この記事は自分用のメモみたいなものです.
ほぼ DeepL 翻訳でお送りします.
間違いがあれば指摘していだだけると嬉しいです.
翻訳元
L2-constrained Softmax Loss for Discriminative Face Verification
Rajeev Ranjan, Carlos D. Castillo, Rama Chellappa
前: 【2. Related Work】
次: 【4. Proposed Method】
3. Motivation
訳文
まず, 図 2 に示すように, DCNN を用いた顔認証システムを学習するための一般的なパイプラインをまとめる. 顔画像と対応する識別ラベルを持つ訓練データセットが与えられると, DCNN は, ネットワークが与えられた顔画像を正しい識別ラベルに分類することを学習する分類タスクとして訓練される. ネットワークの訓練には, 式 1 で与えられるソフトマックス損失関数が使用される
$$L_S = - \frac{1}{M} \sum_{i=1}^{M} \log \frac{e^{W_{y_i}^{T}f(x_i)+b_{y_i}}}{\sum_{j=1}^{C}e^{W_{j}^{T}f(x_i)+b_{j}}}, \tag{1}$$
ここで, $M$ は学習バッチサイズ, $x_i$ はバッチ中の $i$ 番目の入力顔画像,$f(x_i)$ は DCNN の最後の層の対応する出力, $y_i$ は対応するクラスラベル, $W$ と $b$ は分類器として動作するネットワークの最後の層の重みとバイアスである.

図2. DCNN を用いた顔認証システムの学習, テストのための一般的なパイプライン.
テスト時に, 訓練された DCNN を用いて, テスト顔画像, $x_g$ と $x_p$ のペアについて, それぞれ特徴記述子 $f(x_g)$ と $f(x_p)$ を抽出し, 単位長に正規化する. 次に, 特徴ベクトル上で類似度スコアが計算され, これは, 特徴が埋め込まれた空間の中でどれだけ近くにあるか, または距離の指標となる. 類似度スコアが設定された閾値よりも大きい場合, 顔のペアは同一人物であると判断される. 通常, 類似度スコアは, 正規化された特徴の間の $L_2$-距離として計算される [28, 24] または, 式 2 で与えられるように, コサイン類似度 [33, 3, 25, 27] $s$ を用いて計算される. これらの類似度尺度はどちらも等価であり, 同じ結果をもたらす.
$$s = \frac{f(x_g)^T f(x_p)}{||f(x_g)||_2 ||f(x_p)||_2 } \tag{2}$$
このパイプラインには 2 つの大きな問題がある. 第一に, 顔認証タスクの学習ステップとテストステップが分離されていることである. ソフトマックス損失を用いた学習では, 正規化空間や角度空間において, 正のペアがより近く, 負のペアがより遠くに離れているとは限らない.
第二に, ソフトマックス分類器は困難なサンプルや極端なサンプルのモデリングに弱いということである. データ品質が不均衡な典型的な学習バッチでは, ソフトマックスの損失は, 簡単なサンプルについては特徴量の $L_2$ ノルムを大きくし, 難しいサンプルについては無視することで最小化される. このようにして, ネットワークは特徴記述子の $L_2$ ノルムによって顔の質に対応するように学習する. この理論を検証するために, IJB-A [16] のデータセットを用いて簡単な実験を行った. 特徴量は, 通常のソフトマックス損失で学習した Face-Resnet [33] を用いて計算した. 記述子の$L_2$ ノルムが 90 以下のテンプレートは set1 に割り当てられる. $L_2$ ノルムが 90 以上 150 未満のテンプレートは set2 に, $L_2$ ノルムが 150 以上のテンプレートは set3 に割り当てられる. 合計 6 組の評価ペアを形成している. 図1(a) は, IJB-A の顔認証プロトコルにおけるこれら 6 つの評価ペアの性能を示している. どちらのテンプレートも $L_2$ ノルムが低いペアは非常に低い性能であるのに対し, $L_2$ ノルムが高いペアは最高の性能を発揮していることがわかる. 各セット間の性能の差はかなり大きい. 図1(b)は, セット1, セット2, セット3 のテンプレートのサンプルを示しており, 特徴記述子の $L_2$ ノルムがその品質の情報を提供していることを確認している.
