この記事は自分用のメモみたいなものです.
ほぼ DeepL 翻訳でお送りします.
間違いがあれば指摘していだだけると嬉しいです.
翻訳元
[Deep Double Descent: Where Bigger Models and More Data Hurt ]
(https://arxiv.org/abs/1912.02292)
前: 【Abstract】
次: 【2 OUR RESULTS】
1 INTRODUCTION
訳文
バイアス-バリアンス トレードオフは, 古典的な統計学習理論の基本的な概念である (e.g., Hastie et al. (2005)). この考え方は, より複雑なモデルはより低いバイアスを持つが, より高いバリアンスを持つというものである. この理論によると, モデルの複雑さがあるしきい値を過ぎると, モデルはバリアンス項がテスト誤差を支配する状態で "オーバーフィット" し, したがって, この時点以降, モデルの複雑さを増加させても, パフォーマンスが低下する (すなわち, テスト誤差が増加する). したがって, 古典統計学の従来の常識は, あるしきい値を過ぎると, "より大きなモデルはより悪い" ということである.
しかし, 現代のニューラルネットワークはそのような現象を示さない. そのようなネットワークは数百万個のパラメータを持ち, ランダムなラベルでさえ適合させるのに十分な数を超えている (Zhang et al. (2016)) にもかかわらず, 小さなモデルよりも多くのタスクではるかに優れた性能を発揮する. 実際, 専門家の間では “より大きなモデルの方が優れている“ というのが従来の常識である (Krizhevsky et al. (2012), Huang et al. (2018), Szegedy et al. (2015), Radford et al. (2019)). トレーニング時間がテストパフォーマンスに与える影響も議論の余地がある. ある設定では, “early stopping” がテスト性能を向上させる一方で, 他の設定では, ニューラルネットワークをトレーニングエラーゼロまでトレーニングするだけで性能が向上する. 最後に, 古典的な統計学者とディープラーニングの専門家の両方が同意することが一つあるとすれば, "より多くのデータは常により良い"ということである.
この論文では, 上記の "従来の常識" のいくつかに挑戦し, を和解させる実証的な証拠を提示する. 多くのディープラーニングの設定には, 2つの異なるレジームがあることを示す. アンダーパラメータ化されたレジームでは, モデルの複雑さがサンプル数に比べて小さいため, モデルの複雑さの関数としてのテスト誤差は, 古典的なバイアス/バリアンスのトレードオフによって予測される U のような振る舞いに従う. しかし, モデルの複雑さが補間するのに十分に大きくなると, すなわち, 学習誤差がゼロ (近く) 達成されると, 複雑さの増加はテスト誤差を減少させるだけで, "より大きなモデルはより良い" という現代の直観に従う. 同様の挙動は, 以前に Advani & Saxe (2017), Spigler et al. (2018), and Geiger et al. (2019b) で観察された. この現象は, "double descent" と名付けた Belkin et al. (2018) によって最初に一般的に仮定され, MNIST と CIFAR-10 を含む様々な学習タスク上で, 決定木, ランダム特徴量, および $l_2$ loss を持つ 2 層ニューラルネットワークに対して実証された.
主な貢献. 我々は, double descent が様々なタスク, アーキテクチャ, 最適化手法で発生するロバストな現象であることを示す (図 1 とセクション 5 を参照, 我々の実験結果を表 A にまとめる). さらに, 我々は, パラメータの数を変化させることを超えた, より一般的な "double descent" の概念を提案する. 我々は, 学習手順の effective model complexity (EMC) を, 学習誤差がゼロに近い状態で達成できるサンプル数の最大値として定義する. EMC はデータ分布や分類器のアーキテクチャだけでなく, 訓練手順にも依存し, 特に訓練時間の増加は EMC を増加させる. 我々は, 多くの自然モデルや学習アルゴリズムでは, EMC の関数として double descent が起こるという仮説を立てている. 実際, モデルを固定したまま訓練時間を増加させると "epoch-wise double descent" が観察され, アンダーフィッティングの段階 (EMC がサンプル数よりも小さい場合) では古典的なU様曲線に沿った性能を示し, EMC がサンプル数よりも十分に大きくなると訓練時間とともに改善する (図 2 を参照). 補論として, early stopping は, クリティカルパラメータ化されたモデルの比較的狭いパラメータ領域でのみ役立つ.
