この記事では、並列処理に関する入門的知識を解説する。
さらに、Rubyで開発されている新しい並列実行単位Ractorにも言及する。
まず、この話題をする上で混同しがちな用語についてまとめる。
並列処理(parallel)と並行処理(concurrent)について
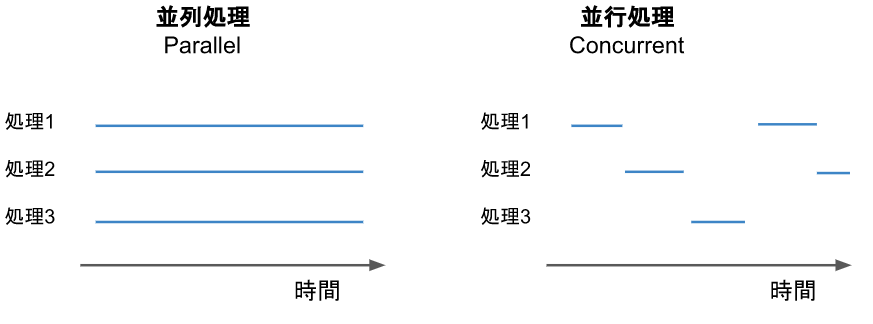
並列処理 では、ある瞬間に複数の処理が同時に走る。
並行処理 では、複数の処理を時分割で順に処理する。並列処理とは異なり、ある瞬間に同時に走る処理は1つだけ。
ある複数の処理が実行されているタイミングを時系列で示すと、下図のようなイメージになる。
(青い線がある部分のみ処理が実行される)
この記事では並列処理の動作について扱うが、並列処理のコードを書いても結局並行処理のように動いている場合もあることには注意。
(例えば、1コアのCPUでは2つ以上の処理を並列に動作させることはできない、など。)
この辺りはOSやVMなどが良い感じにスケジューリングしてくれている。
マルチプロセスとマルチスレッド
一般に並列処理を実現するための主な方法として、 マルチプロセス と マルチスレッド の2つがある。
マルチプロセスは、複数のプロセスを作成し、それぞれのプロセスで1つずつ処理を実行させる方法。
マルチスレッドは、1つのプロセス内に複数のスレッドを作成し、それぞれのスレッドで1つずつ処理を実行させる方法。
マルチプロセスの場合は、メモリ空間が各プロセスで分離されている。
このため、プロセス間で変数の受け渡しなどは基本的にできない。
また、それが故にプロセス間でメモリを介した意図しない相互作用は起こり得ないので、安全性は高い。
デメリットとしては、プロセスごとにメモリ空間を持つので、合計のメモリ使用量は増大しがち。(ただし、linuxではCopy on writeという仕組みにより、プロセス間のメモリを可能な限り共有してくれる。)
マルチスレッドの場合は、1つのプロセスが複数のスレッドを持つため、メモリ空間はスレッド間で共有される。
そのため、メモリ使用量は抑えられる上、実装によってはスレッドの作成や切り替えが、プロセスの作成や切り替えよりも軽いというメリットもある。
ただし、メモリを介してスレッド間が影響を及ぼしあうことができるため、データ競合などのバグは発生しがち。
一般に、マルチスレッドプログラミングは考慮すべきことが多く、正しく実装するのが難しいとされている。
なお、並列処理において1つの処理が実行される単位を 並列実行単位 と呼ぶ。
マルチプロセスの場合は並列実行単位はプロセスであり、マルチスレッドの場合はスレッドである。
(補足) スレッド処理の実現方法について
スレッド処理の主な実現方法として、 ネイティブスレッド と グリーンスレッド の2種類がある。
ネイティブスレッドは、OSの実装をそのまま利用して、マルチスレッド処理を実現する方法。
スレッドのスケジューリング(今どのスレッドの処理を実行するか決めること)をOSに任せられるので処理系の実装は単純になる。
一方で、スレッドの作成や切り替え(いわゆるコンテキストスイッチ)の処理が重いというデメリットもある。
(ちなみにネイティブスレッドは、正確にはカーネルスレッドと軽量プロセスを合わせた概念とのことだが、詳細は割愛。ネイティブスレッドとカーネルスレッドが混用されることも多々ある気がする。)
グリーンスレッドは、言語処理系の仮想マシン(たとえば、crubyのyarv、javaのjvmなど)で独自に実装したスレッドで、マルチスレッド処理を実現する方法である。
golangのgoroutineもグリーンスレッドの一種で、その動作の軽快さはあまりにも有名。
