Amazon Machine Learningとは
Amazon Machine Learning はAWSが提供している機械学習サービスです。機械学習に詳しくない人でも、簡単に学習モデルを作ったり予測結果を取得したりすることができます。また、S3、Redshift、RDS(MySQL)のデータを学習データとして利用することができ、AWSに構築したシステムのデータをシームレスに分析できることも魅力です。2015/4/9に正式公開され、現在はUS East(N. Virginia)リージョンとEU(Ireland)リージョンでのみ利用できます。
クラウドの機械学習サービスとしてはMicrosoft AzureのAzure Machine Learningが先行していますが、AWSもいよいよこの領域に進出してきました。
学習アルゴリズム
Amazon Machine Learningでは標準で以下の3つの手法が利用できます。
(参考:Amazon Machine Learning Concepts)
binary classification(二項分類)
- 学習アルゴリズム
- ロジスティック回帰+確率的勾配降下法
- 用途
- スパムメールのフィルタリング
- 男女の判別
- 広告を打つユーザの判定
multiclass classification(多クラス分類)
- 学習アルゴリズム
- 多クラスロジスティック回帰+確率的勾配降下法
- 用途
- 商品カテゴリの判別
- 映画ジャンルのタグ付け
- ユーザが興味ありそうな話題の選択
regression(数値予測)
- 学習アルゴリズム
- 線形回帰+確率的勾配降下法
- 用途
- 気温の予測
- 商品の売上予測
- 株価の予測
サンプルチュートリアル
「機械学習を試してみたい!」と思った時一番困るのはデータの準備ですが、Amazon Machine Learningではチュートリアル用のサンプルデータが用意されています。
サンプルデータはカリフォルニア大学アーバイン校が公開しているデータセットで、ポルトガルの金融機関の定期預金キャンペーンに関するデータです。データの内容は年齢や職業などの顧客情報、キャンペーンを案内した時期、消費者物価指数などの経済情報で、予測したいこと(target)は「顧客が定期預金を契約するかどうか」です。チュートリアルでは、定期預金を契約した顧客を1(positive)、**契約しなかった顧客を0(negative)**として、binary classificationを使って判定を行います。
機械学習では、データセットを学習データと評価データに分けて使用します。学習データで予測モデルを作り、作ったモデルの出来栄えを評価データを使ってテストします。Amazon Machine Learningの標準設定では、データセットの70%が学習データ、30%が評価用データとして使用されます。単純にデータの上から70%と30%で分けられてしまうので、データは事前にシャッフルしておく必要があります(サンプルデータはあらかじめシャッフルされています)。
チュートリアルの手順については、Amazon Machine Learning Tutorialやこちらの記事でスクリーンショット付きで丁寧に解説されていますので参考にしてみてください。特に難しく考えなくても、デフォルトのままで次へ次へ進んでいけば、以下のような学習モデルを作成することができます。
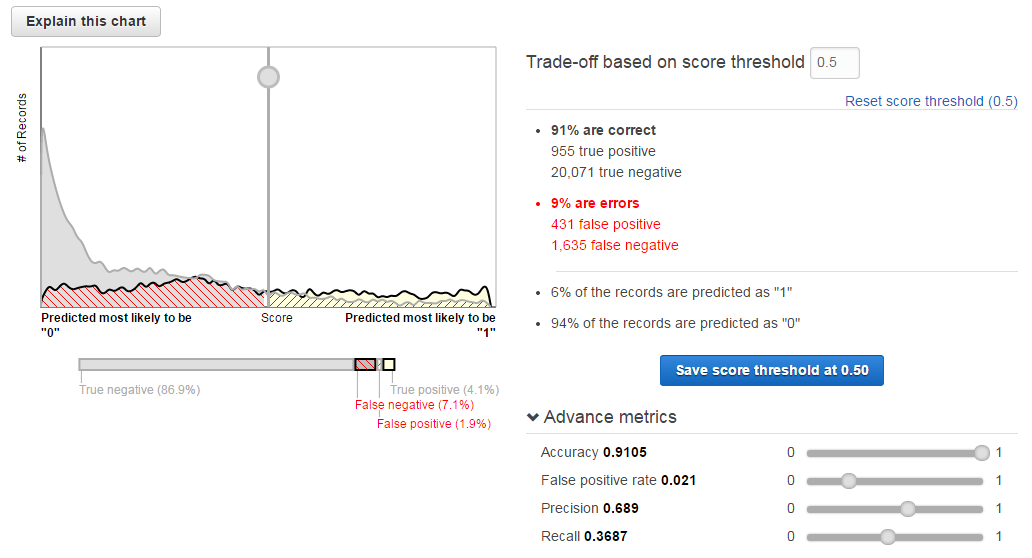
閾値のチューニング
(参考:Evaluating ML Models)
チュートリアルで得られた学習モデルは、**正解率が91%**なのでそれなりに良いモデルのように見えます。しかし正負ごとの正解率を見てみると、以下のような結果だと分かります。
- 正負ごとの正解率
- 契約した顧客:37%(955件/2,590件)
- 契約しなかった顧客:98%(20,071件/20,502件)
