システムを構築する上で、規模が大きくなればなるほど考える必要が出てくるのが可用性や耐障害性です。
クラウドを用いるのが当たり前になった昨今は、ある程度この辺を意識しなくてもシステムを構築できるようになりましたが、
1つのリージョンがダウンした場合でもサービス全体が止まらないような構成を考えなければならないこともあります。
(AWSの障害で〇〇が使えなくなった!などは記憶に新しいです・・・)
高可用性と耐障害性、どっちがどっちかよくわからなくなってしまうのでまとめました。
高可用性と耐障害性という言葉の意味
- 高可用性
つまり、高可用性とはサービスが停止する時間がどれくらい短いか。
もっというと「利用者がどれだけサービスを利用できるか」を指します。
引用元にも記載の通り、クラスタリングなどを用いて実現します。
- 耐障害性
稼働率について
可用性をはかる尺度として、稼働率という指標があります。
稼働率とはサービスが提供できている時間の割合のことです。
例えば、Googleが提供するmBaaSであるFirebaseは月間稼働率が99.5%未満で99.0%以上の場合は10%の返金、
99.0%未満だった場合は30%の金額を返金すると定めています。1
月間稼働率99.0%というのは月間で7.2時間までサービスがダウンする可能性があるということです。
月間稼働率99.5%だとダウンタイムは3.6時間です。
実現方法を考えてみる
クラウドを用いる場合はもちろん、オンプレミスの場合でも一般的にハードウェアは単一障害点が無いように設計し、
ハードウェア耐障害性は担保されていることが多いです。(無停止で部品を交換することが出来る仕組みを使う)
なので、ソフトウェアの可用性を高める以下のようなクラスタリングシステムについて例を用いて解説します。
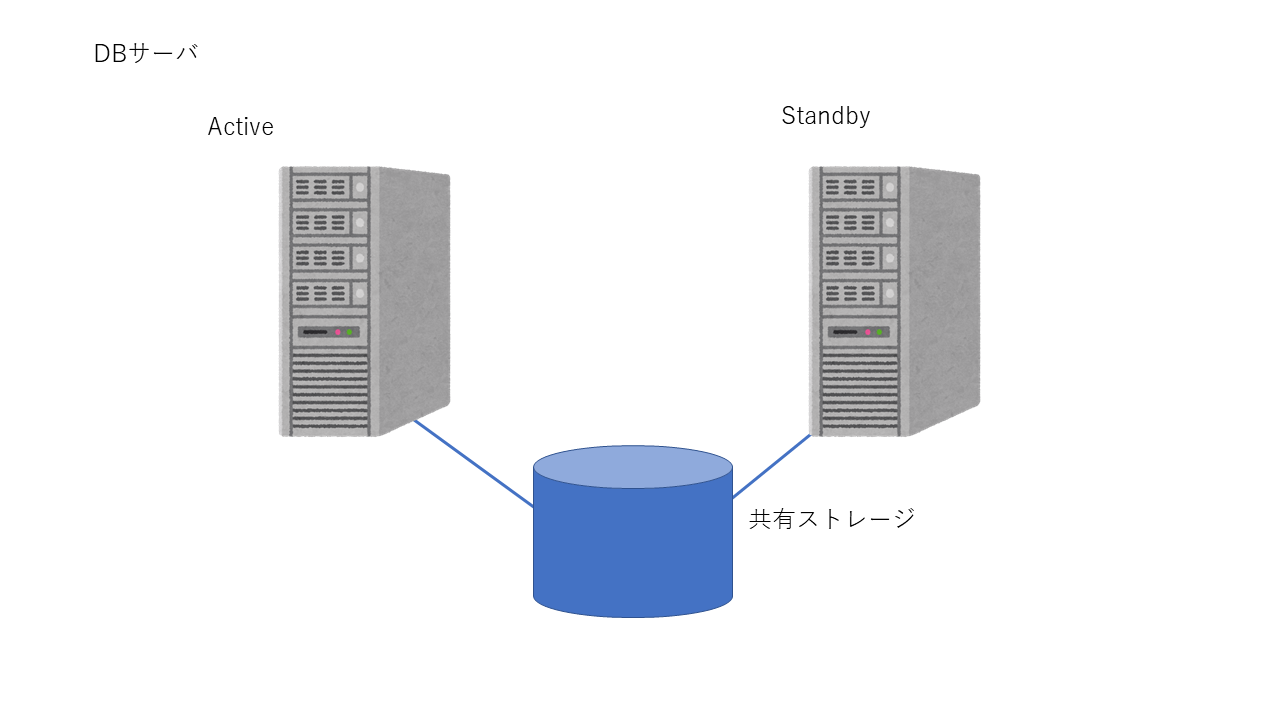
Active-Standby構成のクラスタリング。共有ストレージを切り替えて、サービスを上げ下げすることで切替を行
います。
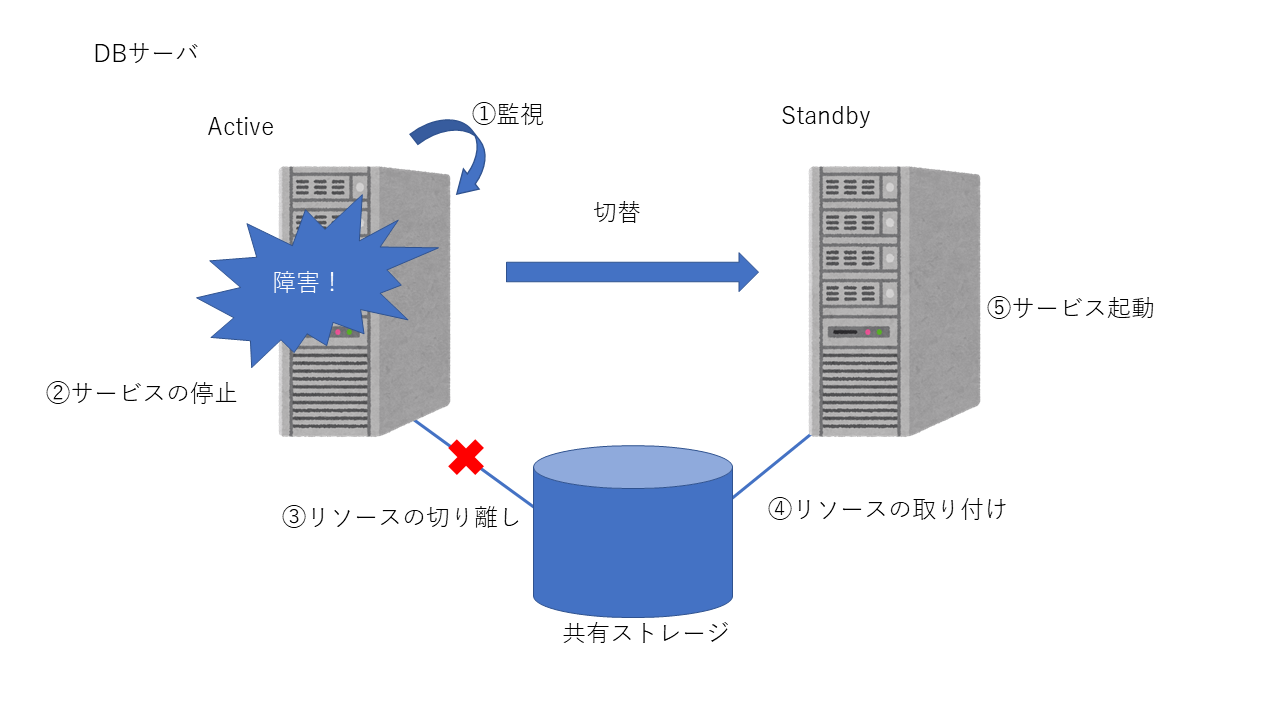
このようなシステムの場合、障害が発生してからスタンバイ側でサービス再開するまでに以下のようなことが起こります。
1. 監視
サービスが起動しているかどうかを定期的にクラスタリングソフトが監視します。