crubyでは、1.9以前はグリーンスレッドにより実装されていたが、今はネイティブスレッドを利用する形に変更された。
グリーンスレッドはユーザースレッドとも呼ばれる。
マルチスレッド・マルチプロセスのコード例
一例として、Rubyにおける並列処理の実装を示す。
RubyではParallelというgemを用いることで、容易に並列処理を記述することが可能。
マルチプロセスのコードは下記のようになる。
require 'parallel'
Parallel.each(1..10, in_processes: 10) do |i|
sleep 10
puts i
end
このコードを実行して、プロセスリストを見ると、下記のようになる。
1個のメインプロセスと、10個の子プロセスが生じていることが分かる。
$ ps aux | grep ruby
PID %CPU %MEM VSZ RSS TT STAT STARTED TIME COMMAND PRI STIME UTIME
79050 9.7 0.1 4355568 14056 s005 S+ 2:39PM 0:00.28 ruby mp.rb
79072 0.0 0.0 4334968 1228 s005 S+ 2:39PM 0:00.00 ruby mp.rb
79071 0.0 0.0 4334968 1220 s005 S+ 2:39PM 0:00.00 ruby mp.rb
79070 0.0 0.0 4334968 1244 s005 S+ 2:39PM 0:00.00 ruby mp.rb
79069 0.0 0.0 4334968 1244 s005 S+ 2:39PM 0:00.00 ruby mp.rb
79068 0.0 0.0 4334968 1172 s005 S+ 2:39PM 0:00.00 ruby mp.rb
79067 0.0 0.0 4334968 1180 s005 S+ 2:39PM 0:00.00 ruby mp.rb
79066 0.0 0.0 4334968 1208 s005 S+ 2:39PM 0:00.00 ruby mp.rb
79065 0.0 0.0 4334968 1252 s005 S+ 2:39PM 0:00.00 ruby mp.rb
79064 0.0 0.0 4334968 1168 s005 S+ 2:39PM 0:00.00 ruby mp.rb
79063 0.0 0.0 4334968 1168 s005 S+ 2:39PM 0:00.00 ruby mp.rb
マルチスレッドのコードは下記のようになる。
require 'parallel'
Parallel.each(1..10, in_threads: 10) do |i|
sleep 10
puts i
end
こちらも同様にスレッド一覧を見てみる。
ps コマンドに -L をつけると、スレッドがプロセスのように表示される。
-L なしではプロセスが1個なのに対し、 -L をつけると11行表示される。
また、 NLWP カラムはプロセスのスレッド数を示すが、これが11(メインスレッドx1 + ワーカースレッドx10)となっていることからも、マルチスレッド処理になっていることが分かる。
$ ps aux | grep mt.rb
4419 1.0 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb
$ ps aux -L | grep mt.rb
PID LWP %CPU NLWP %MEM VSZ RSS TTY STAT START TIME COMMAND
