AWS DeepRacer 日記 2021/10
2021年10月から本格的にDeepRacerリーグに参加し始めました。
今回はDeepRacer日記第1回です。
筆者の試行錯誤を記載していきます。
参考になればうれしいです。
※DeepRacer参加方法については下記にまとめています
10/4
学習
まずは車の作成(メニュー:Reinforcement learning>Your garage)

Stereo Cameraは障害物検知に特化なので、タイムトライアルならCamera一択だと思います。
※誰でも参加可能なVirtualLeagueはタイムトライアルです。
LIDAR sensorは光検出・測距センサーのこと。対戦や障害物検知に特化。こちらもタイムトライアルなら不要
次にモデル作成(Reinforcement learning>Your models)
学習するコースの選択
10月VirtualLeagueのTrackはExpedition Loop である模様。こちらを選択

Race TypeはVirtualLeagueなのでTime trial
トレーニングアルゴリズムはとりあえずPRO※

※トレーニングアルゴリズムは以前まではPRO一択だったが、SACが増えていたので、マニュアルを確認
英語直訳した感じの日本語でPROとSACの差があまり分からん。。
PROは安定しやすく、SACはデータ効率が良いらしい。
とりあえず今回はデフォルトのPROを選択
ハイパーパラメータは玄人向けの設定らしいので、一旦デフォルトのままとした(各パラメータの意味理解も薄い)
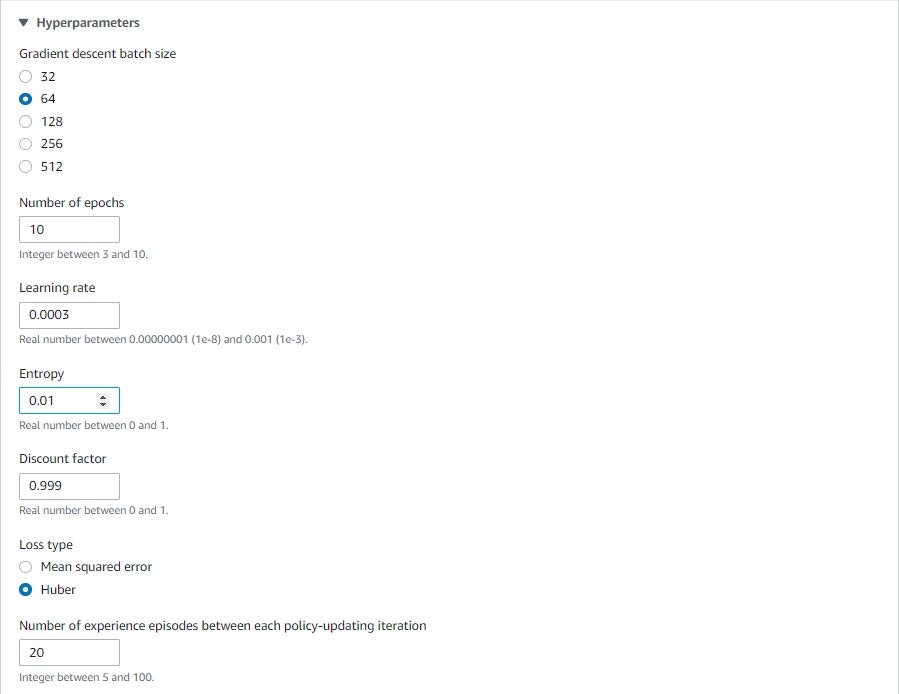