これらの問題を解決するために, 顔画像ごとに特徴量の $L_2$ ノルムを固定するようにする. 具体的には, 特徴量記述子が固定半径の超球上にあるように, 特徴量記述子に $L_2$ の制約を加える. この方法には 2 つの利点がある. 第一に, 超球上では, ソフトマックス損失を最小化することは, 正のペアのコサイン類似度を最大化し, 負のペアのコサイン類似度を最小化することと等価であり, 特徴量の検証信号を強化することができる. 第二に, 顔の特徴はすべて同じ $L_2$ のノルムを持つので, ソフトマックス損失は極端な顔や困難な顔をより良くモデル化することができる.
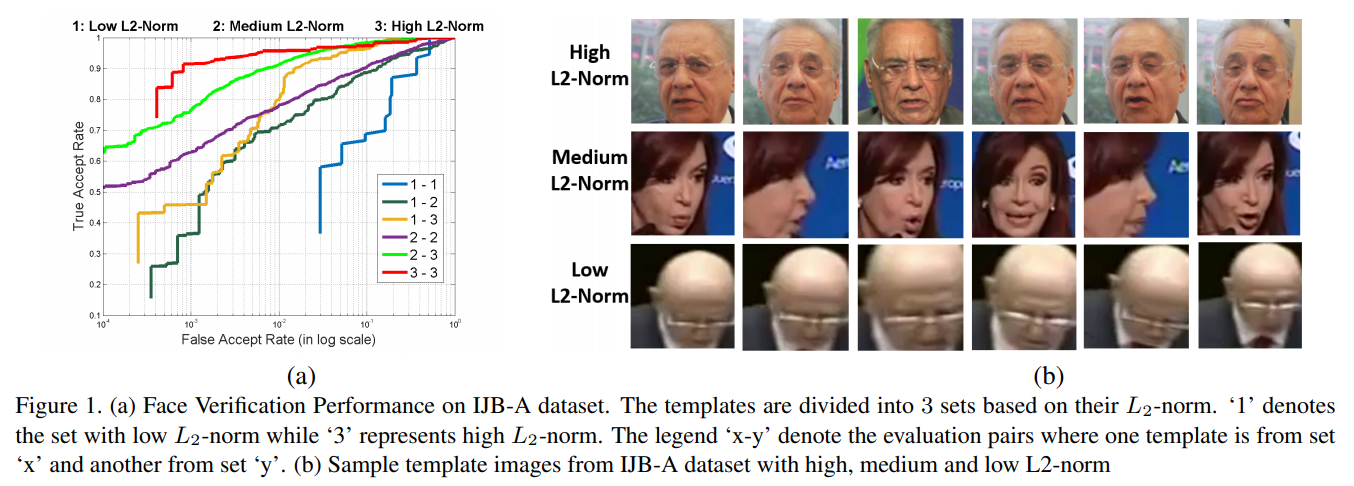
図1. (a) IJB-A データセットにおける顔認証性能. テンプレートは $L_2$ ノルムに基づいて 3 つのセットに分けられている. '1'は $L_2$ ノルムが低いセット, '3' は $L_2$ ノルムが高いセットを示す. 凡例の 'x-y' は, あるテンプレートが集合 'x' のテンプレートで, 別のテンプレートが集合 'y' のテンプレートである場合の評価ペアを示している. (b) IJB-A データセットの高, 中, 低 $L_2$ ノルムのテンプレート画像のサンプル.
