PNDAとは
PNDAは、Platform for Network Data Analytics の略です。
Ciscoが中心となり開発している Platform で Open Source として公開されています。
Kafka, Hadoop, Spark などを統合したデータ分析環境です。
PNDA のサイトは、以下になります。Documentation や Use Case などの情報が公開されています。
PNDA Home page
PNDA の Source Codeは、以下で公開されています。
PNDA project
PNDA 概要
PNDA は、Open Sourceのコンポーネントを組み合わせてできています。
主なコンポーネントを以下の図に示します。
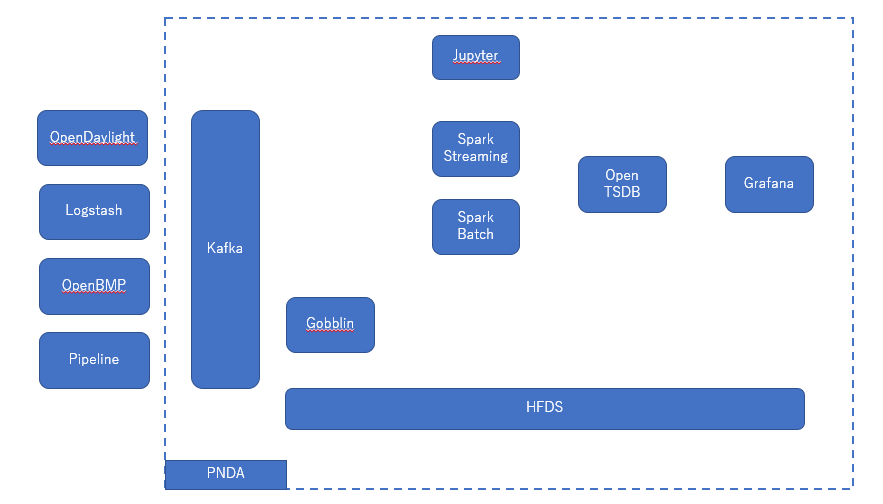
基本的な処理の流れは、次のようになります。
- 外部のProducerと呼ばれるソフトウエアがKafkaに対して、Topicという形でデータをPushする。
- Sparkで作成アプリケーションがKafakaからデータをpullして、処理を行う。
- その結果をTSDBに格納し、Grafana で可視化する。
- Spark での処理を作成する際に、Jupyter Notebookを使って対話的に処理を確認することもできる。
- Kafka に入力されたデータは一定時間ごとに、Gobblin により、HDFS に保存される。
- 処理結果のデータをHDFSに格納することもできる。
PNDA を使う利点
PNDA を利用するとどんなメリットあるのでしょう。PNDA のサイトによれば、利点は以下のように要約されています。
”広範な Big Data 技術から、その機能やコミュニティにおけるサポートなどを考慮して、評価選択されたソフトウエア群が、Stream lineのデータ解析アプリケーションが開発できるように統合されている。"
PNDA サイトには以下のようなこともメリットして上がっています。
- 拡張性の高い、データ分析プラットフォーム。
- 複数のBig Data解析ツールを容易に接続できる。
- データソースとアプリケーションを分離できる。
- 大量のデータをそのままの形で保存できる。
- Logstash と Open Daylight に関しては、Kafka 用の plug-inが用意されている。
- Kafkaによりデータのアプリケーションへの分配が容易にできる。
- Jupyter Notebookによる対話的な、データの解析ができる。
ただ、上記の個々のメリットはPNDAに使用されている各種のOpen Sourceソフトウエアによるものです。その点を除いてPNDAそのもののメリットは何かを考えると以下のようなことではないかと思います。
- 個々のソフトウエアを個別にインストールするのではなくて、ある程度試験された組み合わせのソフトウエアを一括してインストールできる。
- 各コンポーネントを使いやすくするために、次のようなPNDA独自のソフトウエアが提供されている。
- 各ソフトウエアの動作状況やリソース状況などを管理できるDashboard
- PNDAのdefault形式(avro)でHDFSに格納されたデータをdecodeしたり加工するすためのpython library。
- pythonで開発したアプリケーションをPNDAに登録し、管理する機能。PNDAに登録したアプリケーションは、PNDAに含まれるozzieを使って、定期的に起動したり、ワークフローの一部に組み込んだりできる。
- KafakaからデータをHDFSに定期的に保存したり、一定期間を経過したデータを削除するなどのデータ管理機能。
ただし、一括インストールができるといっても、実際にインストールした限りでは結構大変でした。
PNDA のインストール
環境によるかもしれませんが、PNDA のインストールは簡単とは言えないです。PNDA のドキュメントの半分ぐらいは、インストールについて書かれているように思います。
インストール環境
PNDA のインストール環境にはいくつかの要素があります。その中で主なものは下記の表に示す VMM (Virtual Machine Management), OS, Hadoop distributionの三種類です。
| VMM | AWS, OpenStack, VMware, Existing Server |
| OS | RHEL, CentOS, Ubuntu |
| Hadoop | Cloudera, Hotonworks |
どうもすべての組み合わせが試験されているわけではないようです。私は、以下の組み合わせでインストールしました。その際は、一部インストールスクリプトを書き換える必要がありました。
| Release | Items |
|---|---|
| 4.0.1 | OpenStack (Newton), CentOS7, Hotonworks |
| develop (5.0.0に近い) | VMware(6.5), CentOS7, Hotonworks |
PNDA Release 5.0.0 のRelease Noteからテストされた組み合わせに関する記述が載るようになりました。それを見る限りでは、AWS以外の環境では、あまりテストされていないように見えます。
なお、VMwareに関しては、Experimental であまりテストしていないと明記されています。
リソースについて
PNDA のドキュメントによると、約20台のVMで、合計で約100 cpu core, 400 GB memory, 8TB disk spaceが PNDA の standard インストール環境として定義されています。