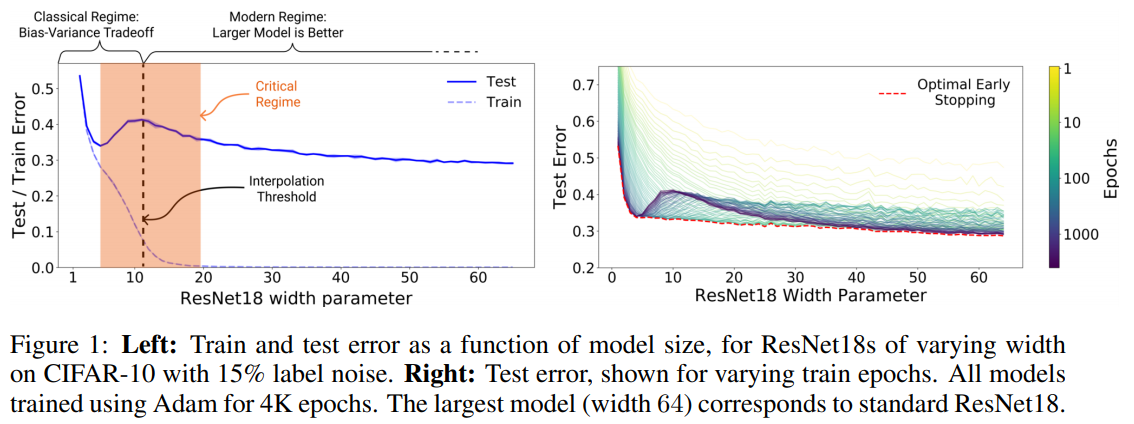
図 1: 左: CIFAR-10, label noise 15% の CIFAR-10 上で幅の異なる ResNet18 について, モデルサイズの関数としての訓練誤差とテスト誤差. 右図: 訓練エポックを変化させた場合のテスト誤差. 学習エポック数を変化させた場合のテスト誤差. すべてのモデルは 4K エポックで Adam を用いて訓練された. 最大のモデル (幅 64) は標準的なResNet18 に対応している.
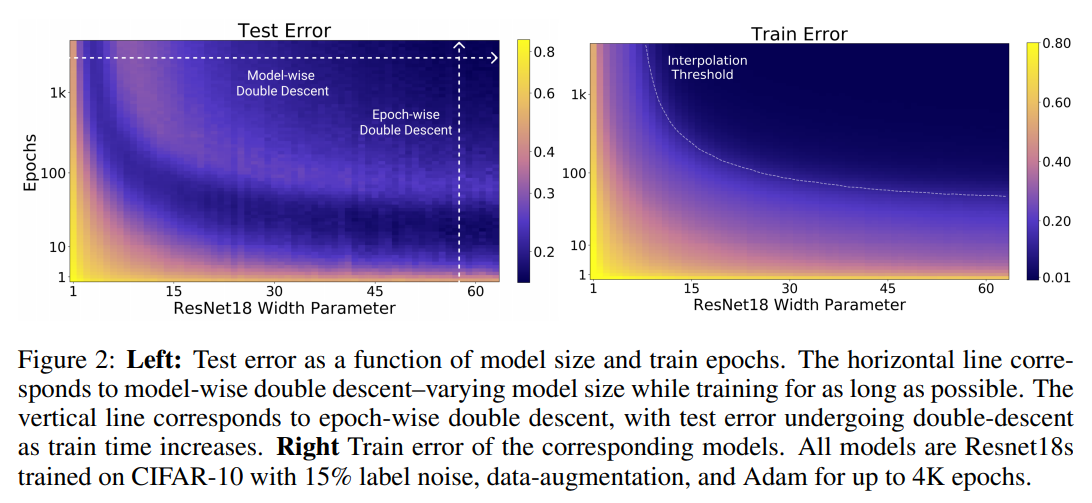
図 2: 左: モデルサイズと訓練エポックの関数としてのテスト誤差. 横軸は, できるだけ長く訓練しながらモデルサイズを変化させたモデルごとの double descent に対応している. 縦軸は, epoch-wise double descent に対応し, 訓練時間が長くなるにつれてテスト誤差は double descent を受ける. 右は対応するモデルの訓練誤差. すべてのモデルは, CIFAR-10 上で 15% の label noise, データオーグメンテーション, Adam を用いて4K エポックまで訓練した Resnet18.