4419 4419 6.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb
4419 4453 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb
4419 4454 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb
4419 4455 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb
4419 4456 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb
4419 4457 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb
4419 4458 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb
4419 4460 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb
4419 4461 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb
4419 4462 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb
4419 4463 0.0 11 0.6 850176 12384 pts/1 Sl+ 15:41 0:00 ruby mt.rb
マルチスレッドプログラミングの難しさ
マルチスレッド処理においては、複数のスレッドがメモリを共有した状態で処理が並列に実行されるため、様々な問題が発生しうる。
主な問題の一つがデータレースである。
データレースは、下記のようなコードで発生する可能性がある。
このコードは 1~10までの整数の和を求めようとしたものであるが、データレースの問題があるために、正しく和を求められない可能性がある。
require 'parallel'
sum = 0;
Parallel.each(1..10, in_threads: 10) do |i|
add = sum + i
sum = add
end
puts sum
このコードにおいて、各スレッドは変数 sum を共有しており、各スレッドがsumの読み込みや書き込みを同時に行う。
この結果、あるスレッドで書き込まれた内容が、別のスレッドにより上書きされる可能性がある。
このため、上記のコードは正常に和を計算できない可能性があるという問題がある。
データレースの問題を解決する一般的な方法は、スレッド間で排他ロックを取る方法である。
require 'parallel'
sum = 0;
m = Mutex.new
Parallel.each(1..10, in_threads: 10) do |i|
m.lock
add = sum + i
sum = add
m.unlock
end
puts sum
これにより、ロックを取っている間の処理は同時に1スレッドしか実行されなくなり、データレースは解消される。
これらの問題が正しく考慮され、マルチスレッドにおいても正常に動作するコードを、スレッドセーフと呼ぶ。
Global Interpreter Lockについて
軽量言語(ruby, python等)でのマルチスレッド処理においてしばしば話題に上がるのが GIL である。
ちなみにRubyにおいてはGVL(Giant VM Lock)と呼ばれている。
GILは、スレッド同士の排他制御を行うことで、複数のスレッドが同時に実行されることを防ぐ。