PNDA を試しに動かしてみたいという場合に、このリソースは多すぎるので、お試し環境として pico というのが別に定義されています。pico では、VM 5台で、約20 cpu core, 70 GB memory, 250 GB disk space となります。
例えば、OpenStackの場合のリソース例は、以下に記述されています。
PNDA OpenStack Resource
私は、手元のリソースが豊富というわけではなかったのでpicoを使いました。ただし、大規模な解析には向きません。
インストール手順
VMM によらず、インストールの流れは同じで、以下のようになります。
- Base Imageを作成。ただし、AWS では、CentOS などの image が既に用意されているので不要。
- mirrorを作成。Hadoop などのアプリケーションや各種ライブラリをInternetにアクセスせずにインストールするための local repository。
- いくつかのアプリケーションをbuild。インストール時に個々のマシンでbuildする必要がないように事前にbinaryをbuildしておく。主に、PNDA 固有のアプリケーション。
- 個々のVMを作成して、インストール。
また、VM の生成に関しては、VMM によって以下のツールを使用することで、インストールを自動化しています。
| AWS | CloudFormation |
| OpenStack | Heat |
| VMware | Teraframe |
SaltStackについて
PNDA では、Heat などを使ってVMを生成した後、Salt Stackを使って個々のVMに必要なアプリケーションおよびライブラリをインストールします。
Saltの場合、各VMで、minion と呼ばれる agent が動きます。Salt Masterと呼ばれるmaster serverからの指示でyumなどのコマンドを実行して、必要な環境を構築します。インストールするパッケージや、その依存関係などはSLS (Salt State file)に記述されています。
この Saltを使うステージがインストールの最終ステージですが、私がインストールした環境では、5時間以上かかった気がします。また、このステージがうまく行かないときは、SLS の中身などを調べる必要があるので、ある程度、Salt の理解も必要です。
インストール時注意事項
以下のような点には留意してインストールすると失敗は少なくなるかと思います。
- なるべくなら、Release Note で試験されている組み合わせを選択する。
- pnda gitからいくつかのfileをダウンロードしたり、設定ファイルで PNDA の Release を指定したりする個所があるが、使用するReleaseは一貫して同じものを指定するようにする。
- 可能であれば、http proxy を使わずにdirectでインストールするようにする。
最後の、proxyをなるべく使わないという件ですが、これは、proxyを使う場合、単にproxy用の環境変数だけでなく、インストールのスクリプトの使用する環境変数などにも値を入れておく必要があるので、手順が複雑になる点が、理由の一つです。
PNDAは、Bastion (橋頭保) と呼ばれる nodeを作成するモードと作成しないモードがあるようです。どうも、OpenStack の private network などに PNDA を作成すると、外部からは、Bastion node を通じてしかアクセスできないようです。ただ、Bastion を使うモードでインストールしてしまうと、PNDA を実際に使う際に ssh tunnel や http proxy の設定が必要になるのでややこしいです。私は、まだよく理解できていないのですが、インストール時にproxyを使う設定が、bastion を使うモードに関係しているかもしれないです。
PNDA 使用方法
いくつかのアプリケーションの例が以下のgit repository にあります。
PNDA Application Examples
これを試す場合も、PNDAのRelease と同じ Release の git repositoryからファイルを取ってくる必要があります。
実のところ、pySparkしか、まだ操作していません。KafkaやGrafanaの部分はまだです。そのため、具体的な使い方というのは判っていません。時間があれば、その部分についてもアップデートしたいと思います。
PNDA における Machine Learning について
PNDA そのものは、特に機械学習に特化した機能はもっていません。データ解析で機械学習を使うのであれば、Sparkの持っている機能に依存にします。
Sparkの機械学習ライブラリは、Spark 1.6であれば、MLlib, Spark 2.0では MLがあるそうです。Spark 2.0を使っていますが、MLもPNDAをインストールした際に、インストールされていました。MLは、Spark 対応という点で、Data Frameをそのまま入力できたりする点が便利ですが、機能は少ないです。
後から、TensorFlowをインストールしてpySparkから使用することはできました。しかし、TensorFlowはSpark対応というわけではないので、複数ノードに分散した RDD や Data Frame といった Spark 環境固有のデータ構造は扱えないと思います。ローカルノードで Numpy などに変換する必要があります。