概要
統計的な有意差を示すためのブラケットとテキストを描画するパッケージを作りました。そのときに工夫した点を備忘録的に残しています。
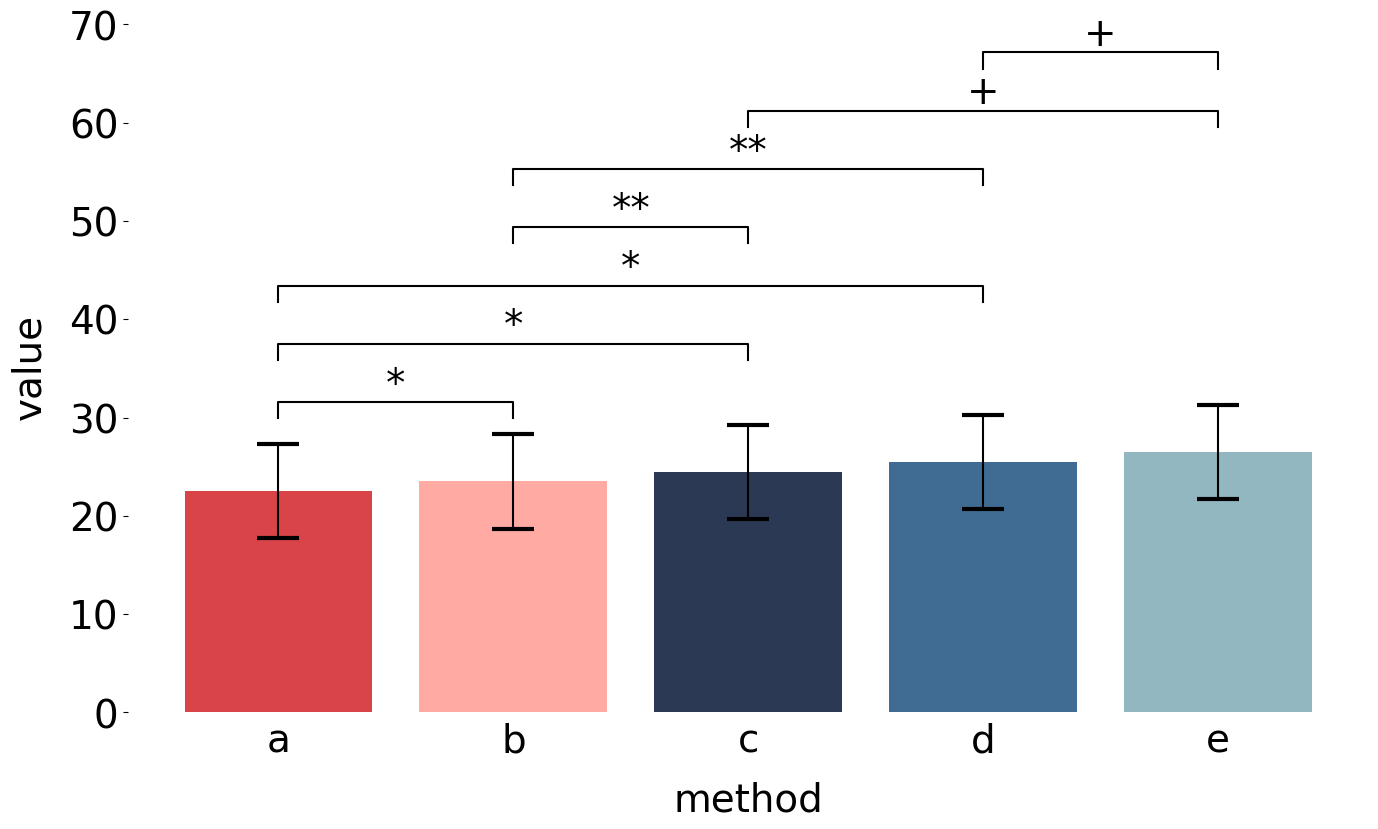
下図の描画をMatplotlibと自作パッケージの関数を使って行うことができるようになります。
PyPIにもPublishしたので、pip installして使えるかと思います。
2022/12/29
座標内のテキストの高さにおいて誤りがあったので修正しました。
背景
統計的検定の結果を示すために棒グラフと該当ラベルの棒グラフ間をブラケットで囲み、その上にテキストを記述することが多くあります。
水準数が少なかったり、作成の機会が少ない場合はPowerPointなどで追加する方法で十分かと思いますが、多くなった場合に非常に手間です。
その問題に自分もぶち当たったのでPythonパッケージののMatplotlibで描画できるようにした話を書きます。
統計的な有意差をMatplotlibで描画するという話はあり、「統計的有意 グラフ python」で検索すると山拓さんの記事が出てきました。
この記事ではstack overflowの回答が参照されており、ここで示されたスクリプトを使って描画することも可能です。
という話であれば自分が改良を加える必要はなく万々歳だったのですが、実際に使ってみると引数の値を調整しないとブラケットとテキストが被ってしまい個別に調整が必要でした。出力するグラフが多くなるとそれぞれのグラフごとの調整が必要になり非常に手間でした。
具体的に、Stack overflowのスクリプトを参照すると、
barplot_annotate_brackets(0, 2, 'p < 0.0075', bars, heights, dh=.2)
dhという引数の値を調整しないとブラケットとテキストが被ってしまいます。
その手間をなくすための実装の話をここからしていきます。
課題
上記の手間を省くためには、ブラケットとテキストがかぶらないように自動で調整する必要があり、その調整のためにはテキストの高さを知る必要があります。Stack overflowの実装はテキストの高さを扱わず、AxesのY軸の高さを拠り所にdhの割合で間隔を決定する実装になっています。
自分も質問に回答するためであれば、面倒そうなのでテキストの高さは扱いたくないですネ(笑)
しかし、今回はそこから逃げずに実装をしてみました。ちょっと大変でした...。
座標内のテキストの高さ
さて、Matplotlibの座標内でテキストの高さを得る方法について記述します。ここで行うのはフォントサイズから座標(Axes)内の高さへの変換です。
フォントサイズはptで指定されますが、そのままでは座標内の単位には適しません。28ptのフォントは座標中で28の大きさではないということです。
ここで知りたくなるのは1ptが座標中ではいくつになるのかです。
Axesクラスは、各軸の最大値と最小値、バウンディングボックスの情報を保持しています。これらの情報からフォントサイズがy軸上ではいくつになるかを計算します。
p_miny, p_maxy= plt.gca().get_window_extent().get_points()[:, 1]
gcaは現在のAxesを取得しています。get_window_extentによりBboxクラスを取得し、get_pointsで頂点の値を取得できます。そしてスライスによりy軸の値に絞っています。ここで取得される値はピクセルです。
次にフォントサイズptをピクセルの単位に変換します。ptを1pt=1/72インチという関係を使ってインチに変換し、インチをdpiを使ってピクセルに変換します。dpiはdots per inchの略称で1インチあたりのドット数を表します。ここで、1dot=1pxであるため、
