イントロダクション
この記事はパフォーマンスチューニングが根底にあります。1
パフォーマンスチューニングをするためにはSQL Serverが何をしているのか、どういう理屈や順序で探してきているのかを知る必要がありました。
私は考えました。
「そんなもの実際に運用してるサーバー弄らせてでももらえなければ実感できぬ…………」
なのでとりあえず引き出しを増やすため、私は大きく以下の手順で進めます。
1.入口になる基本的なSQL、あるいはデータベースの知識を出す
2.私の知る観点でそのトピックを元に拡張したり、まとめる
3.概要を出せたら、その情報を知るためのキーワードを書く
「調べたら思い出せる」+「調べ方も概ね見当がつく」となるように覚書をします。読む方もそのつもりだと幸いですが、いかんせん「調べても見つからないものを書こう」とした内容ですので、調べづらいものも多々あります。
本記事で分からない内容があれば、それはおおむね下記の書籍からわかると思います。2
「絵で見てわかるSQL Serverの仕組み」 平山 理 翔泳社
https://amzn.asia/d/7lGKP0N
内容としては、基礎的な概念は理解していることを込みで裏側の話が多いです。3
SQLの処理
歴史とかはさておき、SQL Server上でSQLはどう処理されていくのでしょうか。
まず、有名な話ではありますがSQLでも例えばSELECTは処理順序があります。
FROM → WHERE → GROUP BY → HAVING
→ SELECT → UNION → ORDER BY → DISTINCT
この通りですね。まあ日本語訳すると
1.どの表を見るか指定
2.どの条件で見るか指定
3.どの条件でまとめるか指定
4.どの条件でまとめたものを見るか指定
5.出力するカラムを指定
6.結合するテーブルを指定
7.並び替えの方法を指定
8.重複したものを除外
この順序で出力される。
パフォーマンスの観点で言うと、WHEREに関数を入れるな、SELECTで*を使うなというのがよく言われています。
SQL自体の良し悪しももちろん、どのようなインデックスがどこに張られていて、テーブルはどういった性質を持つのかという議論もできます。
インデックスでもクラスタ化インデックスは一定範囲のデータ検索に適しているし、非クラスタ化インデックスは小規模な検索に適している。
それぞれの話をしているときりがないのですが、要は 「テーブルやインデックスにも種類があるし、それぞれCRUDで向き不向きがある」 というのが漫然とした事実です。
[キーワード]
・インデックス 種類
・SQL 実行順
・パフォーマンスチューニング
コンピュータの設計と処理を寄り添わせる
キャッチーな言語化が出来ないので見出しは分かりづらいですが、ハードディスクってどうやってデータを記録していっているのでしょうか。というイントロダクションから始めるべき内容です。
プログラミング言語は私達が解読できる形をしていますが、これはコンパイル、インタプリタ4などによって抽象化、簡略化されて私達が分かりやすい形で使えるようにセットされています。
機械の分野では、ユーザー(この場合はお客様)が入力したり利用するサービスと、プログラマーやエンジニアの利用するものでは後者の方が直観的ではない構造をしていますが、プログラマーやエンジニアと機械自身でも同じことが起きているようなのです。
本題に戻します。なので、パフォーマンスや大規模な何かを機械上で扱う、となると、この「直観的ではない構造」を理解して、それに沿った処理あるいは機械自体の設計の再考をしてやる場面が発生します。
代表例がトランザクションログ。SQL Server上でデータの変更があるたびに、ログファイルとして物理ディスクにそれを書き込んでいます。
変更処理

データベースは実際にデータを収めるデータファイル、ログを収めるログファイルで分かれています。
先にログファイルにログを入れてから、実際のデータファイルの変更を行います。