アクションスペースはスピードを2に上げてみる。あとはデフォルトのまま

デフォルトのセンターラインに近いと報酬が高い関数があるので、
それに加えて下記の記事の「パターン2:早いスピードで走行させる」を参考に
スピードが速いと報酬を多めにした記述(SPEED_THRESHOLD~)を追加
使用した報酬関数
def reward_function(params):
'''
Example of rewarding the agent to follow center line
'''
# Read input parameters
track_width = params['track_width']
distance_from_center = params['distance_from_center']
# Calculate 3 markers that are at varying distances away from the center line
marker_1 = 0.1 * track_width
marker_2 = 0.25 * track_width
marker_3 = 0.5 * track_width
# Give higher reward if the car is closer to center line and vice versa
if distance_from_center <= marker_1:
reward = 1.0
elif distance_from_center <= marker_2:
reward = 0.5
elif distance_from_center <= marker_3:
reward = 0.1
else:
reward = 1e-3 # likely crashed/ close to off track
SPEED_THRESHOLD = 1.5
speed = params['speed']
if speed < SPEED_THRESHOLD:
# 低速走行の為、報酬は少なめ
reward = reward * 0.5
return float(reward)
10/11
評価
・学習結果の確認
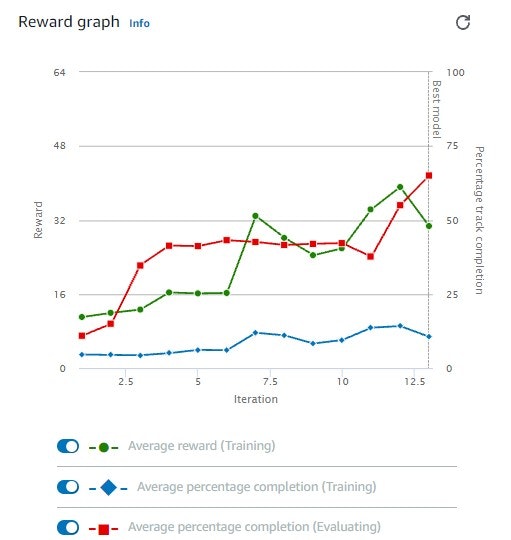
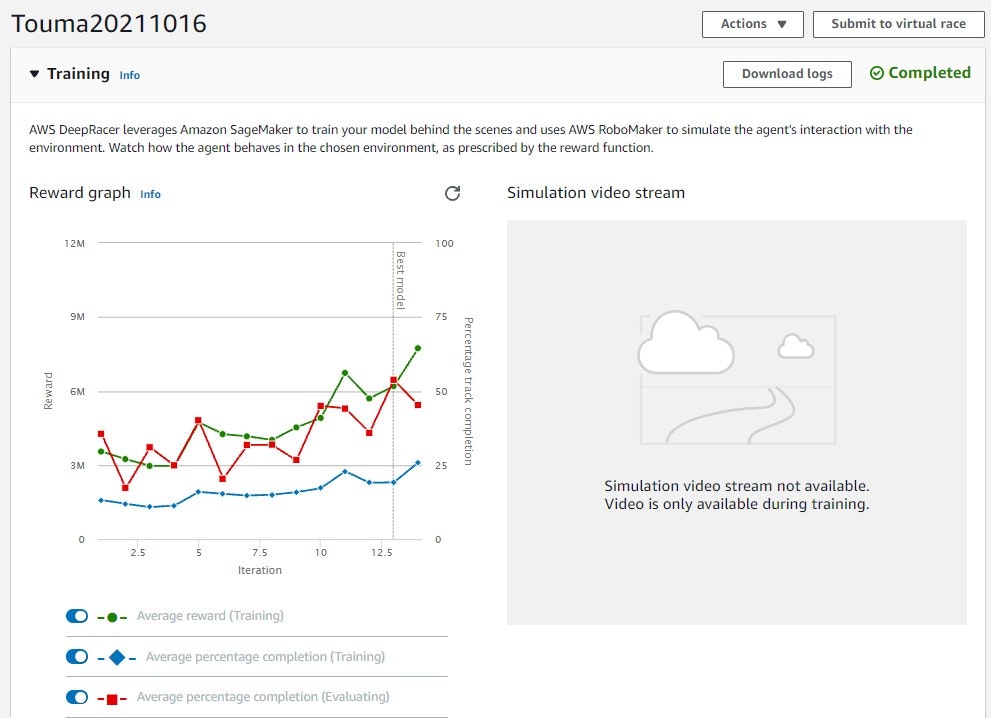
こんなグラフが作成される。
IterationごとのRewardや完走率が確認できる。
ただし、学習時のこのグラフが何に影響するのか分からない。。
・評価の実施、評価結果の確認

・VirtualLeague参加
137位(599人中)。
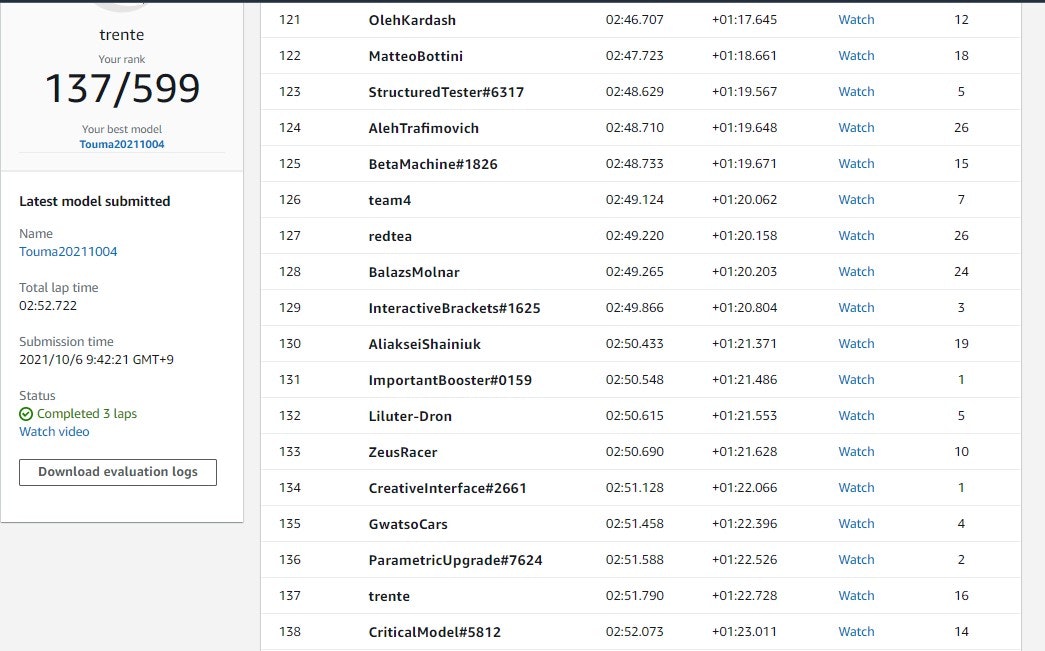
VirtualLeague参加すると動画でどのような走りだったか確認ができる
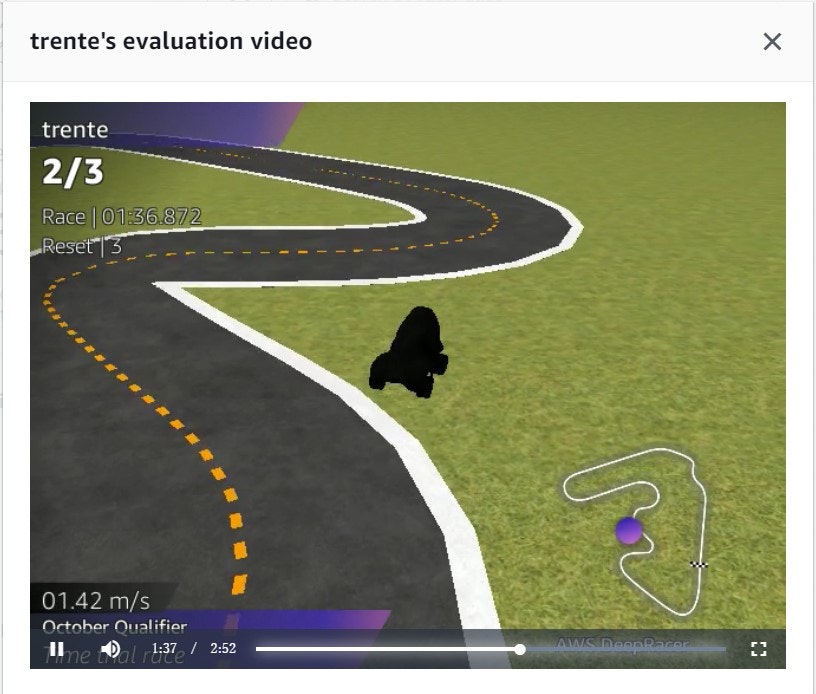
コースアウトがまだ多い印象
→センターラインにいるときの報酬を高くして再学習させた方が良さそう
スピードは直線はもう少し速くしたいが、完走率向上後に変更してみる
などの考察をした。
ここでgithubで報酬関数を検索してみる(けっこういっぱいある、感謝)
https://github.com/search?q=DeepRacer+Reward&type=Repositories
玄人っぽい人の報酬関数を発見(340行!)