つまり、一つのインタープリタ、VM内では同時に一つのスレッドしか実行されないようにする。
これが必要な理由やメリットとして、下記が挙げられる:
- マルチスレッドプログラミングをする際、個々のデータ構造ごとに排他処理を記述する必要がなくなる
- 処理が高速化する
- アプリ開発者のコーディングは簡単になる(データレースについて考えることが減る)
- ネイティブプラグインの実装がスレッドセーフでないことが多々あるが、それらの実装を変えずに安全に実行するため
- VMの実装自体がスレッドセーフではない
GILのおかげで、実は先程例示したマルチスレッドプログラミングのRubyコードは、Mutexを利用しない場合でも正常に動作する。
この挙動は、プログラミングを楽にするというRubyの根本思想に違わないものと言える。
しかしながら、同時に1つのスレッドしか実行できないということは、本来の並列処理が不可能であることを意味する。
RubyやPythonが並列計算に適していないとしばしば言及されるのは、このためである。
なお、例外的にI/Oの待機時はスレッドはGILを解除するため、実質的に複数のスレッドが同時に処理を実行できる。
このため、I/O待ちが多いような処理(ウェブサーバーなど)では、GILのある処理系においても実用的にマルチスレッドが利用される。
実装の例
HTTPサーバーは通常リクエストごとに同時に処理する必要があるため、並列処理の実装がなされていることが多い。
Rubyにおける代表的なHTTPサーバーとしてunicornとpumaがあり、前者はマルチプロセスの実装、後者はマルチスレッドの実装である。
unicornとpumaはこちらのブログで性能が比較されている。
このブログの結論は、下記のようなものである:
- CPU boundな処理においては、unicornがやや優れたパフォーマンスを発揮する
- I/O boundな処理においては、pumaのほうが圧倒的に優れたパフォーマンスを発揮する
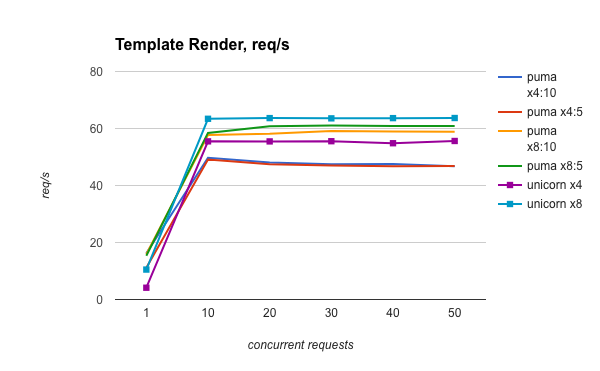
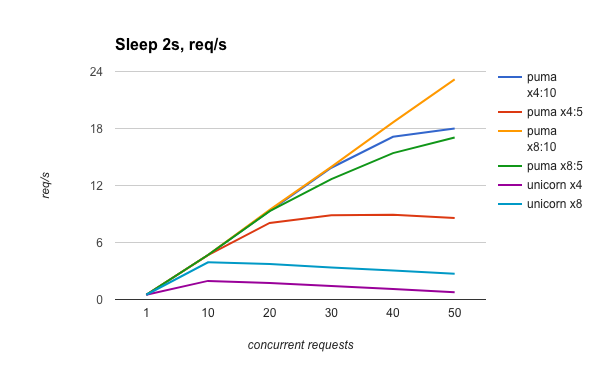
これは、上記の仕組みを考えても、納得のいく結果である。
Ractorについて
ここまで並列処理の実現方法について説明し、Rubyでの実装やその性能を示した。
Rubyにおけるマルチスレッド処理は、GVLによって、本来のパフォーマンスを発揮することができないという問題がある。
Ractor(旧称: Guild)は、この問題を解決するために生まれた新しいRubyの並列処理機構である。
Ractorは従来のGVLによるマルチスレッドプログラミングが扱いやすくなるという利点を保ちながら、本来のマルチスレッドのパフォーマンスを実現できる。
その仕組みを解説する。
Ractorの思想
データレースが生じるのは、スレッド間がメモリを共有しているために、複数のスレッドが一つの変数に対して読み書き可能なためである。
これを解決する方法としては、
- 全ての変数を読み取り専用(Immutable)にする
- スレッド間で共有する変数は型で明示し、スレッドセーフでない処理に対してコンパイル時に検知する
- 並列実行単位ごとにメモリを独立させる
Ractorでは3の方法が採られた。この新しい並列実行単位がRactorと呼ばれている。
1つのRubyプロセスは1つ以上のRactorを持ち、1つのRactorは1つ以上のスレッドを持つ。
Ractorはそれぞれ個別のメモリ空間上で動作するため、従来のスレッドのようにメモリを共有することによる問題は生じない。
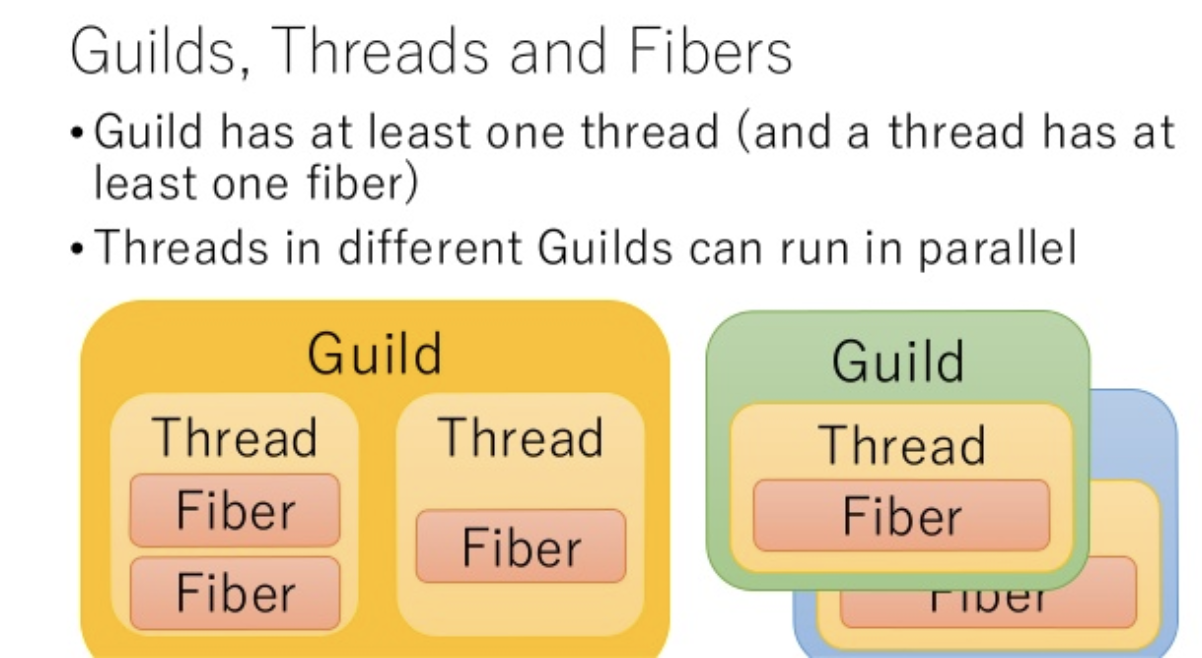
