長かった学生生活の最後のクリスマス前に(研究をサボって)人生初のアドベントカレンダー投稿です。内容は悩んだのですが、今後、疎遠になる可能性の高い統計的検定の内容を投稿しようと決めました。(あとは、統計的検定は学生だったら皆さん通る道なのかなと思ったからです。)
表題の通り、統計的検定(t検定、one-way ANOVAと多重比較)とその検定結果の可視化までをすべてPythonでやろうという内容です。この記事は下記のノートブックの内容の説明なので、プログラムだけで良いという方は下をご覧ください。
2022/12/21追記: @WolfMoon さんのご指摘を受けて記事を修正しています。
背景
実験計画を立てデータを取得した後、統計的検定を実際に行う場合、いろんな選択肢があるかと思います。多くの人はExcelやRを使うかと思います。自分の研究室では js-STAR というWebアプリを使うことが勧められていました。js-STARは検定結果を出す(後ろはRで動いてます。)ところまで行ってくれます。様々な検定手法がカバーされていてとても便利なツールで愛用していました。論文では検定結果を図表にして載せる必要があるので、js-STARで出力された検定結果を別のツールを使い、図表の出力していました。
しかし、ツールを跨ぐというのは時間がかかり、非常に面倒です。図の出力はPythonを使っていたので、検定の部分もPythonで行い、一気通貫で論文に使える図を出力しようというのがこの記事の内容になります。この記事ではt検定とANOVAと多重比較を行い、多重比較の結果を 棒グラフ 箱ヒゲ図で表示します。すべて平均値の比較のケースです。
統計的検定
検定はScipyを使います。ほんとに簡単にできます。もっと早く使っておけばよかった。
検定方法は適宜、下記ページから選んでください。
t検定
ここでは1要因の2水準のデータを考えます。
Scipyには対応ありと対応なしの関数(ttest_ind, ttest_rel)、統計量を与えてt検定を行う(ttest_ind_from_stats, ttest_1samp)計4種類の関数が用意されています。
今回は対応ありのttest関数であるttest_relを使います。
ttest_data_df = pd.read_csv("読み込むデータ")
ttest_result = ttest_rel(*ttest_data_df.values.T.tolist())
print(ttest_result)
# Ttest_relResult(statistic=-4.255038352867175, pvalue=0.01310531204506057)
※ 最初に示したノートブックでは手間を省くために1要因5水準のデータソースから2水準に絞って検定を行っていますが、良くない方法なので、真似しないでください。実験計画で2水準と決めて収集したデータを使ってください。
ANOVAと多重比較
ここでは1要因5水準のデータを扱います。検定の仕方などは様々議論があり深すぎる内容なのでここではあまり考えません。研究分野や研究室の慣例や正しいと思う方法を採用してください。ここではANOVA、事後検定で多重比較を行います。
from scipy.stats import f_oneway, tukey_hsd
data_df = pd.read_csv("読み込むデータ")
# One-way ANOVA
anova_result = f_oneway(*data_df.values.T.tolist())
print(anova_result)
# F_onewayResult(statistic=10.037079093822024, pvalue=0.00012680522359504427)
# 多重比較(Tukey HSD method)
tukeyhsd_result = tukey_hsd(*data_df.values.T.tolist())
print(tukeyhsd_result)