https://github.com/VilemR/AWS_DeepRacer/blob/master/reward_function.py
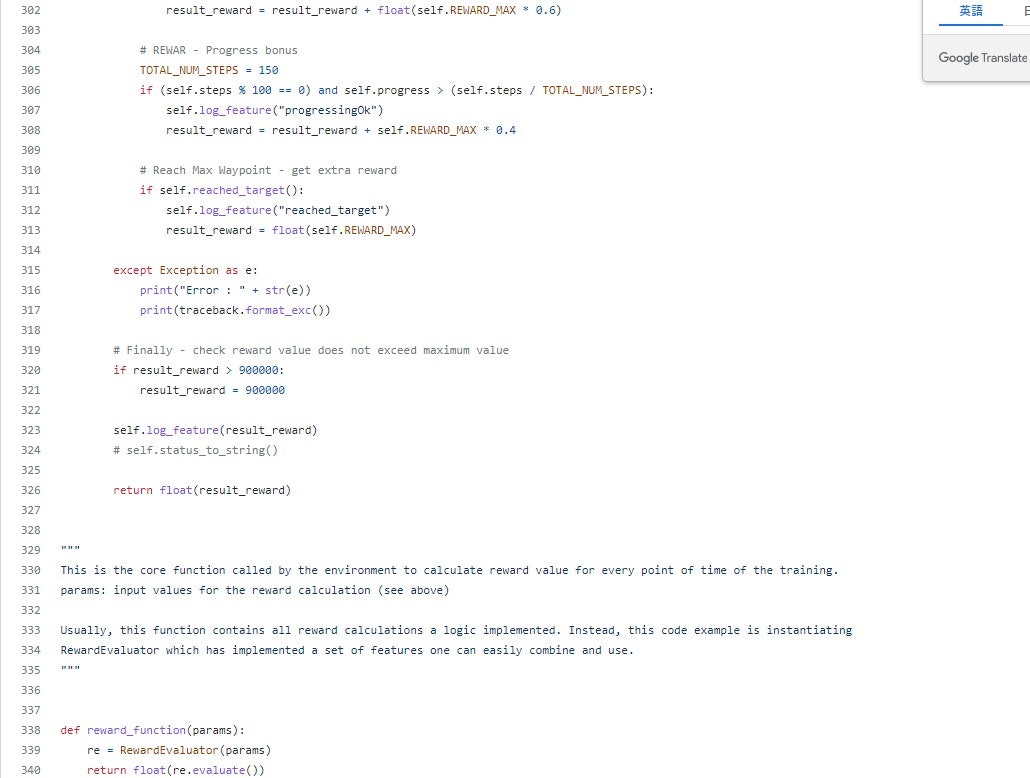
報酬関数の冒頭にコメント記載あり
This is the source code you cut and paste into AWS console. It consists of RewardEvaluator class that is instantiated
by the code of the desired reward_function(). The RewardEvaluator contains a set of elementary "low level" functions
for example the distance calculation between waypoints, directions as well as higher-level functions (e.g. nearest turn
direction and distance) allowing you to design more complex reward logic.