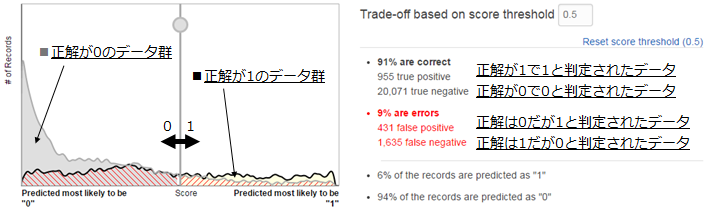
つまり、このままのモデルでは契約してくれそうな顧客を逃したくない場合には向いていないと言えます。そこで、モデルの閾値を変更して判定基準をチューニングしてみます。
binary classificationでは、与えられた評価データに対して0~1の範囲の予測スコアを出力し、そのスコアが閾値以上なら1、閾値以下なら0と予測します。閾値はデフォルトで0.5に設定されています。
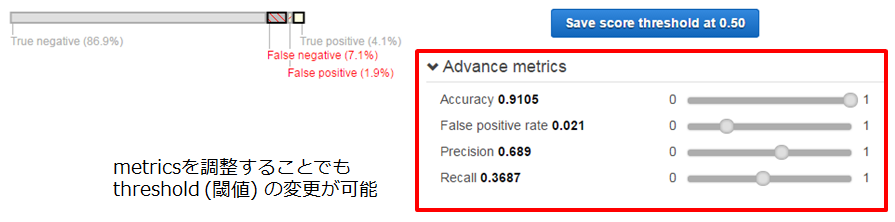
Amazon Machine Learningでは、閾値をスライダーバーで調整することができます。また、精度や再現率といったmetricsのスライダーバーを調整することで、それに合わせた閾値に自動調整することもできます。
以下は、契約してくれそうな顧客を逃さないよう閾値をチューニングした例です。全体の正解率は89%に低下しましたが、契約した顧客の80%を正しく予測できるようになりました。
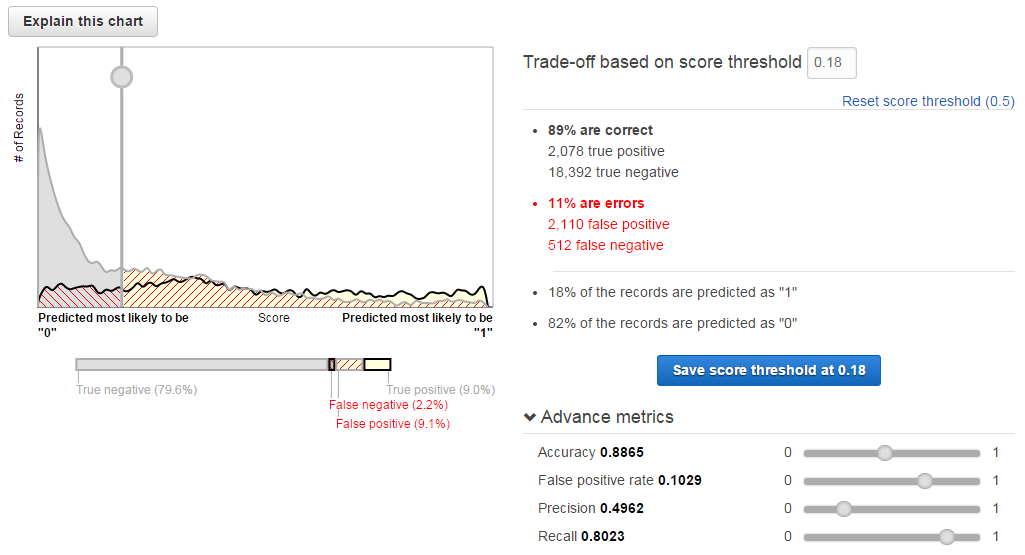
Advance metrics
metricsの数値については以下の通りです。詳しい算出方法はこちらを参照してください。
- Accuracy (正解率)
- 全データの中で正しく予測されたデータの割合
- False Positive Rate
- 実際は0のデータを誤って1と予測した割合
- 0であるデータをできるだけ正しく予測したい場合False Positive Rateを小さくする
- Precision (精度)
- 1と予測したデータの中で実際に1であったデータの割合
- 1と予測した結果に誤りが含まれていると困る場合Precisionを大きくする
- Recall (再現率)
- 実際が1であるデータの中で1と予測されたデータの割合
- 1であるデータをできるだけ正しく予測したい場合Recallを大きくする
また、モデル全体の良さを評価する尺度としてF値(F-measure, F1-score)があります。PrecisionとRecallはトレードオフの関係にあるため、これらがバランス良く共に大きい値であれば良いモデルと言えます。F値は以下の式で算出します。
- F-measure = 2 * Precision * Recall / ( Precision + Recall )
デフォルトのモデルはF値が0.48でしたが、チューニングした後はF値が0.61となり、モデルとしても良くなったと言えます。
利用料金
利用料金はモデル構築と予測に分かれています。詳しくは"Amazon Machine Learning - 料金"を確認してください。
- データ分析およびモデル構築料金
- コンピューティングリソース利用時間 1時間あたり 0.42 USD
- 予測料金
- バッチ予測
- 予測 1,000 件当たり 0.10 USD
- リアルタイム予測
- 予測 1 件当たり 0.0001 USD
- リザーブドメモリ 10MB ごと 1時間あたり 0.001 USD
- その他
- S3等のストレージ利用料、データ転送量など
まとめ
Amazon Machine Learningは、サンプルデータとチュートリアルが用意されており、機械学習に詳しくない人でも、簡単に試してみることができます。学習データの取り込みからモデルの評価までがウィザード形式で行え、つまづくことも少ないと思います。ドキュメントがしっかりと用意されているのも非常に助かります。
一方、機械学習サービスとしてはまだまだ物足りない印象です。今のところ学習アルゴリズムの選択肢が無いため、ロジスティック回帰や線形回帰で上手く分析できない問題を扱うことはできません。また、データの正規化等の前処理もGUIでは行えず、レシピを書く必要があります。まだ、公開されたばかりのサービスですので、このあたりの機能強化は今後に期待したいと思います。