■完成出力
・対象データが movieId が2の場合の出力
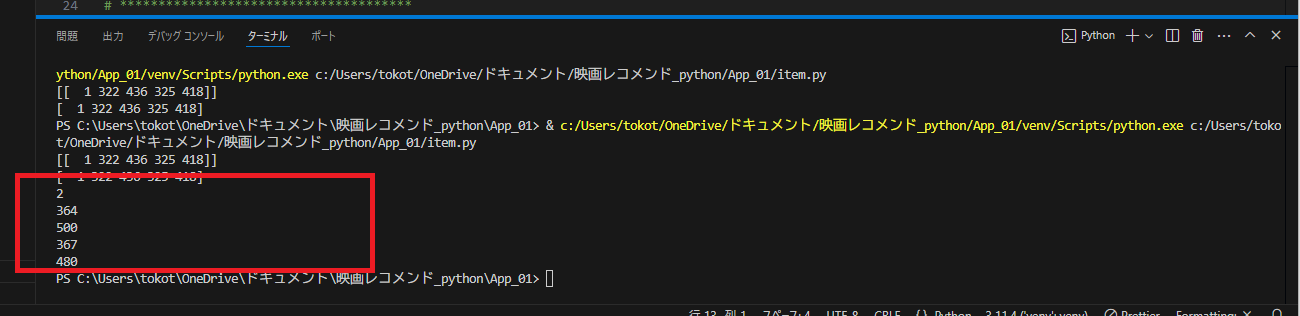
・データ例
・movieId 364のカラム列
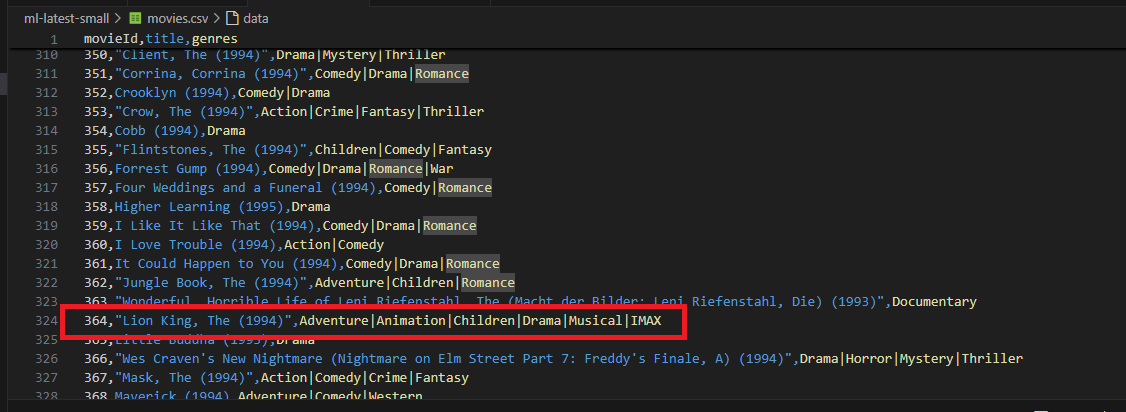
■ソースコード
item.py
import pandas as pd
from sklearn.neighbors import NearestNeighbors
import numpy as np
###============= アイテムベースでレコメンド =============###
# 読み込み
df = pd.read_csv("ml-latest-small/ratings.csv")
# 先頭出力
# print(df.head())
# 疎行列(ほとんどの要素が 0 の行列)
# アイテム/ユーザ行列
#pandas ピボット
df_rating = df.pivot(index="movieId", columns="userId" ,values="rating").fillna(0)
# print(df_rating.head())
###### 最近傍探索
neigh = NearestNeighbors(metric="cosine")
# **************************************
# ****** 学習する *******
# **************************************
neigh.fit(df_rating)
# ★★★★★★ 特定の映画に近いものを探索 ★★★★★★
# movieId2 に近いもの
distanve, indices = neigh.kneighbors(df_rating[df_rating.index == 2])
# [[ 1 322 436 325 418]] 2次元のindex
print(indices)
# ↑ 1次元にする
print(indices.flatten())
# 出力
for i in indices.flatten() :
print(df_rating.index[i])
### 出力 結果
# 2
# 364
# 500
# 367
# 480