このログファイルには面白い性質があり、トランザクションログを書き込むとき、前回のトランザクションログの書き込み終了時点から開始します。
物理的なディスク(ここではハードディスク)はレコードプレーヤーのような形をしており、ログファイルの収納先のディスクを別の用途で使うと、ログの書き込み終了地点とは違うところまで回ってしまいます。
その時に新しいトランザクションログを書き込もうとすると、ディスクがもう一度終了地点まで回転してしまう。なので、ログを書き込むディスクはログ専用に用意すると回転して位置を戻さなくなり、パフォーマンスが向上します。
似たようなトピックとして、ディスク上で管理するのではなくメモリが徹頭徹尾管理することで処理数を増やそうとする「インメモリOLTP」という手法も。
これも普通のデータベースとは情報の配置法則が違ったりして、一概に良いものではありません。
ただし、ディスク上で管理するかメモリ上で完結するかという考慮点はパフォーマンスの観点で必要になってきます。5
要旨として、 コンピューターの動作とはただUI上のプログラムやシステムを触っているだけでは分かりづらく、調査や学習である程度勘所を掴まないと、いざという時に対処が難しくなる ような部分があります。
[キーワード]
・ハードディスク 仕組み
・SQL Server インメモリ
※本セクションの内容はネット上で記述が少なく、キーワードでは出てこない場合もあります。
関連内容のリマインドとしては先述した「絵で見てわかるSQL Serverの仕組み」を参照下さい。
パフォーマンス改善に関する観察
SQL自体のパフォーマンスは、平たく言えば大事です(今回のような細部の調整をする以前に元のSQLの無駄は少ないほどいい)。
ただ、それだけでは頭打ちするパフォーマンスチューニングの際にどこを見ればいいのか。というと、ケースバイケースにはなりますが以下のようなものが考えられます。
データベースの検索傾向に併せたインデックスの実装
先ほどもちらりと触れていますが、どんな検索が多いかによって適したインデックスの種類というものがあります。一件だけ見つけるようなSQLが多いのか、一定範囲をまとめてくるものが多いのか…………。
付加列インデックス、カバリングインデックス…………SQL Serverでは様々なインデックスが実装できるので是非それぞれの特徴を学んで適切な実装を行いたいところです。6
後述しますが、ただメリットデメリットを学んで実際の採用時の考慮基準に織り込む、というだけではなくモニタリングなどで状況を見ていくことも重要です。
覚書として、私の知る限りのインデックスの種類を列挙します。
・クラスタ化インデックス
・非クラスタ化インデックス
・クラスタ化列ストアインデックス
・非クラスタ化列ストアインデックス
・ハッシュインデックス
・インメモリクラスタ化インデックス
・インメモリ非クラスタ化インデックス
・カバリングインデックス
・付加列インデックス
CPUの運用方法の見直し
先に書いておくと、CPUを増設しろとは言っていません。運用上NUMAという概念を知っていると、意外なパフォーマンス向上になるかもしれない。というトピックです。
メモリとCPUの間にはデータを交換するための経路、バスがあり、CPU達はバスをある程度共有しています。
CPU1がメインメモリを取ってしまうと、CPU2~10はバスが使われているので待機になります。また、CPUが増えるとバスも長くなって、単純にアクセスの時間もかかります。
じゃあCPU増やしてもコスパ悪い? そういうことではなくてですね。
こうなればいいのになぁと誰かが思ったらしく、出来るようになりました。これがNUMAアーキテクチャです。7
いくつかのCPUがグループになり、独自のバスとメモリを手にしたのです。バスは短く、待機は少なく。可能であるならウィンウィンです。
深い世界になるとハードウェアではNUMAに対応していないのにソフトウェア上でNUMAのように振る舞うソフトNUMAなる存在もいます。
[キーワード]