要約すると
「これは、AWSコンソールにカット&ペーストするソースコードです。」
複雑だが、速そうなので、意味はわからずとも全ペーストで走らせてみることにする。(ありがとうございます)
そのままコピペすると下記のエラーに
The reward function contains illegal import(s): ['traceback']"}]
tracebackがimportできない模様
tracebackはスタックトレースをログ出力するときに利用するモジュールであるため、デバッグ用と思われる
import traceback行を削除したら実行可能になった。
これでとりあえず、120分学習させてみる。
↓
なんと83位に(Off-Trackも最初の16回から5回とだいぶ少なくなった)
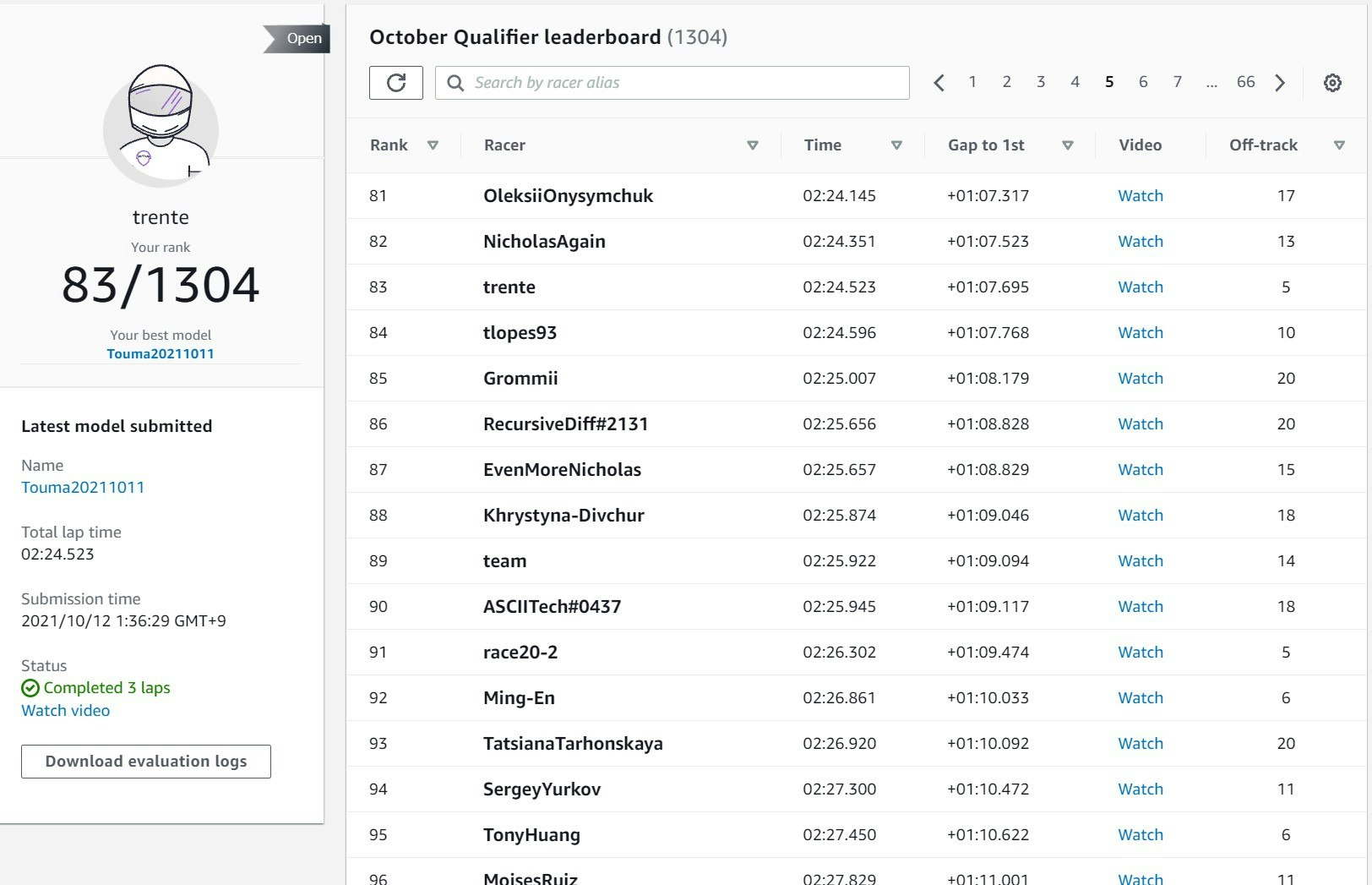
インコースを攻めながらもコースアウトが減った
ここはセンターラインに近い場合を高い評価とするデフォルトの報酬関数では起きえない動き
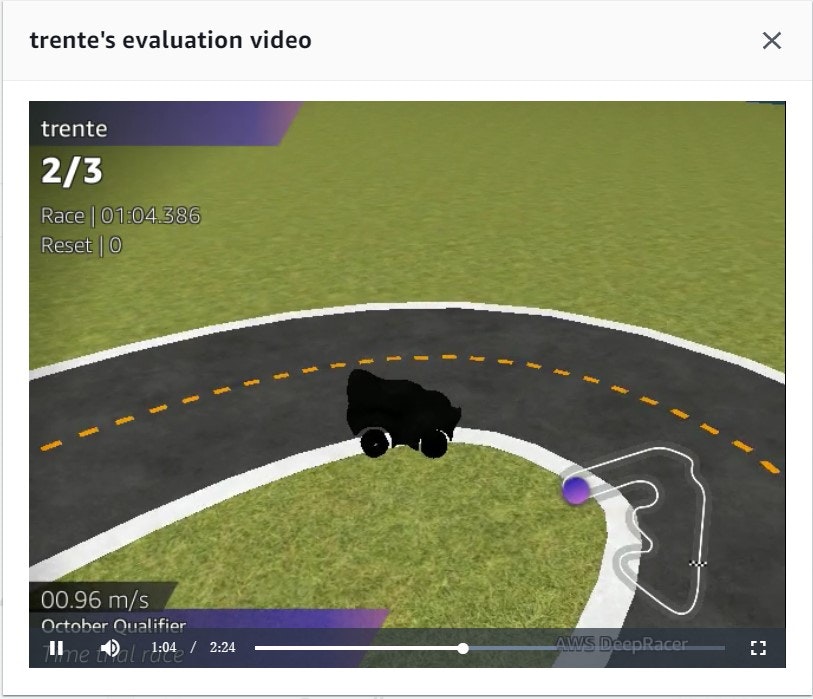
トレーニング結果的にはまだ右肩上がりで、まだ学習の余地がありそう(この理解であっているのか、調べても分からない。。)