# pt to inch (1pt = 1/72 inch)
fsinch = fs / 72
# inch to pixel
fspx = fsinch * plt.rcParams["figure.dpi"]
これでピクセル単位におけるフォントのサイズが分かりました。あとは、y軸上におけるフォントのサイズに変換するだけです。
y軸の最大値と最小値は、
ax_min_y, ax_max_y = plt.gca().get_ylim()
により取得できます。y軸上でのフォントのサイズは
fspx * (ax_maxy - ax_min_y) / (p_maxy - p_miny)
で算出することができます。
この記事を参考にしました。
Y軸の最大値の変化
座標内のテキストの高さを決めるためにはY座標の最大値と最小値を使いました。最大値はブラケットとテキストを追加することによって大きくなってしまいます。特にブラケットとテキストの数が増えれば増えるほどにそれは顕著です。
最大値が大きくなるため、ブラケットとテキストを追加する前の最大値でテキストの高さを算出すると、本来の高さよりも小さく算出してしまうことになります。このままにしておくとブラケットがテキストと被ってしまいます。
そこで事前にどれくらい大きくなるかを見積もって追加後のY座標の最大値としてテキストの高さを算出します。
# グラフとブラケットの間隔
fixed_dh = dh * (ax_max_y - ax_min_y)
# ブラケットの高さ
fixed_barh = barh * (ax_max_y - ax_min_y)
# テキストとブラケットの間隔
fixed_text_dh = text_dh * (ax_max_y - ax_min_y)
# テキストの高さ
font_height = fs * (ax_max_y - ax_min_y) / (p_maxy - p_miny)
ax_max_y += fixed_dh + len(tuples) * (fixed_text_dh*2 + fixed_barh + font_height)
ブラケットの高さ、追加前の最大値から算出したテキストの高さ、テキストとブラケットの上下間隔を1セットととして描画する件数をかけ合わせたものをグラフとブラケットの間隔に足し合わせた値だけ最大値が大きくなるという見積もりです。ここで算出された座標の最大値を使ってテキストの高さを再計算します。
テキストの高さの算出にテキストの高さを使うという入れ子構造になって少しややこしくなりましたが、ブラケットの数をよっぽど追加しない限りはブラケットとテキストの被りが発生しないかと思います。また、この処理を繰り返せばより被りが発生しづらくなるかなと予想しています。
普段は機械学習系の分野にいるですが、ある変数の推測(テキスト高さの推測)とそれの利用(座標の高さの算出)を繰り返すEMアルゴリズムぽい処理になってしまったと思いました。笑
パッケージング
スクリプトをコピーして使うというのでもいい気がするのですが、悩み(どこに配置するのか、使いまわしをどうするのか)が減るので、パッケージ化しました。
poetry を使ってみましたが、めちゃくちゃ便利ですね。パッケージのPyPIへの公開がかなり簡単でした。
実装した関数について
Stack overflowの回答で用いられた名前と同じbarplot_annotate_bracketsという関数名で実装しています。
コード中に説明を書いていますが、日本語の備忘録としてここに引数をまとめておきます。
| 引数 | 型 | 必須 | 説明 |
|---|---|---|---|
| tuples | Tuple[int, int, str] | ○ | ブラケットを描画する棒グラフの組とテキスト、棒グラフはcenterの値ではなくインデックスで指定する。 |