# Tukey's HSD Pairwise Group Comparisons (95.0% Confidence Interval)
# Comparison Statistic p-value Lower CI Upper CI
# (0 - 1) 185.800 0.179 -53.666 425.266
# (0 - 2) -232.800 0.059 -472.266 6.666
# ...
ANOVAも多重比較のTukey's HSD法も関数を呼び出すだけで実行できます。実行結果をjs-STARの結果と比較しましたが、ちゃんと同じ結果になっていました。
次にこの検定結果を可視化していきます。
検定結果の可視化
可視化ではseabornとmatplotlib、vistatsの3つのパッケージを使います。seabornはカラーマップの取得のみで使用したので正直いらないかもしれないです。ちなみにvistatsは自分が作ったパッケージでその話は
に書きました。(pip installできます)
ここから手順を書いていきます。
棒グラフとブラケットの描画(ダイナマイトプロット)
ダイナマイトプロットについて
下記に記事にもある通り、あまり好ましくないブラフとのことです。("dynamite plots must die"って過激なタイトルですねw)
とはいえ、公開していたのでとりあえず残しておきます。利用には注意してください。
ダイナマイトプロットの描画
平均と標準誤差の計算とX軸のデータの作成
# ttestとtukey hsdでそれぞれ算出
bars = np.arange(len(data_df.columns))
means = data_df.mean(axis=0)
sems = data_df.sem(axis=0)
グラフ間のブラケットとテキストの準備。scipyで得られた検定結果を図で使いやすいように変換します。
from vistats.util import ttest_result2asterisk_tuples, tukeyhsd_result2asterisk_tuples
asterisk_tuples = ttest_result2asterisk_tuples(ttest_result)
tukeyhsd_asterisk_tuples = tukeyhsd_result2asterisk_tuples(tukeyhsd_result)