原文
We first summarize the general pipeline for training a face verification system using DCNN as shown in Figure 2. Given a training dataset with face images and corresponding identity labels, a DCNN is trained as a classification task where the network learns to classify a given face image to its correct identity label. A softmax loss function is used for training the network, given by Equation 1
$$L_S = - \frac{1}{M} \sum_{i=1}^{M} \log \frac{e^{W_{y_i}^{T}f(x_i)+b_{y_i}}}{\sum_{j=1}^{C}e^{W_{j}^{T}f(x_i)+b_{j}}}, \tag{1}$$
Figure 2. A general pipeline for training and testing a face verification system using DCNN.
where M is the training batch size, xi is the i th input face image in the batch, f(xi) is the corresponding output of the penultimate layer of the DCNN, yi is the corresponding class label, and W and b are the weights and bias for the last layer of the network which acts as a classifier.
At test time, feature descriptors $f(x_g)$ and $f(x_p)$ are extracted for the pair of test face images $x_g$ and $x_p$ respectively using the trained DCNN, and normalized to unit length. Then, a similarity score is computed on the feature vectors which provides a measure of distance or how close the features lie in the embedded space. If the similarity score is greater than a set threshold, the face pairs are decided to be of the same person. Usually, the similarity score is computed as the $L_2$-distance between the normalized features [28, 24] or by using cosine similarity [33, 3, 25, 27] $s$, as given by Equation 2. Both these similarity measures are equivalent and produce same results.
$$s = \frac{f(x_g)^T f(x_p)}{||f(x_g)||_2 ||f(x_p)||_2 } \tag{2}$$
There are two major issues with this pipeline. First, the training and testing steps for face verification task are decoupled. Training with softmax loss doesn’t necessarily ensure the positive pairs to be closer and the negative pairs to be far separated in the normalized or angular space.
Secondly, the softmax classifier is weak in modeling difficult or extreme samples. In a typical training batch with data quality imbalance, the softmax loss gets minimized by increasing the $L_2$-norm of the features for easy samples, and ignoring the hard samples. The network thus learns to respond to the quality of the face by the $L_2$-norm of its feature descriptor. To validate this theory, we perform a simple experiment on the IJB-A [16] dataset where we divide the templates (groups of images/frames of same subject) into three different sets based on the $L_2$-norm of their feature descriptors. The features were computed using Face-Resnet [33] trained with regular softmax loss. Templates with descriptors’ $L_2$-norm $< 90$ are assigned to set1. The templates with $L_2$-norm $> 90$ but $< 150$ are assigned to set2, while templates with $L_2$-norm $> 150$ are assigned to set3. In total they form six sets of evaluation pairs. Figure 1(a) shows the performance of the these six different sets for the IJB-A face verification protocol. It can be clearly seen that pairs having low $L_2$-norm for both the templates perform very poor, while the pairs with high $L_2$-norm perform the best. The difference in performance between each set is quite significant. Figure 1(b) shows some sample templates from set1, set2 and set3 which confirms that the $L_2$-norm of the feature descriptor is informative of its quality.
To solve these issues, we enforce the $L_2$-norm of the features to be fixed for every face image. Specifically, we add an $L_2$-constraint to the feature descriptor such that it lies on a hypersphere of a fixed radius. This approach has two advantages. Firstly, on a hypersphere, minimizing the softmax loss is equivalent to maximizing the cosine similarity for the positive pairs and minimizing it for the negative pairs, which strengthens the verification signal of the features. Secondly, the softmax loss is able to model the extreme and difficult faces better, since all the face features have same $L_2$-norm.

Figure 1. (a) Face Verification Performance on IJB-A dataset. The templates are divided into 3 sets based on their $L_2$-norm. ‘1’ denotes the set with low $L_2$-norm while ‘3’ represents high $L_2$-norm. The legend ‘x-y’ denote the evaluation pairs where one template is from set ‘x’ and another from set ‘y’. (b) Sample template images from IJB-A dataset with high, medium and low $L_2$-norm