監視間隔は設定できることが多いですが、短すぎると誤検知してしまう確率が上がり、長すぎると気づくのが遅くなるので稼働率が下がってしまいます。
2. サービスの停止
監視で異常に気付いた後は、サービスを停止します。
サービスが異常になっている場合、正常に停止できないこともあるので、まずは普通に止めてみて、ダメだったら強制終了する というような動きになることが多いです。
この場合も、強制終了に移行するまでの時間を決めれることが多いですが、短すぎると正常稼働時でも強制終了してしまい、DBに不整合が起きてしまったり、逆に長すぎるとその分、稼働率が下がることになります。
3. リソースの切り離し
共有ストレージやVIPの切り離しを行います。LinuxでLVMだとアンマウント⇒LVダウン⇒VGダウン といった感じです。
それなりに時間がかかります。上2つと同様にタイムアウトが設定できるようになっていることが多いです。
4. スタンバイ側でのリソースの取り付け
Active側の切り離しが完了したら、Standby側でリソースの取り付けを行います。
5. サービス起動
正常にリソースが取り付けられたら、決められた順番に沿ってサービスを起動していきます。
これでDBサーバとしてはサービス再開できるわけです。
稼働率はどのくらいになるか
この例の場合、気にすべきタイマ値は以下です。
- 監視間隔(ソフトウェアで制御可能)
- サービス停止時間(タイムアウトはソフトウェアで制御可能)
- リソース切り離し時間(マシンスペックや構成に大きく依存)
- リソース取り付け時間(マシンスペックや構成に大きく依存)
- サービス起動時間(マシンスペックや構成に大きく依存)
仮に監視間隔120(s)、サービス停止の最大値が240(s)、リソース切り離し+リソース取り付けが120(s)、サービス起動に120(s)かかるとすると
切替に10分かかるということになります。
仮に月に1回障害が発生し切替が行われるとすると(発生しすぎですが、一旦)
稼働率 =1 - \frac{10分}{(30日 \times 24時 \times 60分)} = 99.976...\%
となり99.9%以上の稼働率となります。
-
Service Level Agreement for Hosting and Realtime Database - Firebase (https://firebase.google.com/terms/service-level-agreement) ↩