print(tukeyhsd_asterisk_tuples)
# [(1, 2, '**'), (1, 3, '**'), (1, 4, '**')]
箱ひげ図の描画とブラケット&テキストの描画。
import matplotlib.pyplot as plt
import seaborn as sns
from vistats import annotate_brackets
fig, ax = plt.subplots(figsize=(16, 9))
# 自動で色を決めるためカラーマップの取得
cmap = sns.color_palette("Set2", as_cmap=True)
# 図の枠線の削除
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['left'].set_visible(False)
plt.gca().spines['bottom'].set_visible(False)
plt.tick_params(bottom=False, labelsize=28)
# 棒グラフの描画
plt.bar(
bars, means,
tick_label=data_df.columns.tolist(),
yerr=sems,
capsize=15.0,
error_kw={"capthick": 3.0},
align='center',
color=cmap.resampled(len(data_df.columns)).colors
)
# ブラケットとテキストの描画
annotate_brackets(
asterisk_tuples, bars, means.tolist(),
yerr=sems.tolist(), fs=28
)
# X, Y軸のラベル
plt.ylabel("performance", labelpad=15, fontsize=28)
plt.xlabel("method", labelpad=15, fontsize=28)
多重比較で最終的に出力される図(t検定の図は省きます。)
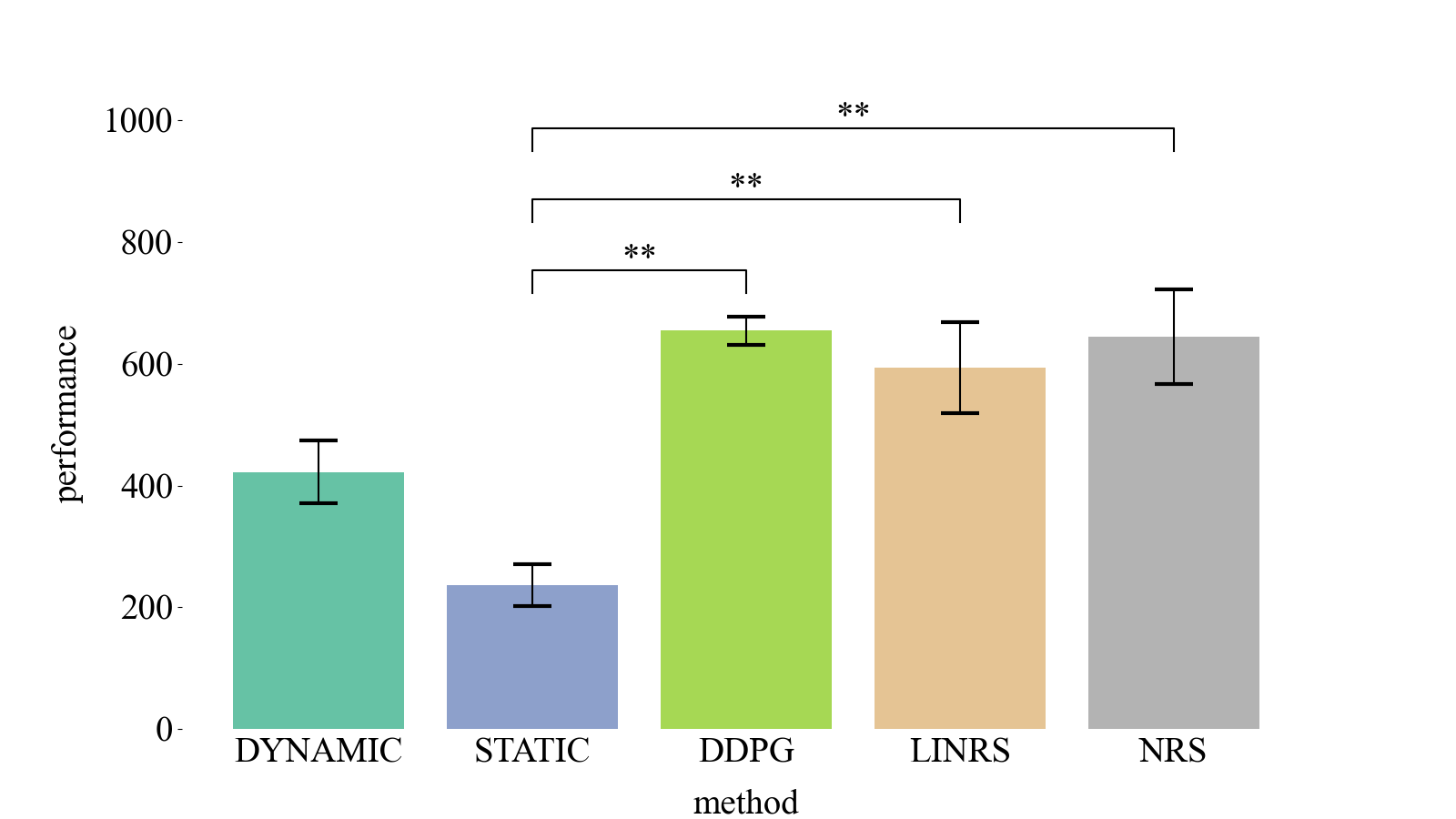
箱ひげ図
2022/12/21に追記した内容です。
モジュールの読み込み
from scipy import stats