・NUMAアーキテクチャ
・ソフトNUMA
・バス
モニタリングによる課題発見
色々書きましたが、そもどこがネックなのかが分からないといけないのが実態で。
SSMS(SQL Server Management Studio)やSQL Server自体の機能で現状を正しく知ることが必要です。
まずはこれ。SSMSの推定実行プランの表示機能です。
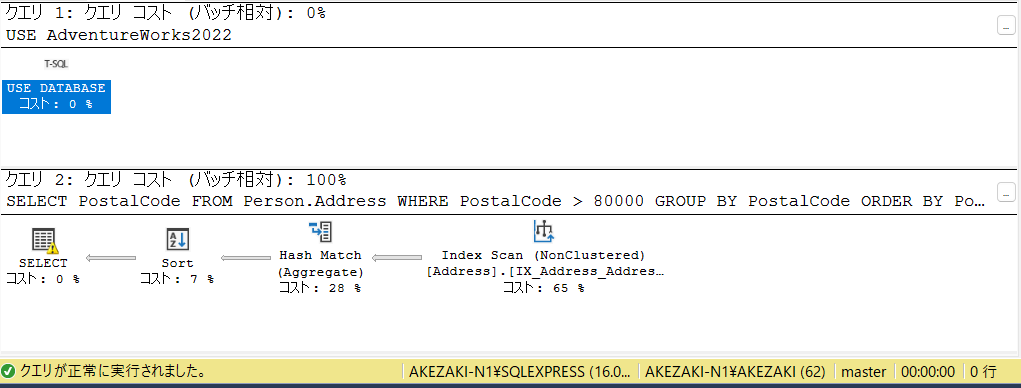
表示方法などは本旨ではないので省きますが、具体的に実行しようとしているクエリの動作やそのコストの比重などを調べる際に扱います。
これはクエリをたたくことで呼び出せるスナップショット。
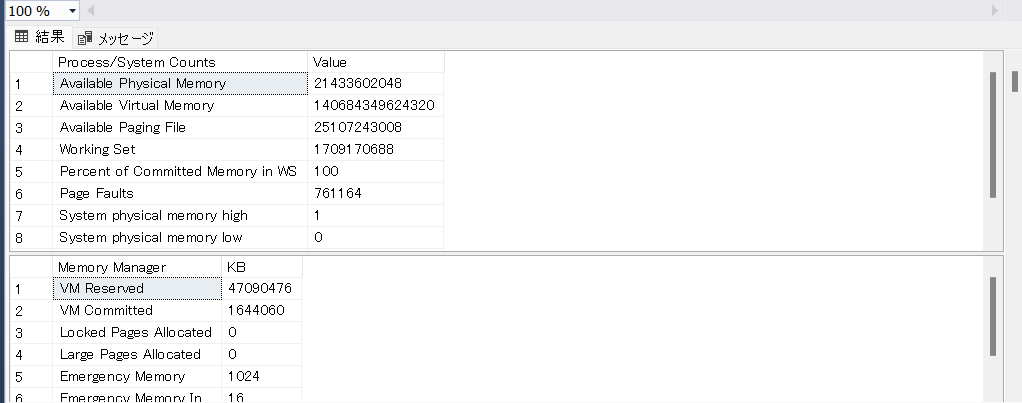
DBCC MEMORY STATUS
GO
今回であれば上記のSQLで出せます。
他にはクエリストアなどの概念も活用したいところ。
[キーワード]
・SSMS 推定実行プラン
・SQL Server DBCC
・クエリストア
まとめとして
可能な限り、実際にキーワードや単語をピックアップして、いざというときに思い出せる記事を意識しました。私の覚書としてはまずまずなのですが、他の方にとってはどうでしょうか。
本記事の最終目標を最後に開示すると
SQLの速度低下を感じた際に、SQLの改善だけではなく、NUMAアーキテクチャ、クラスタ化インデックスと言った単語が状況と照らし合わせながら浮かぶようになる為のとっかかりの文章
でした。
たとえばデータが維持される必要のないテーブルはメモリ最適化テーブルで実装すればよいとか。8
検索範囲が広いことが多いからこのテーブルはクラスタ化インデックスに変えておくかだとか。
あるいはよく分からないからとりあえず推定実行プランとDBCCコマンド辺りで探してみるかとか。
そういうニュアンスの発想につながっていけば記事を作成した意味はあると思います。
私も可能な限り定着したと考えている内容を記述していますが、あくまで定着した知識の使い方につながるトピックになっています。情報のわずかな不正確さや、あるいは別の原因で不適切、不適当な内容があればご指摘いただけるとありがたいです。
-
ざっくり言うとデータベースの処理を早くしたり、あまり負荷をかけないようにしようという調整作業。 ↩
-
ではなぜ引用していないんだと言われますと、「知識を実践的に、問題に直面した時にどういう思考で活用するのか」が趣旨であり、本書の重要としている知識そのものは抽象的に記述しているためです。参考文献としてご理解ください。 ↩
-
具体的にはSQLでCRUDを打つのは問題ないし、テーブルとインデックスとデータベースが何っていうのは一応説明できる程度ぐらいを想定しています。内部処理というより、実務でどう動いてるか分かれば大丈夫です。 ↩
-
大枠で話すと、「コンピューターが読めるように指示を直してやる作業」です。 ↩
-
「メモリ上で完結するか」という表現は違和感があるかもしれません。普段はディスクで管理している場合も、アクセス時にはメモリに読み込みます。実は常にメモリ上にあるか、そうでないかというだけの違いです。 ↩
-
本記事は「壁に突き当たった際のアイデア量を増やす」がテーマであるため、個別の内容は概要理解のためにしか触れません。 ↩
-
この資料によればバスとは物理的であるかのように描かれています。ですがNUMAアーキテクチャの各種解説ではメモリを二つにグループごとに分けるという考え方が基本で書かれ、「物理ではない」かのようにも見えます。この辺りは調べても中々わからなかったので曖昧に書いていますが(本記事はNUMAの利便性を書いているのであってその物理的な状況や法則が理解できなければ書けないわけではないため)、分かる方いればご教授いただきたいです。おそらくハードウェア側がNUMAアーキテクチャをサポートしているので出来ているだけとは思われますが……。 ↩
-
インメモリOLTPで使われるテーブル。 ↩