogogiri::XML::NodeSet < Enumerable
- Nokogiri::HTML::Document < Nokogiri::XML::Document < Nokogiri::XML::Node
- Nokogiri::XML::Element < Nokogiri::XML::Node
- Nokogiri::XML::Text < Nokogiri::XML::CharacterData < Nokogiri::XML::Node
- etc...
- 検索系のメソッドは
Nokogiri::XML::Nodeにまとまっているため、同じ検索メソッドがこれらオブジェクトに対して使える
-
他にも色々あるけど、作られているオブジェクトの説明を簡単に
- Nokogiri::XML::Node
- ノードに対する操作や検索処理を規定する
- 具体的には、
Nokogiri::XML::Searchableをincludeして各種メソッドを実装- SearchableはDOM検索のインターフェース
- Nokogiri::XML::NodeSet
- Nokogiri::XML::Node オブジェクトのリストを持つ
- Nokogiri::XML::Searchable#css/#xpathの実行結果
- Nokogiri::HTML::Document
- Nokogiriによって解析されたHTMLドキュメント
- Nokogiri::HTML.parseの戻り値
- Nokogiriによって解析されたHTMLドキュメント
- Nokogiri::XML::DTD
- 対象ドキュメントが DTD による文書構造に従っているかどうかを検証している?
- Nokogiri::XML::Element
- Nokogiriで HTML 要素を扱うためのオブジェクト
- C 拡張なのできっと早い
- Nokogiriで HTML 要素を扱うためのオブジェクト
- Nokogiri::XML::Text
- Nokogiri で HTML テキストを扱うためのオブジェクト
ツリーの検索
検索方法
大まかに 3 種類
- XPath
- XML形式の文書から特定の部分を指定して抽出するための簡潔な構文
- CSS
- ウェブページのスタイルを指定するための言語
- その他
- child とか parentとか相対的に位置を特定する
よくある流れ
-
Nokogiri::HTML::Documentオブジェクトに対して、CSSセレクタやXPathで検索を行い、検索結果としてNokogiri::XML::NodeSetオブジェクトを取得 - NodeSet は Node のリストは配列のように扱えるため、each や [] で該当ノードである Element を特定する
- CSS や Xpath は NodeSet を返すが、at や child など Element を返すものもあるので要確認
検索メソッド
よく使うであろう Nokogiri::XML::Node のメソッドについて
Nodeset と Element 両方に対して使える
XPath
親タグとして body(id="test_id"), div, ul を持つ li 全てを検索
html.xpath('//body[@id="test_id"]/div/ul/li').each do |li|
p li.text
p li.at('a')[:href]
end
- 引数について
- 冒頭の
/が階層構造のルートを表す - その他の
/で各タグの階層情報を指定 -
/の間に何もない場合は、配下にあることを示す -
divやulはタグ名の指定-
*は、任意のタグに一致するワイルドカードとして使える
-
- 属性(例えばidの値とか)を指定するときは
タグ名[@属性名=xxx]を使う - 引数は複数指定できる
- 冒頭の
- 戻り値について
- NodeSet を返す
- 結果が無ければ空の NodeSet
- その他
- 現状 CSS では、実現できないことができる(2022/10/14)
CSS
上記を CSS で置き換える
html.css('body[id="test_id"] > div > ul > li').each do |li|
p li.text
p li.at('a')[:href]
end
- 引数について
-
/の代わりに>または空白を使う -
>は親タグ直下のタグを指定したいときに使う- xpathで言う
//h3/a- h3 直下に a が来る
- xpathで言う
- 空白はタグ間に任意のタグを許容したいときに使う
- xpathで言う
//h3//a- h3 と a 間に任意のタグを許容する
- xpathで言う
- 属性(例えばidの値とか)を指定するときは
タグ名[属性名=xxx]を使う - class 属性の包含を指定するときは タグ名.class名 を使う
-
タグ名[属性名=xxx]は完全一致する必要がある
-
- テキストから検索したいときは
タグ名:contains("テキスト")を使うhtml.at('a:contains("Ruby")')
- 引数は複数指定できる
-
- 戻り値について
- NodeSet を返す
- 結果が無ければ空の NodeSet
補足
- 便利メソッド
-
search("検索")- 引数に XPath または CSS を指定できる
- 戻り値として、NodeSetを返す、無ければ空の NodeSet
-
at("検索")- 引数に XPath または CSS を指定できる
- 戻り値として、最初のノードの Element を返す、無ければ nil
-
- ChromeやFirefox(Firebug)で指定タグのパスが抽出できる
- Chrome の場合
- バージョン: 106.0.5249.103(Official Build) (x86_64)
- 開発者コンソールを開いて、Elements タブで該当要素を選択する
- 右クリックして、
Copy > Copy Selector / Copy XPathでコピペ
- Chrome の場合
その他
ノードを指定して任意の相対ノードにアクセスできる
- child
- 最初の子ノードが Element で返る
- children
- 子ノード(Element)の配列が返る
- previous_sibling、previous
- 兄ノードが Element で返る
- 手前にあるノード
- 兄ノードが Element で返る
- next_sibling、next
- 弟ノードが Element で返る
- 後にあるノード
- 弟ノードが Element で返る
- parent
- 親ノードが Element で返る
- ancestors
- 祖先ノード(Element)の配列が返る
ノード情報の参照
ノードに関する情報を取得するためのメソッド
基本的に Nodeset と Element 両方に対して使えるが一部例外あり
ドキュメントの参照
Nokogiri::XML::Node と NodeSet で基本的には同じ API が使えるが、一部のメソッド(content、to_str)がない
NodeSet の場合、リスト内の全てのノードに対してメソッドを適用した結果を返してくれる
- to_s
- ノード全体のテキストをつなぎ合わせた文字列が返る
- content、text、inner_text、to_str
- 子孫ノードのテキスト内容をつなぎ合わせた文字列が返る
- エイリアス多
- to_html、 to_s
- ノード全体HTMLをつなぎ合わせた文字列が返る
- 本人ノードも含めた inner_html
- ノード全体HTMLをつなぎ合わせた文字列が返る
- to_xhtml、 to_xml
- ノード全体を XHTML をつなぎ合わせた文字列が返る
- inner_html
- 子孫ノードの HTML をつなぎ合わせた文字列が返る
属性情報の参照
通常の Ruby ハッシュのように扱える
Element に対して使う
- ["属性名"]、get_attribute("属性名")
- 属性値を文字列で返す、無ければ nil
- key?("属性名")、has_attribute?("属性名")
- 属性の有無をtrue/falseで返す
- keys
- 属性名を文字列の配列で返す
- values
- 属性値を文字列の配列で返す
- attributes
- 属性名と属性オブジェクトのハッシュを返す
- attribute("属性名")
- 属性オブジェクトを返す
- each { |k,v| }
- 属性名と属性値を返しブロック呼び出し
まとめ
- ツリーを探索しているイメージを持つとわかりやすい
- 今自分が操作しているのが NodeSet なのか Element なのか知っていた方が混乱なさそう
- CSS や Xpath は NodeSet を返すが、at や child など Element を返す
- 今自分が操作しているのが NodeSet なのか Element なのか知っていた方が混乱なさそう
- 大抵のケースでは最初のサンプルで事足りそう
- 取得部分の細かい指定が必要な場合には children 等を使う
- CSS で検索して NodeSet を取ってきて、それを each で回して各要素の情報を取得する
- テキストから検索するのは結構使いそう
- CSSで書くと
html.at('a:contains("Ruby")')など
- CSSで書くと
- 取得部分の細かい指定が必要な場合には children 等を使う