from vistats import boxplot_annotate_brackets
グラフの描画部分
fig, ax = plt.subplots(figsize=(16, 9))
cmap = sns.color_palette("Set2", as_cmap=True)
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['left'].set_visible(False)
plt.gca().spines['bottom'].set_visible(False)
plt.tick_params(bottom=False, labelsize=28)
plt.rcParams["font.family"] = "Times New Roman"
bplot = plt.boxplot(data_df.values, labels=data_df.columns.tolist(), patch_artist=True)
boxplot_annotate_brackets(asterisk_tuples, data_df.values, fs=28)
for box, sample_cmap in zip(bplot['boxes'], cmap.resampled(len(bplot['boxes'])).colors):
box.set_facecolor(sample_cmap)
plt.ylabel("performance", labelpad=15, fontsize=28)
plt.xlabel("method", labelpad=15, fontsize=28)
matplotlibのboxplotで箱ひげ図を描画し、boxplot_annotate_bracketsでブラケットとテキストを描画しています。asterisk_tuplesは棒グラフと同じです。
出力されるグラフは
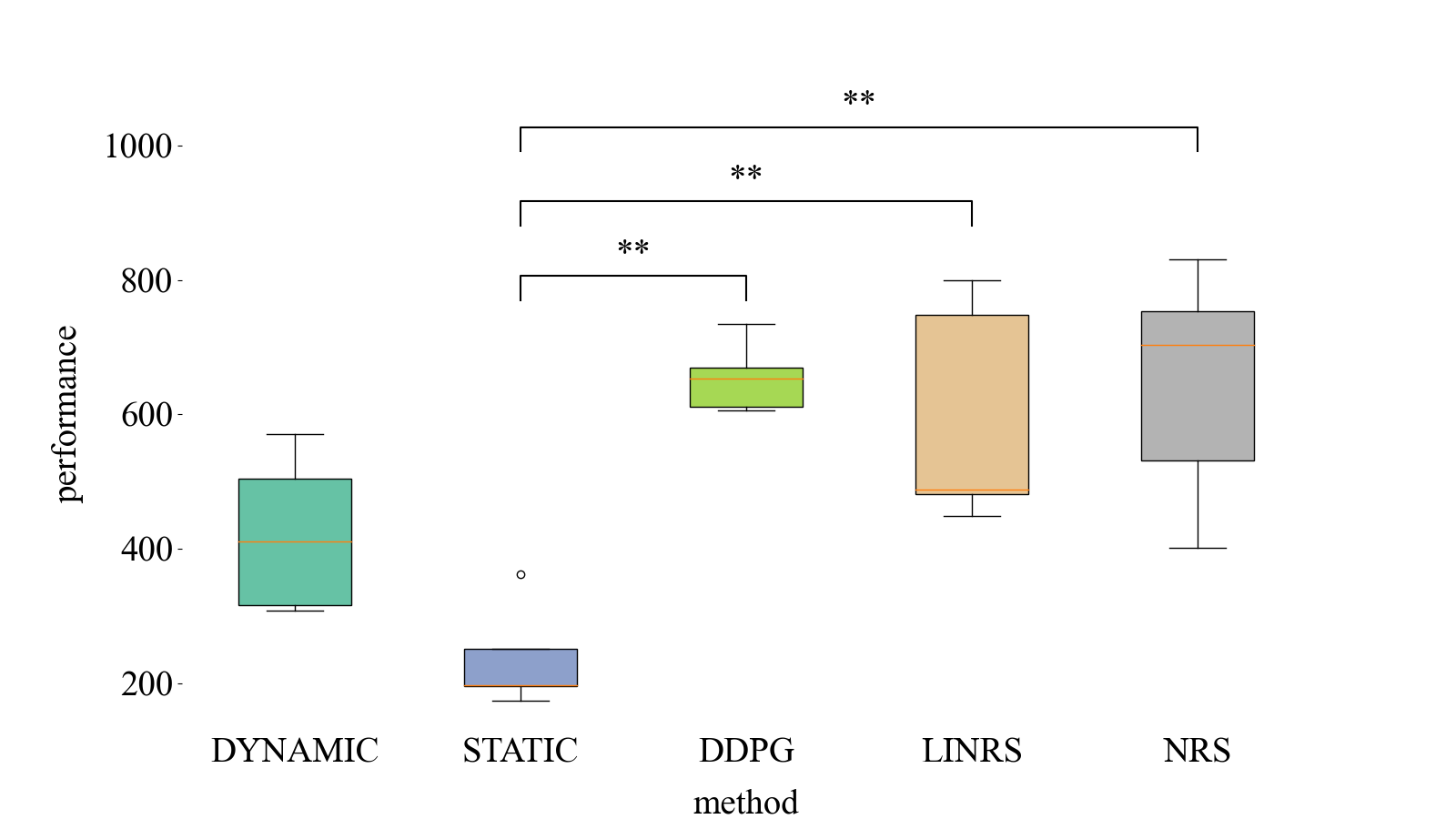
最後に
ここまで書いたコードは下記のノートブックにまとまっています。
今回は多重比較やT検定で論文に載せる図をPythonで一気通貫に出力する内容を書きました。書いてる最中に後輩からtwo-way ANOVAのグラフ出力についても書いて欲しいと言われたので卒業までにその内容も書きたいなと思います。残り約3ヶ月の学生生活楽しむゾー!