1位の人の車を見るとスピードが全然足りていない感じがする。
評価は1回Complete(100%)した!(前回は64%)安定性はかなり高くなった。
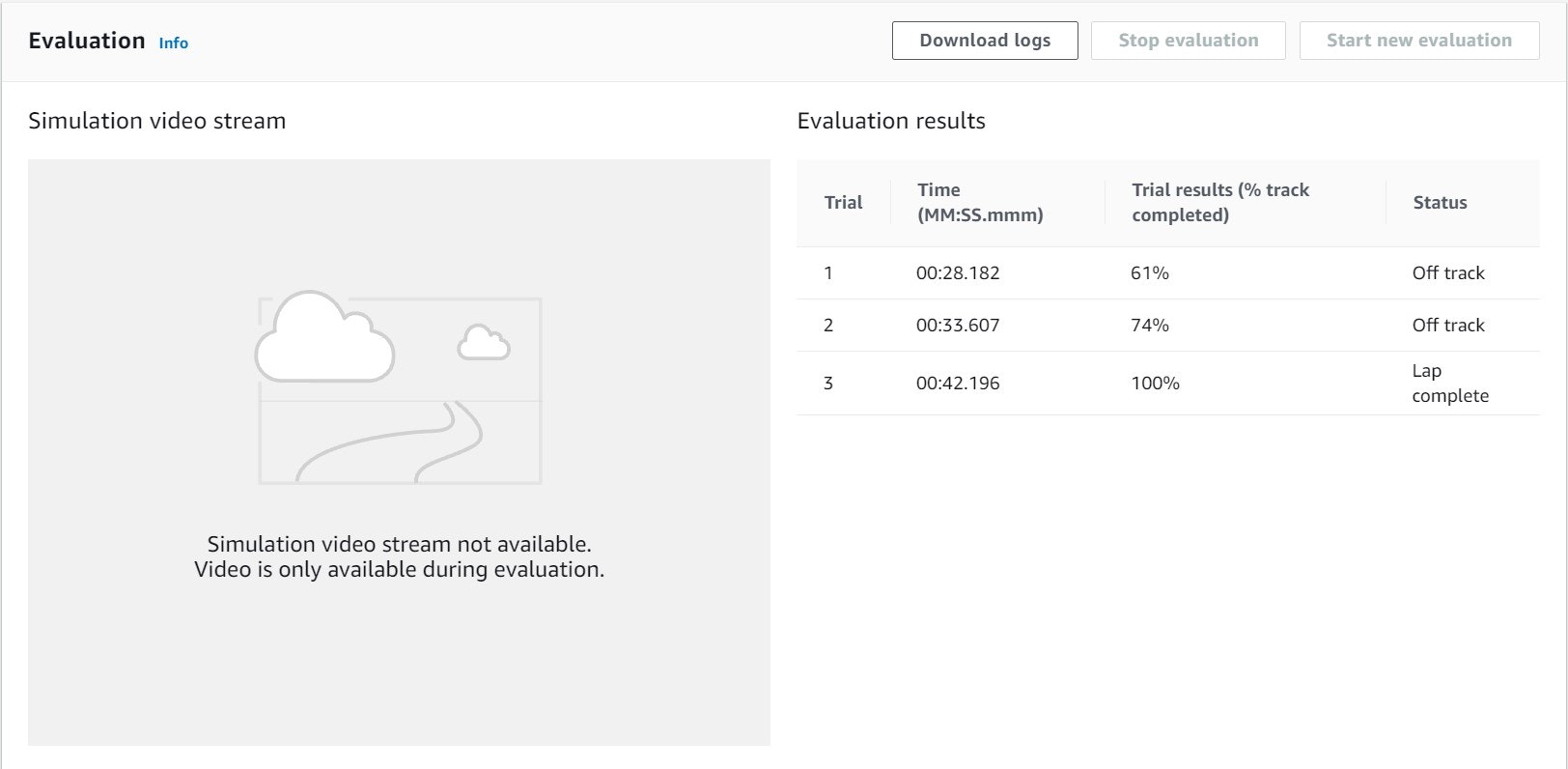
10/16
まだ成長の余地がありそうなので、同じ報酬関数でスピードだけを上げて再学習させてみる(スピードだけMAXの4に)
学習している動画を見てて思ったが、
Average percentage completion (Evaluating)はコースを平均してどれだけ走れたかを示すだけの指標で
例えば50%ならコースを半分コースアウトすることなく走れるモデルとなったことを意味している
この情報にスピードは関係なく、この評価自体が低くても(10%以下とか低すぎたらさすがに厳しいが)タイムが伸びることがありそうな気がする。
10/18
スピードが速いとカーブでコースアウトが多くなった。
2:47秒で前回モデルより23秒遅い
3周の合計タイムで競うから安定性の方を重視した方が良い結果になるのか・・。
Evaluation結果は63%で100%から下がってしまう結果となった。(学習のEvaluationグラフの通り)