Sample non-monotonicity. 最後に, 我々の結果は, 訓練サンプル数の関数としての試験性能に光を当てている. 試験誤差は EMC がサンプル数と一致する点 (アンダーパラメータ化からオーバーパラメータ化への移行点) でピークを迎えるため, サンプル数を増やすとこのピークを右にシフトさせる効果がある. ほとんどの設定では, サンプル数を増やすと誤差が減少するが, このシフト効果により, データ数が多い方が悪いという設定になってしまうことがある! 例えば, 図 3 はサンプル数を 4.5 倍に増やすとテスト性能が低下するケースを示してる.
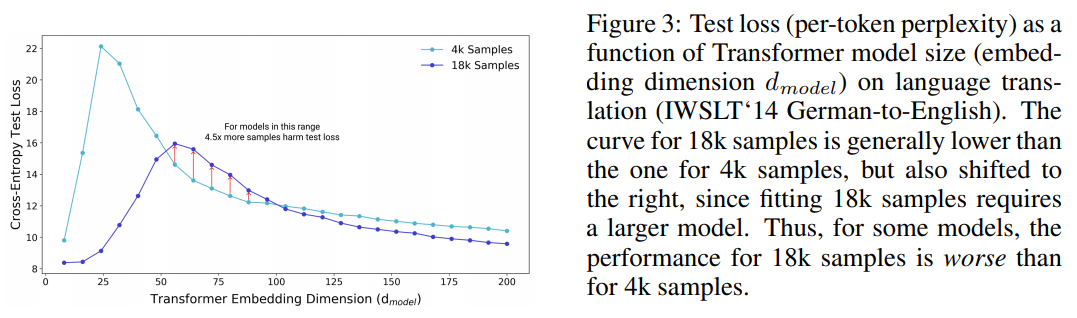
図 3: 言語翻訳 (IWSLT‘14 ドイツ語から英語への翻訳) におけるトランスフォーマーのモデルサイズ (埋め込み次元$d_{model}$) の関数としてのテスト損失 (トークンあたりのペルプレキシティ). 18kサンプルの曲線は, 一般的に 4k サンプルの曲線よりも低くなっているが, 18k サンプルのフィットはより大きなモデルを必要とするため, 右にシフトしている. このように, いくつかのモデルでは, 18k サンプルの性能は 4k サンプルよりも悪くなっている.
原文
Figure 1: Left: Train and test error as a function of model size, for ResNet18s of varying width on CIFAR-10 with 15% label noise. Right: Test error, shown for varying train epochs. All models trained using Adam for 4K epochs. The largest model (width 64) corresponds to standard ResNet18.
The bias-variance trade-off is a fundamental concept in classical statistical learning theory (e.g., Hastie et al. (2005)). The idea is that models of higher complexity have lower bias but higher variance. According to this theory, once model complexity passes a certain threshold, models “overfit” with the variance term dominating the test error, and hence from this point onward, increasing model complexity will only decrease performance (i.e., increase test error). Hence conventional wisdom in classical statistics is that, once we pass a certain threshold, “larger models are worse.”