| center | np.ndarray | ○ | X軸の値(plt.barの入力) |
| height | np.ndarray | ○ | 棒グラフの高さ(plt.barの入力) |
| yerr | np.ndarray | ○ | エラーバーの値(plt.barの入力) |
| dh | float | エラーバーとブラケットの間隔(0~1)。座標の最大-最小に対してかけられる。 | |
| barh | flaot | ブラケットの高さ(0~1)。座標の最大-最小に対してかけられる。 | |
| text_dh | float | ブラケットとテキストの間隔(0~1)。座標の最大-最小に対してかけられる。 | |
| fs | Optional[int] | フォントサイズ。指定がなければデフォルトの値を取得する。 |
dh以下は指定せずともデフォルトである程度はいい感じ描画ができるかと思います。
実際に表示してみる
下記にアップしていますが、試しに表示をしてみました。主なところだけ抜粋します。全体はリンク先を確認ください。
読み込み処理
from vistats import barplot_annotate_brackets
グラフの描画処理
plt.figure(figsize=(16, 9))
plt.gca().spines['right'].set_visible(False)
plt.gca().spines['top'].set_visible(False)
plt.gca().spines['left'].set_visible(False)
plt.gca().spines['bottom'].set_visible(False)
plt.tick_params(bottom=False, labelsize=28)
bars = np.arange(len(target_data_df.columns))
plt.bar(
bars, means,
tick_label=target_data_df.columns.tolist(),
yerr=sems,
capsize=15.0,
error_kw={"capthick": 3.0},
align='center',
color=["#d94448", "#ffaaa2", "#2b3955", "#406c93", "#92b7c0"]
)
# run the function after plt.bar
asterisk_tuples = [(0, 1, "*"), (0, 2, "*"), (0, 3, "*"), (1, 2, '**'), (3, 4, "+"), (1, 3, '**'), (2, 4, "+")]
annotate_brackets(
asterisk_tuples, bars, means.tolist(),
yerr=sems.tolist(), fs=28
)
plt.ylabel("value", labelpad=15, fontsize=28)
plt.xlabel("method", labelpad=15, fontsize=28)
これにより、ページ先頭のグラフが出力されます。高さの調整が必要なくて便利になりました。
おわりに
入力チェックはしていないので、ある程度妥当な値が関数に入力されることを前提としてます。また、ブラケットの描画位置はまだまだ工夫の余地があります。例えば上図のd-e間のブラケットはエラーバー直上に表示した方が見栄えがいいかもしれません。
これにより統計的な有意差をグラフで示すことが少しでも簡単になれば幸いです。
(ここまで書いて、もとのスクリプトの説明もしといた方が良かったかなと思いましたが、、、気が向けば書こうかと思いますw)