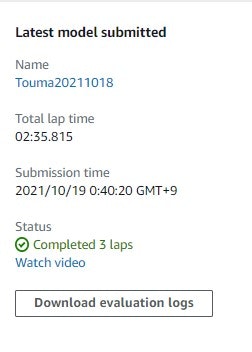
再度、10/11に作成したモデルからクローンして、スピードだけ3にして試してみる
10/25
スピードを3にしたところ、2:35(10/11の最速モデルより11秒遅い)となった。
一度コースアウトすると同じところで何度もコースアウトしたり、
直線の道でジグザグに進んでしまうことが多く見られた。

評価は1回Complete(100%)した。ただし36%でOff Trackとなっているため、
安定性はスピード2のときよりは下がる。

スピード2にして全く同じパラメータで再学習させてみる。
ここで評価・分析のやり方がこれでよいのか気になってきたので、調査。
ログ分析の実施
タブローパブリックのダウンロードを実施し、下記サイトの通りやってみる
https://dev.classmethod.jp/articles/analysis_sim_trace_log/
・タブローダウンロード
https://public.tableau.com/ja-jp/s/download
10/28
スピード2にして全く同じパラメータで再学習させてみたところ、2:40で学習時間が短いモデルよりも遅くなった。

全く同じパラメータで多くの時間学習させ続けても成果が出ないことが分かった。(これが過学習なのか。。)
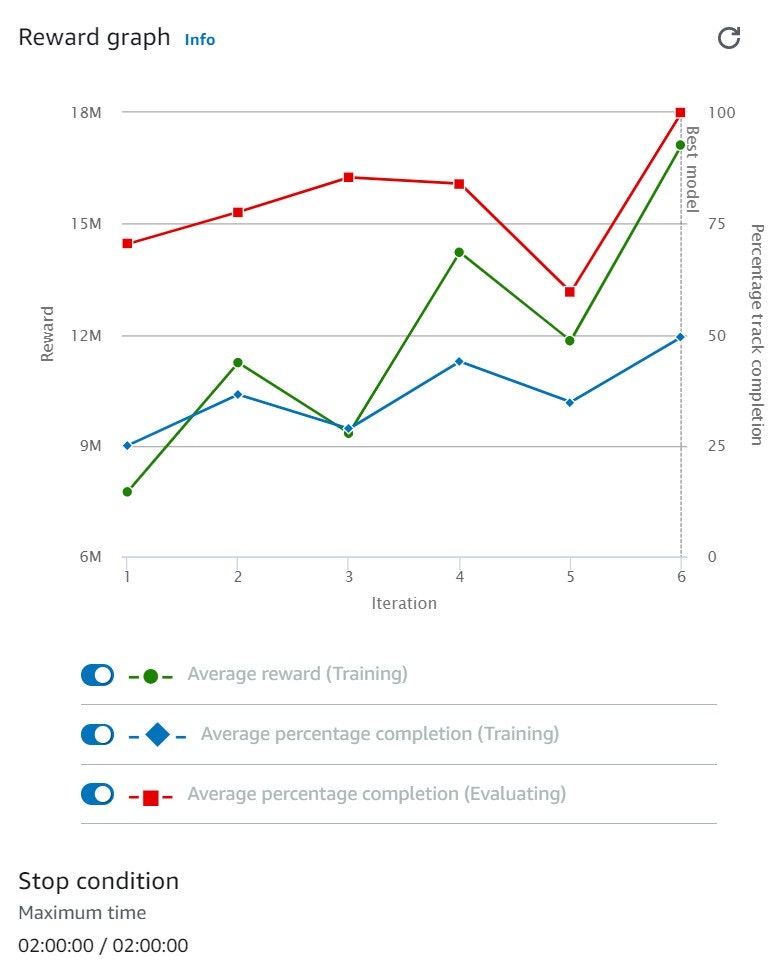
学習のEvaluationグラフは100%に達していて、今までのモデルで最高の値になっていた。
カーブが連続する箇所でのコースアウトが目立つ。あと、やはり一度コースアウトすると連続でコースアウトする傾向にある。

ログ分析の実施
sim-traceのログにはスピードの項目が無いので、分析が難しいのではと感じた。
ログ分析で得られるものもあるとは思うが、Virtual Circuitへの参加を行うと、
いつでも動画で結果を確認できるので、現状はそれが改善検討を行う上では一番良さそう。
まとめ
・下記の報酬関数を利用すればだれでもプロリーグの参加が可能!!
https://github.com/VilemR/AWS_DeepRacer/blob/master/reward_function.py
・評価は現状ではリーグ参加して動画で見るのが一番良さそう
※ハイパーパラメータの理解を進めて、効率よく学習させる方法を調査したい。