However, modern neural networks exhibit no such phenomenon. Such networks have millions of parameters, more than enough to fit even random labels (Zhang et al. (2016)), and yet they perform much better on many tasks than smaller models. Indeed, conventional wisdom among practitioners is that “larger models are better’’ (Krizhevsky et al. (2012), Huang et al. (2018), Szegedy et al. (2015), Radford et al. (2019)). The effect of training time on test performance is also up for debate. In some settings, “early stopping” improves test performance, while in other settings training neural networks to zero training error only improves performance. Finally, if there is one thing both classical statisticians and deep learning practitioners agree on is “more data is always better”.
In this paper, we present empirical evidence that both reconcile and challenge some of the above “conventional wisdoms.” We show that many deep learning settings have two different regimes. In the under-parameterized regime, where the model complexity is small compared to the number of samples, the test error as a function of model complexity follows the U-like behavior predicted by the classical bias/variance tradeoff. However, once model complexity is sufficiently large to interpolate i.e., achieve (close to) zero training error, then increasing complexity only decreases test error, following the modern intuition of “bigger models are better”. Similar behavior was previously observed in Opper (1995; 2001), Advani & Saxe (2017), Spigler et al. (2018), and Geiger et al. (2019b). This phenomenon was first postulated in generality by Belkin et al. (2018) who named it “double descent”, and demonstrated it for decision trees, random features, and 2-layer neural networks with `2 loss, on a variety of learning tasks including MNIST and CIFAR-10.
Main contributions. We show that double descent is a robust phenomenon that occurs in a variety of tasks, architectures, and optimization methods (see Figure 1 and Section 5; our experiments are summarized in Table A). Moreover, we propose a much more general notion of “double descent” that goes beyond varying the number of parameters. We define the effective model complexity (EMC) of a training procedure as the maximum number of samples on which it can achieve close to zero training error. The EMC depends not just on the data distribution and the architecture of the classifier but also on the training procedure—and in particular increasing training time will increase the EMC. We hypothesize that for many natural models and learning algorithms, double descent occurs as a function of the EMC. Indeed we observe “epoch-wise double descent” when we keep the model fixed and increase the training time, with performance following a classical U-like curve in the underfitting stage (when the EMC is smaller than the number of samples) and then improving with training time once the EMC is sufficiently larger than the number of samples (see Figure 2). As a corollary, early stopping only helps in the relatively narrow parameter regime of critically parameterized models.
Figure 1: Left: Train and test error as a function of model size, for ResNet18s of varying width on CIFAR-10 with 15% label noise. Right: Test error, shown for varying train epochs. All models trained using Adam for 4K epochs. The largest model (width 64) corresponds to standard ResNet18.
Figure 2: Left: Test error as a function of model size and train epochs. The horizontal line corresponds to model-wise double descent–varying model size while training for as long as possible. The vertical line corresponds to epoch-wise double descent, with test error undergoing double-descent as train time increases. Right Train error of the corresponding models. All models are Resnet18s trained on CIFAR-10 with 15% label noise, data-augmentation, and Adam for up to 4K epochs.
Sample non-monotonicity. Finally, our results shed light on test performance as a function of the number of train samples. Since the test error peaks around the point where EMC matches the number of samples (the transition from the underto over-parameterization), increasing the number of samples has the effect of shifting this peak to the right. While in most settings increasing the number of samples decreases error, this shifting effect can sometimes result in a setting where more data is worse! For example, Figure 3 demonstrates cases in which increasing the number of samples by a factor of 4.5 results in worse test performance.
Figure 3: Test loss (per-token perplexity) as a function of Transformer model size (embedding dimension $d_{model}$) on language translation (IWSLT‘14 German-to-English). The curve for 18k samples is generally lower than the one for 4k samples, but also shifted to the right, since fitting 18k samples requires a larger model. Thus, for some models, the performance for 18k samples is worse than for 4k samples.