今回読んだ論文はAlibabaのチームによる論文でした!(Qiitaでの発信は初めて)
Alibabaが提供するECサイトのTmallでの価格決定で用いるアルゴリズムに強化学習のアプローチを取りましたという内容になります。
あとで更新をかける予定です。まずは簡易版で公開しようと思います。
学会ではRejectされているようでしたが、興味があったので読んでみました。
Dynamic Pricing on E-commerce Platform with Deep Reinforcement Learning
ダイナミックプライシングとは?
ダイナミックプライシングは在庫や市場での需要を見ながら動的に価格を決定することを指します。価格決定を自動化しようとします。ダイナミックプライシングにおける難しさは、大きく下記の三点があります。
- 市場の定量化が難しい(予測が難しい)
- 少しでも不適切な価格設定が大きな損失を招く。
- 違法になるため、オンラインでのA/Bテストができない。(同時期に同じ商品に異なる価格をつけると違法になる。)
この論文はmarkdown pricingとdaily pricingに絞って考えると書かれていました。これらの違いは在庫の考え方の違いにあると解釈しています。markdown pricingは割引できる商品数には限りがあり、在庫数が有限と考え、daily pricingは在庫数が無限であると考えた上での価格決定をします。論文では直接説明がなかったので、全体を読んで上記のように解釈しました。
(ダイナミックプライシングの知識がなさすぎてこの解釈が合っているのかがわからないのですが...)
Dynamic Pricing as a MDP
強化学習を使うためにダイナミックプライシングをマルコフ決定過程の枠組みに落とします。表でまとめます。
||記号|項目|
|---|---|---|---|
|製品|$i$||
|状態|$s_{i,t}$|値段、売上個数、収益、実際の値段、値引率、クーポン、ページビュー数、固有訪問者数、購入者数、顧客コメント、類似製品の状態|
|行動|$a_{i,t}$|製品ごとに行動空間が異なる。それぞれに価格帯が設定されており、その範囲内の価格|
|報酬|$r_{i,t}$|下節で説明|
|行動頻度|$d$|1日ごと|
行動空間が価格帯における価格で製品ごとに行動空間が異なる点などはならではの設定と思いました。
報酬関数の設計
報酬関数は製品ページを見た固有ユーザーあたりの収益を報酬関数として用います。
$r_{i,t} = revenue_{i,t}/uv_{i,t}$
保管コストなどが算出可能で、コストを算出できる場合は、固有ユーザーあたりの利益を報酬関数として用います。
$r_{i,t} = profit_{i,t}/uv_{i,t}$
しかし、ここまでの報酬関数ではfast-moving customer goods(FMCG;消費者向けの低価格の製品、日用品など)の価格決定の方策学習には向かないということが論文中で主張されています。(理由に関しては追記予定)
最終的に報酬関数は下記のような形になります。
$r_{i,t} = \frac{revenue_{i,t}}{uv_{i,t}} - \frac{revenue_{i,t-\tau}}{uv_{i,t-\tau}}$
この関数を**DRCR(The Difference of the Revenue Conversion Rates)**と呼び、時刻$t$における固有ユーザーあたりの収益と時刻$t-\tau$における固有ユーザーあたりの収益の差分で表されます。ここで、$\tau$は任意の時間間隔を表します。つまり、$\tau$だけ時間が経って、1人あたりの収益がどれだけ変化したかという値です。
この報酬関数で学習された方策は固有ユーザーあたりの収益の上昇幅が最大になるような挙動をすることを目指しているというわけですね。
モデルの選択
行動空間は製品の値段ということは前節で記述しました。値段は連続値で表現することができます。ただし、スパンで区切ると離散値での表現も可能になります。強化学習では行動空間が連続か離散かで使用するモデルが変わります。
この論文では、連続値の場合はDDPGというモデル。離散値の場合はDQNというモデルを用います。
実験結果
DQNとDDPGと人が設定した場合であるControl groupの30日間のDRCRの推移の図が下図です。
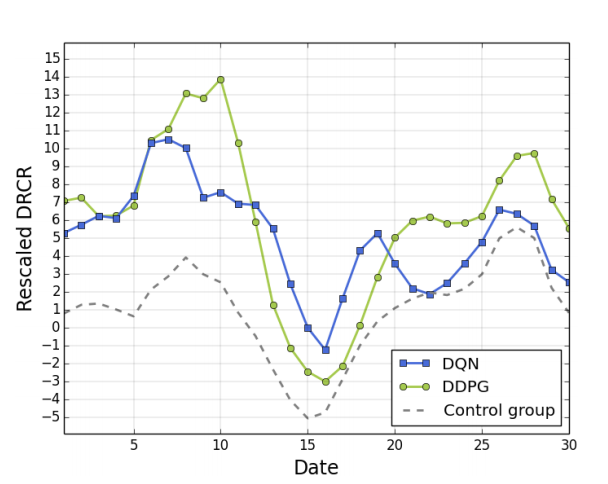
全ての日で強化学習のアルゴリズムで価格を設定した場合に人が設定するよりもDRCRが大きくなっていることがわかります。DRCRは固有ユーザー1人あたりの商品の売上の増減を表しているので、強化学習アルゴリズムを使った方が固有ユーザー1人あたりの商品の売上を増加させることができていることがわかります。
ここまで、強化学習によるダイナミックプライシングに関する論文の内容をまとめました。あまり時間がなく色々省いているので、今後時間を作って追記していけたらなと思ってます!