出典: https://www.slideshare.net/KoichiSasada/guild-prototype
また、Ractor導入以前のRubyコードは、1つのRactor内で動かすことにより後方互換性を保つことができる。
Ractor間でのデータ共有の方法
Ractor同士はメモリを共有しないため、情報の受け渡しが面倒になると思うかもしれない。
これを解決するため、Ractor間の通信を実現する channel という機能も用意されている。
共有したいオブジェクトは channel を経由してのみ受け渡すことができる。
オブジェクトは 共有可能オブジェクト と 共有不可オブジェクト に分類される。
共有可能オブジェクトは、読み取り専用の定数など、Ractor間で共有してもデータレースの発生し得ないオブジェクトを指す。
共有可能オブジェクトは、 channel を通じて自由に共有できる。
共有不可オブジェクトは、一般のミュータブルなオブジェクトを指す。
このオブジェクトを channel に通すと、ディープコピーまたはムーブセマンティクスが発生する。
ディープコピーの場合は、コピーの処理コストやメモリ使用量の増大が発生するが、マルチプロセスと同様の安全さ・わかりやすさがある。
ムーブセマンティクスの場合は、オブジェクトの所有権が別のRactorに譲渡される形になる。
このため、元のRactorからはそのオブジェクトを参照できなくなるが、ディープコピーとは異なりコピーほどの処理コストはメモリ使用量も増大しない。
まとめると:
- 基本的にRactor間でメモリを共有しない
- 必要なオブジェクトのみを開発者が明示的に指定して共有する
- 共有する場合は、オブジェクトに応じて最適な方法を選択する
ことで、Ractorはスレッドセーフ性を保ちながらも容易なマルチスレッドプログラミングを実現する。
Ractorはプロセスとスレッドの中間に位置する並列実行単位である。
開発者がRactor間で共有したい情報を適切に選択することで、マルチプロセスほどRAM使用量を増やさず、またマルチスレッドのようにGILによるパフォーマンス低下がなく、並列処理を実現できる。
Ractorの現在
RactorはRuby 3の新機能として注目を浴びている。
Ractor自体は今も開発が進んでいるようで、一般Rubyユーザーの手に届くのはもう少し先になるだろう。
今後はRubyのマルチスレッド処理をするライブラリがRactorで再実装されることも期待される。
Pumaに代わるHTTPサーバーが主流になる時代も近い、かもしれない。
(追記) falconというRuby製HTTPサーバーもあった。
こちらはFiberという別の並列実行単位で動く。
FiberはRubyでのグリーンスレッドのようなものなので、Pumaよりは軽量に動くと思われるが、依然としてGVLの影響は受けるはず。
参考文献
- https://github.com/ko1/ruby/blob/ractor/ractor.ja.md
- http://www.atdot.net/~ko1/activities/sasada_ipsj_pro_120.pdf
- https://qiita.com/Kohei909Otsuka/items/26be74de803d195b37bd
- https://qiita.com/yohhoy/items/00c6911aa045ef5729c6
- https://zenn.dev/yohhoy/articles/multithreading-toolbox
勉強のためまとめた文章です。間違いがあればご指摘いただければ幸いです!